
基于RTOS SDK实现拍学机
概览
本文主要介绍如何基于RTOS SDK(视频版本, 以下提及的RTOS SDK均为支持视频版本)实现拍学机功能开发;
开发准备
需求场景
拍学机的核心功能需求一般包含 AI对话、拍图识物、拍图问、答、拍图识字、拍照成画、拍图物效等几个部分。 其中:
- AI对话:指基本的大模型实时语音交互;
- 拍图识物:指拍图识别后,大模型理解并描述图片内容,单次交互;
- 拍图问答:指拍图识别后, 用户可针对图片内容进行多轮问答交互;
- 拍图识字:指拍图识别后, 大模型根据prompt要求返回图中物体的中英文读音、拼音、释义、例句等信息;TTS仅对中英文物体名称、单词进行一次播报,用户点击可再次播报,内容详情则进行屏幕展示, 如 :

- 拍照成画:拍图上传后,用户可通过按钮切换不同的风格, 包括:涂鸦、卡通、写真、3D;
- 拍照物效:与拍照成画基本相同,物效主要针对人像生成不同的特效;
方案实现
当前,可基于RTOS SDK 实现全部的拍学机功能,具体实现方式如下。
AI对话
当前的RTOS 大模型实时互动方案即可实现基本的AI 语音对话功能;
拍图识物
可基于视觉理解+图片模式即可实现该功能。
- 相关接口说明:
- 更新视觉理解模式
1/**
2 * @brief 更新视觉理解模式
3 * @param engine engine 实例指针
4 * @param mode 0:图片模式, 适合单次图片识别; 1:视频流模式,适合持续的视觉理解;
5 */
6void baidu_chat_agent_engine_update_visual_mode(BaiduChatAgentEngine *engine, const int mode);- 图片发送接口,可使用该接口发送一帧jpeg图片, 图片理解时, 一般先向服务端发送一张图片, 然后再发送图片识别的query;
1/**
2 * @brief 向 AI Agent Server发送一帧jpeg图片数据
3 * @param engine engine 实例指针
4 * @param data 一帧jpeg图片数据
5 * @param len 数据长度
6 */
7void baidu_chat_agent_engine_send_video(BaiduChatAgentEngine* engine, const uint8_t* data, size_t len);- 视觉图片请求回调, 若服务端在收到图片识别query时没有接收到图片, 则服务端会通过该回调请求端侧发送一张图片。
1void (*onVisionImageRequest)(void);- 服务端接收图片回调
1void (*onVisionImageAck)(const char* name);- 实现流程
- 初始化
1// 1. 定义智能体创建config , 配置 enable_visual 为true
2#define JSON_CONFIG_TEMPLATE_VISUAL "{\"app_id\": \"%s\", \"config\" : \"{\\\"llm\\\" : \\\"%s\\\", \\\"llm_token\\\" : \\\"no\\\", \\\"enable_visual\\\" : \\\"%s\\\", \\\"dfda\\\" : \\\"true\\\",\\\"remote_music_player\\\" : \\\"true\\\", \\\"rtc_ac\\\": \\\"pcmu\\\", \\\"lang\\\" : \\\"%s\\\"}\", \"quick_start\": true}"
3
4static bool g_enable_visual = true; // true: 视觉理解模式(依赖开启视频), 与图片生成模式互斥; false: 普通语音交互模式(默认)
5static bool g_vision_mode = VISION_MODE_IMAGE; // VISION_MODE_IMAGE :视觉理解图片模式; VISION_MODE_STREAM 视觉视频流模式 (默认)
6static bool g_enable_image_generate = false; // 开启图片生成模式(默认开启),依赖开启视频。与视觉理解模式互斥;
7...
