
云端音频3A最佳实践
更新时间:2026-05-19
1. 概览
本文主要介绍:
- 云端音频3A各功能的启用、禁用方法
- 参数含义 & 参数的配置建议值
2. 需求场景
音频3A功能即:回声消除——AEC、噪声抑制——ANS、自动增益——AGC。
回声消除应对场景:设备的麦克风会拾取到扬声器播放的声音(如对话回复、音乐、故事等),导致播放内容被ASR误识别、打断正常对话或引发自问自答。
噪声抑制应对场景:环境中的嘈杂噪声会干扰ASR的识别准确率。
自动增益应对场景:当麦克风拾音能力较弱,采集到的音频音量过低时,会影响ASR的识别准确率。
3. 云端3A各功能的启用、禁用方法
创建智能体时,(请求头域见创建大模型互动实例) config字段携带如下参数(即可启用3A的全部功能,每个功能还有详细参数,可根据需求配置):
JSON
1{
2 "cloud_3A_url": {
3 "AEC": {
4 "enable": true,
5 "enhanced": true
6 },
7 "ANS": {
8 "enable": true
9 },
10 "AGC": {
11 "enable": true
12 }
13 }
14}3.1. 不做传参配置、服务端的默认值是:
- 回声消除——AEC:禁用
- 噪声抑制——ANS:启用
- 自动增益——AGC:禁用
3.2. 单独配置一个功能
cloud_3A_url的任何一个参数都可以缺省配置,只要保证json格式正确即可,例如:
关闭ANS:
JSON
1{
2 "cloud_3A_url": {
3 "ANS": {
4 "enable": false
5 }
6 }
7}4. 完整参数、含义、参考值、取值范围
完整的cloud_3A_url:
JSON
1{
2 "cloud_3A_url": {
3 "AEC": {
4 "enable": false,
5 "enhanced": true,
6 "audiobm": 100
7 },
8 "ANS": {
9 "enable": true,
10 "preMode": "N",
11 "midGainDb": 0,
12 "dfLimitDb": 75
13 },
14 "AGC": {
15 "enable": false,
16 "maxVolume": 60,
17 "extraGain": 0
18 }
19 }
20}| 3A功能 | 功能参数 | 类型 | 描述 | 参考值 | 取值范围 |
|---|---|---|---|---|---|
| AEC | enable | bool | 是否启用回声消除 | false | true/false |
| AEC | enhanced | bool | 是否启用基于模型的回声消除方案 | false | true/false |
| AEC | audiobm | int | 端侧的播放音频的缓冲区大小(ms) | 100 | [0, 2000] |
