
智能搜推引擎V_2.3.0版本新特性
更新时间:2023-11-29
一、大模型赋能用户兴趣旅程构建
大模型在用户理解方面具有巨大的潜力,能够提供更深入的理解。我们利用聚类算法将整个物料库聚类为若干集群,每个集群代表一个兴趣簇。
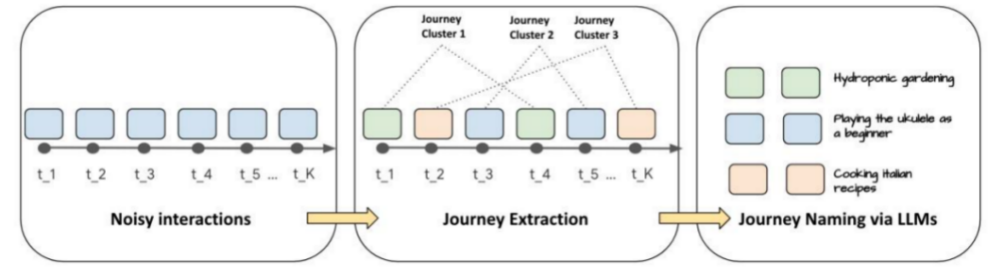
1、兴趣构建:使用LLM技术个性化提取兴趣旅程,并结合少样本提示、提示调整和微调等技术来优化模型的性能,使其能够更好地理解和总结用户的兴趣旅程。

