
创建传输任务
任务信息
1.在日志服务页面中点击“传输任务”,进入传输任务列表页面后,点击“创建传输任务”,进入创建传输任务页面。 2.在“任务信息”区,请输入任务名称。 3.为该任务添加标签,便于进行分类管理与查找。
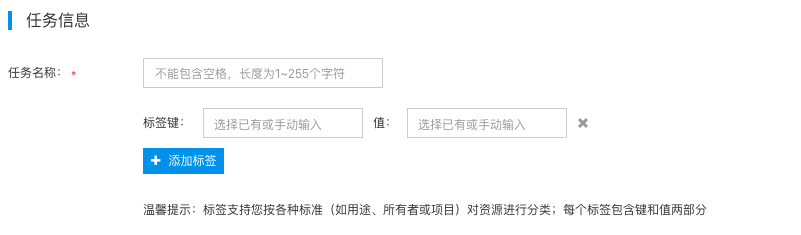
目的端设置
4.在“目的端设置”,设置日志数据投递目的端。产品提供日志集、KAFKA、BOS、BES四种目的端,各端对应的具体参数配置分别如下:
(1)“日志集”作为目的端

- 日志集:选择已创建的日志集;关于日志集功能,请参考日志集
- 传输速率:默认10MB/s,支持速率范围为 [1-100] MB/s。
(2)“BOS”作为目的端

选择“BOS为日志投递目的,不支持解析日志内容。需要注意的是,当源端为离线文件时,系统将每一个文件作为一个BOS对象上传;当源端为实时文件时,可自定义采集间隔,并将采集内容生成一个BOS对象。 请配置如下参数:
- BOS路径:选择BOS路径作为存储日志的目的地址。
-
日志聚合:选择是否依据“时间”“主机”配置聚合在相应目录下,支持多选。
- 根据时间聚合:需选择源日志文件名中包含的时间格式(如“yyyy-MM-dd”),以及选择对应的聚合方式:按天聚合、按小时聚合、用户自定义。其中选择按“用户自定义”的方式聚合日志时,可根据右侧的提示设置日期通配符,系统会根据您定义的日期通配符在您指定的BOS路径中聚合日志。
- 根据主机聚合:需选择按主机IP聚合,或按主机名聚合。
- 传输速率:默认10MB/s,支持速率范围为 [1-100] MB/s。
-
数据压缩:选择是否启用先压缩日志文件后传输功能,默认不启用,若需启用请选择压缩算法,各压缩算法特点如下:
- Gzip:压缩率高,可有效节省空间,但压缩速度慢,且较Snappy和Lzop更多占用CPU资源。
- Snappy:压缩速度快,但压缩率低于Gzip。
- Lzop:压缩速度快,但稍慢于Snappy,压缩率也稍高于Snappy。
- Bzip2:压缩速度慢。
- 实时文件处理策略:若您需要采集正在写入的实时文件,日志服务支持设置采集间隔,避免在BOS中生成大量小文件;该策略设置后对离线文件不生效,离线文件仍为实时采集。
- 传输通知:仅当源端是离线日志类型且在时间聚合时支持传输通知功能,且默认不开启。开启传输通知后,系统将在每个文件传输完毕后,在BOS端目的路径下生成一个对应的文件名加“.done”后缀的空文件,便于下游服务根据标记启动。如下图所示:

(3)“KAFKA”作为目的端

支持将日志传输到专享版Kafka;关于专享版Kafka的使用,请参考专享版Kafka。
- 集群:选择已建立的Kafka集群。
- 主题:选择已创建的Kafka主题。
- 认证协议:请根据您的采集器和Kafka集群所在的网络环境情况,选择Kafka集群所提供的正确协议,可参考查看集群接入点
- 连接地址:选择和认证协议相匹配的连接地址。
- SASL机制:选择与认证协议相匹配的SASL机制。
- 用户名:填写访问集群时认证的用户名。
- 密码:填写访问集群时认证的用户密码。
- 数据丢弃:默认关闭,开启后,若单条消息大小超过10M时则丢弃该条消息。
-
数据压缩:选择是否启用先压缩日志文件后传输功能,默认不启用,若需启用请选择压缩算法,各压缩算法特点如下:
- Gzip:压缩率高,可有效节省空间,但压缩速度慢,且较Snappy和Lz4更多占用CPU资源。
