
数据模型
数据模型
在HBase中,数据存储在具有行和列的表中。这与关系数据库(RDBMS)的术语相似,但是更恰当的方式是将HBase表视为一种多维映射。
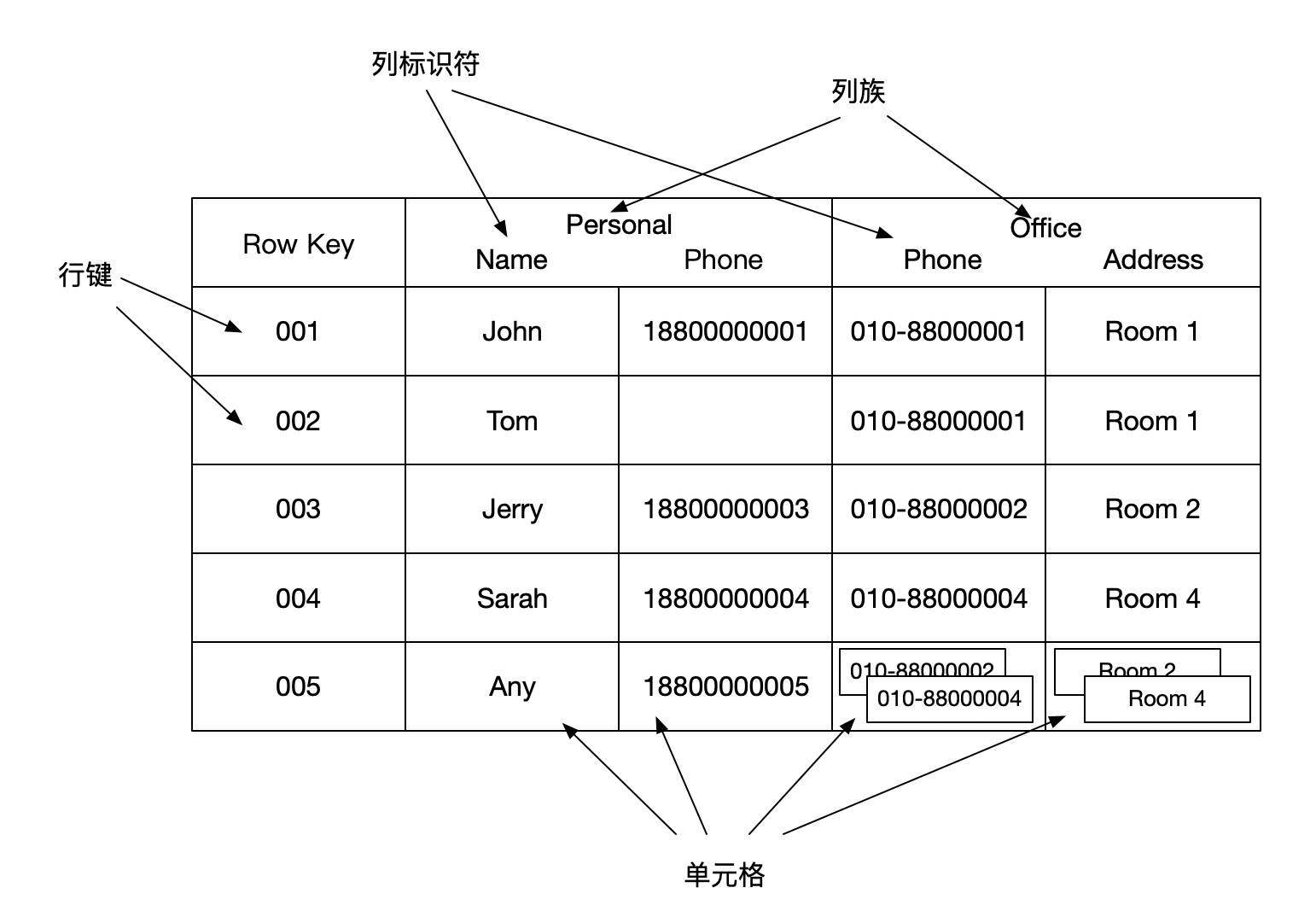
相关术语
-
命名空间(Namespace)
命名空间是一组表(Table)的集合,类似于关系型数据库中的Database概念。这一概念有助于多租户场景下的数据和资源的隔离。
-
表(Table)
一张HBase表由许多行(row)数据组成。
-
行(Row)
一行数据由一个行键(row key)以及一个或多个值(value)构成。在存储数据时,行按照行键的字母序排列。因此,行键的设计非常重要:相关的行最好能够被分配到相近的位置。一个常见的例子是网站地址。如果你的行键设置成网站地址,那么你应当将网站地址逆序存储(例如org.apache.www, org.apache.mail等)。这种行键设计能够将同属于apache.org的网址存放在相近的位置。
-
列(Column)
一列数据由一个列族(column family)以及一个列标识符(column qualifier)组成;二者通常由一个:符号相连(例如column_family:column_qualifier),表示一列数据。
-
列族(Column Family)
列族表示物理上存储在一起的一组列(column)和他们的值。这么做的原因通常是性能。每个列族中都有一组存储属性,例如其是否该换存在内存中,其数据如何压缩存储,或是其行键的编码的方式为何,等等。一张表格中的每行都拥有相同的列族,但是某一行也许只会在一些列族上存储内容,而另一些列族上为空。
-
列标识符(Column Qualifier)
列标识符与列族一起指定了一列数据。尽管创建表时列族的数量与名称就固定了,但是列标识符可以动态增加或删除。即使在同一个列族中,行与行之间也可能拥有不同的列标识符。
-
单元格(Cell)
一个单元格指一个由 <(行,列族,列标识符) => (时间戳,值)> 构成的数据结构。一个单元格可以有多个版本的值,由时间戳区分。
-
时间戳(Timestamp)
每个值都带有一个时间戳,指代某个某个特定版本。默认情况下,时间戳指的是当数据写入某个RegionServer时RegionServer上的本地时间,但是用户也可以在写入数据时指定时间戳。
概念视图
本示例表格由BigTable论文第二页中的示例修改得到。
