
接口调用
Hi,您好,欢迎使用百度人体分析私有化部署产品。
人体分析私有化部署包部署成功后,即可获得与在线API基本完全相同的接口,相关接口将会启动,即可参考本文档开始调用测试。
人体分析的各个接口拆分为不同的私有部署包,人体关键点识别、人流量统计、人体检测、人体属性识别(单人版)、手势识别、人像分割、手部关键点识别、驾驶行为分析对应8个不同的部署包,方便选取所需能力灵活应用。
接口能力介绍
1、人体关键点识别
检测图片中的所有人体,识别每个人体的21个主要关键点,包含四肢、脖颈、五官等部位,同时可输出人体的坐标信息。支持多人检测、人体位置重叠、遮挡、背面、侧面、中低空俯拍、大动作等复杂场景。
- 21个关键点的位置:头顶、左眼、右眼、左耳、右耳、左嘴角、右嘴角、鼻子、脖子、左肩、右肩、左手肘、右手肘、左手腕、右手腕、左髋部、右髋部、左膝、右膝、左脚踝、右脚踝。
注:接口会返回人体坐标框和每个关键点的置信度分数,在应用时可综合置信度score分数,过滤掉置信度低的“无效人体”,推荐的过滤阈值在下文"接口调用说明"部分展开。
2、人体检测
检测图像中的所有人体,返回每个人体的矩形框位置;支持人体重叠、遮挡、截断、背面、侧面、动作变化等复杂场景。人体像素需大于60px * 60px。
3、人体属性识别(单人版)
输入单个人体的图片,识别人体的静态属性和行为,共支持28种属性。主要适用于中低空大角度斜拍视角,支持人体轻度重叠、轻度遮挡、背面、侧面等不同拍摄角度。
- 可识别28种属性:性别、年龄阶段、下身服饰类别、上身服饰类别、戴帽子(可区分普通帽/安全帽)、戴口罩、上身服饰颜色、下身服饰颜色、使用手机、吸烟、身体朝向、撑伞、背包、是否有交通工具……
注:接口返回的属性信息包括人体的遮挡、截断情况,在应用时可基于此过滤掉“无效人体”,比如严重遮挡、严重截断的人体。
4、人流量统计
识别和统计图像当中的人体个数(静态统计,不支持追踪和去重);支持框定多个不规则区域统计局部人数,同时可输出渲染图片。
适用于3米以上的中远距离俯拍,5米以上为佳,以头部为主要识别目标统计人数,无需正脸、全身照,适应各类人流密集场景。支持轻度畸变的鱼眼摄像头。
5、手势识别
识别图片中的手势类型,返回手势名称、手势矩形框、概率分数,可识别24种常见手势,适用于手势特效、智能家居手势交互等场景。
- 支持的24类手势列表:拳头、OK、祈祷、作揖、作别、单手比心、点赞、Diss、我爱你、掌心向上、双手比心(3种)、数字(9种)、Rock、竖中指。
适用于3米以内的拍摄距离,1米内为佳,自拍和他人拍摄均支持,拍摄距离尽量近一些,否则手势目标太小,容易漏识别。
6、人像分割
识别人体的轮廓范围,与背景进行分离,适用于拍照背景替换、照片合成、身体特效等场景。输入正常人像图片,返回分割后的二值结果图、灰度图、透明背景的人像图(png格式)。 美颜、P图等图片美化手段会影响分割效果,请使用原图进行分割。
7、手部关键点识别
检测图片中的手部,输出手部坐标框、21个骨节点的坐标信息。当前主要适用于图片中单个手部的情况,图片中同时存在多个手部时,识别效果可能欠佳。
8、驾驶行为分析
针对车载场景,识别驾驶员使用手机、抽烟、不系安全带、未佩戴口罩、闭眼、打哈欠、双手离开方向盘等动作姿态,分析预警危险驾驶行为,提升行车安全性。
接口格式说明
变量类型定义
| 类型 | 定义 |
|---|---|
| string | 普通的字符串,可能会有长度要求,具体参见接口说明中的备注 |
| uint32 | 整形数字,最大取值为4字节int。自然数 |
| int64 | 整形数字,最大取值为8字节int。允许负数 |
| json | 无论是request还是response中某个字段定义为json,那么它其实是一个json格式的字符串,需要二次解析 |
| array | request的query中表示array请使用key[] 。response的json中的array即为jsonArray |
| double | 双精度,小数点后最大8位四舍五入 |
返回格式
- error_code、error_msg即错误码和错误描述,详细含义请参考错误码表, error_code为0代表请求成功
- result是接口返回的详细信息, 格式为数组。
- log_id是请求的日志id, 13位长(bigint), 用于定位请求。
{
"error_code" : 0, //错误码 0代表成功
"error_msg" : "SUCCESS", //错误信息
"result" : {...} //返回结果 具体内容详见相关接口
"log_id" : 3535325235 //请求的日志id
"timestamp" : 1512391548 //请求到达的时间戳 精确到秒级
"cached" : 0 //未启用 无需处理
}接口调用说明
人体关键点识别
检测图片中的所有人体,识别每个人体的21个主要关键点,包含四肢、脖颈、五官等部位,同时可输出人体的坐标信息。
21个关键点的位置:头顶、左耳、右耳、左眼、右眼、鼻子、左嘴角、右嘴角、脖子、左肩、右肩、左手肘、右手肘、左手腕、右手腕、左髋部、右髋部、左膝、右膝、左脚踝、右脚踝。示意图如下:

调用接口的地址示例:[192.168.0.1]:8124/GeneralClassifyService/classify,其中ip需要替换为用户自己服务器的ip,端口默认为:8124
路径
/GeneralClassifyService/classify
请求参数
| 参数 | 必选 | 类型 | 可选值范围 | 说明 |
|---|---|---|---|---|
| image | true | string | 0-255彩色图像, size >50 | 图像数据,base64编码,图片长宽比需介于0.1-10之间,图片尺寸长宽小于50pixel时,会提示尺寸过小 |
请求参数构造及python代码示例
请求参数为json格式,请求时请将Content-Type设置为application/json格式。
请求参数格式如下:
{
"data" : base64encode(
{
"image" : base64encode(binary image data)
}
)
}python代码示例如下:
import base64
import json
# 输入图片为/home/work/01.jpg
image_file = "/home/work/01.jpg"
# 将图片内容读取至image_data
with open(image_file, 'rb') as f:
image_data = f.read()
data = {
# 将image_data进行base64编码
"image": base64.b64encode(image_data)
}
request_body = {
# 将data转为json,并进行base64编码
"data": base64.b64encode(json.dumps(data))
}
# 最终应该传入http body的内容
print json.dumps(request_body)返回参数
接口返回人体坐标框和每个关键点的置信度分数,在应用时可综合置信度score分数,过滤掉置信度低的“无效人体”,建议过滤方法:当关键点得分大于0.2的个数大于3,且人体框的得分大于0.2时,才认为是有效人体。
实际应用中,可根据对误识别、漏识别的容忍程度,调整阈值过滤方案,灵活应用,比如对误识别容忍低的应用场景,人体框的得分阈值可以提到0.3甚至更高。
| 字段 | 是否必选 | 类型 | 说明 |
|---|---|---|---|
| person_num | 是 | uint32 | 人体数目 |
| person_info | 是 | object数组 | 人体姿态信息 |
| +location | 是 | object | 人体坐标信息 |
| ++height | 是 | float | 人体区域的高度 |
| ++left | 是 | float | 人体区域离左边界的距离 |
| ++top | 是 | float | 人体区域离上边界的距离 |
| ++width | 是 | float | 人体区域的宽度 |
| ++score | 是 | float | 置信度分数,取值0-1,越接近1代表识别准确的概率越大 |
| +body_parts | 是 | object | 身体部位信息,包含21个关键点 |
| ++left_ankle | 是 | object | 左脚踝 |
| +++x | 是 | float | x坐标 |
| +++y | 是 | float | y坐标 |
| +++score | 是 | float | 置信度分数 |
| ++left_elbow | 是 | object | 左手肘 |
| +++x | 是 | float | x坐标 |
| +++y | 是 | float | y坐标 |
| +++score | 是 | float | 置信度分数 |
| ++left_hip | 是 | object | 左髋部 |
| +++x | 是 | float | x坐标 |
| +++y | 是 | float | y坐标 |
| +++score | 是 | float | 置信度分数 |
| ++left_knee | 是 | object | 左膝 |
| +++x | 是 | float | x坐标 |
| +++y | 是 | float | y坐标 |
| +++score | 是 | float | 置信度分数 |
| ++left_shoulder | 是 | object | 左肩 |
| +++x | 是 | float | x坐标 |
| +++y | 是 | float | y坐标 |
| +++score | 是 | float | 置信度分数 |
| ++left_wrist | 是 | object | 左手腕 |
| +++x | 是 | float | x坐标 |
| +++y | 是 | float | y坐标 |
| +++score | 是 | float | 置信度分数 |
| ++neck | 是 | object | 颈 |
| +++x | 是 | float | x坐标 |
| +++y | 是 | float | y坐标 |
| +++score | 是 | float | 置信度分数 |
| ++nose | 是 | object | 鼻子 |
| +++x | 是 | float | x坐标 |
| +++y | 是 | float | y坐标 |
| +++score | 是 | float | 置信度分数 |
| ++right_ankle | 是 | object | 右脚踝 |