- Snappy:压缩速度快,但压缩率低于Gzip。
- Lz4:压缩速度快,但稍慢于Snappy,压缩率也稍高于Snappy。
- partitioner类型:默认为随机,可选择“按Value值哈希”用于消息去重。
- message key:默认为无,可变更为“源端主机HostName”或“源端主机IP”。
- 传输速率:开启数据压缩状态下,数据传输速率限速1MB/s;关闭数据压缩状态下,数据传输速率限速10MB/s。
(4)“BES”作为目的端

选择“BES”作为日志投递目的,可投递实时日志。请配置如下参数:
- 选择ES集群:选择当前用在当前region已创建的BES集群。
- 用户名:填写所选BES集群的登录用户名
- 密码:填写所选BES集群的登录密码
- 测试连通性:测试并验证是否能够连接上所选的BES集群,如不能连通,传输任务无法正常运行。
- index前缀:index前缀通过用户自定义,index Rolling开启状态下,BES集群中的index名称由“index前缀+采集日期”组成,关闭状态下,index名称由index前缀组成。采集日期是指数据写入BES时的日期,日期格式为:YYYY-MM-DD。
- index Rolling:设定BES集群自动生成新index的频率,默认处于关闭状态;开启后,按照设定频率生成新index,采集的日志数据写入到新index。
源端设置
5.添加源端设置,产品提供“主机”,“容器”,“自定义数据源”三种类型的源端:
- 主机:适用于采集实时写入的、离线的日志文件。
- 容器:适用于采集容器内产生的文本日志和标准输出日志。
- 自定义数据源:支持jornal日志采集和syslog日志采集
详细配置过程信息如下。
(1)“主机”作为源端的配置

当源端类型为“主机”时,有以下特殊配置项:
- 源日志目录:输入采集日志的源目录。目录支持golang Glob模式匹配,详见目录规则。
- 匹配文件规则:输入正则表达式,匹配上正则表达式的文件将会被监控和收集。常见正则表达式语法以及编写示例如下:
| 符号 | 说明 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
| [^a] | 匹配除了a以外的任意字符 |
| [^abc] | 匹配除了abc这几个字符以外的任意字符 |
| (?!abc) | 否定前瞻排除abc字符串出现 |
| \D | 匹配任意非数字的字符 |
| \S | 匹配任意不是空白符的字符 |
1示例:
21.匹配所有.log结尾的文件: .*.log$
32.匹配某个具体的文件如service1.log: ^service1.log$
43.匹配service1或者service2多个日志文件: ^(service1|service2).log$
54.匹配除了service3以外的所有日志文件: ^(?!service3.log$).*.log$
65.匹配service.log.2016-01-01_123这类文件带日期和后缀带自增数字的文件: ^\w*.log.\d{4}-\d{2}-\d{2}_\d*$- 排除文件规则:输入正则表达式,匹配正则表达式的文件将不会被监控和收集,可排除正在写入的日志文件,避免导致传输出现异常,具体规则填写示例见上面匹配文件规则。
- 采集元数据:添加与日志一起上传的元数据,主机支持自定义环境变量,在日志集日志中以@tag_元数据形式展示,在Kafka和BES中以Json形式展示!
