
内存子系统
内存子系统是操作系统的关键子模块,管理着内存的页表映射、内存的分配与回收等相关内存操作。内存类相关问题大致可分为内存泄露、内存访问越界、内存溢出等,可结合实际情况参考以下方法进行处理。
内存信息分析
内存信息分析主要针对系统整体内存资源、进程内存资源进行,了解内存的使用分布情况,为后续进一步的分析拓展方向。
- 系统内存资源分析
系统内存整体分布情况,可通过free -h获取:

其中buffers表示内核使用的buffer页,cache表示page cache和slab占用的内存。更详细的系统内存资源分布情况,可通过 /proc/meminfo文件获取:
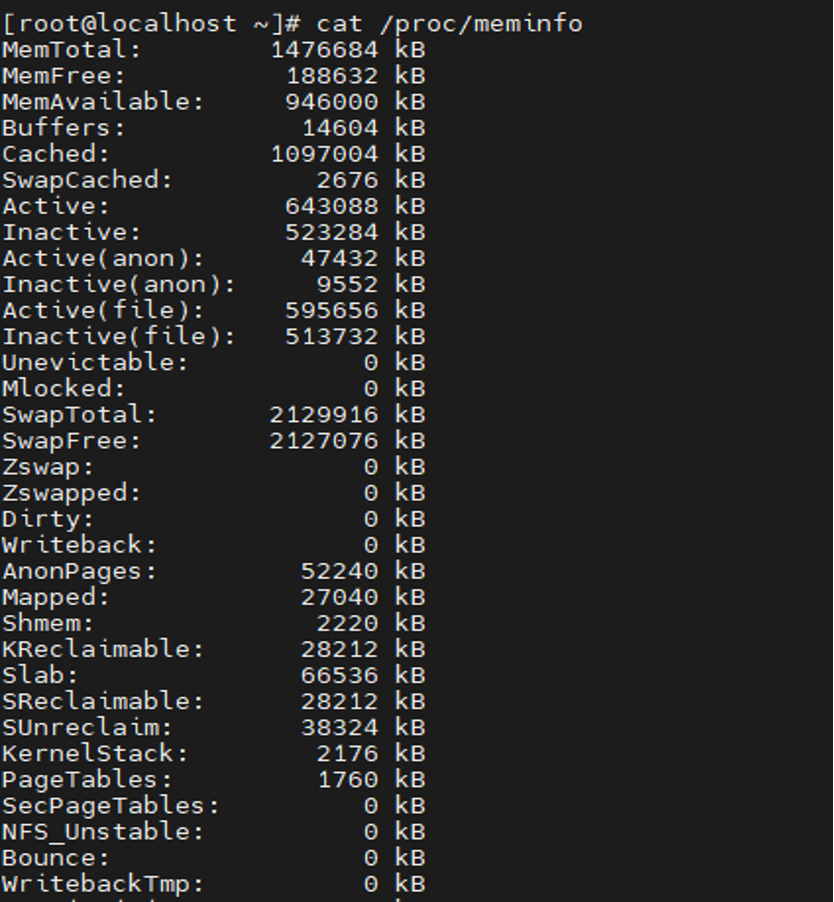
物理内存各node节点下对应zone的水位分布情况可通过 cat /proc/zoneinfo | grep -E "pages free|Node|min|low|high |managed|spanned|present|manage" 查看,该资源分析可详细定位每个Node节点下zone的内存资源使用情况。
其中,pages free代表该zone剩余的页数;low表示该zone的中间内存水位,低于该水位将唤醒kswapd线程进行内存回收;min表示最低内存水位,低于该值将进行直接内存回收,异步内存分配将被阻塞,直到回收后内存高于该水位;high表示高内存水位,当内存高于该值时kswapd线程停止内存回收,进入休眠。
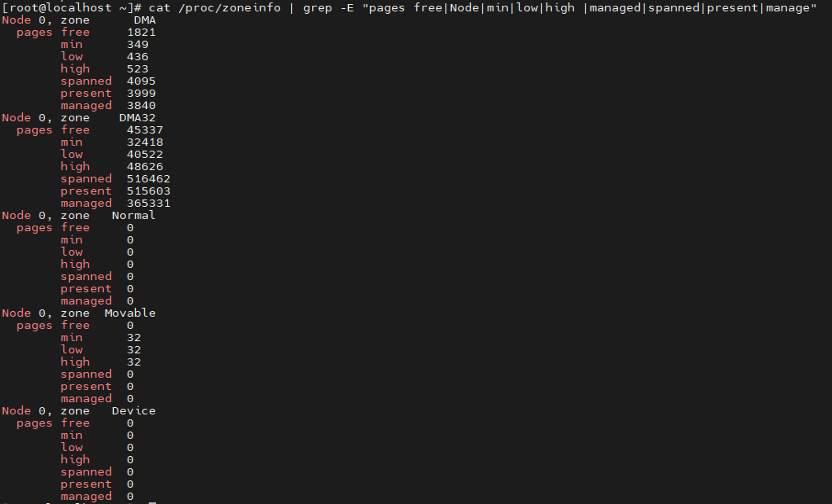
- Spanned (spanned_pages = zone_end_pfn - zone_start_pfn)
表示当前zone所包含的所有的pages,即起始页帧号之间的内存页。
- Present (present_pages = spanned_pages - absent_pages(pages in holes))
表示当前zone在去掉内存空洞后剩下的pages,表示系统实际的物理内存page数。
- Managed (managed_pages = present_pages - reserved_pages)
表示当前zone去掉初始化完成以后所有的kernel 保留的内存而剩下的pages数,也就是被伙伴系统管理的页数,每个zone下的min、low、high值就是基于managed数值和min_free_kbytes内核参数,通过相应计算公式换算而来。
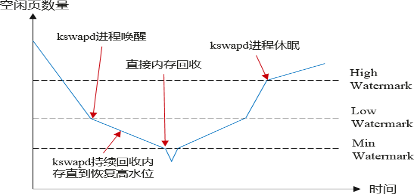
内存管理中,最终内存的分配都是依赖伙伴系统完成,当出现内存相关问题时也可借助/proc/buddyinfo进行辅助分析:

为了解决物理内存的外碎片问题,在linux中使用伙伴算法,把所有空闲的内存以2的幂次方的形式,分成若干个链表,分别对应为2^n个页块,n一般为取值为0-10, aarch64下n为0-13。以第二行第三列数据614为例,其表示Node0节点下Normal区域,当前可用的四页内存连续的页块个数为614个。
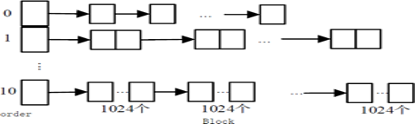
详细的信息可以进一步通过/proc/pagetypeinfo进行分析:

Page block order表示最大的页块阶数为13,pages per block表示阶数为13时,该阶链表中每个页块包含8192(2^13)个连续页。接下来显示的是不同node节点、zone区域下各阶的对应可用迁移类型内存页块分布情况,迁移类型包括Unmovable、Movable、Reclaimable等 ,HighAtomic、CMA、Isolate 一般涉及较少,主要迁移类型含义分别如下:
- Unmovable
不可移动页,在内存中有固定位置,不能进行移动,内核分配的大多数内存属于该类别。
- Movable
可移动页,可以随意地移动,通常用户空间应用程序的页属于该类别,他们是通过页表映射的。
- Reclaimable
可直接回收页,不能直接移动,但可以删除,其内容可以从某些源重新生成。例如,映射文件的数据类别属于该类别。kswapd守护进程会根据可回收页访问的频繁程度,周期性释放此类内存。另外,内存短缺时也可以发起页面回收。
- 进程内存资源分析
用户进程内存使用情况首先可以通过top等命令了解大致内存分布

VIRT表示对于进程使用的虚拟内存,并不是实际是内存;RES表示进程使用的实际物理内存;SHR表示进程使用的共享内存。详细的进程使用内存分布情况可通过 /poc/PID/smaps获取。
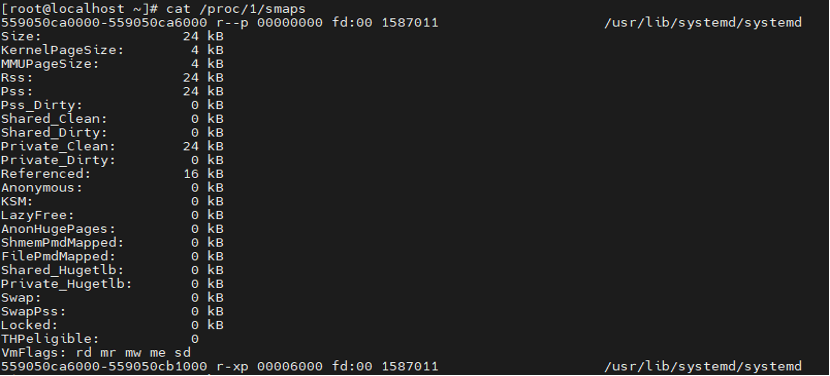
当需要统计部分字段信息时,如匿名页使用情况,可通过 cat /proc/1/smaps |grep 'Anonymous' |awk '{total += $2}; END {print total}'命令进行统计。
应用层内存问题分析
- 内存泄露
内存泄露是指应用程序在申请内存后,未针对申请的内存空间进行释放,导致内存资源被一直被占用。单次的内存泄露往往不易发现,但随着内存泄露的增加,整体内存会逐渐被消耗,最终可能导致OOM等问题。内存泄露可分为以下几种类型:
- 常发性内存泄漏发生内存泄漏的代码会被多次执行到,每次被执行的时候都会导致一块内存泄漏。
- 偶发性内存泄漏发生内存泄漏的代码只有在某些特定环境或操作过程下才会发生。常发性和偶发性是相对的。对于特定的环境,偶发性的也许就变成了常发性的。所以测试环境和测试方法对检测内存泄漏至关重要。
- 一次性内存泄漏发生内存泄漏的代码只会被执行一次,或者由于算法上的缺陷,导致总会有一块且仅有一块内存发生泄漏。
- 隐式内存泄漏程序在运行过程中不停的分配内存,但是直到结束的时候才释放内存。严格的说这里并没有发生内存泄漏,因为最终程序释放了所有申请的内存。但是对于一个服务器程序,需要运行几天,几周甚至几个月,不及时释放内存也可能导致最终耗尽系统的所有内存。所以,我们称这类内存泄漏为隐式内存泄漏。
- 定位思路
常见的内存泄露检测工具有valgrind、ASAN等,下面主要介绍下基于valgrind工具如何进行内存泄露问题分析。
- valgrind工具
Valgrind是一套Linux下,开放源代码(GPLV2)的仿真调试工具的集合。Valgrind由内核以及基于内核的其他调试工具组成。内核类似于一个框架,它模拟了一个CPU环境,并提供服务给其他工具;而其他工具则类似于插件,利用内核提供的服务完成各种特定的内存调试任务。
Valgrind提供memcheck、cachegrind、helgrind等标准工具,这里主要聚焦于memcheck工具分析内存类问题。
memcheck探测程序中内存管理存在的问题。它检查所有对内存的读/写操作,并截取 所有的malloc/new/free/delete调用。因此memcheck工具能够探测到以下问题:
- 使用未初始化的内存
- 读/写已经被释放的内存
- 读/写内存越界
- 读/写不恰当的内存栈空间
- 内存泄漏
- 使用malloc/new/new[]和free/delete/delete[]不匹配。
- valgrind安装