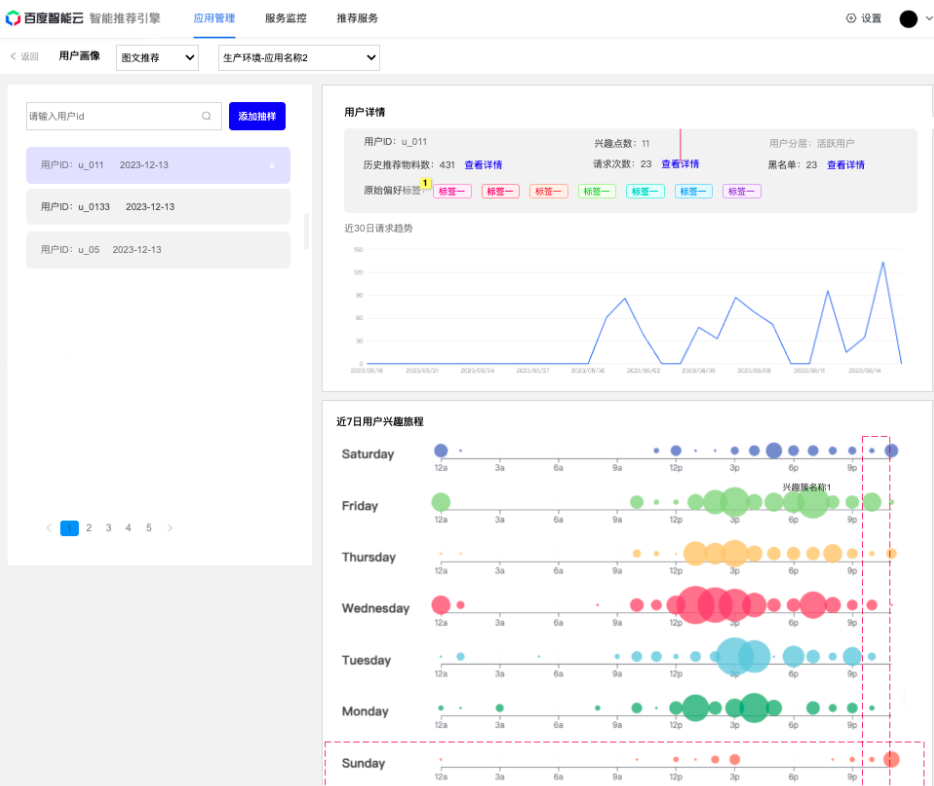
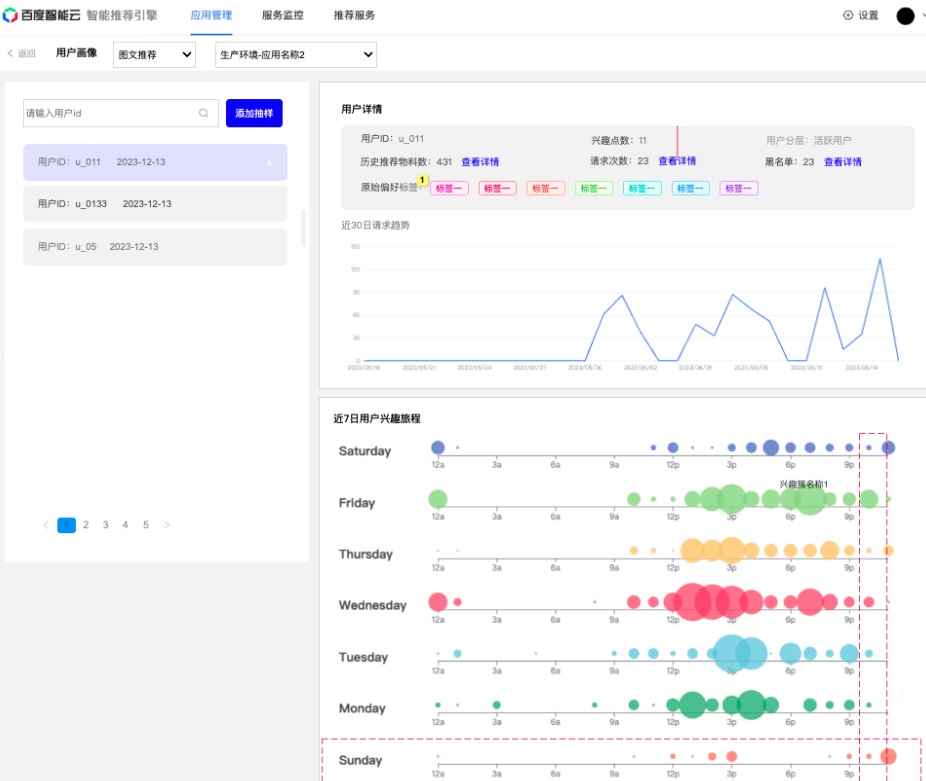
2、用户兴趣旅程:兴趣旅程提取组件将用户的历史行为映射到连贯的兴趣旅程中,同时支持查看用户兴趣点强度和查询某个兴趣点的时间变化趋势,从而挖掘用户的长短期兴趣。这有助于更好地理解用户的兴趣和行为,从而提供更深入、更可解释的用户理解。
二、运营规则升级:新增置顶和负反馈