| +++x | 是 | float | x坐标 |
| +++y | 是 | float | y坐标 |
| +++score | 是 | float | 置信度分数 |
| ++right_elbow | 是 | object | 右手肘 |
| +++x | 是 | float | x坐标 |
| +++y | 是 | float | y坐标 |
| +++score | 是 | float | 置信度分数 |
| ++right_hip | 是 | object | 右髋部 |
| +++x | 是 | float | x坐标 |
| +++y | 是 | float | y坐标 |
| +++score | 是 | float | 置信度分数 |
| ++right_knee | 是 | object | 右膝 |
| +++x | 是 | float | x坐标 |
| +++y | 是 | float | y坐标 |
| +++score | 是 | float | 置信度分数 |
| ++right_shoulder | 是 | object | 右肩 |
| +++x | 是 | float | x坐标 |
| +++y | 是 | float | y坐标 |
| +++score | 是 | float | 置信度分数 |
| ++right_wrist | 是 | object | 右手腕 |
| +++x | 是 | float | x坐标 |
| +++y | 是 | float | y坐标 |
| +++score | 是 | float | 置信度分数 |
| ++top_head | 是 | object | 头顶 |
| +++x | 是 | float | x坐标 |
| +++y | 是 | float | y坐标 |
| +++score | 是 | float | 置信度分数 |
| ++left_mouth_corner | 是 | object | 左嘴角 |
| +++x | 是 | float | x坐标 |
| +++y | 是 | float | y坐标 |
| +++score | 是 | float | 置信度分数 |
| ++right_mouth_corner | 是 | object | 右嘴角 |
| +++x | 是 | float | x坐标 |
| +++y | 是 | float | y坐标 |
| +++score | 是 | float | 置信度分数 |
| ++right_eye | 是 | object | 右眼 |
| +++x | 是 | float | x坐标 |
| +++y | 是 | float | y坐标 |
| +++score | 是 | float | 置信度分数 |
| ++left_eye | 是 | object | 左眼 |
| +++x | 是 | float | x坐标 |
| +++y | 是 | float | y坐标 |
| +++score | 是 | float | 置信度分数 |
| ++right_ear | 是 | object | 右耳朵 |
| +++x | 是 | float | x坐标 |
| +++y | 是 | float | y坐标 |
| +++score | 是 | float | 置信度分数 |
| ++left_ear | 是 | object | 左耳朵 |
| +++x | 是 | float | x坐标 |
| +++y | 是 | float | y坐标 |
| +++score | 是 | float | 置信度分数 |
说明:body_parts,一共21个part,每个part包含x,y两个坐标,如果part被截断,则x、y坐标为part被截断的图片边界位置,part顺序以实际返回顺序为准。
返回示例
{
"err_no": 0,
"err_msg": "fg_human_service[status:succeed]",
"result": {
"person_num": 1,
"person_info": [
{
"body_parts": {
"left_ankle":{
"score":0.868368387222290,
"x":643.8750,
"y":649.6250
},
"left_ear":{
"score":0.8685630559921265,
"x":643.8750,
"y":303.68750
},
"left_elbow":{
"score":0.8781360983848572,
"x":677.6250,
"y":413.3750
},"left_eye":{
"score":0.9187903404235840,
"x":635.43750,
"y":303.68750
},
"left_hip":{
"score":0.8074261546134949,
"x":652.31250,
"y":480.8750
},
"left_knee":{
"score":0.7978388071060181,
"x":652.31250,
"y":565.250
},
"left_mouth_corner":{
"score":0.8915061950683594,
"x":635.43750,
"y":320.56250
},
"left_shoulder":{
"score":0.8677763342857361,
"x":660.750,
"y":354.31250
},
"left_wrist":{
"score":0.8828375339508057,
"x":702.93750,
"y":464.0
},
"neck":{
"score":0.8687257170677185,
"x":627.0,
"y":337.43750
},
"nose":{
"score":0.9034447669982910,
"x":627.0,
"y":312.1250
},
"right_ankle":{
"score":0.8528900742530823,
"x":610.1250,
"y":649.6250
},
"right_ear":{
"score":0.8603078126907349,
"x":610.1250,
"y":303.68750
},
"right_elbow":{
"score":0.8440912961959839,
"x":559.50,
"y":413.3750
},
"right_eye":{
"score":0.8926745653152466,
"x":618.56250,
"y":303.68750
},
"right_hip":{
"score":0.7821152210235596,
"x":601.68750,
"y":480.8750
},
"right_knee":{
"score":0.7996079921722412,
"x":610.1250,
"y":573.68750
},
"right_mouth_corner":{
"score":0.8937355875968933,
"x":618.56250,
"y":320.56250
},
"right_shoulder":{
"score":0.8571984171867371,
"x":584.81250,
"y":354.31250
},
"right_wrist":{
"score":0.8279093503952026,
"x":542.6250,
"y":455.56250
},
"top_head":{
"score":0.8723988533020020,
"x":627.0,
"y":278.3750
}
},
"location": {
"height":449.7995910644531,
"left":514.0347900390625,
"score":0.9874296784400940,
"top":256.1484069824219,
"width":226.6530609130859
}
}
]
},
"format": "json",
"img": "./data/img/normal_109.jpg" //这个字段为测试端新加,为方便核对图片结果,与服务端无关。
}错误返回值
| 参数 | 类型 | 必选 | 说明 |
|---|---|---|---|
| err_msg | string | 是 | 错误信息,只在异常中出现(参考错误码) |
| err_code | unit32 | 是 | 错误码,只在异常中出现(参考错误码) |
错误码表
| err_code | err_msg | 解释 |
|---|---|---|
| 0 | Succeed! | 请求成功 |
| 216100 | Failed to parse input json | json读取错误 |
| 216201 | Failed to load the image | 图片加载出错 |
| 216200 | Image empty | 图像数据为空 |
| 216202 | Image size error | 图片尺寸错误 |
| 216202 | Image size is too small | 图片太小,比如小于10像素 |
| 216202 | Invalid image ratio | 图片长宽比超出范围,比如超过10 |
| 216203 | Image detection error | 图片检测错误 |
人体检测
检测图像中的所有人体,返回每个人体的矩形框位置和置信度分数。人体目标需大于30px * 30px,否则模型会直接丢弃,无法检测到有效人体。
调用接口的地址示例:[192.168.0.1]:8125/GeneralClassifyService/classify,其中ip需要替换为用户自己服务器的ip,端口默认为:8125
路径
/GeneralClassifyService/classify
请求参数
| 参数 | 必选 | 类型 | 说明 |
|---|---|---|---|
| image | true | string | 图像数据,base64编码。若图片尺寸长或宽小于50pixel,会提示尺寸过小。 |
| return_crop | false | int | 0或1,0表示false,1表示true,表示是否将检测到的人体框裁剪下来。 异常:若该参数存在无法识别的单词,则忽略不进行处理,默认为false,不裁剪人体框 |
请求参数构造及python代码示例
请求参数为json格式,请求时请将Content-Type设置为application/json格式。
请求参数格式如下:
{
"data" : base64encode(
{