valgrind在百度Linux服务器操作系统 V5.0系统下,可通过配置百度Linux服务器操作系统 V5.0 yum源后使用以下命令进行安装。
1# yum install valgrind -y- valgrind使用进行内存泄露分析
安装完成后可直接进行内存泄露问题分析,下面用以下示例代码进行介绍。示例代码:
1int main()
2{
3char *buffer = (char*) malloc(4); free(buffer);
4int *arry = new int [2]; //line 9 buffer = (char*) malloc(4);
5// Line 10 return 0;
6}编译过程加入-g选项可以在检测报告中指示实际的代码行,方便定位。针对生成的test 文件,使用命令分析如下:
1# valgrind --tool=memleack --leak-check=full ./test分析结果如下:

分析结果中command表示运行的应用程序命令行,'66792'表示程序的PID,HEAP SUMMARY、LEAK SUMMARY展示了堆内存、内存泄露的概述信息。在堆内存概述中,描述了整体问题的概况:一个内存块中的12个字节在程序退出时仍在使用,未释放;程序总共做了4次内存申请,释放了两次。后面显示的就是详细的每个内存泄露点的信息,并在最后显示了详细的调用栈和代码行位置,如test.c文件中的第9、10行, 便于准确识别内存泄露代码行进行修改。LEAK SUMMARY各字段含义如下:
- definitely lost:表示应用程序出现内存泄露,需要进行修复。
- indirectly lost:表示程序中基于指针的结构体或类出现内存泄露,如二叉树结构体的根节点出现definitely lost,则所有子节点都将出现indirectly lost。如果definitely lost的内存泄露修复,indirectly lost的内存泄露也将同步消失。
- possibly lost:表示可能有泄漏,一般是有二级指针等复杂情况不易于追踪时出现。如果不想显示相关结果,可以使用--show-possibly-lost=no参数屏蔽。
- still reachable:表示内存没有被释放,仍有指针指向,内存仍在使用中,这可以不算泄露(如程序退出时仍在工作的异步系统调用等),如果不想显示相关结果,可以使用-- show-reachable=no参数屏蔽。
- suppressed:表示出现了内存泄露但系统自动处理了,可以忽略该项的相关错误。
- 内存访问越界:内存越界是指访问的内存大小超出了应用程序向系统申请的内存空间大小,使得原有的内存数据被错误访问,最终可能导致应用程序数据结构发生改变,导致程序或系统崩溃问题。
该类问题也可通过valgrind进行分析,下面用以下示例进行分析:
示例代码:
1int main()
2{
3char *buffer = (char*) malloc(4); int *ptr = (int*)(buffer + 4);
4*ptr = 100; // Line 9 cout<<*ptr<<endl; // Line 10 free(buffer);
5return 0;
6}编译过程加入-g选项可以在检测报告中指示实际的代码行,方便定位。针对生成的可执行文件,使用命令分析如下:
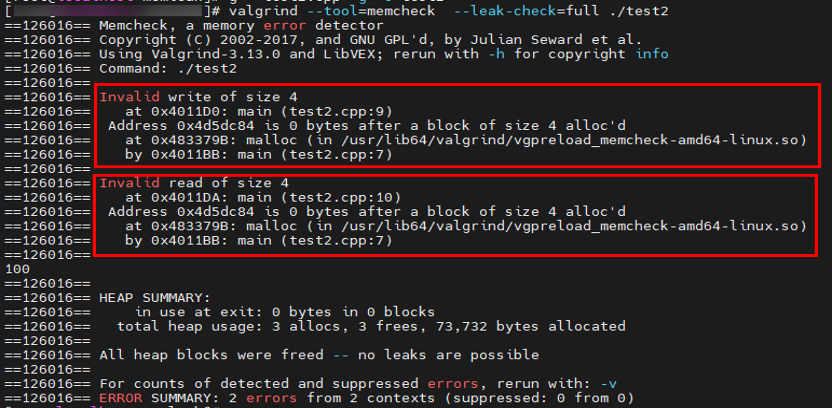
分析结果显示进行了超出内存申请地址的非法访问,分别发生在文件的第9、10行,快速的完成了越界访问的定位。