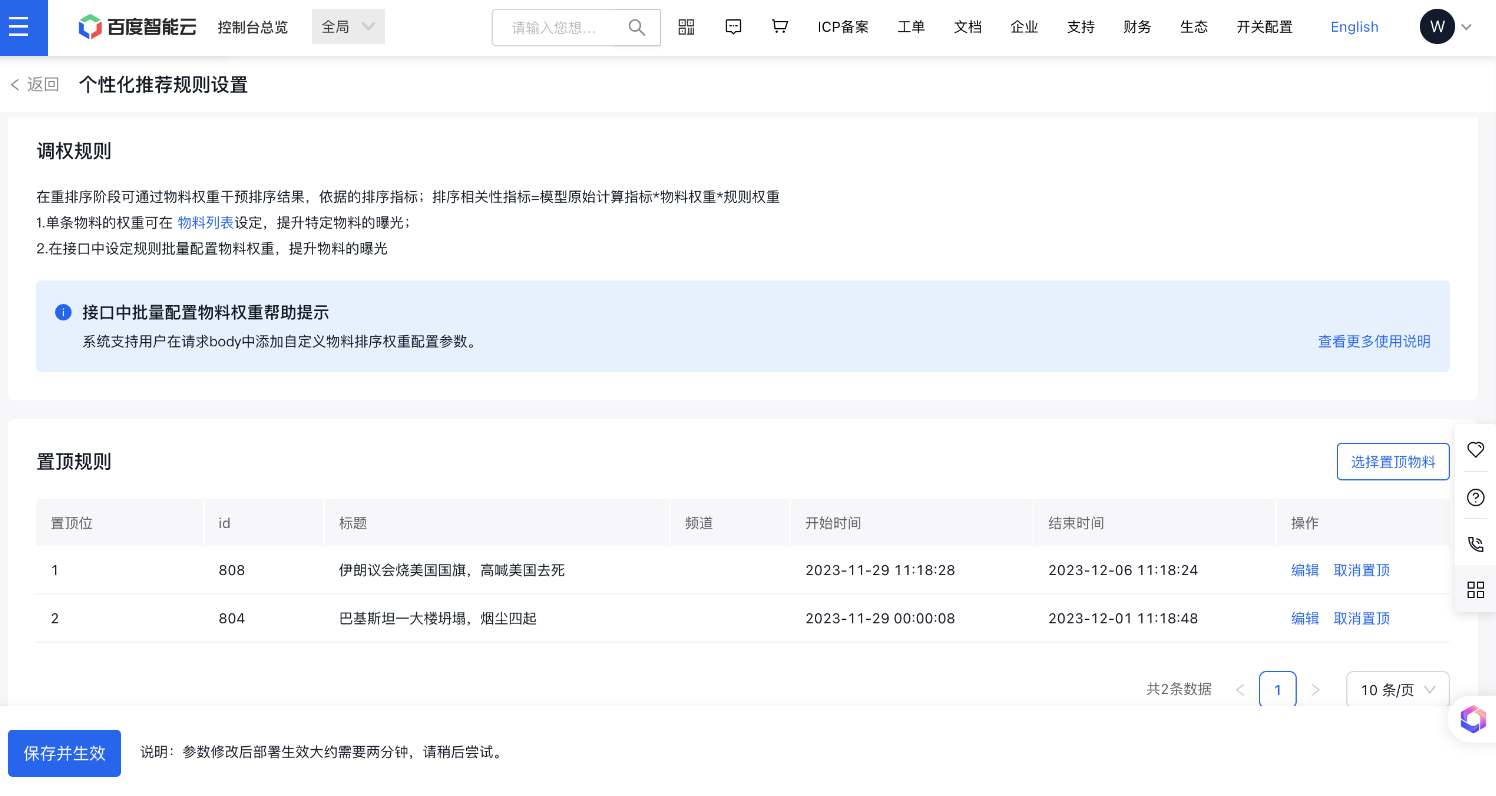
1、置顶规则:支持置顶一个或多个物料,可对物料列表中的物料进行编辑和取消置顶的操作。 能够在内容分发过程中将选定内容放置在显眼位置,以吸引更多用户关注。通过该功能,用户可以根据分发任务的需求和目标受众的特点,选择需要置顶的内容,并确保这些内容在分发过程中始终处于突出位置。
2、黑名单过滤和负反馈。行为数据增加新类型:dislike。用户可标记不喜欢或者选择:过滤标签、屏蔽作者、屏蔽类别。