"image" : base64encode(binary image data),
"return_crop" : "0,1",
}
)
}python代码示例如下:
import base64
import json
# 输入图片为/home/work/01.jpg
image_file = "/home/work/01.jpg"
# 将图片内容读取至image_data
with open(image_file, 'rb') as f:
image_data = f.read()
data = {
# 将image_data进行base64编码
"image": base64.b64encode(image_data),
"return_crop": 0,
}
request_body = {
# 将data转为json,并进行base64编码
"data": base64.b64encode(json.dumps(data))
}
# 最终应该传入http body的内容
print json.dumps(request_body)返回参数
| 字段 | 必选 | 类型 | 说明 |
|---|---|---|---|
| err_msg | true | string | 错误信息,只在异常中出现(参考错误码表) |
| err_no | true | uint32 | 错误码,只在异常中出现(参考错误码表) |
| format | true | string | 返回格式说明,默认添加,值为“json” |
| result | true | string | 人体检测结果,服务对返回结果做了base64编码 |
正确返回值说明(返回参数为base64编码格式,将result字段base64解码后可得到以下内容):
| 字段 | 类型 | 说明 |
|---|---|---|
| person_num | int | 检测到的人体框数目 |
| det_res | object数组 | 每个人体框的具体信息 |
| +classname | string | 类型名称,默认为person |
| +left | int | 检测框左坐标 |
| +top | int | 检测框顶坐标 |
| +width | int | 检测框宽度 |
| +height | int | 检测框高度 |
| +probability | float | 对应人体框的概率分数,取值0-1,越接近1代表识别准确的概率越大 |
| +label | int | 下标,默认为1,无实际含义 |
| +crop | string | 如果打开return_crop的请求参数为true,这里会返回该人体的patch图像,base64编码 |
返回示例
{
"person_num": 3,
"det_res":
[
{
"classname":"person",
"crop":"",
"left": 1092,
"top": 594,
"width": 112,
"height": 200,
"probability": 0.6849,
"label":1
},
{
"classname":"person",
"crop":"",
"left": 1263,
"top": 281,
"width": 63,
"height": 130,
"probability": 0.5300,
"label":1
},
{
"classname":"person",
"crop":"",
"left": 969,
"top": 192,
"width": 71,
"height": 75,
"probability": 0.4311,
"label":1
}
]
}错误码表
| err_no | value | err_msg | 解释 |
|---|---|---|---|
| GENERAL_CLASSIFY _SUCCEED |
0 | GeneralClassify [status: human detect succeed] |
人体检测成功(即整体流程成功) |
| GENERAL_CLASSIFY _CONF_FILE_ERR |
216401 | GeneralClassifyProcessorFactory [status:reading conf file error] |
读取conf文件出错 |
| GENERAL_CLASSIFY _BBOX_PREDICT_ERR |
216401 | GeneralClassify [status: bbox predict error!] |
boudingbox检测过程出错 |
| GENERAL_CLASSIFY _INPUT_FORMAT_ERR |
216101 | GeneralClassify [status:parse input format error] |
输入数据中不存在“image”字段 |
| GENERAL_CLASSIFY _INPUT_PARSING_ERR |
216401 | pedestrian-detection-service [status:input parsing failed] |
读取base64输入图片出错 |
| GENERAL_CLASSIFY _IMAGE_EMPTY_ERR |
216200 | pedestrian-detection-service [status:image empty] |
输入数据图片读取结果为空 |
| GENERAL_CLASSIFY _IMAGE_SIZE_ERR |
216202 | pedestrian-detection-service [status:image size not between 50 and 4096] |
输入图片尺寸不在允许范围之内 |
| GENERAL_CLASSIFY _AUTH_ERR |
216401 | pedestrian-detection-service [auth verify error] |
权限问题 |
| GENERAL_CLASSIFY _ENCODE_ERR |
216401 | pedestrian-detection-service [status: encode error] |
人像patch编码成base64字符串 |
人体属性识别(单人版)
输入单个人体的图片,识别人体的静态属性和行为,共支持28种属性。
注:模型默认将输入的整张图片当作“1个人体”直接识别属性,需提前使用人体检测模型,将原图中的每个人体检测、裁剪出来,再调用本服务识别属性信息。
接口返回每个属性的置信度分数,在应用时可综合置信度score分数,过滤掉置信度低的属性。实际应用中,可根据对误识别、漏识别的容忍程度,调整阈值过滤方案,灵活应用。
调用接口的地址示例:[192.168.0.1]:8126/GeneralClassifyService/classify,其中ip需要替换为用户自己服务器的ip,端口默认为:8126
路径
/GeneralClassifyService/classify
请求参数
| 参数 | 必选 | 类型 | 说明 |
|---|---|---|---|
| image | true | string | 图像数据,base64编码。若图片尺寸长或宽小于50pixel,会提示尺寸过小。 |
| type | false | string | 如只需返回某几个特定属性,请将type 参数值设定属性可选值,用逗号分隔,无空格。(如"gender,headwear,carrying_item,cellphone")。不提供该字段则输出默认的17个属性,若需获取其余属性,请将type参数值设定为需要返回的全部属性。 异常情况: ①若该参数存在无法识别的单词,则忽略不进行处理,返回17个默认输出的属性; ②若提供了该参数,但不含任何可识别的合法值,则按err_no=8返回 |
请求参数构造及python代码示例
请求参数为json格式,请求时请将Content-Type设置为application/json格式。
请求参数格式如下:
{
"data" : base64encode(
{
"image" : base64encode(binary image data),
"type" : "gender,headwear,carrying_item,cellphone"
}
)
}python代码示例如下:
import base64
import json
# 输入图片为/home/work/01.jpg
image_file = "/home/work/01.jpg"
# 将图片内容读取至image_data
with open(image_file, 'rb') as f:
image_data = f.read()
data = {
# 将image_data进行base64编码
"image": base64.b64encode(image_data),
"type": "gender,headwear,carrying_item,cellphone"
}
request_body = {
# 将data转为json,并进行base64编码
"data": base64.b64encode(json.dumps(data))
}
# 最终应该传入http body的内容
print json.dumps(request_body)type字段说明
| ID | type | 说明 | 是否默认输出 | 类别数 | 类别取值 |
|---|---|---|---|---|---|
| 0 | gender | 性别 | 是 | 2 | 男性、女性 |
| 1 | age | 年龄阶段 | 是 | 5 | 幼儿、青少年、青年、中年、老年 |
| 2 | action | 动作姿态 | 否 | 4 | 站立、蹲或坐、走、跑 |
| 3 | hair_length | 发长 | 否 | 4 | 长发、中长发、短发、秃顶 |
| 4 | bag | 背包 | 是 | 3 | 无背包、单肩包、双肩包 |
| 5 | upper_wear | 上身服饰 | 是 | 2 | 长袖、短袖 |
| 6 | lower_wear | 下身服饰 | 是 | 5 | 长裤、短裤、长裙、短裙、不确定 |
| 7 | upper_color | 上身颜色 | 是 | 11 | 红、橙、黄、绿、蓝、紫、粉、黑、白、灰、棕 |
| 8 | lower_color | 下身颜色 | 是 | 12 | 红、橙、黄、绿、蓝、紫、粉、黑、白、灰、棕、不确定 |
| 9 | upper_wear_fg | 上身服饰细分 | 否 | 9 | T恤、无袖、衬衫、西装、毛衣、夹克、羽绒服、风衣、外套 |
| 10 | upper_wear_texture | 上身服饰纹理 | 否 | 4 | 纯色、图案、碎花、条纹或格子 |