内存越界访问类问题也可以在编译时添加 -fsanitize=address等地址消毒编译选项, 让内存越界访问等问题尽快暴露出来。
- 内存泄露检测 kmemleak
kmemleak是内核自带的内存泄露检测工具,通过启动内核线程扫描内存,追踪kmalloc(), vmalloc(), kmem_cache_alloc()等函数,打印发现新的未引用对象数量。启用kmemleak功能,需要在内核配置时打开如下编译选项,重新编译内核:
1CONFIG_DEBUG_KMEMLEAK=y # 表示内核打开kmemleak
2CONFIG_DEBUG_KMEMLEAK_EARLY_LOG_SIZE=4096
3CONFIG_DEBUG_KMEMLEAK_DEFAULT_OFF=y
4# 表示kmemleak默认关闭,需要显式启用,启用方式在启动命令中加入kmemleak=on同步将kmemleak=on添加到内核启动的命令行中,这样就完成了基本的配置。如果debugf还未挂载,可通过 mount -t debugfs nodev /sys/kernel/debug/进行挂载。当系统中有内核模块出现内存泄露等问题时,kmemleak缺省每10分钟扫描内存一次, 找到可疑的内存泄漏会在syslog中写一条记录,并提示通过/sys/kernel/debug/ kmemleak查看。kmemleak可通过以下命令完成基本的设置、扫描、查看等操作:
1cat /sys/kernel/debug/kmemleak
2#查看memory leak检测结果
3echo scan > /sys/kernel/debug/kmemleak
4#手动触发立即进行memleak检测
5echo scan=on/off > /sys/kernel/debug/kmemleak
6#开启/关闭后台memleak自动检测线程
7echo scan=<secs> > /sys/kernel/debug/kmemleak
8#设置后台memleak检测时间周期,默认600秒
9echo clear > /sys/kernel/debug/kmemleak
10# 清除当前所有memory leaks记录
11echo off > /sys/kernel/debug/kmemleak
12# 关闭kemeleak(不可逆),也可以通过内核启动命令添加kmemleak=off关闭运行示例如下:
1# modprobe kmemleak-test
2# echo scan > /sys/kernel/debug/kmemleak可以运行一段时间后再进行查看:
1# cat /sys/kernel/debug/kmemleak
2unreferenced object 0xffff89862ca702e8 (size 32):
3comm "insmod", pid 2088, jiffies 4294680594 (age 375.486s) hex dump (first 32 bytes):
46b 6b 6b 6b 6b 6b 6b 6b 6b 6b 6b 6b 6b 6b 6b 6b 6b 6b 6b 6b 6b 6b 6b 6b 6b 6b 6b 6b 6b 6b 6b a5
5backtrace:
6[<00000000e0a73ec7>] kmemleak_alloc+0x8c/0xcc
7[<000000000c5d2a46>] kmem_cache_alloc_trace+0x41/0x1df
8[<0000000046db7e0a>] create_kmemleak+0x55/0x200 [kmemleak]
9...
