
声纹使用最佳实践
(一)录入声纹
1.1 通过http接口注册声纹
本地通过音频录制软件录制音频,然后通过http接口注册声纹能力;举例使用 Audacity软件。
音频输入要求16K采样率,单声道,16位采样深度音频,并且录制音频保证只有一个人在说话,尽量保证环境安静。每个用户录制5份wav数据,要求录音不少于8秒;
可以在正式录制前,提前熟悉文本,试读几遍,防止在录制时出现停顿、错读等问题。
接口调用:api/v1/voiceprint/register url 返回声纹id信息, 由业务层进行保存声纹id。
声纹注册关联user_id, SDK默认都提供一个参数 user_id参数,用于设备关联远端声纹信息。
| SDK | 参数名称 | 链接地址 |
|---|---|---|
| Android SDK | AIAgentEngineParams#userId | 链接 |
| iOS SDK | AgentEngineParams#userId | 链接 |
| RTOS SDK | AgentEngineParams#userId | 链接 |
1.2 通话自动录入
创建智能体'api/v1/aiagent/generateAIAgentCall' url
增加参数voice_fp_url = {"firstSentenceRegistration":true,"enable":true,"interruptMode":1,"similarity":[0.2,0.28,0.3,0.41]}
'similarity' 参数可以根据自己业务情况进行调整,长度必须是4个float组成数组, 并且从小达到进行排列;
| 名称 | 类型 | 描述 | 备注 |
|---|---|---|---|
| firstSentenceRegistration | bool | 是否容许自动注册 | 是否容许自动注册声纹, 打开后自动录入前5秒有效用户说话时长音频 (自动过滤掉非说话时间音频时间) |
| enable | bool | 是否开启声纹 | true 开启声纹能力,false 关闭 |
| enableSyncWait | bool | 三方模型是否同步等待声纹结果 (最大等待时长100ms) | true 开启声纹能力,false 关闭 (默认false) |
| interruptMode | int | 0: 关闭声纹打断能力 1:打开声纹打断能力 | 仅仅响应录入声纹声纹,未录入不响应 |
| similarity | array | 相似度阈值 | 用于匹配不同长度音频阈值列表 |
声纹信息仅仅本次有效,每次创建会话都会重新录入声纹信息;
1.3 通话function-call录入
创建智能体'api/v1/aiagent/generateAIAgentCall' url
控制台增加录入声纹function-cal, 名称必须是voice_fp_add, 参数名必须是name
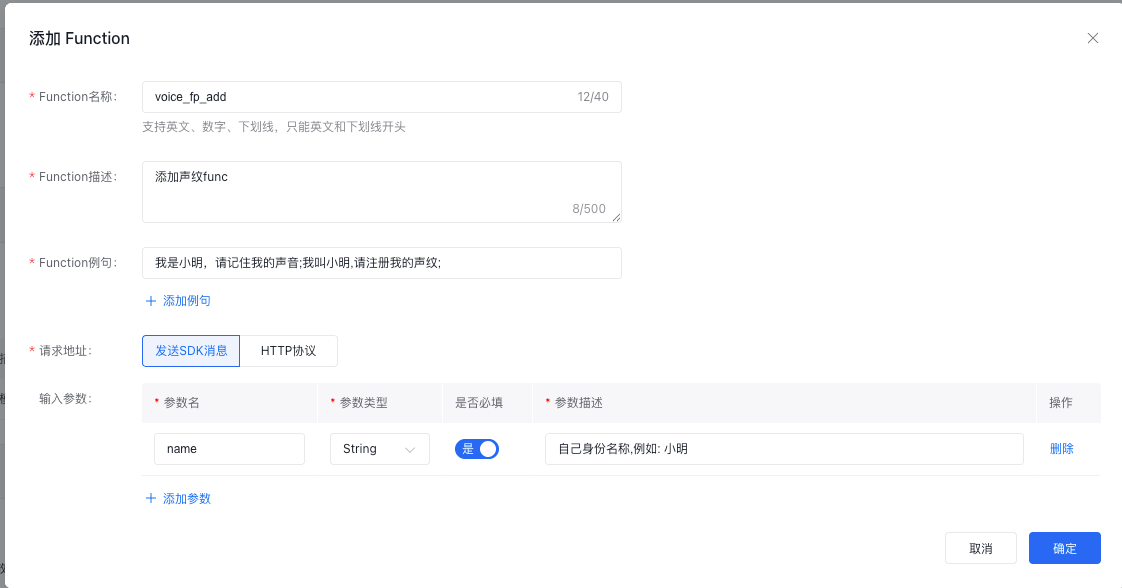