| 11 | headwear | 是否戴帽子 | 是 | 3 | 无帽、普通帽、安全帽 |
| 12 | glasses | 是否戴眼镜 | 否 | 4 | 无眼镜、戴眼镜、戴墨镜、不确定 |
| 13 | smoke | 是否吸烟 | 是 | 3 | 未吸烟、吸烟、不确定 |
| 14 | cellphone | 是否使用手机 | 是 | 4 | 未使用手机、打电话、看手机、不确定 |
| 15 | orientation | 人体朝向 | 是 | 4 | 正面、背面、左侧面、右侧面 |
| 16 | umbrella | 是否打伞 | 否 | 2 | 未打伞、打伞 |
| 17 | carrying_baby | 是否抱小孩 | 否 | 2 | 未抱小孩、抱小孩 |
| 18 | face_mask | 是否戴口罩 | 是 | 3 | 无口罩、戴口罩、不确定 |
| 19 | glove | 是否戴手套 | 否 | 2 | 无手套、戴手套 |
| 20 | carrying_item | 是否有手提物 | 否 | 3 | 无手提物、有手提物、不确定 |
| 21 | vehicle | 是否有交通工具 | 否 | 4 | 无交通工具、骑摩托车、骑自行车、骑三轮车 |
| 22 | luggage | 是否有拉杆箱 | 否 | 2 | 无拉杆箱、有拉杆箱 |
| 23 | upper_cut | 上方截断 | 是 | 2 | 无上方截断、有上方截断 |
| 24 | lower_cut | 下方截断 | 是 | 2 | 无下方截断、有下方截断 |
| 25 | side_cut | 侧方截断 | 是 | 2 | 无侧方截断、有侧方截断 |
| 26 | occlusion | 遮挡情况 | 是 | 3 | 无遮挡、轻度遮挡、重度遮挡 |
| 27 | is_human | 是否是正常人体 | 是 | 2 | 非正常人体、正常人体。用于判断说明人体的截断/遮挡情况,并非判断动物等非人类生物。 正常人体:身体露出大于二分之一的人体,一般以能看到腰部肚挤眼为标准; 非正常人体:严重截断、严重遮挡的人体,一般是看不到肚挤眼的,比如只有个脑袋、一条腿 |
返回参数
| 字段 | 必选 | 类型 | 说明 |
|---|---|---|---|
| err_msg | true | string | 错误信息,只在异常中出现(参考错误码表) |
| err_no | true | uint32 | 错误码,只在异常中出现(参考错误码表) |
| format | true | string | 返回格式说明,默认添加,值为“json” |
| result | true | string | 人体属性识别结果,服务对返回结果做了base64编码 |
正确返回值说明(返回参数为base64编码格式,将result字段base64解码后可得到以下内容):
| 字段 | 类型 | 说明 |
|---|---|---|
| person_num | int | 人体框数目,固定为1 |
| person_info | object数组 | 每个人体框的具体信息 |
| +location | object | 人体框位置,固定为整图范围(即:原图大小) |
| ++left | int | 检测框左坐标 |
| ++top | int | 检测框顶坐标 |
| ++width | int | 检测框宽度 |
| ++height | int | 检测框高度 |
| ++score | float | 人体框的置信度分数,固定为1 |
| +attributes | object | 人体属性内容 |
| ++gender | object | 性别 |
| +++name | string | 如"男性" |
| +++score | float | 对应概率分数 |
| ++age | object | 年龄阶段 |
| +++name | string | 如"青年" |
| +++score | float | 对应概率分数 |
| ++action | object | 动作姿态 |
| +++name | string | 如"站立" |
| +++score | float | 对应概率分数 |
| ++hair_length | object | 发长 |
| +++name | string | 如"短发" |
| +++score | float | 对应概率分数 |
| ++bag | object | 背包 |
| +++name | string | 如"双肩包" |
| +++score | float | 对应概率分数 |
| ++upper_wear | object | 上身服饰 |
| +++name | string | 如"短袖" |
| +++score | float | 对应概率分数 |
| ++lower_wear | object | 下身服饰 |
| +++name | string | 如"长裤" |
| +++score | float | 对应概率分数 |
| ++upper_color | object | 上身颜色 |
| +++name | string | 如"白" |
| +++score | float | 对应概率分数 |
| ++lower_color | object | 下身颜色 |
| +++name | string | 如"蓝" |
| +++score | float | 对应概率分数 |
| ++upper_wear_fg | object | 上身服饰细分 |
| +++name | string | 如"衬衫" |
| +++score | float | 对应概率分数 |
| ++upper_wear_texture | object | 上身服饰纹理 |
| +++name | string | 如"纯色" |
| +++score | float | 对应概率分数 |
| ++headwear | object | 是否戴帽子 |
| +++name | string | 如"无帽" |
| +++score | float | 对应概率分数 |
| ++glasses | object | 是否戴眼镜 |
| +++name | string | 如"戴眼镜" |
| +++score | float | 对应概率分数 |
| ++smoke | object | 是否吸烟 |
| +++name | string | 如"未吸烟" |
| +++score | float | 对应概率分数 |
| ++cellphone | object | 是否使用手机 |
| +++name | string | 如"未使用手机" |
| +++score | float | 对应概率分数 |
| ++orientation | object | 人体朝向 |
| +++name | string | 如"右侧面" |
| +++score | float | 对应概率分数 |
| ++umbrella | object | 是否打伞 |
| +++name | string | 如"未打伞" |
| +++score | float | 对应概率分数 |
| ++carrying_baby | object | 是否抱小孩 |
| +++name | string | 如"未抱小孩" |
| +++score | float | 对应概率分数 |
| ++face_mask | object | 是否戴口罩 |
| +++name | string | 如"无口罩" |
| +++score | float | 对应概率分数 |
| ++glove | object | 是否戴手套 |
| +++name | string | 如"无手套" |
| +++score | float | 对应概率分数 |
| ++carrying_item | object | 是否有手提物 |
| +++name | string | 如“有手提物" |
| +++score | float | 对应概率分数 |
| ++vehicle | object | 是否有交通工具 |
| +++name | string | 如"无交通工具" |
| +++score | float | 对应概率分数 |
| ++luggage | object | 是否有拉杆箱 |
| +++name | string | 如"有拉杆箱" |
| +++score | float | 对应概率分数 |
| ++upper_cut | object | 上方截断 |
| +++name | string | 如"无上方截断" |
| +++score | float | 对应概率分数 |
| ++lower_cut | object | 下方截断 |
| +++name | string | 如"无下方截断" |
| +++score | float | 对应概率分数 |
| ++side_cut | object | 侧方截断 |
| +++name | string | 如"无侧方截断" |
| +++score | float | 对应概率分数 |
| ++occlusion | object | 遮挡情况 |
| +++name | string | 如"轻度遮挡" |
| +++score | float | 对应概率分数 |
| ++is_human | object | 是否是正常人体 |
| +++name | string | 对应概率分数 |
| +++score | float | 如"正常人体" |
说明:接口返回每个属性的置信度分数,在应用时可综合置信度score分数,过滤掉置信度低的属性。实际应用中,可根据对误识别、漏识别的容忍程度,调整阈值过滤方案,灵活应用。
返回示例
{
"person_num": 1,
"person_info":
[
{
"location":
{
"left": 0,
"top": 0,
"width": 200,
"height": 400
"score": 1.0
}
"attributes":
{
"gender":
{
"name": "男性",
"score": 0.937
}
"hair_length":
{
"name": "短发",
"score": 0.889
}
"lower_wear":
{
"name": "长裤",
"score": 0.925
}
"upper_wear":
{
"name": "短袖",
"score": 0.774
}
}
}
]
}错误码表
| err_no | value | err_msg | 解释 |