用户可以在推荐页面点击x按钮来添加黑名单。一旦物料被添加到黑名单中,系统将不会向用户推荐这些物料,有助于提高用户推荐的准确性和用户体验。
三、新增物料粒度的运营指标统计
支持单个物料粒度的点击数、收藏数、曝光数、点击率、点赞数和访问用户数等指标的统计和行为数据查询。
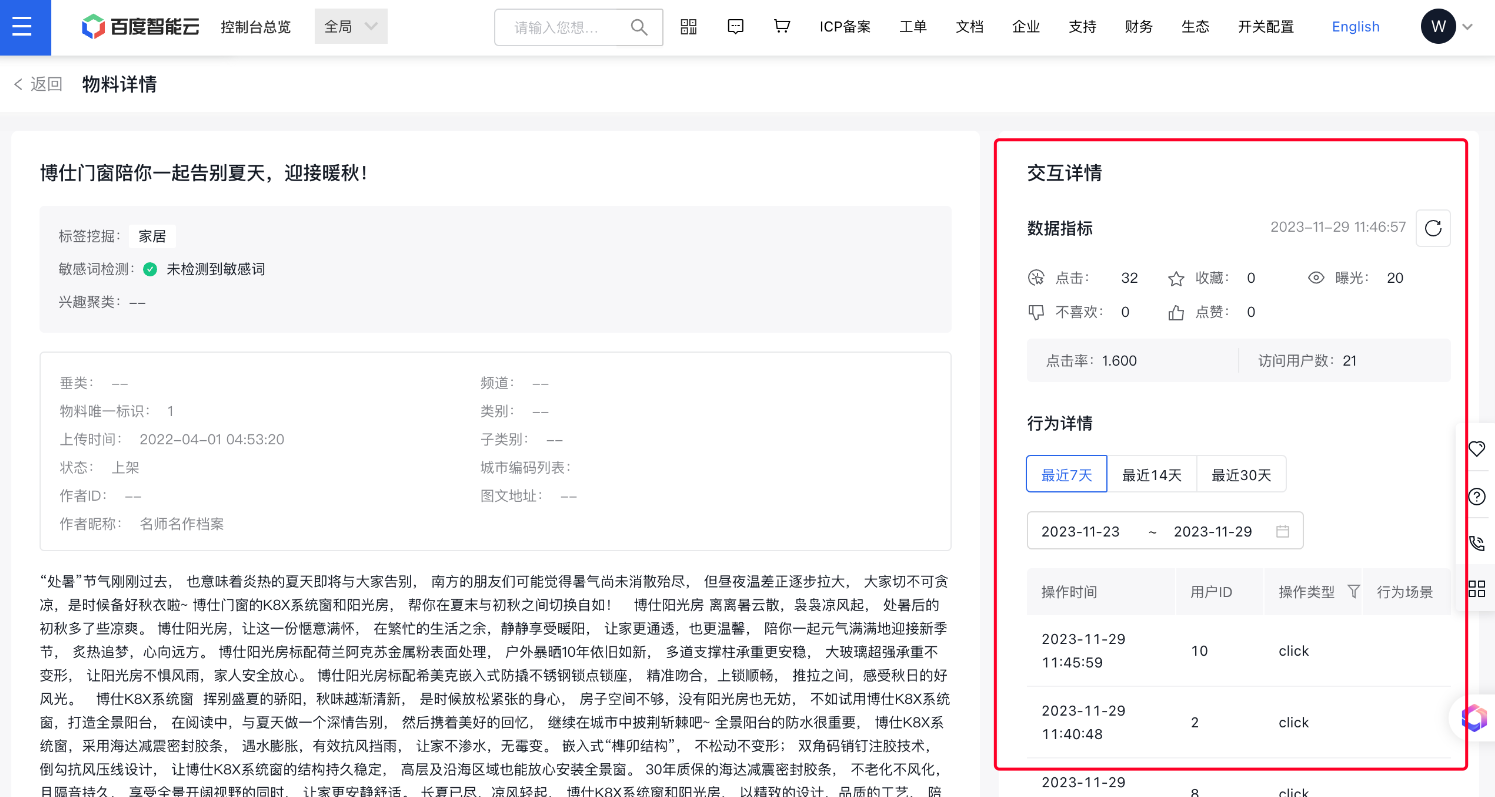
- 更好的数据驱动决策:通过详细的物料粒度数据,可以更好地了解用户的行为和喜好,从而制定更精准的运营策略。