8
9void brtc_init(void)
10{
11 BaiduChatAgentEvent events = {
12 .onError = onErrorCallback,
13 .onCallStateChange = onCallStateChangeCallback,
14 .onConnectionStateChange = onConnectionStateChangeCallback,
15 .onUserAsrSubtitle = onUserAsrSubtitleCallback,
16 .onFunctionCall = onFunctionCall,
17 .onMediaSetup = onMediaSetup,
18 .onAIAgentSubtitle = onAIAgentSubtitle,
19 .onAIAgentSpeaking = onAIAgentSpeaking,
20 .onAudioPlayerOp = onAudioPlayerOp,
21 .onAudioData = onAudioData,
22 .onVideoData = onVideoData,
23 .onLicenseResult = onLicenseResult,
24 .onVisionImageRequest = onVisionImageRequest, // 设置视觉图片请求回调
25 .onVisionImageAck = onVisionImageAck, // 设置服务端接收图片回调
26 .onMediaGenerateResult = onMediaGenerateResult, // 设置图片生成结果回调
27 };
28
29 AgentEngineParams agentParams;
30 memset(&agentParams, 0, sizeof(agentParams));
31 setUserParameters(&agentParams);
32 // 初始化
33 int result = baidu_chat_agent_engine_init(engine, &agentParams);
34 ...
35 baidu_chat_agent_engine_call(engine);
36}
37
38int sendGenerateAIAgentCall() {
39 char config_data[MAX_PARAM_LENGTH] = {0};
40 // 视觉理解与图片生成都需要开启视频功能
41 snprintf(config_data, sizeof(config_data), JSON_CONFIG_TEMPLATE_VISUAL,
42 g_appid, DEFAULT_BRTC_LLM, (g_enable_visual || g_enable_image_generate) ? "true": "false", DEFAULT_BRTC_LANG);
43
44 char request_url[MAX_PARAM_LENGTH] = {0};
45 snprintf(request_url, sizeof(request_url), "%s/generateAIAgentCall", g_platform_host);
46 return http_post(request_url, config_data, &call_resp);
47}拍图问答
基于视觉理解+视频流模式即可实现该功能。 其实现方法与上述拍万物拍图识物基本相同,主要不同在于:
- 对话状态下, 调用
baidu_chat_agent_engine_update_visual_mode(engine, VISION_MODE_STREAM)设置视频流模式; - 调用
baidu_chat_agent_engine_send_video(g_engine, data, len)周期性发送图片, 建议 1000ms 采集、发送发一张图片, 过高的图片发送频率可能造成视觉模型tokens的过度消耗; - 视频流模式下,视觉模型处理持续进行, 可随时发出图片识别query;
拍图识字
拍图识字功能实际也是视觉的一种应用, 只不过, 相对于普通的图片识别,拍图识字有两点特殊要求:
- 需要对模型输出的内容进行定义,指定其输出识字卡片形式;
- 模型输出的内容有涉及需要TTS报播的, 也有不需要报播的(如释义部分,用户只需要上屏显示即可, 不需要报播 ); 这两个需求, 可以分别通过RTOS SDK 提供的视觉prompt自定义更新及标签功能进行实现; 具体实现方式如下:
- 视觉模型prompt自定义更新
默认的视觉模型prompt 只能对图片进行基本的识别、理解,针对于识字场景, 则需要更新视觉模型prompt, SDK提供相应的接口对视觉模型prompt进行更新。 涉及接口:
1/**
2 * @brief 向 AI agent server 发送事件消息, 自定义的视觉prompt通过该接口发送
3 * @param engine engine 实例指针
4 * @param event 事件消息字符串
5 */
6void baidu_chat_agent_engine_send_event_to_agent(BaiduChatAgentEngine* engine, const char* event);使用方式参考:
1// 1. 自定义拍图识字视觉prompt, 可参考这个修改自定义的prompt, 注意转义符号;
2static const char* object_vision_prompt =
3 "# 你是一位资深的早教老师,每次会收到一张来自幼儿园或小学生的物品照片。请识别照片中的物品并输出它的中文汉字和英文单词名称及如字典一样详细的中英文释义。\\\\n\\\\n"
4 "## 中文释义要求:\\\\n"
5 "1. 根据<汉字>进行回答\\\\n"
6 "2. 回答<汉字>的笔画数量,格式:`strokenumber:{number}`\\\\n"
7 "3. 回答<汉字>的偏旁部首,格式:`radical:{word}`\\\\n"
8 "4. 按次序提供<汉字>的不同词义,并为每个词义提供1~2个包含该汉字的词语\\\\n"
9 "5. 保证内容简洁明了,易于低龄学生理解\\\\n\\\\n"
10 "## 英文释义要求:\\\\n"
11 ... ...