|---|---|---|---|
| GENERAL_CLASSIFY _SUCCEED |
0 | GeneralClassify [status: human attrib succeed] |
人体属性检测成功(即整体流程成功) |
| GENERAL_CLASSIFY _CONF_FILE_ERR |
1 | GeneralClassifyProcessorFactory [status:reading conf file error] |
读取conf文件出错 |
| GENERAL_CLASSIFY _BBOX_PREDICT_ERR |
2 | GeneralClassify [status: bbox predict error!] |
boudingbox检测过程出错 |
| GENERAL_CLASSIFY _ATTRIB_PREDICT_ERR |
3 | GeneralClassify [status: attrib predict error!] |
人体属性检测过程出错 |
| GENERAL_CLASSIFY _INPUT_FORMAT_ERR |
4 | GeneralClassify [status:parse input format error] |
输入数据中不存在“image”字段 |
| GENERAL_CLASSIFY _INPUT_PARSING_ERR |
5 | fg_human_attribute [status:input parsing failed] |
读取base64输入图片出错 |
| GENERAL_CLASSIFY _IMAGE_EMPTY_ERR |
6 | fg_human_attribute [status:image empty] |
输入数据图片读取结果为空 |
| GENERAL_CLASSIFY _IMAGE_SIZE_ERR |
7 | fg_human_attribute [status:image size not between 50 and 4096] |
输入图片尺寸不在允许范围之内 |
| GENERAL_CLASSIFY _ATTRIB_TYPE_PARSING_ERR |
8 | fg_human_attribute [status:attrib type parsing failed] |
读取提供的type参数出错 |
人流量统计
识别和统计图像当中的人体个数(静态统计,不支持追踪和去重)。默认识别整图中的人数,支持指定多个不规则区域统计局部人数,同时可输出渲染图片(会增加接口延时)。
适用于3米以上的中远距离俯拍,5米以上为佳,以头部为主要识别目标统计人数,无需正脸、全身照,适应各类人流密集场景。支持轻度畸变的鱼眼摄像头。
渲染图示例如下:

调用接口的地址示例:[192.168.0.1]:8122/GeneralClassifyService/classify,其中ip需要替换为用户自己服务器的ip,端口默认为:8122
路径
/GeneralClassifyService/classify
请求参数
| 参数 | 必选 | 类型 | 说明 |
|---|---|---|---|
| image | true | string | 图像数据,base64编码,图片尺寸长宽小于50pixel,会提示尺寸过小 |
| area | false | array < array < int > > | 特定框选区域坐标,支持多个多边形区域,最多支持10个区域,如输入超过10个区域,截取前10个区域进行识别。 此参数为空或无此参数、或area参数设置错误时,默认识别整个图片的人数 。 area参数设置错误的示例:某个坐标超过原图大小(area坐标取值需<原图,如原图为1080 * 720,area取值范围为1~1079、1~719),x、y坐标未成对出现等; 注意:设置了多个区域时,任意一个坐标设置错误,则认为area参数错误、失效。 area参数设置格式: 1)多个区域用英文逗号“,”分隔; 2)同一个区域内的坐标用英文逗号“,”分隔,默认尾点和首点相连做闭合。 示例:[[xa1,ya1,xa2,ya2,...,xan,yan], [xb1,yb1,xb2,yb2,...,xbn,ybn], ...] |
| show | false | int | 取值范围:0,1,2,3 是否返回热力图渲染结果,含义如下: 0:不返回渲染图(性能最高) 1:只返回渲染图,如果设定了area区域参数,同时返回区域框 2:返回渲染图+左上角的总人数,如果设置了area参数,也会返回区域框 3:返回渲染图+左上角的总人数,如果设置了area参数,不会返回区域框 小于0按0计,大于3按3计。上述结果中,渲染图为红云效果,区域框为蓝线绘制(如果设置了area参数) |
请求参数构造及python代码示例
请求参数为json格式,请求时请将Content-Type设置为application/json格式。
请求参数格式如下:
{
"data" : base64encode(
{
"image" : base64encode(binary image data)
}
)
}python代码示例如下:
import base64
import json
# 输入图片为/home/work/01.jpg
image_file = "/home/work/01.jpg"
# 将图片内容读取至image_data
with open(image_file, 'rb') as f:
image_data = f.read()
data = {
# 将image_data进行base64编码
"image": base64.b64encode(image_data)
}
request_body = {
# 将data转为json,并进行base64编码
"data": base64.b64encode(json.dumps(data))
}
# 最终应该传入http body的内容
print json.dumps(request_body)
返回参数
| 字段 | 必选 | 类型 | 说明 |
|---|---|---|---|
| err_msg | true | string | 错误信息,只在异常中出现(参考错误码表) |
| err_no | true | uint32 | 错误码,只在异常中出现(参考错误码表) |
| format | true | string | 返回格式说明,默认添加,值为“json” |
| result | true | string | 人流密度估计结果,服务对返回结果做了base64编码 |
正确返回值说明:(返回参数为base64编码格式,将result字段base64解码后可得到以下内容)
| 字段名称 | 类型 | 说明 |
|---|---|---|
| person_num | int32 | 识别出的人体数目;当未设置area参数时,返回的是全图人数;设置了有效的area参数时,返回的人数是所有区域的人数总和(所有区域求并集后的不规则区域覆盖的人数) |
| image | string | 渲染图片文件byte内容的base64编码,请求端得到后先做解码再以字节流形式直接写入文件 |
| area_counts | array | 每一个框选区域的人数,仅当请求中有area参数且参数有效时才会返回,否则该字段不返回;成功返回示例:[5,3,8] |
特别说明:
1)person_num固定返回,image只有当请求字段中"show"为true时候返回;
2) image 的内容是图片字节内容做byte64编码的string字符,拿到后反编码再按照字节写成文件即可;
返回示例
{"person_num": 86} // 请求时,show为0或者不传
{"person_num": 86, "image": "/9j/4AAoFS2P/9k="} // 请求时,show为1错误码表
| err_code | err_msg | 名称 | 说明 |
|---|---|---|---|
| 0 | fg-crowd-counting [status:succeed] |
GENERAL_CLASSIFY _SUCCEED |
整体流程成功 |
| 1 | fg-crowd-counting [status:input format illegal] |
GENERAL_CLASSIFY _INPUT_FORMAT_ERR |
请求未包含image |
| 2 | fg-crowd-counting [status:input parsing failed] |
GENERAL_CLASSIFY _INPUT_PARSING_ERR |
输入格式有误 |
| 3 | fg-crowd-counting [status:image empty] |
GENERAL_CLASSIFY _IMAGE_EMPTY |
图片为空 |
| 4 | fg-crowd-counting [status:image size < 50] |
GENERAL_CLASSIFY _IMAGE_SIZE_ERR |
图片尺寸过小 |
| 5 | fg-crowd-counting [status:heatmap prediction fail] |
GENERAL_CLASSIFY _HM_PREDICT_ERR |
热力图forward出错 |
| 6 | fg-crowd-counting [auth verify error] |
GENERAL_CLASSIFY _AUTH_ERR |
鉴权错误 |
| 7 | fg-crowd-counting [status:detection prediction fail] |
GENERAL_CLASSIFY _BBOX_PREDICT_ERR |
检测器forward出错 |
手势识别
识别图片中的手势类型,返回手势名称、手势矩形框、概率分数,可识别24种常见手势:拳头、OK、祈祷、作揖、作别、单手比心、点赞、Diss、我爱你、掌心向上、双手比心(3种)、数字(9种)、Rock、竖中指。每种手势的示例图参考:https://ai.baidu.com/ai-doc/BODY/4k3cpywrv
适用于3米以内的拍摄距离,1米内为佳,自拍和他人拍摄均支持,拍摄距离尽量近一些,否则手势目标太小,容易漏识别。
调用接口的地址示例:[192.168.0.1]:8120/GeneralClassifyService/classify,其中ip需要替换为用户自己服务器的ip,端口默认为:8120
路径
/GeneralClassifyService/classify
请求参数
| 参数 | 是否必选 | 类型 | 说明 |
|---|---|---|---|