10[<00000000542b9814>] load_module+0x203c/0x2480
11[<00000000c2850256>] Sys_finit_module+0xba/0xe0
12...kmemleak提示内存泄露可疑对象的具体调用栈信息,如create_kmemleak+0x55/0x200,获取函数出错的代码段,帮助快速分析定位。
- KASAN 内存检测
Kernel Address SANitizer(KASAN)是一种动态内存安全错误检测工具,在linux内核4.0版本时被引入内核,主要功能是检查内存越界访问和使用已释放内存的问题。在使用KASAN前,也需要先开启内核相关配置选项,重新编译内核:
1CONFIG_KASAN=y
2CONFIG_KASAN_OUTLINE=y
3CONFIG_KASAN_INLINE=y测试示例,完成以上配置,重新编译内核后,可通过以下示例进行测试:
1// kasanTest.c文件
2#include <linux/kernel.h>
3#include <linux/printk.h>
4#include <linux/slab.h>
5#include <linux/string.h>
6#include <linux/module.h>
7static noinline void init kmalloc_oob_memset_16(void)
8{
9char *ptr;
10size_t size = 16;
11pr_info("out-of-bounds in memset16\n"); ptr = kmalloc(size, GFP_KERNEL);
12if (!ptr) {
13pr_err("Allocation failed\n"); return;
14}
15memset(ptr+1, 0, 16); // 越界访问
16kfree(ptr);
17}
18static int init kmalloc_tests_init(void)
19{
20kmalloc_oob_memset_16();
21}
22module_init(kmalloc_tests_init); MODULE_LICENSE("GPL");Makefile文件内容:
1obj-m := kasanTest.o
2KERNELDIR := /lib/modules/$(shell uname -r)/build PWD := $(shell pwd)
3default:
4$(MAKE) -C $(KERNELDIR) M=$(PWD) modules
5clean:
6rm -f *.o *.ko *.mod.c *.order *.symvers编译后生成kasanTest.ko模块,执行insmod kasanTest.ko测试,会在dmsg日志中生成kasan的分析结果,结果显示kmalloc_oob_memset_16+0x51处出现内存操作问题。
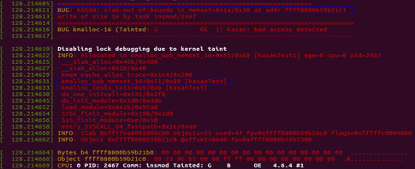
-
crash 内存问题分析
crash是分析dump文件的一个强大工具,内存类问题导致的系统崩溃均可基于该工具进一步分析。在使用前需要配置kdump功能,遇到非法内存访问后会触发生成vmcore,再基于vmcore进行分析,本小节主要聚焦如何基于crash分析内存类问题导致的系统崩溃问题。crash工具中内存分析相关的几个主要命令有vm、kmem、ptob、ptov、pte、rd等:- vm:显示当前虚拟内存数据信息,如 vm -m PID可显示PID进程的mm_struct结构体信息,-v查看
- vm_arear_structs结构体信息,-P 显示指定vm地址的转换信息等。