12 "树。\\\\n"
13 "tree。\\\\n"
14 "((CUSTOM:\\\\n"
15 "{\\\\n"
16 " \\\\\\\"name_ch\\\\\\\": \\\\\\\"花\\\\\\\",\\\\n"
17 " \\\\\\\"name_en\\\\\\\": \\\\\\\"flower\\\\\\\",\\\\n"
18 " \\\\\\\"comments_ch\\\\\\\": {\\\\n"
19 " \\\\\\\"name\\\\\\\": \\\\\\\"花\\\\\\\",\\\\n"
20 " \\\\\\\"strokenumber\\\\\\\": 7,\\\\n"
21 " \\\\\\\"radical\\\\\\\": \\\\\\\"艹\\\\\\\",\\\\n"
22 " \\\\\\\"comment\\\\\\\": \\\\\\\"1. 种子植物的有性繁殖器官,由花瓣、花萼、花托、花蕊组成。词语:一朵花。\\\\\\\\\\\\n2. 可供观赏的植物。词语:花草。\\\\\\\",\\\\n"
23 " \\\\\\\"example_sentence\\\\\\\": \\\\\\\"学校里种了许许多多五颜六色的花。\\\\\\\"\\\\n"
24 " },\\\\n"
25 ... ...
26 "}\\\\n"
27 "))\\\\n\\\\n"
28 "## 请按以下格式应答:\\\\n"
29 "<汉字>:{识别出的中文名称}。\\\\n"
30 "<单词>:{识别出的英文名称}。\\\\n"
31 "((CUSTOM:\\\\n"
32 "{\\\\n"
33 " \\\\\\\"name_ch\\\\\\\": \\\\\\\"{中文名称}\\\\\\\",\\\\n"
34 " \\\\\\\"name_en\\\\\\\": \\\\\\\"{英文名称}\\\\\\\",\\\\n"
35 " \\\\\\\"comments_ch\\\\\\\": {\\\\n"
36 " \\\\\\\"name\\\\\\\": \\\\\\\"{中文名称}\\\\\\\",\\\\n"
37 " \\\\\\\"strokenumber\\\\\\\": {笔画数},\\\\n"
38 " \\\\\\\"radical\\\\\\\": \\\\\\\"{偏旁部首}\\\\\\\",\\\\n"
39 " \\\\\\\"comment\\\\\\\": \\\\\\\"{详细释义}\\\\\\\",\\\\n"
40 " \\\\\\\"example_sentence\\\\\\\": \\\\\\\"{示例句子}\\\\\\\"\\\\n"
41 " },\\\\n"
42 ... ...
43 "}\\\\n"
44 "))";
45
46static char visual_prompt_text[4096];
47// 2. 视觉prompt 更新消息格式定义,注意括号内为 \\\ 三斜扛转义;
48static const char g_updata_vision_prompt_cmd[] = "%s{\\\"model_type\\\":\\\"%s\\\",\\\"prompt\\\":\\\"%s\\\"}";
49
50void update_vision_prompt(char *prompt) {
51 int prompt_len = prompt ? strlen(prompt) : 0;
52 int total_len = prompt_len + strlen(g_updata_vision_prompt_cmd) + 64;
53 char *update_prompt_cmd = (char *)custom_malloc_psram(total_len);
54
55 if (update_prompt_cmd) {
56 snprintf(update_prompt_cmd, total_len, g_updata_vision_prompt_cmd,
57 AGENT_EVENT_UPDATE_SYSTEM_PROMPT, "2", prompt);
