
介绍
概述
百度消息服务(Baidu Messaging System BMS)是全兼容Apache Kafka的分布式、高可扩展、高通量的托管消息队列服务,您可以直接享用Kafka带来的先进功能而无需考虑集群运维,并按照使用量付费。
Kafka在网络中的位置和作用
本章节以开发新一代互联网应用的发展历程为例,介绍Kafka在网络中的位置和作用。
-
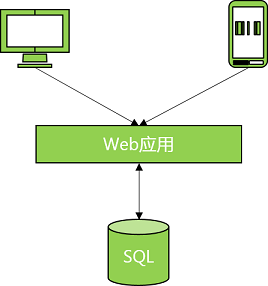
第一阶段,首次搭建应用网络如下:
- Web应用部署在云服务器上,为个人电脑或移动用户提供访问服务。
- SQL数据库为Web应用提供数据持久化和数据查询。
-
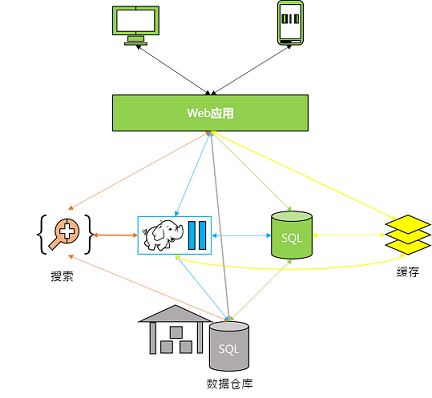
第二阶段:基于业务的迅速发展,网络扩容如下:
- 增加缓存服务,从而降低SQL数据库的荷载。
- 搜集日志保存至Hadoop做离线处理,从而更加理解用户行为。
- 数据汇总至数据仓库,从而获取交互式报表。
- 加入实时模块和外部数据交互等等。
网络扩容后的问题如下:
- 不同系统之间的数据同步
- 系统扩展问题
-
第三阶段:新增Kafka模块提供消息队列,Web应用数据只需向队列中添加数据,网络中的各组件从队列中依次读取数据并自行处理,如下图所示:
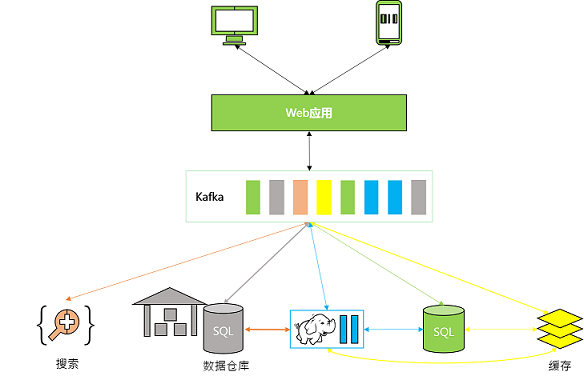
网络扩容带来的问题迎刃而解,而且降低了系统组网复杂度;降低编程复杂度,各个子系统不在是相互协商接口,各个子系统类似插口插在插座上,Kafka承担高速数据总线的作用。
Apache Kafka简介
Apache Kafka是分布式的流数据平台,具有三大特性:
-
提供Pub/Sub方式的海量消息处理。
Kafka提供的Pub/Sub就是典型的异步消息交换,消息的发布者(Pub)只需指定消息的类别,而无需与订阅者(Sub)交互;订阅者只接受订阅的一个或几个类型的消息。发布者与订阅者的解耦可独立的扩展或修改接口两边的处理过程。例如,您可以为服务器日志或者物联网设备创建不同主题(Topic),之后数据便可持续发送到各个主题,后端数据仓库、流式分析或者全文检索等对接特定主题,无需关注服务器或者物联网设备。
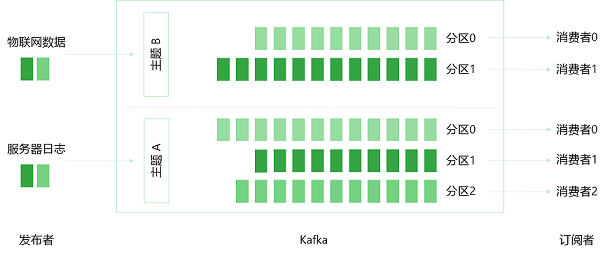
同时,Kafka将主题划分为多个分区(Partition),并根据分区规则选择消息存储的分区。若分区规则设置合理,则所有的消息被均匀的分布到不同的分区中,可实现负载均衡和水平扩展。
-
以高容错的方式存储海量数据流。
多个订阅者可以从一个或者多个分区中同时消费数据,以支撑海量数据处理能力。同时为了保证数据的可靠性,Kafka为每个分区设置一个Leader,Leader负责所有的读写操作,Follower只与Leader同步消息。消息写入分区时,Leader为自己和Follower复制数据做多个备份,如果Follower失效,Kafka会从另外的Follower处同步Leader的历史消息;如果Leader失效,其他Follower成为新的Leader继续服务。
-
保证数据流的顺序。
每个发布者发送到Kafka分区中的消息是确保顺序的,订阅者可以依赖这个承诺进行后续处理。顺序写磁盘的效率比随机写内存高,是Kafka高吞吐率的重要保证之一。
百度消息服务综述
百度消息服务是基于Apache Kafka的分布式、高可扩展、高通量、多分区和多副本的托管消息队列服务。百度消息服务封装了Kafka集群细节,并以托管服务形式提供,您可以直接使用百度消息服务创建主题来集成大规模分布式应用,而无需考虑集群运维,仅按照使用量支付处理数据的费用。相对于传统的消息服务,百度消息服务有以下特点:
- 可通过分区(Partition)实现主题水平扩展。
- 分区分布在多个节点上以达到高通量。
- 通过消费者组(Consumer Group)来支持单个消费者以队列或者Pub/Sub形式的消息消费,或者多个消费者集群顺序消费消息。
- 生产者和消费者异步交互,而不需要彼此等待。
产品优势
- 一键部署:开通即使用百度消息服务,专注产品开发即可,无需耗费精力安装、部署、配置、调试和维护集群。
- 低廉价格:无需任何硬件软件投入,只需开通服务并且为使用的资源付费。由于与社区的Kafka兼容,迁移成本极低,且不用担心被技术锁定。
- 数据安全:消息中心仅支持SSL加密的数据传输,以保证数据在传输的过程中不被窃听或者篡改,保证客户数据的安全。
- 可靠耐用:独特的高可用特性设计,防止数据在应用程序故障、个别机器故障或设施故障时丢失。
业务场景
- 采集网站、设备或应用程序的海量用户浏览、点击、搜索等数据以便实时分析。
- 汇总分布式应用的遥感数据方便系统运维。
- 对接百度MapReduce提供的Spark Streaming实现实时流数据分析。
评价此篇文章