用于语音输入『我是小明,请记住我的声音』 (默认function-call会内部处理掉不会下发到SDK) 直接开始注册命中后5秒内有效用于输入音频数据。
控制台增加删除声纹function-cal, 名称必须是voice_fp_remove, 参数名必须是name
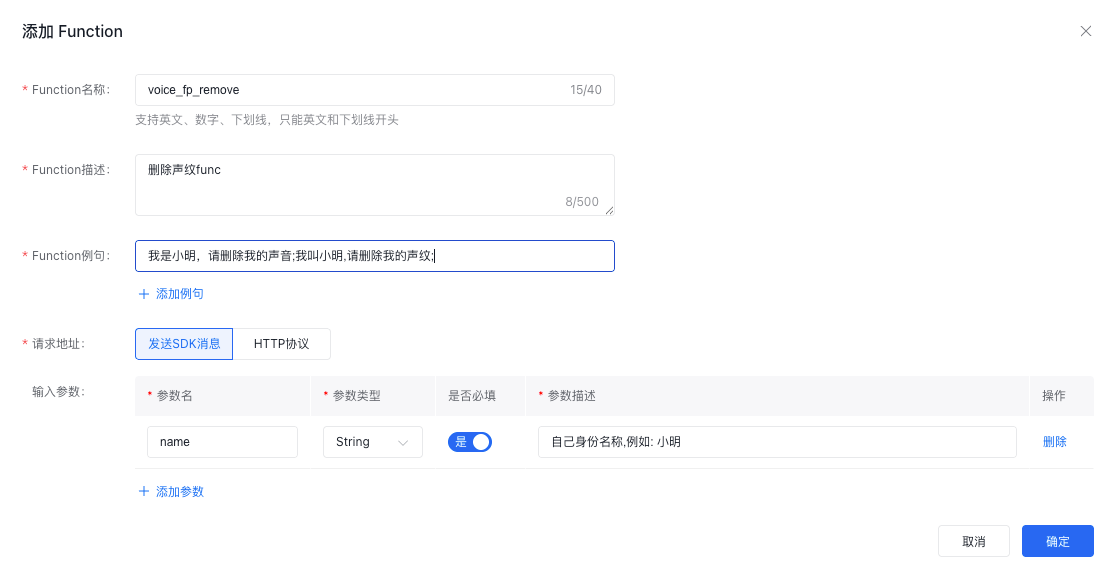
用于语音输入『我是小明,请删除我的声音』 (默认function-call会内部处理掉不会下发到SDK) 直接删除掉用户声纹信息。
(二)使用声纹
2.1 三方模型
当前支持使用三方模型,支持openAI规范, url
http header 增加扩展信息,
1
2 "ext_info" = URL.Encode("[emotion]:高兴&[nick_name]:小明")emotion: 情感识别 nick_name:声纹识别昵称 每次请求三方模型时候将当前说话人匹配出声纹对应昵称返回过去,如果当时未匹配到对应声纹 nick_name = "未知"
2.2 打断过滤
创建智能体'api/v1/aiagent/generateAIAgentCall' url
config.voice_fp_url 参数中的interruptMode = 1
音频过来后会进行声纹匹配,如果匹配失败不会进行后续大模型请求,如果匹配成功进行后续大模型请求。
打断效果可以通过 参数中的similarity 进行调整,这个是4个float组成阈值参数,可以根据场景微调对应阈值参数。
用户一次发言音频长度小于1秒用第一个值; 用户一次发言音频长度小于2秒用第二个值; 用户一次发言音频长度小于3秒用第三个值; 用户一次发言音频长度大于3秒用第四个值;
2.3 SDK回调
SDK返回 用户端ASR结果,有一个附加值包含声纹识别身份信息;
| SDK | 参数名称 | 链接地址 |
|---|---|---|
| Android SDK | void onUserAsrSubtitle(String text, boolean isFinal, Constants.ASRExtInfo info) info 包含识别身份信息 | 链接 |
| iOS SDK | - (void) onUserAsrSubtitle:(NSString )text isFinal:(BOOL)isFinal ext:(AgentAsrExtInfo _Nullable)info; info 包含识别身份信息 | 链接 |
| RTOS SDK | void (onUserAsrSubtitle)(const char text, size_t text_len, bool final, const ASRExtInfo* info); info 包含识别身份信息 | 链接 |
(三)查询和删除
注册声纹 'api/v1/voiceprint/register', url
查询声纹 'api/v1/voiceprint/list', url
删除声纹 'api/v1/voiceprint/delete', url
评价此篇文章