58 } else {
59 os_printf("update_vision_prompt malloc failed\r\n");
60 return;
61 }
62 strncpy(visual_prompt_text, update_prompt_cmd, sizeof(visual_prompt_text) -1);
63 custom_free_psram(update_prompt_cmd);
64}
65
66void agent_update_prompt(void * text) {
67 baidu_chat_agent_engine_send_event_to_agent(g_engine, (char *)text);
68}
69
70// 3. 更新视觉prompt, 2: 更新视觉prompt; 0: 为恢复系统默认视觉prompt; 注意:退出识字场景后需要恢复系统默认prompt;
71void update_prompt(const char *prompt_mode) {
72 int mode = os_atoi(prompt_mode);
73 os_memset(visual_prompt_text, 0, sizeof(visual_prompt_text) -1);
74 if (mode == 2) {
75 update_vision_prompt(object_vision_prompt);
76 } else if (mode == 0) {
77 // reset vision prompt
78 update_vision_prompt("");
79 }
80
81 os_printf("update prompt text:%s\r\n", visual_prompt_text);
82 os_task_create("brtc_task_update_prompt", agent_update_prompt, (void*)visual_prompt_text, OS_TASK_PRIORITY_NORMAL, 0, NULL, 16 * 1024);
83}
84
85
86// 4. 调用视觉prompt更新
87update_prompt(param);
88
89// 5. 发出图片识别query (“如:图片中是什么, 可以语音说出也可以使用接口发送text文本”)之后, 模型会返回更新prompt后的内容如, TTS 会播报中英文 “ 猫 / cat” ,其它部分不会播报, 只会当做普通消息传递到端侧进行显示. 是的,这里的 ((CUSTOM: xxx))里的内容不会播报, 只会当前普通文本消息传递到端侧,这个则是我们接下来要介绍的标签消息功能。
1猫。
2cat。
3((CUSTOM:
4{
5"name_ch": "猫",
6"name_en": "cat",
7"comments_ch": {
8"name": "猫",
9"strokenumber":11,
10"radical":"犭",
11"comment":"1.哺乳动物,面部略圆,躯干长,耳壳短小,眼大,瞳孔随光线强弱而缩小放大,四肢较短,掌部有肉质的垫,行动敏捷,善跳跃,能捕鼠,毛柔软,有黑、白、黄、灰褐等颜色。种类很多。词语:猫腻、狸猫。\n2. 躲藏:猫冬(指躲在家里过冬)",
12"example_sentence":"我家养了一只可爱的~。",
13},
14"comments_en": {
15"name": "cat",
16"soundmark_us":"/kæt/",
17"soundmark_en":"/kæt/",
18"comment":"n. 猫; 猫科动物;\nv. 把(锚)吊放在锚架上; 钓(鱼);\nn. (Cat) (美、俄、法、德)卡特(人名)",
19"example_sentence":"The cat is sleeping on the sofa.",
20},
21}
22))- 标签功能
标签是指与大模型事先约定的、对模型输出起补充、增强、注释等意义的一些信息片段, 标签信息一般需要在大模型prompt里进行定义,然后, 模型在回复时会携带相应的标签,TTS不会对标签内容进行播报,标签内容会作为普通消息随大模型输出返回给客户端;