- 目录递归:默认关闭,开启后,最多可传输指定目录(包含所有层次的子目录)下5个符合匹配文件规则的活跃文件。 开启目录递归会增加CPU占用。
- 有效文件时间范围:可选时间范围为1~90天,默认3天,即默认收集传输任务创建前3天以及之后新建或编辑的文件,最多可以回溯到任务创建前90天。
(2)“容器”作为源端的配置
当源端类型为”容器“时,支持采集标准输出与容器内日志,具体配置项如下:
(2.1)日志类型为标准输出日志

-
采集元数据:支持固定元数据,自定义Label,自定义环境变量采集
注意:
目的端为日志集时:收集器1.6.1及以后版本容器固定元数据才可支持自定义配置,且新增自定义Label配置;收集器1.6.1之前版本默认采集固定元数据,且不支持自定义Label,修改该两项内容不生效;如需使用新能力,请参考帮助文档升级对应收集器版本
目的端为Kafka和ES时:收集器1.6.1及以后版本容器固定元数据可支持自动开启和关闭,且新增自定义Label配置;收集器1.6.1之前版本如添加了自定义环境变量则自动采集容器固定Label,容器固定元数据和自定义Label配置后不生效;如需使用新能力,请参考帮助文档升级对应收集器版本
- Label白名单:如果要设置Label白名单,点击【添加白名单】,依次输入LabelKey、LabelValue内容,其中LabelKey、Labelvalue必填,LabelValue支持输入正则表达式来匹配所有需要采集的目标容器。
-
Label黑名单:如果要设置Label黑名单,点击【添加黑名单】,依次输入LabelKey、LabelValue内容,其中LabelKey、Labelvalue必填,LabelValue支持输入正则表达式来匹配所有需要排除的目标容器。
注意:
- Label白名单中多个键值对之间逻辑关系为【且】
- Label黑名单中多个键值对之间逻辑关系为【或】
- Label白名单、Label黑名单内Labelkey值不能重复,LabelVaule值不能为空
- 环境变量白名单:如果要设置环境变量白名单,点击【添加白名单】,依次输入EnvKey、EnvValue内容,其中EnvKey、EnvValue必填,EnvValue支持输入正则表达式来匹配所有需要采集的目标容器。
-
环境变量黑名单:如果要设置环境变量黑名单,点击【添加黑名单】,依次输入EnvKey、EnvValue内容,其中EnvKey、EnvValue必填,EnvValue支持输入正则表达式来匹配所有需要排除的目标容器。
注意:
- 环境变量白名单中多个键值对之间逻辑关系为【且】
- 环境变量黑名单中多个键值对之间逻辑关系为【或】
- 环境变量白名单、环境变量黑名单内Envkey值不能重复,EnvVaule值不能为空
- 有效文件时间范围:可选时间范围为1~90天,默认3天,即默认收集传输任务创建前3天以及之后新建或编辑的文件,最多可以回溯到任务创建前90天。
(2.2)日志类型为容器内部日志

- 源日志目录:输入采集日志的源目录。目录支持golang Glob模式匹配,详见目录规则。注意这里的目录应当填写容器内的路径,而非挂载到宿主机的路径。并且需要将容器内日志文件的任意级父路径挂载到宿主机中。
- 匹配文件规则:输入正则表达式,匹配正则表达式的文件将会被监控和收集。常见正则表达式语法以及编写示例如下:
| 符号 | 说明 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
| [^a] | 匹配除了a以外的任意字符 |
| [^abc] | 匹配除了abc这几个字符以外的任意字符 |