| appid | false | string | 固定值,示例:123456 |
| logid | false | int | 随机数 |
| format | false | string | 固定值,示例:json |
| from | false | string | 固定值,示例:test-python |
| cmdid | false | string | 固定值,示例:123 |
| clientip | false | string | 固定值,示例:0.0.0.0 |
| data | true | string | 图片的base64编码字符串 |
请求参数构造及python代码示例
请求参数为json格式,请求时请将Content-Type设置为application/json格式。
请求参数格式如下:
{
"data" : base64encode(
{
"image" : base64encode(binary image data),
}
)
}python代码示例如下:
import base64
import json
# 输入图片为/home/work/01.jpg
image_file = "/home/work/01.jpg"
# 将图片内容读取至image_data
with open(image_file, 'rb') as f:
image_data = f.read()
data = {
# 将image_data进行base64编码
"image": base64.b64encode(image_data)
}
request_body = {
# 将data转为json,并进行base64编码
"data": base64.b64encode(json.dumps(data))
}
# 最终应该传入http body的内容
print json.dumps(request_body)返回参数
| 字段 | 是否必选 | 类型 | 说明 |
|---|---|---|---|
| err_msg | true | string | 返回错误信息 |
| err_no | true | int | 返回错误代码 |
| format | true | string | 固定值,json |
| result | true | json | 包含所有检测到的目标 |
| +object | true | json | 检测到的一个实例 |
| ++classname | false | string | 目标所属的类别,即手势名称 |
| ++label | false | int | 目标的标签 |
| ++left | false | int | 目标框最左坐标 |
| ++top | false | int | 目标框最上坐标 |
| ++width | false | int | 目标框的宽 |
| ++height | false | int | 目标框的高 |
| ++probability | false | float | 目标属于该类别的概率 |
其中classname和label的对应关系如下表所示:
| label | classname | 手势中文名 |
|---|---|---|
| 1 | One | 数字1(也可以叫做食指) |
| 2 | Five | 数字5(也可以叫做掌心向前) |
| 3 | Fist | 拳头 |
| 4 | Ok | OK |
| 5 | Prayer | 祈祷 |
| 6 | Congratulation | 作揖(也可以叫恭喜) |
| 7 | Honour | 作别 |
| 8 | Heart_single | 单手比心 |
| 9 | Thumb_up | 点赞 |
| 10 | Thumb_down | diss |
| 11 | ILY | 我爱你 |
| 12 | Palm_up | 掌心向上 |
| 13 | Face | 人脸 |
| 14 | Heart_1 | 双手比心1 |
| 15 | Heart_2 | 双手比心2 |
| 16 | Heart_3 | 双手比心3 |
| 17 | Two | 数字2(也可以叫做比V) |
| 18 | Three | 数字3 |
| 19 | Four | 数字4 |
| 20 | Six | 数字6 |
| 21 | Seven | 数字7 |
| 22 | Eight | 数字8 |
| 23 | Nine | 数字9 |
| 24 | Rock | 摇滚 |
| 25 | Insult | 竖中指 |
返回示例:
{
u'err_no': 0,
u'err_msg': u'DetectionSsd[status:succeed]',
u'result':
'{
"object":
[
{
"classname":"Thumb_up",
"height":145,
"label":9,
"left":453,
"probability":0.5996769666671753,
"top":563,
"width":106
}
]
}\n',
u'format': u'json'
}错误码表
| 错误码 | 错误信息 | 说明 |
|---|---|---|
| 0 | DetectionSsd [status:succeed] |
成功检测并返回结果 |
| 216100 | gestureservice [status:Failed to parse input json] |
输入参数解析失败 |
| 216101 | gestureservice [status:Invalid image string in input json] |
输入参数不足 |
| 216200 | gestureservice [status:image empty] |
输入图片为空 |
| 216201 | gestureservice [status:Failed to load the image] |
输入图片解析失败 |
| 216202 | gestureservice [status:Image size is too small] |
输入图片尺寸过小或者裁切后的图片尺寸过小 |
| 216203 | gestureservice [status:Image detection error] |
图片可以正常解析,但图片无法通过网络处理 |
| 216204 | gestureservice [status:Not authenticated] |
请求没有被授权 |
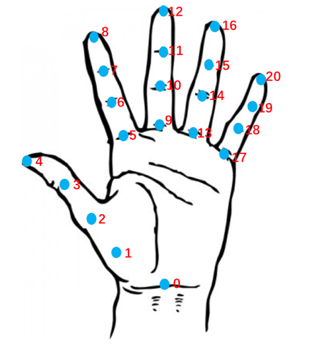
手部关键点识别
检测图片中的所有手部,返回每只手的坐标框、21个骨节点坐标信息。
当前接口主要适用于图片中单个手部的情况,图片中同时存在多个手部时,识别效果可能欠佳。
21个关键点对应位置示意图:
调用接口的地址示例:[192.168.0.1]:8128/GeneralClassifyService/classify,其中ip需要替换为用户自己服务器的ip,端口默认为:8128
路径
/GeneralClassifyService/classify
请求参数
| 参数 | 是否必选 | 类型 | 说明 |
|---|---|---|---|
| appid | false | string | 固定值,示例:123456 |
| logid | false | int | 随机数 |
| format | false | string | 固定值,示例:json |
| from | false | string | 固定值,示例:test-python |
| cmdid | false | string | 固定值,示例:123 |
| clientip | false | string | 固定值,示例:0.0.0.0 |
| data | true | string | 图片的base64编码字符串 |
请求参数构造及python代码示例
请求参数为json格式,请求时请将Content-Type设置为application/json格式。
请求参数格式如下:
{
"data" : base64encode(
{
"image" : base64encode(binary image data),
}
)
}python代码示例如下:
import base64
import json
# 输入图片为/home/work/01.jpg
image_file = "/home/work/01.jpg"
# 将图片内容读取至image_data
with open(image_file, 'rb') as f:
image_data = f.read()
data = {
# 将image_data进行base64编码
"image": base64.b64encode(image_data)
}
request_body = {
# 将data转为json,并进行base64编码
"data": base64.b64encode(json.dumps(data))
}
# 最终应该传入http body的内容
print json.dumps(request_body)
返回参数
| 字段 | 是否必选 | 类型 | 说明 |
|---|---|---|---|
| err_no | true | string | 错误码,只在异常中出现(参考错误码表) |
| err_msg | true | uint32 | 错误信息,只在异常中出现(参考错误码表) |
| result | true | string | base64编码的手部关键点识别结果 |
正确返回值说明:(返回参数为base64编码格式,将result字段base64解码后可得到以下内容)
| 字段名称 | 类型 | 说明 |
|---|---|---|
| hand_info | object数组 | 检测到的所有手部信息 |
| +hand_num | uint32 | 检测到的手部数量 |
| +location | object | 手部所在的位置信息 |
| ++left | uint32 | 手部区域离左边界的距离 |
| ++top | uint32 | 手部区域离上边界的距离 |
| ++height | uint32 | 手部区域的高度 |
| ++width | uint32 | 手部区域的宽度 |
| ++score | float | 手部的置信度分数 |
| +hand_parts | object | 单个手部的关键点信息,包含21个关键点 |
| ++[0-20] | object | 检测到的关键点 |
| +++x | uint32 | 关键点的x坐标 |
| +++y | uint32 | 关键点中的y坐标 |