我们内置了若干标签在某些场景进行使用,当前开放给用户可使用的标签为CUSTOM标签,如上prompt , CUSTOM 标签格式为((CUSTOM: xxx)),RTOS SDK有单独的标签事件回调,用户可从标签事件回调获得标签消息,标签功能具体使用方式可参考标签消息。
拍照成画、物效
拍照成画、与图片物效可基于大模型实时互动方案的图生图模型进行实现,方案内置图生图模型, 配置、使用方式如下:
- 前置条件:控制台配置文生图、图生图Function Call,生图意图基于Function Call实现, 使用前在控制台针对客户自己的appid配置生图Function Call; 配置生图Function Call如下,当前不支持修改Function内容, Function名称、Function例名、Function描述、输入参数等需要按照如下定义填写;
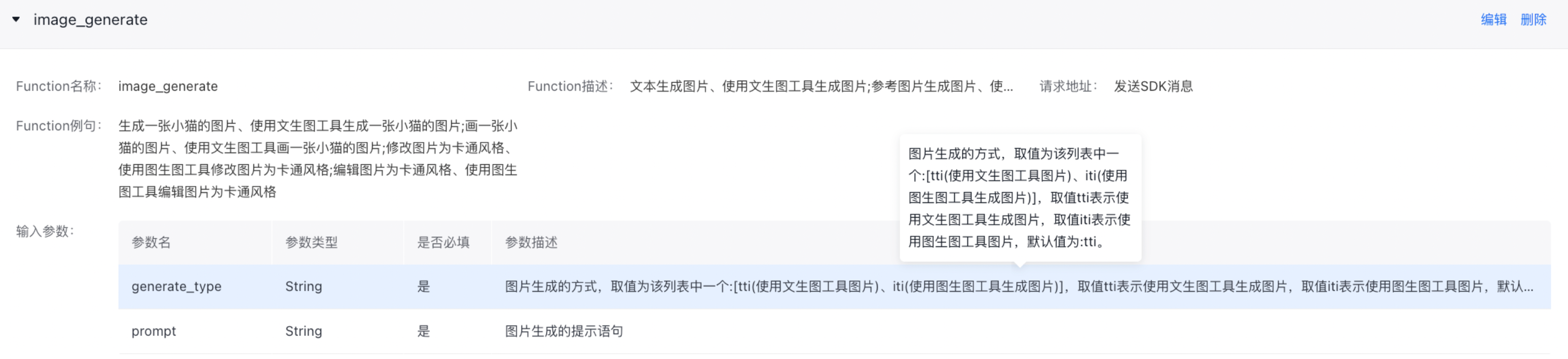
文本参考:
1 {
2 "functionName": "image_generate",
3 "functionAlias": "image_generate",
4 "promptFunctionDef": "###函数定义\n{\n \"function_name\": \"image_generate\",\n \"function_description\": \"文本生成图片、使用文生图工具生成图片;参考图片生成图片、使用图生图工具生成图片\",\n \"call_examples\": \"生成一张小猫的图片、使用文生图工具生成一张小猫的图片;画一张小猫的图片、使用文生图工具画一张小猫的图片;修改图片为卡通风格、使用图生图工具修改图片为卡通风格;编辑图片为卡通风格、使用图生图工具编辑图片为卡通风格\",\n \"parameter_list\": [\n {\n \"parameter_name\": \"generate_type\",\n \"parameter_description\": \"图片生成的方式,取值为该列表中一个:[tti(使用文生图工具图片)、iti(使用图生图工具生成图片)],取值tti表示使用文生图工具生成图片,取值iti表示使用图生图工具图片,默认值为:tti。\",\n \"parameter_type\": \"String\",\n \"required\": \"TRUE\"\n },\n {\n \"parameter_name\": \"prompt\",\n \"parameter_description\": \"图片生成的提示语句。\",\n \"parameter_type\": \"String\",\n \"required\": \"TRUE\"\n }\n ],\n \"function_schema\": {\n \"function_name\": \"image_generate\",\n \"parameter_list\": [\n {\n \"generate_type\": \"tti\"\n },\n {\n \"prompt\": \"小猫\"\n }\n ]\n }\n}\n\n",
5 "parameterList": [{"paramName":"generate_type", "required":true}, {"paramName":"prompt", "required":true}],
6 "functionDescription": "",
7 "callExamples": ""
8 }- 初始化,与拍图识物一样,智能体创建及SDK params开启视频功能;
- 模式切换,图生图功能与视觉理解不能同时使用, 使用图生图时需要视觉切换到图片模式, 同时开启图生图功能, 使用视觉理解时则需要关闭国生图功能;参考设置如下(mode 2 可适用于图生图);
1static void set_agent_mode(void *agent_mode) {
2 char *mode_str = (char *)agent_mode;
3 ...