| (?!abc) | 否定前瞻排除abc字符串出现 |
| \D | 匹配任意非数字的字符 |
| \S | 匹配任意不是空白符的字符 |
1示例:
21.匹配所有.log结尾的文件: .*.log$
32.匹配某个具体的文件如service1.log: ^service1.log$
43.匹配service1或者service2多个日志文件: ^(service1|service2).log$
54.匹配除了service3以外的所有日志文件: ^(?!service3.log$).*.log$
65.匹配service.log.2016-01-01_123这类文件带日期和后缀带自增数字的文件: ^\w*.log.\d{4}-\d{2}-\d{2}_\d*$- 排除文件规则:输入正则表达式,匹配正则表达式的文件将不会被监控和收集,可排除正在写入的日志文件,避免导致传输出现异常。具体规则填写示例见上面匹配文件规则
-
采集元数据:支持固定元数据,自定义Label,自定义环境变量采集
注意:
目的端为日志集时:收集器1.6.1及以后版本容器固定元数据才可支持自定义配置,且新增自定义Label配置;收集器1.6.1之前版本默认采集固定元数据,且不支持自定义Label,修改该两项内容不生效;如需使用新能力,请参考帮助文档升级对应收集器版本
目的端为Kafka和ES时:收集器1.6.1及以后版本容器固定元数据可支持自动开启和关闭,且新增自定义Label配置;收集器1.6.1之前版本如添加了自定义环境变量则自动采集容器固定Label,容器固定元数据和自定义Label配置后不生效;如需使用新能力,请参考帮助文档升级对应收集器版本
- Label白名单:如果要设置Label白名单,点击【添加白名单】,依次输入LabelKey、LabelValue内容,其中LabelKey、LabelValue必填,LabelValue支持输入正则表达式来匹配所有需要采集的目标容器。
-
Label黑名单:如果要设置Label黑名单,点击【添加黑名单】,依次输入LabelKey、LabelValue内容,其中LabelKey、LabelValue必填,LabelValue支持输入正则表达式来匹配所有需要排除的目标容器。
注意:
- Label白名单中多个键值对之间逻辑关系为【且】
- Label黑名单中多个键值对之间逻辑关系为【或】
- Label白名单、Label黑名单内Labelkey值不能重复,LabelVaule值不能为空
- 环境变量白名单:如果要设置环境变量白名单,点击【添加白名单】,依次输入EnvKey、EnvValue内容,其中EnvKey、EnvValue必填,EnvValue支持输入正则表达式来匹配所有需要采集的目标容器。
-
环境变量黑名单:如果要设置环境变量黑名单,点击【添加黑名单】,依次输入EnvKey、EnvValue内容,其中EnvKey、EnvValue必填,EnvValue支持输入正则表达式来匹配所有需要排除的目标容器。
注意:
- 环境变量白名单中多个键值对之间逻辑关系为【且】
- 环境变量黑名单中多个键值对之间逻辑关系为【或】
- 环境变量白名单、环境变量黑名单内Envkey值不能重复,EnvVaule值不能为空
- 有效文件时间范围:可选时间范围为1~90天,默认3天,即默认收集传输任务创建前3天以及之后新建或编辑的文件,最多可以回溯到任务创建前90天。
(3)自定义数据源配置
(3.1)Journal日志

- 数据源:Journal日志
- Unit单元:默认为空,表示采集全部Unit单元的数据,可自定义添加,支持添加多个