| ANS | enable | bool | 是否启用噪声抑制 | true | true/false |
| ANS | preMode | string | 前置线性降噪算法的抑制模式(禁用/低/中/高/极高),不配置preMode则默认禁用 | L | N/L/M/H/VH |
| ANS | midGainDb | float | 若启用前置线性降噪算法,可选择是否附加一次固定的数字增益(单位db)。不设置midGainDb或设置为0,则不做增益。(前置线性降噪算法+固定增益的目的是『尽可能在恶劣噪声场景中提高信噪比、有利于后续降噪』) | 0 | [0.0, 15.0] |
| ANS | dfLimitDb | float | 模型降噪的抑制强度:该值越大,则能应对更嘈杂的环境,但也可能对人声造成损伤。 | 75.0 | [0.0, 95.0] |
| AGC | enable | boo | 是否启用自动增益 | false | true/false |
| AGC | maxVolume | int | 自动增益后的峰值音量上限。 | 60 | [1,100) |
| AGC | extraGain | Double | 在自动增益后施加额外的固定增益。单位是db | 0 | [0,3) |
5. 场景与参数配置示例
5.1. 回声消除

『云端回声时延』 = 『云端编码下发音频 -> 网络传输 -> 端侧解码播放音频 -> 麦克风采集 > 编码上传音频 -> 网络传输 -> 云端解码音频』的耗时。
这个过程可以划分为两大部分:端侧音频时延 + 非端侧音频时延。非端侧主要是网络传输。
当前建议启用enhanced。
因此,需根据设备具体情况做调整的只有一个参数:audiobm——端侧设备的播放缓冲区大小。
例如,端侧设备的缓存buffer可以累积500ms的播放音频帧,则:
JSON
1{
2 "cloud_3A_url": {
3 "AEC": {
4 "enable": false,
5 "enhanced": true,
6 "audiobm": 500
7 }
8 }
9}5.2. 噪声抑制
- 默认配置(仅开启模型降噪、最大抑制量75db)
JSON
1{
2 "cloud_3A_url": {
3 "ANS": {
4 "enable": true
5 }
6 }
7}该配置与服务端的默认配置相同,即:
Plain Text
1* 禁用前置线性降噪算法
2* 启用基于降噪模型的噪声抑制功能,最大抑制量dfLimitDb=75- 启用前置线性降噪算法+模型降噪
JSON
1{
2 "cloud_3A_url": {
3 "ANS": {
4 "enable": true,
5 "preMode": "M",
6 "dfLimitDb": 30
7 }
8 }
9}该配置是将两个降噪算法级联使用,即
Plain Text
1* 启用前置线性降噪算法,抑制模式为『中等』。preMode可配置为L/M/H/VH,对应:低/中/高/极高