- kmem:显示内核内存信息使用情况,如kmem -i显示内存使用信息,kmem -f显示各node、zone下内存使用情况,kmem -s 查看对应slab分配缓存数据信息等。
- ptob: ptob
将物理页帧号转化为物理地址。 - ptov:ptov 将物理内存转换成虚拟内存,ptov offset:cpuspec通过PERCPU变量物理地址获得在指定CPU上的虚拟地址。
- pte:将一个十六进制的PTE页表内容进行解码,解码之后可以获得PTE对应的物理页以及PTE页表的标志。如果
- PTE对应的物理页表位于SWAP中,那么CRASH将输出物理页在SWAP中偏移以及SWAP的设备名。
- rd:进行内存数据的读取,如rd -p 读取物理地址的内容,rd -u
读取虚拟地址的内容,rd 读取符号所在物理内存的内容等。
通过以上内存相关信息分析基础命令,可以获取进程运行时内存分配、内存存储信息等详细内容,协助问题分析定位,详细的操作可以在crash命令下执行help查看,如help kmem。
- 基于crash分析内存非法访问
系统运行程序时出现系统挂死,重器后生成了vmcore文件,基于crash工具进行分析。
- 执行 crash分析工具
1# crash vmcore ./vmlinux发现引发的错误是空指针访问错误,访问了无效的地址空间。

- 打印调用栈信息
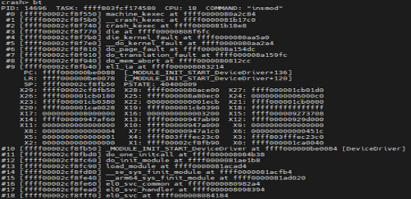
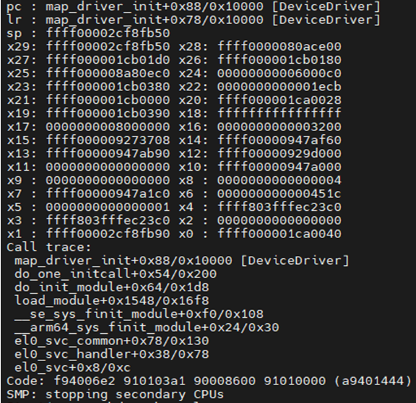
结合调用栈、现场log信息发现是在加载模块DeviceDriver后执行出现问题,函数位置为map_driver_init+0x78附近,需要加载对应模块后分析具体符号表及代码行位置。
- 加载模块
模块符号表信息加载:
1crash> mod -s DeviceDriver /home/MapDriver/DeviceDriver.ko
2MODULE NAME SIZE OBJECT FILE
3ffff000001a30000 DeviceDriver 262144 /home/MapDriver/DeviceDriver.ko
4打印报错时调用栈中PC指针中位置代码信息
5crash> l *map_driver_init+0x78
60xffff000001c90078 is in map_driver_exit (/home/MapDriver/DeviceDriver.c:28).
723 for (index= 0; index< MaxNums; index++) {
824 pages[index] = alloc_pages(GFP_KERNEL, 10);
925 lastPtr =pages[index];
1026 }
1127 printk("last ptr value %lx \n", lastPtr);
1228 usigned long pValue = *lastPtr; 29 .....
13....
14}错误发生在28行,初步猜测在申请内存时可能失败了,代码中未作该场景判断,导致lastPtr为空指针,后续代码对其进行了空指针访问。
- kmem -i查看内存
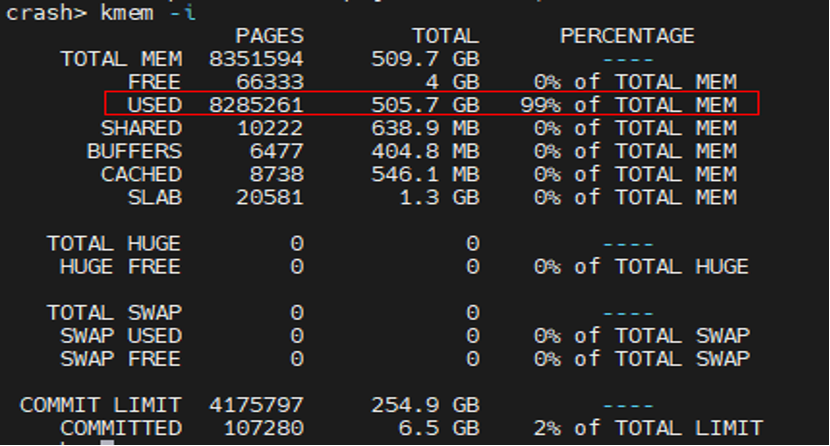
进一步分析发现当时内存属于满负荷情况,模块确实有可能无法申请到内存。通过对DeviceDriver.c代码进一步分析,发现MaxNums是一个较大的数,申请内存大于剩余内存,导致内存申请失败,触发空指针访问问题。
修复方法
在申请内存后增加相应判断,查看是否申请内存失败,失败时进行必要的异常处理,避免空指针访问。
评价此篇文章