- Journal路径:默认为空代表采集journal内存数据,添加具体journal路径代表采集journal持久化数据代表采集journal持久化数据,如/var/log/journal,支持添加多个
- 首次采集方式:默认Tail,Tail表示只采集采集器绑定任务后的新数据,Head表示采集所有数据;提示内容写到按钮下方
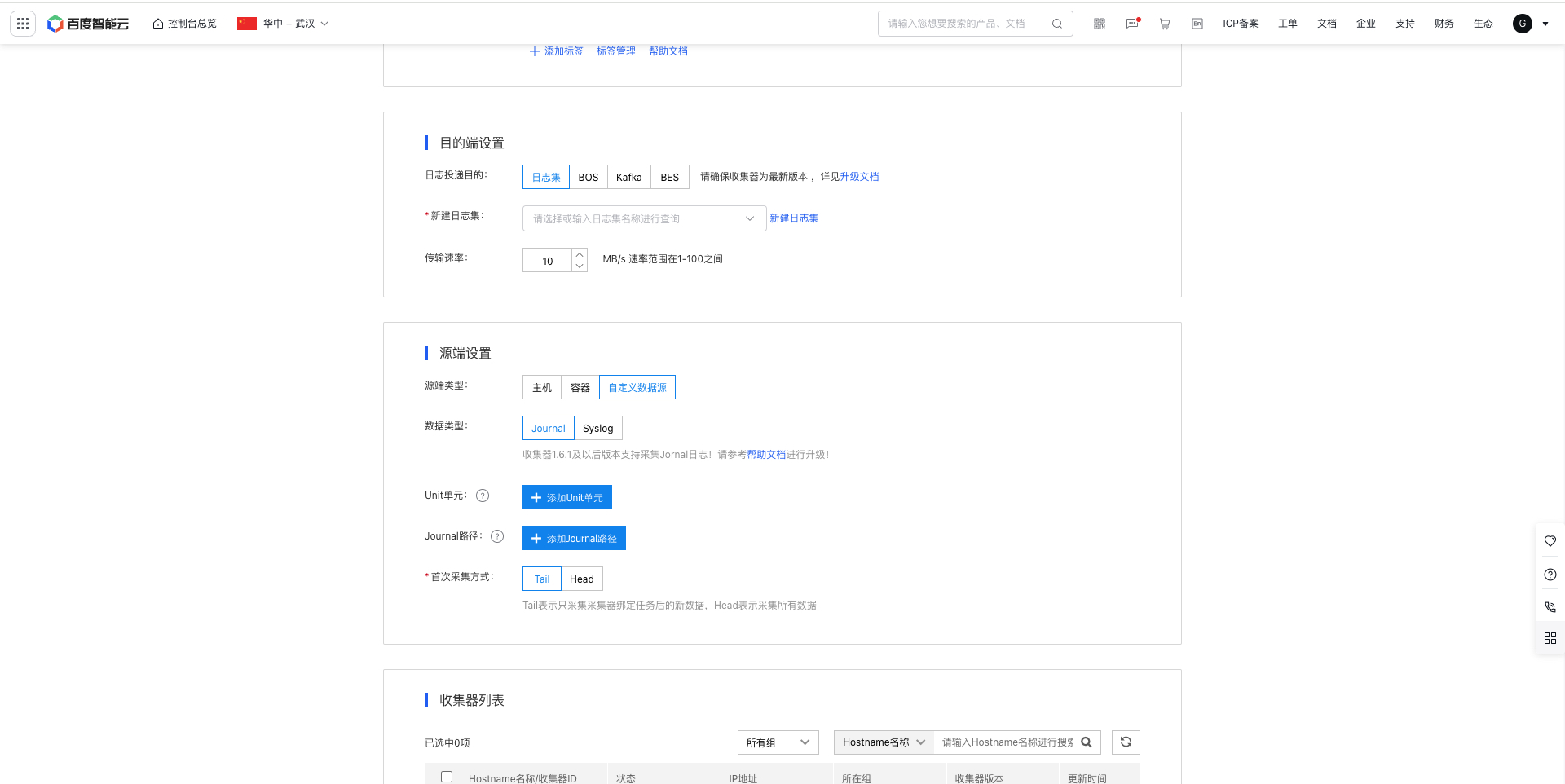
(3.2)syslog日志

- 数据类型:syslog日志
- 输出源:必填,默认项:tcp://127.0.0.1:9999,表示只能接收本地转发的日志。可自定义修改,格式为[tcp/udp]://[ip]:[port]。
-
解析日志协议类型:
- 指定解析日志所使用的协议,默认为不解析,可选择其他解析类型
- fc3164:指定使用RFC3164协议解析日志
- rfc5424:指定使用RFC5424协议解析日志
- auto:指定Logtail根据日志内容自动选择合适的解析协议
处理配置
6.通过处理配置可对日志进一步的解析处理,支持处理插件和DSL函数
(1)主机和容器方式处理插件配置
- 样例日志:可不填写,建议填写
- 多行模式:如果您的日志是多行的,请开启多行模式,并设置行首正则表达式,系统将以此正则作为每条日志的分割标识。
-
数据处理插件:默认无,支持添加多个处理插件,可上下移动位置,添加后可删除,按顺序串行处理
注意:数据处理插件组合配置需要升级到1.6.8及以后版本,旧版本支持情况如下: 1.旧版本只可配置Json解析、KV解析、正则解析、分隔符解析中其中一个解析规则,配置多个不生效 2.旧版本支持配置时间解析配置和过滤处理插件但必需在Json解析、KV解析、正则解析、分隔符解析后面才生效 3.旧版本不支持新增的添加字段和丢弃字段插件
| 类型 | 说明 |
|---|---|
| JSON解析 | 可解析Json格式日志 原始字段:默认系统字段@raw,可自定义修改丢弃解析失败日志:开启状态,会自动丢弃解析失败的日志数据;关闭状态,日志解析失败时上传原始日志。 原始字段:默认系统字段@raw,可自定义修改丢弃解析失败日志:开启状态,会自动丢弃解析失败的日志数据;关闭状态,日志解析失败时上传原始日志。 |
| KV解析 | 通过KV提取日志字段,并将日志解析为键值对形式  原始字段:默认系统字段@raw,可自定义修改 样例日志:默认从外面带过来正则表达式:输入正则表达式,如何配置正则表达式见下方Syslog日志处理配置日志提取字段:支持从样例日志中根据解析规则解析出来,用户需要给Value值输入自定义的Key和类型,或者自定义添加(有样例日志且在第一个位置时支持解析,其他情况只可自定义添加) 丢弃解析失败日志:开启状态,会自动丢弃解析失败的日志数据;关闭状态,日志解析失败时上传原始日志保留原始字段:开启后,将保留解析前的日志原始字段 原始字段:默认系统字段@raw,可自定义修改 样例日志:默认从外面带过来正则表达式:输入正则表达式,如何配置正则表达式见下方Syslog日志处理配置日志提取字段:支持从样例日志中根据解析规则解析出来,用户需要给Value值输入自定义的Key和类型,或者自定义添加(有样例日志且在第一个位置时支持解析,其他情况只可自定义添加) 丢弃解析失败日志:开启状态,会自动丢弃解析失败的日志数据;关闭状态,日志解析失败时上传原始日志保留原始字段:开启后,将保留解析前的日志原始字段 |