2* 启用基于降噪模型的噪声抑制功能,最大抑制量dfLimitDb=30- 启用前置线性降噪算法+固定数字增益+模型降噪
JSON
1{
2 "cloud_3A_url": {
3 "ANS": {
4 "enable": true,
5 "preMode": "M",
6 "midGainDb": 6,
7 "dfLimitDb": 30
8 }
9 }
10}该配置是将两个降噪算法级联使用,即
Plain Text
1* 启用前置线性降噪算法,抑制模式为『中等』。preMode可配置为L/M/H/VH,对应:低/中/高/极高
2* 前置线性降噪算法完成后,执行固定的数字增益算法,增益6db(约等于音量*2)
3* 启用基于降噪模型的噪声抑制功能,最大抑制量dfLimitDb=305.3. 自动增益
注意:
- 如果环境嘈杂,则很难实现中远距离对话的自动增益(因为人声小、环境噪声大,已经在降噪过程中被抹掉了)
- 建议自动增益和噪声抑制搭配使用,即不要单独开启自动增益。
下面是常见场景和建议值:
- 近距离对话(1m内)、麦克风收音效果较差:
JSON
1{
2 "cloud_3A_url": {
3 "ANS": {
4 "enable": true
5 },
6 "AGC": {
7 "enable": true,
8 "maxVolume": 60,
9 "extraGain": 0
10 }
11 }
12}- 中距离对话(1-2m):
JSON
1{
2 "cloud_3A_url": {
3 "ANS": {
4 "enable": true
5 },
6 "AGC": {
7 "enable": true,
8 "maxVolume": 70
9 "extraGain": 0
10 }
11 }
12}3 远距离对话(2m外):
JSON
1{
2 "cloud_3A_url": {
3 "ANS": {
4 "enable": true
5 },
6 "AGC": {
7 "enable": true,
8 "maxVolume": 70
9 "extraGain": 1
10 }
11 }
12}6. 处理结果示例图
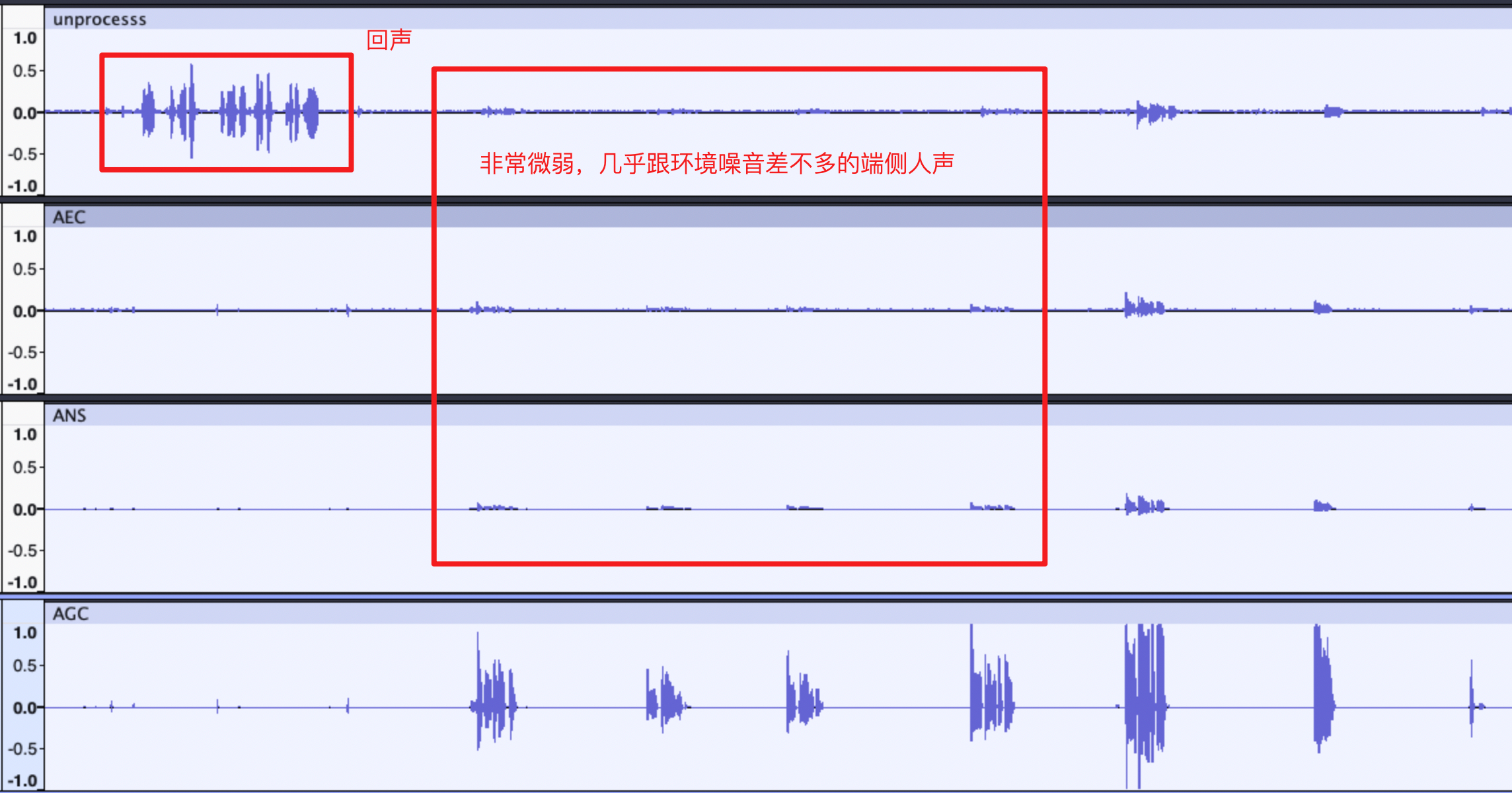
6. 注意事项
-
回声消除:
- 建议配合
dfda=true使用,效果更稳定。 - 若在语音回复刚开始或刚结束时抢问,发现 ASR 识别出现吞字现象,这大概率与回声消除有关。建议减小
tts_end_delay_ms参数值来优化此问题(如条件允许,请设置为tts_end_delay_ms=10)。 - 如需开启『TTS/云播放音频加速下发』的功能,则 必须 为
audiobm配置对应的值。 audiobm可联系开发人员查看云端日志,迭代给出最合适的值。
- 建议配合
- 在自动增益中,为避免过度增益、削峰失真,建议maxVolume不超过90、非必要不启用extraGain。
评价此篇文章