
大事务报警处理方法
更新时间:2023-08-24
概览
大事务是指运行时间比较长,操作的数据比较多的事务。大事务风险有很多,主要集中如下两点:
- 锁定太多的数据,造成大量的阻塞和锁超时,影响其他线程正常执行SQL语句。
- 执行时间长,容易造成主从延迟。
百度RDS数据库采集了大事务的监控项:最大事务执行时间,用于监控大事务是否存在。大事务监控默认不会添加报警策略,需要用户根据自身需要配置报警策略。
本文重点讲解存在大事务报警的情况下,如何应对和处理。
参考资料:《监控报警操作指南》
需求场景
适用于有大事务困扰的云数据库RDS用户。
方案概述
问题发现
大事务问题的发现渠道有如下几种:
- 在BCM配置了RDS最大事务执行时间的监控策略,当达到报警阈值,会发送报警信息。
- 访问数据库过程中发现耗时增加,极大可能是存在未提交的大事务,阻塞了部分线程的SQL执行
- 查看RDS仪表盘监控趋势图,观察最大事务执行时间的曲线,如下图例。
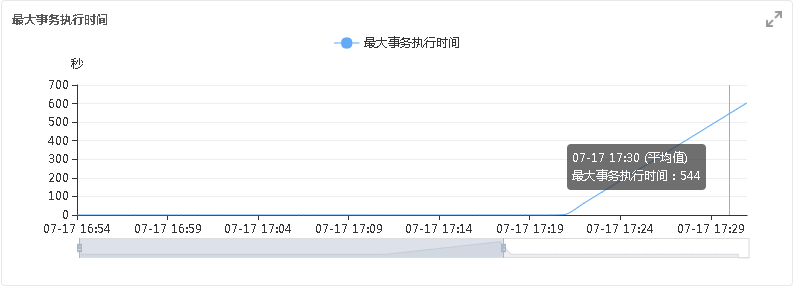
问题定位
- 第一步:使用数据库账号登录RDS实例,执行如下命令,查看当前进程状态,是否存在预期中的长耗时SQL。
Plain Text
1show processlist;举例:得到结果如下:
Plain Text
1| 35620525 | db_user | ip:34880 | baidu_dba | Sleep | 563 | | NULL |
2| 35620617 | db_user | ip:35270 | NULL | Query | 0 | starting | show processlist |- 第二步:打印InnoDB内核日志,建议打印到文本文件方便后续分析。
Plain Text
1SHOW ENGINE INNODB STATUS \G- 第三步:查询文件中的关键字:ACTIVE。
Plain Text
1grep -A2 ACTIVE status.log举例:得到结果如下:
Plain Text
1---TRANSACTION 421530771110624, not started
20 lock struct(s), heap size 1136, 0 row lock(s)
3---TRANSACTION 326595544, ACTIVE 565 sec
42 lock struct(s), heap size 1136, 1 row lock(s), undo log entries 1
5MySQL thread id 35620525, OS thread handle 140055217084160, query id 400967592 127.0.0.1 db_user- 第四步:分析。 如上面的举例,发现一个执行了565秒的事务,且事务的线程ID是与第一步查看到的线程ID匹配:35620525。
问题解决
首先需要确认这个事务是否可以回滚,如果可以回滚,登录RDS执行KILL命令:
Plain Text
1KILL 35620525(threadID)这时客户端会收到报错信息如下,这是符合预期的:
Plain Text
1ERROR 2006 (HY000): MySQL server has gone away 观察监控趋势图:最大事务执行时间恢复正常。
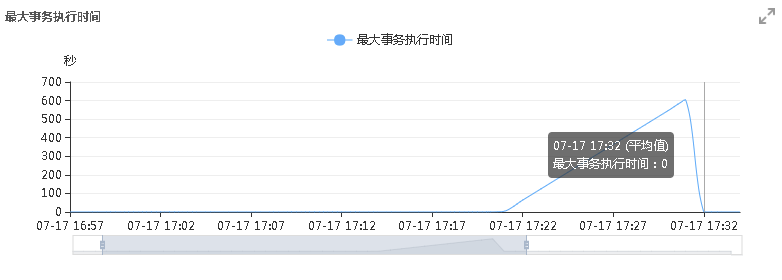
相关产品
云数据库 SCS:兼容 Redis、Memcached 协议的分布式缓存服务。
云数据库 DocDB for MongoDB:兼容 MongoDB 协议的文档数据库服务。
评价此篇文章