- 提高运营效率:通过点击数、收藏数、曝光数等指标,可以评估不同物料的运营效果,从而优化运营资源分配,提高运营效率。
四、体验优化
- 推荐链路升级置顶和合并去重节点,新增快捷上一次、下一次操作。
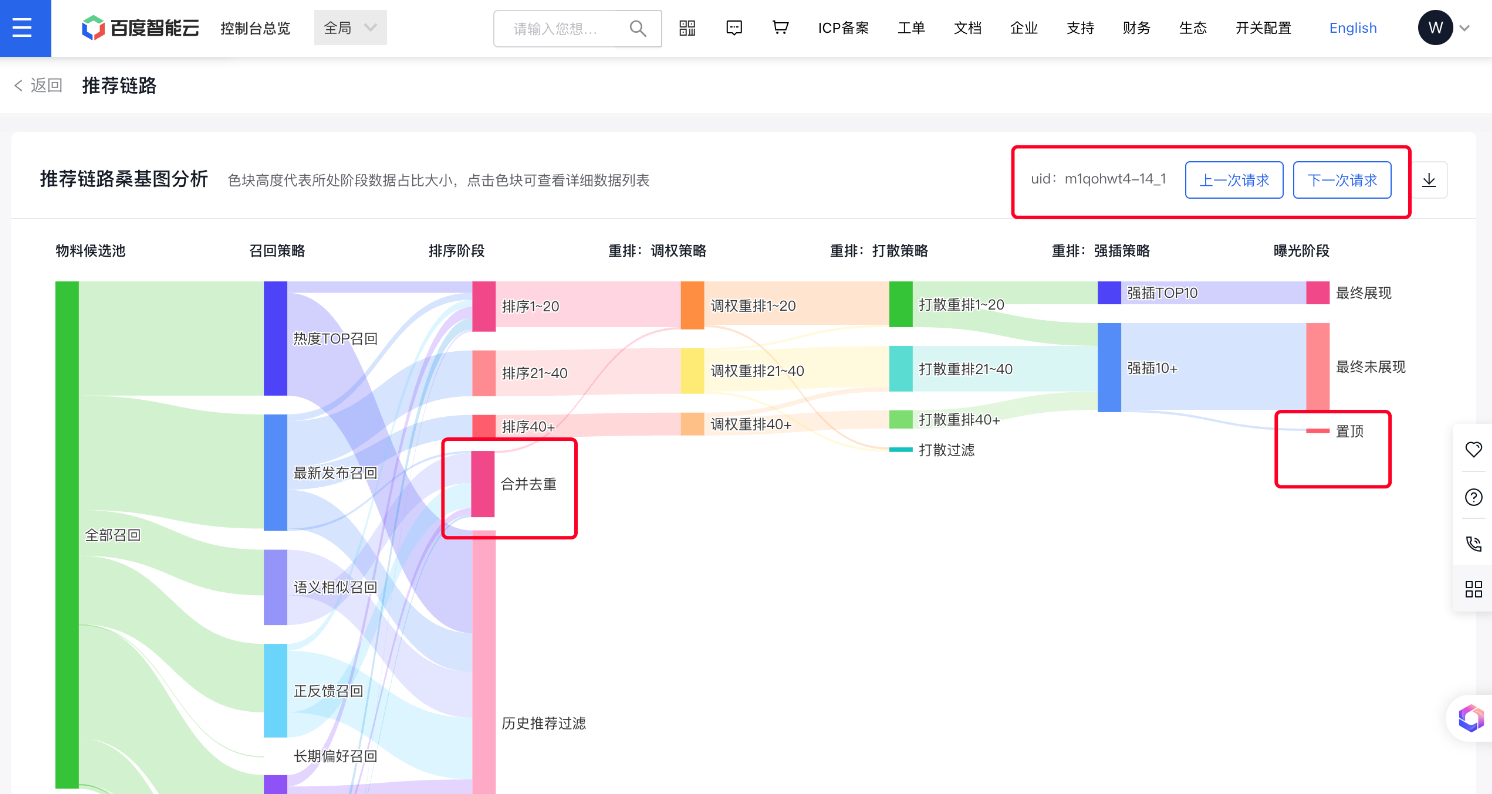
- 修复了已知的其他问题。
五、新版本预告
1.搜推一体架构升级,打造全新的推荐激发式搜索新模式。
2.数据多应用可复用,应用升级不在重复上传数据。