| 正则解析 | 通过正则表达式提取日志字段,并将日志解析为键值对形式  原始字段:默认系统字段@raw,可自定义修改 样例日志:默认从外面带过来正则表达式:输入正则表达式,如何配置正则表达式见下方Syslog日志处理配置日志提取字段:支持从样例日志中根据解析规则解析出来,用户需要给Value值输入自定义的Key和类型,或者自定义添加(有样例日志且在第一个位置时支持解析,其他情况只可自定义添加) 丢弃解析失败日志:开启状态,会自动丢弃解析失败的日志数据;关闭状态,日志数据解析失败时,日志解析失败时上传原始日志保留原始字段:开启后,将保留解析前的日志原始字段 原始字段:默认系统字段@raw,可自定义修改 样例日志:默认从外面带过来正则表达式:输入正则表达式,如何配置正则表达式见下方Syslog日志处理配置日志提取字段:支持从样例日志中根据解析规则解析出来,用户需要给Value值输入自定义的Key和类型,或者自定义添加(有样例日志且在第一个位置时支持解析,其他情况只可自定义添加) 丢弃解析失败日志:开启状态,会自动丢弃解析失败的日志数据;关闭状态,日志数据解析失败时,日志解析失败时上传原始日志保留原始字段:开启后,将保留解析前的日志原始字段 |
| 分隔符解析 | 通过分隔符将日志内容结构化,解析为多个键值对形式  原始字段:默认系统字段@raw,可自定义修改 样例日志:默认从外面带过来分隔符:选择按照空格、竖线、逗号等分隔符分隔,并且支持用户自定义分隔符引用符:默认不启用,可选择按照单引号、双引号等引用符日志提取字段:支持从样例日志中根据解析规则解析出来,用户需要给Value值输入自定义的Key和类型,或者自定义添加(有样例日志且在第一个位置时支持解析,其他情况只可自定义添加) 丢弃解析失败日志:开启状态,会自动丢弃解析失败的日志数据;关闭状态,日志解析失败时上传原始日志保留原始字段:开启后,将保留解析前的日志原始字段 原始字段:默认系统字段@raw,可自定义修改 样例日志:默认从外面带过来分隔符:选择按照空格、竖线、逗号等分隔符分隔,并且支持用户自定义分隔符引用符:默认不启用,可选择按照单引号、双引号等引用符日志提取字段:支持从样例日志中根据解析规则解析出来,用户需要给Value值输入自定义的Key和类型,或者自定义添加(有样例日志且在第一个位置时支持解析,其他情况只可自定义添加) 丢弃解析失败日志:开启状态,会自动丢弃解析失败的日志数据;关闭状态,日志解析失败时上传原始日志保留原始字段:开启后,将保留解析前的日志原始字段 |
| 时间解析 | 解析日志的时间字段,如不解析则默认为系统时间  原始字段:默认系统字段@raw,可自定义修改 样例日志:默认从外面带过来时间解析格式:配置时间解析格式则指定解析结果中的一个字段作为时间字段,您需提供该字段时间解析格式,系统将按照该格式解析日志时间,如果解析失败则使用系统时间作为日志时间。格式书写可以参考此链接:SimpleDateFormat。 原始字段:默认系统字段@raw,可自定义修改 样例日志:默认从外面带过来时间解析格式:配置时间解析格式则指定解析结果中的一个字段作为时间字段,您需提供该字段时间解析格式,系统将按照该格式解析日志时间,如果解析失败则使用系统时间作为日志时间。格式书写可以参考此链接:SimpleDateFormat。 | | |
| 过滤处理 | 支持通过数据表达式过滤日志内容,只采集符合表达式要求的日志数据  数据表达式:配置数据表达式,只采集符合表达式要求的日志数据。表达式支持的语法具体如下: 数据表达式:配置数据表达式,只采集符合表达式要求的日志数据。表达式支持的语法具体如下: | | |