| +++score | float | 关键点的置信度分数 |
返回示例
{
"hand_num": 1,
"hand_info": [
{
"hand_parts": {
"0": {
"y": 707,
"x": 829,
"score": 0.81601244211197
},
"1": {
"y": 620,
"x": 873,
"score": 0.6850221157074
},
……
"20": {
"y": 325,
"x": 567,
"score": 0.91110396385193
}
},
"location": {
"height": 556,
"width": 426,
"top": 151,
"score": 17.495880126953,
"left": 567
}
}
]
}错误码表
| err_code | err_msg | 说明 |
|---|---|---|
| 0 | Succeed! Congrats, May the force be with you ... | 成功检测并返回结果 |
| 216100 | Failed to parse input json | 输入参数解析失败 |
| 216101 | Invalid image string in input json | 输入参数不足 |
| 216200 | Image empty | 输入图片为空 |
| 216201 | Failed to load the image | 输入图片解析失败 |
| 216202 | Image size is too small (less than 10 pixels) | 输入图片尺寸过小或者裁切后的图片尺寸过小 |
| 216203 | Image detection error | 图片可以正常解析,但图片无法通过网络处理 |
| 216401 | Not authenticated | 请求没有被授权 |
人像分割
识别人体的轮廓范围,与背景进行分离,返回分割后的二值结果图、灰度图、透明背景的人像图(png格式)。分割效果示例图请参考:https://ai.baidu.com/ai-doc/BODY/Fk3cpyxua
美颜、P图等图片美化手段会影响分割效果,请使用原图进行分割。
调用接口的地址示例:[192.168.0.1]:8127/GeneralClassifyService/classify,其中ip需要替换为用户自己服务器的ip,端口默认为:8127
路径
/GeneralClassifyService/classify
请求参数
| 参数 | 必选 | 类型 | 说明 |
|---|---|---|---|
| image | true | bytes | 图像数据,base64编码。必须字段,待分割的图片 |
请求参数构造及python代码示例
请求参数为json格式,请求时请将Content-Type设置为application/json格式。
请求参数格式如下:
{
"data": base64.b64encode(data)
} python 2.x 代码示例如下:
import base64
import json
def encode_img_to_file(image_data):
img_encode = cv2.imencode('.png', image_data)[1]
data_encode = np.array(img_encode)
str_encode = data_encode.tostring()
return str_encode
file = "test.jpg"
image = cv2.imread(file, -1)
img_data = encode_img_to_file(image)
proto_data.image = img_data
data = proto_data.SerializeToString()
data = {
# 将图片进行json编码
"data": base64.b64encode(image_string)
}
# 将数据转为json字符串
request_body = json.dump(data)
# 最终应该传入http body的内容
print json.dumps(request_body)python 3.x 代码示例下载地址:
https://ai.baidu.com/file/8044251026DB40619E8C8E77AB4152A5
返回参数
| 字段 | 必选 | 类型 | 说明 |
|---|---|---|---|
| err_no | true | int | 返回错误代码 |
| err_msg | true | string | 返回错误信息 |
| result | true | string | 分割结果信息 |
| +type | true | string | 分割类型,目前仅支持person |
| +labelmap | true | string | 分割后的二值图结果,经过base64之后的字符串,单通道图片;需二次处理方能查看分割效果,Python、Java的处理示例代码见:https://ai.baidu.com/docs#/Body-API/a28d94ec |
| +scoremap | true | string | 分割后人像前景的scoremap,归一到0-255,单通道图片;不用进行二次处理,直接解码保存图片即可 |
| +foreground | true | string | 分割后的人像前景抠图结果,png图片,透明背景,四通道;不用进行二次处理,直接解码保存图片即可 |
| format | true | string | 固定值,json |
返回示例
{
"err_no": 0,
"err_msg": "ParseService[status:succeed]",
"result":
{
"labelmap": "",
"scoremap": "",
"type":"person",
"foreground": ""
},
"format": "json"
}错误码表
| err_no | 解释 |
|---|---|
| 216100 | 参数无效或者错误 |
| 216200 | 无效图片 |
| 216201 | 图片格式错误 |
| 216401 | 预测过程出错 |
驾驶行为分析
针对车内驾驶室监控画面,识别图像中是否有人体,若检测到至少1个人体,将目标最大的人体作为驾驶员,进一步识别驾驶员的属性行为,可识别使用手机、抽烟、未系安全带、双手离开方向盘、视线未朝前方、未佩戴口罩、闭眼、打哈欠、低头9种典型行为姿态。
注:若图像中检测到多个大小相当的人体,默认取画面中右侧最大的人体作为驾驶员;针对香港、海外地区的右舵车,可通过请求参数里的wheel_location字段,指定将左侧最大的人体作为驾驶员。
图片质量要求:
- 服务只适用于车载驾驶室监控场景,普通室内外监控场景,若要识别使用手机、抽烟等行为属性,请使用人体检测与属性识别服务。
- 车内摄像头硬件选型无特殊要求,分辨率建议720p以上,但更低分辨率的图片也能识别,只是效果可能有差异。
- 车内摄像头部署方案建议:尽可能拍全驾驶员的身体,并充分考虑背光、角度、方向盘遮挡等因素。
- 服务适用于夜间红外监控图片,识别效果跟可见光图片相比可能略微有差异。
- 图片主体内容清晰可见,模糊、驾驶员遮挡严重、光线暗等情况下,识别效果肯定不理想。
调用接口的地址示例:[192.168.0.1]:8132/GeneralClassifyService/classify,其中ip需要替换为用户自己服务器的ip,端口默认为:8132
路径
/GeneralClassifyService/classify
请求参数
| 参数 | 必选 | 类型 | 说明 |
|---|---|---|---|
| image | true | string | 图像数据,base64编码。支持图片格式:jpg、bmp、png,若图片尺寸长或宽小于50pixel,会提示尺寸过小。 |
| type | 否 | string | 如只需识别某几个属性,可用type参数控制接口返回的属性list,英文逗号分隔,如:smoke,cellphone,not_buckling_up;默认所有属性都识别,目前支持的属性列表如下: smoke // 吸烟, cellphone // 使用手机 , not_buckling_up // 未系安全带, both_hands_leaving_wheel // 双手离开方向盘, not_facing_front // 视角未看前方, no_face_mask // 未正确佩戴口罩, yawning // 打哈欠, eyes_closed // 闭眼, head_lowered // 低头 |
| wheel_location | 否 | string | 有效取值范围:0,1 默认值"1",表示左舵车(普遍适用于中国大陆地区,若图像中检测到多个大小相当的人体,默认取画面中右侧最大的人体作为驾驶员); "0"表示右舵车(适用于香港等地区,若图像中检测到多个大小相当的人体,则取画面中左侧最大的人体作为驾驶员); 其他输入值视为非法输入,直接使用默认值 |
请求参数构造及python代码示例
请求参数为json格式,请求时请将Content-Type设置为application/json格式。
请求参数格式如下:
{
"data" : base64encode(
{
"image" : base64encode(binary image data),
"type" : "smoke,cellphone"
}
)
}python代码示例如下:
import base64
import json
# 输入图片为/home/work/01.jpg
image_file = "/home/work/01.jpg"
# 将图片内容读取至image_data
with open(image_file, 'rb') as f:
image_data = f.read()
data = {
# 将image_data进行base64编码
"image": base64.b64encode(image_data),
"type": "smoke,cellphone"
}
request_body = {
# 将data转为json,并进行base64编码
"data": base64.b64encode(json.dumps(data))
}
# 最终应该传入http body的内容
print json.dumps(request_body)返回参数
| 字段 | 必选 | 类型 | 说明 |
|---|---|---|---|