4 int mode = os_atoi(mode_str);
5 if (mode == 0) {
6 // 普通语音交互模式;视频理解+图片模式; 适用于 普通AI对话 及 拍图识物、拍图识字
7 g_enable_visual = true;
8 g_enable_image_generate = false;
9 // 关闭文、图生图
10 baidu_chat_agent_engine_send_event_to_agent(g_engine, AGENT_EVENT_DISABLE_MEDIA_GENERATE);
11 baidu_chat_agent_engine_update_visual_mode(g_engine, VISION_MODE_IMAGE);
12 } else if (mode == 1) {
13 // 视觉理解+视频流模式; 适用于拍图问答
14 g_enable_visual = true;
15 g_enable_image_generate = false;
16 // 关闭文、图生图
17 baidu_chat_agent_engine_send_event_to_agent(g_engine, AGENT_EVENT_DISABLE_MEDIA_GENERATE);
18 baidu_chat_agent_engine_update_visual_mode(g_engine, VISION_MODE_STREAM);
19 } else if (mode == 2) {
20 // 图片生成模式;适用于文生图、图生图
21 g_enable_visual = false;
22 g_enable_image_generate = true;
23 baidu_chat_agent_engine_update_visual_mode(g_engine, VISION_MODE_IMAGE);
24 // 关闭文、图生图
25 baidu_chat_agent_engine_send_event_to_agent(g_engine, AGENT_EVENT_ENABLE_MEDIA_GENERATE);
26 }
27}- 与拍图识物一下, 调用 baidu_chat_agent_engine_send_video(g_engine, data, len)发送一张图片给大模型;(使用文生图功能则不需要发送图片)
- 发出文生图、图生图query,如, 文生图:“生成一张小猫吃鱼的图片”、“画一张小猫吃鱼的图片”; 图生图: “编辑图片为动漫风格”、“修改图片为动漫风格”; 注意,这里的query与所配置的Function Call 相关,与Function Call 不匹配的query可能影响意图识别;
- query发送若干秒后, 生图模型会返回生成的jpeg图片数据(默认分辨率为 640 * 480)及生图回调;jpeg图片可直接用于渲染上屏;涉及接口:
jpeg图片数据回调, 一次返回一帧jpeg数据:
1// 在初始化时设置回调
2BaiduChatAgentEvent events = {
3 ... ...
4 .onVisionImageRequest = onVisionImageRequest, // 设置视觉图片请求回调
5 .onVisionImageAck = onVisionImageAck, // 设置服务端接收图片回调
6 .onMediaGenerateResult = onMediaGenerateResult, // 设置图片生成结果回调
7 };
8
9void onVideoData(const uint8_t *data, size_t len, RtcImageType imgtype, int width, int height)
10{
11 BRTC_LOG("FrameReceived video data of length: %d, width: %d, height: %d\n", len, width, height);
12 if (imgtype == RTC_IMAGE_TYPE_JPEG) {
13#ifdef DUMP_VIDEO_FRAME
14 if (len > 0) {
15 char filename[64] = {0};
16 os_sprintf(filename, "0:video_frame_%04d.jpeg", (uint32_t)os_jiffies() % 9999);
17 dumpVideoFrame(filename, data, len);
18 }
19#endif
20 // render to display
21 jpeg_photo_renderer(data, len, 320, 240);
22 }
23}生图结果回调:
1void onMediaGenerateResult(const char* result) {
2 if (result && strlen(result) > 0) {
3 BRTC_LOG("onMediaGenerateResult content: %s\n", result);
4 }
5}测试验证
在完成上述接入流程后,拍学机相关功能即可全部实现, 可以跑如下测试case进行验证:
| 功能 | 测试case | 验证结果 |
|---|---|---|
| AI对话 | query: "请一个故事" | 播报一则故事 |
| 拍图识物 | 设置视觉图片模式;上传一张图片; query:"图片中是什么" | 详细描述模型所理解的图片内容 |
| 拍图问答 | 设置视觉视频流模式;持续上传图片; query:"图片中大家在干什么" 、"一共有几个人"、“有没有戴帽子的人” | 模型根据所上传的图片,与用户多轮交互,持续回答用户问题 |
| 拍图识字 | 设置视觉图片模式;更新prompt; 上传一张图片; query:"图片中是什么" | 根据用户prompt播报图片中物体的中英文名称,并接收到翻译义标签信息 |
| 拍照成画 | 设置视觉图片模式; 设置开启图片生成;上传一张图片; query:"编辑图片切换背景为星空" | 收到模型返回的星空背景的新图片 |
| 拍照物效 | 设置视觉图片模式; 设置开启图片生成;上传一张图片; query:"编辑图片为动漫风格" | 收到模型返回的动漫风格的新图片 |
至此,基于RTOS SDK的拍学机开发完成。
相关产品
评价此篇文章