| 添加字段 | 在日志里自定义添加字段和字段值  添加字段:自定义添加字段名和字段值,将添加到每条日志里 添加字段:自定义添加字段名和字段值,将添加到每条日志里 |
| 丢弃字段 | 可配置丢弃字段,原始日志里的字段将被丢弃  丢弃字段:自定义丢弃字段,所配置的字段将会丢弃 丢弃字段:自定义丢弃字段,所配置的字段将会丢弃 |
(2)主机和容器方式DSL函数配置
支持配置DSL函数自定义组合进行日志清洗、结构化、过滤等,具体函数语法请查看 数据加工函数

(3)自定义数据源Syslog处理配置
自定义数据源syslog方式可对content字段进行进一步的处理配置,具体解析处理方式如下:
-
解析失败上传:
- 解析日志类型选择具体解析日志协议类型时显示该项
- 开启解析失败上传开关可在解析失败时将默认把失败日志上传到content字段,如关闭解析失败上传开关,则表示解析失败时丢弃日志
-
content字段解模式:不解析,json解析,分隔符解析,完全正则解析,kv解析
- 不解析:用于采集并传输原始日志数据,不对数据做解析。
- JSON模式:用于采集JSON格式的日志数据,支持嵌套JSON的解析。
- 分隔符模式:根据指定分隔符把数据进行解析成JSON格式。支持空格、制表符、竖线、逗号作为分隔符,并且支持用户自定义分隔符,自定义格式没有限制,解析出来的数据作为Value值显示在“解析结果”中,用户需要给Value值输入自定义的Key。
- 完全正则模式:输入一条样例日志数据,再输入正则表达式,点击“解析”按钮,会根据输入的正则表达式解析样例日志数据,解析出来的数据作为Value值显示在“解析结果”中,用户需要给Value值输入自定义的Key。
- 完全正则模式一般具备较高的灵活性,可以解析提取一些日志打印不太规范的场景,但是会对日志解析性能会有一定的影响,尤其是非常复杂的正则表达式,在日志量非常大的场景中需要谨慎使用这种方式,以避免因数据解析性能不够产生数据投递延迟,以下通过一个具体的解析示例帮助理解完全正则模式的使用方式

1上文中原始日志:
22023-08-23T05:54:55,305 [WARN ][com.baidu.bls.Test.java] [12345678-192.168.0.1] took[15.9ms],source[{"size":1000,"query":{"bool":{"must":[{"term":{"deleted":{"value":false,"boost":1.0}}}],"adjust_pure_negative":true,"boost":1.0}}}],id[]
3
4正则表达式:
5(\S+)\s\[([A-Z]+\s+)\]\[(\S+)\]\s+\[(\d+)-(\d+.\d+.\d+.\d+)\]\s+took\[(\d+\.*\d*)ms\],source(.*)
6
7匹配过程如下:
81. (\S+) 为第1个捕获组匹配非空白字符串,会匹配上原文中的time字段2023-08-23T05:54:55,305
92. \s\[ 匹配一个空白字符和一个[中括号
103. ([A-Z]+\s+) 为第2个捕获组,捕获大写字母构成的单词,会匹配上原文的level字段WARN
114. \]\[ 紧接着匹配一个]和[
125. (\S+) 为第3个捕获组,匹配非空白字符串,会匹配上原文中的source字段com.baidu.bls.Test.java
136. )\]\s+\[会匹配]和[以及中间可能存在的多个空白字符串
147. (\d+) 为第4个捕获组,捕获1到多个数字,会匹配上原文的app_id字段12345678