| err_msg | true | string | 错误信息,只在异常中出现(参考错误码表) |
| err_no | true | uint32 | 错误码,只在异常中出现(参考错误码表) |
| format | true | string | 返回格式说明,默认添加,值为“json” |
| result | true | string | 属性识别结果,服务对返回结果做了base64编码 |
正确返回值说明(返回参数为base64编码格式,将result字段base64解码后可得到以下内容):
| 字段 | 类型 | 说明 |
|---|---|---|
| person_num | int | 人体框数目,固定为1 |
| person_info | object数组 | 每个人体框的具体信息 |
| +location | object | 人体框位置,固定为整图范围(即:原图大小) |
| ++left | int | 检测框左坐标 |
| ++top | int | 检测框顶坐标 |
| ++width | int | 检测框宽度 |
| ++height | int | 检测框高度 |
| ++score | float | 人体框的置信度分数,固定为1 |
| +attributes | object | 人体属性内容 |
| ++gender | object | 性别 |
| +++name | string | 如"男性" |
| +++score | float | 对应概率分数 |
| ++age | object | 年龄阶段 |
| +++name | string | 如"青年" |
| +++score | float | 对应概率分数 |
| ++action | object | 动作姿态 |
| +++name | string | 如"站立" |
| +++score | float | 对应概率分数 |
| ++hair_length | object | 发长 |
| +++name | string | 如"短发" |
| +++score | float | 对应概率分数 |
| ++bag | object | 背包 |
| +++name | string | 如"双肩包" |
| +++score | float | 对应概率分数 |
| ++upper_wear | object | 上身服饰 |
| +++name | string | 如"短袖" |
| +++score | float | 对应概率分数 |
| ++lower_wear | object | 下身服饰 |
| +++name | string | 如"长裤" |
| +++score | float | 对应概率分数 |
| ++upper_color | object | 上身颜色 |
| +++name | string | 如"白" |
| +++score | float | 对应概率分数 |
| ++lower_color | object | 下身颜色 |
| +++name | string | 如"蓝" |
| +++score | float | 对应概率分数 |
| ++upper_wear_fg | object | 上身服饰细分 |
| +++name | string | 如"衬衫" |
| +++score | float | 对应概率分数 |
| ++upper_wear_texture | object | 上身服饰纹理 |
| +++name | string | 如"纯色" |
| +++score | float | 对应概率分数 |
| ++headwear | object | 是否戴帽子 |
| +++name | string | 如"无帽" |
| +++score | float | 对应概率分数 |
| ++glasses | object | 是否戴眼镜 |
| +++name | string | 如"戴眼镜" |
| +++score | float | 对应概率分数 |
| ++smoke | object | 是否吸烟 |
| +++name | string | 如"未吸烟" |
| +++score | float | 对应概率分数 |
| ++cellphone | object | 是否使用手机 |
| +++name | string | 如"未使用手机" |
| +++score | float | 对应概率分数 |
| ++orientation | object | 人体朝向 |
| +++name | string | 如"右侧面" |
| +++score | float | 对应概率分数 |
| ++umbrella | object | 是否打伞 |
| +++name | string | 如"未打伞" |
| +++score | float | 对应概率分数 |
| ++carrying_baby | object | 是否抱小孩 |
| +++name | string | 如"未抱小孩" |
| +++score | float | 对应概率分数 |
| ++face_mask | object | 是否戴口罩 |
| +++name | string | 如"无口罩" |
| +++score | float | 对应概率分数 |
| ++glove | object | 是否戴手套 |
| +++name | string | 如"无手套" |
| +++score | float | 对应概率分数 |
| ++carrying_item | object | 是否有手提物 |
| +++name | string | 如“有手提物" |
| +++score | float | 对应概率分数 |
| ++vehicle | object | 是否有交通工具 |
| +++name | string | 如"无交通工具" |
| +++score | float | 对应概率分数 |
| ++luggage | object | 是否有拉杆箱 |
| +++name | string | 如"有拉杆箱" |
| +++score | float | 对应概率分数 |
| ++upper_cut | object | 上方截断 |
| +++name | string | 如"无上方截断" |
| +++score | float | 对应概率分数 |
| ++lower_cut | object | 下方截断 |
| +++name | string | 如"无下方截断" |
| +++score | float | 对应概率分数 |
| ++side_cut | object | 侧方截断 |
| +++name | string | 如"无侧方截断" |
| +++score | float | 对应概率分数 |
| ++occlusion | object | 遮挡情况 |
| +++name | string | 如"轻度遮挡" |
| +++score | float | 对应概率分数 |
| ++is_human | object | 是否是正常人体 |
| +++name | string | 对应概率分数 |
| +++score | float | 如"正常人体" |
说明:接口返回每个属性的置信度分数,在应用时可综合置信度score分数,过滤掉置信度低的属性。实际应用中,可根据对误识别、漏识别的容忍程度,调整阈值过滤方案,灵活应用。
返回示例
{
"person_num": 1,
"person_info":
[
{
"location":
{
"left": 0,
"top": 0,
"width": 200,
"height": 400
"score": 1.0
}
"attributes":
{
"gender":
{
"name": "男性",
"score": 0.937
}
"hair_length":
{
"name": "短发",
"score": 0.889
}
"lower_wear":
{
"name": "长裤",
"score": 0.925
}
"upper_wear":
{
"name": "短袖",
"score": 0.774
}
}
}
]
}错误码表
| err_no | value | err_msg | 解释 |
|---|---|---|---|
| GENERAL_CLASSIFY _SUCCEED |
0 | GeneralClassify [status: human attrib succeed] |
人体属性检测成功(即整体流程成功) |
| GENERAL_CLASSIFY _CONF_FILE_ERR |
1 | GeneralClassifyProcessorFactory [status:reading conf file error] |
读取conf文件出错 |
| GENERAL_CLASSIFY _BBOX_PREDICT_ERR |
2 | GeneralClassify [status: bbox predict error!] |
boudingbox检测过程出错 |
| GENERAL_CLASSIFY _ATTRIB_PREDICT_ERR |
3 | GeneralClassify [status: attrib predict error!] |
人体属性检测过程出错 |
| GENERAL_CLASSIFY _INPUT_FORMAT_ERR |
4 | GeneralClassify [status:parse input format error] |
输入数据中不存在“image”字段 |
| GENERAL_CLASSIFY _INPUT_PARSING_ERR |
5 | fg_human_attribute [status:input parsing failed] |
读取base64输入图片出错 |
| GENERAL_CLASSIFY _IMAGE_EMPTY_ERR |
6 | fg_human_attribute [status:image empty] |
输入数据图片读取结果为空 |
| GENERAL_CLASSIFY _IMAGE_SIZE_ERR |
7 | fg_human_attribute [status:image size not between 50 and 4096] |
输入图片尺寸不在允许范围之内 |
| GENERAL_CLASSIFY _ATTRIB_TYPE_PARSING_ERR |
8 | fg_human_attribute [status:attrib type parsing failed] |
读取提供的type参数出错 |