158. -是匹配app_id字段和host_ip字段之间的连接符
169. (\d+.\d+.\d+.\d+) 为第5个捕获组,不过IPv4地址为原文的host_ip字段
1710. \]\s+took\[ 匹配]、多个空白字符一个took单词和[
1811. (\d+\.*\d*)ms 为第6个捕获组,会匹配原文的毫秒耗时,但是去掉单位便于做float数值分析
1912. \],source 匹配],source部分
2013. (.*)为第7个捕获组,匹配0到多个任意换行符以外的字符,作为detail字段
21经过上述13步的匹配,就能够将原文中格式不太规范的日志字段信息提取出来- 日志时间:支持选择“使用日志时间”、“使用系统时间”,若选择“使用日志时间”,则会尝试解析日志中的时间信息,并以此作为日志时间;选择“使用系统时间”,则日志时间为日志上传时的系统时间。
- 指定时间字段Key名称:若上文选择“使用日志时间”,您需指定解析结果中的一个字段作为时间字段,否则将使用系统时间作为日志时间。
- 时间解析格式:若上文选择“使用日志时间”,并指定了解析结果中的一个字段作为时间字段,您需提供该字段时间解析格式,系统将按照该格式解析日志时间,如果解析失败则使用系统时间作为日志时间。 格式书写可以参考此链接:SimpleDateFormat。 以下列出几种常见的时间解析格式:
| 时间样例 | 解析格式 |
|---|---|
| 2021-07-04 08:56:50 | yyyy-MM-dd HH:mm:ss |
| 2021-07-04 08:56:50.123 | yyyy-MM-dd HH:mm:ss.SSS |
| 2001-07-04T12:08:56.235-07:00 | yyyy-MM-dd'T'HH:mm:ss.SSSXXX |
| 2001-07-04T12:08:56.235-0700 | yyyy-MM-dd'T'HH:mm:ss.SSSZ |
| 010704120856-0700 | yyMMddHHmmssZ |
| Wed, 4 Jul 2001 12:08:56 -0700 | EEE, d MMM yyyy HH:mm:ss Z |
- 丢弃解析失败日志:开启状态,会自动丢弃解析失败的日志数据;关闭状态,日志数据解析失败时,将原始日志数据传输到下游。“不解析”模式下不支持该选项。
- 保留原文:开启后,将保留解析前的日志原文到@raw字段
-
数据匹配表达式:不填写的情况采集所有数据,填写的情况下,只采集符合表达式要求的日志数据。表达式支持的语法具体如下:
- 字段Key使用$key表示
- 逻辑运算符中,字符串类型字段支持=、!=;数值类型字段支持=、!=、>、<、>=、<=;布尔类型字段支持!;字段之间支持&&、||、(、)
- 若正则表达式中出现了运算符、括号、$等特殊符号时,则必须要使用双引号""括起来
Plain Text1示例: 2($level = "^ERROR|WARN$" || $ip != 10\.25.*) && (($status>=400) || !$flag) && $user.name = ^B.*
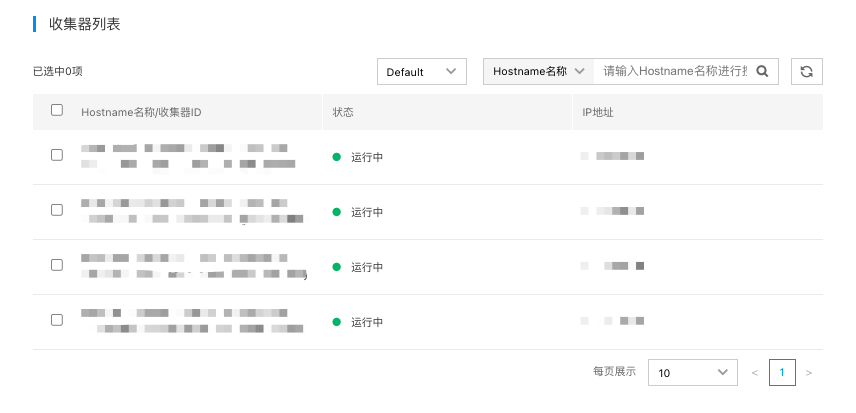
选择收集器
7.选择主机上已安装的收集器,收集器Server端会下发传输任务到已选的主机上。如下图,列表中显示当前Region已安装收集器且未处于“丢失”状态的主机。
- 点击“保存”即可完成日志传输任务的创建,约1分钟后传输任务生效。
评价此篇文章