| 行键 | 时间戳 | 列族 contents | 列族 anchor | 列族 people |
|---|---|---|---|---|
| "com.cnn.www" | t9 | anchor:cnnsi.com = "CNN" | ||
| "com.cnn.www" | t8 | anchor:my.look.ca = "CNN.com" | ||
| "com.cnn.www" | t6 | contents:html = "<html>…" | ||
| "com.cnn.www" | t5 | contents:html = "<html>…" | ||
| "com.cnn.www" | t3 | contents:html = "<html>…" | ||
| "com.example.www" | t5 | contents:html = "<html>…" | people:author = "John Doe" |
需要注意的是,表格中的空白代表该行在这个列族上没有数据。需要注意的是,表格中的空格在HBase中不占用空间,实际上也并不存在。下面这个json代表了与表格相同的信息。
注意:这个json只是作为示例使用,他并不是严格意义上绝对准确的。
1{
2 "com.cnn.www": {
3 contents: {
4 t6: contents:html: "<html>..."
5 t5: contents:html: "<html>..."
6 t3: contents:html: "<html>..."
7 }
8 anchor: {
9 t9: anchor:cnnsi.com = "CNN"
10 t8: anchor:my.look.ca = "CNN.com"
11 }
12 people: {}
13 }
14 "com.example.www": {
15 contents: {
16 t5: contents:html: "<html>..."
17 }
18 anchor: {}
19 people: {
20 t5: people:author: "John Doe"
21 }
22 }
23}物理视图
尽管在概念视图的示例中,HBase中的数据看起来以行为单位存储,但是实际上他们按照列族存储。一个新的列标识符可以随时被加入已经存在的列族存储中。
| 行键 | 时间戳 | 列族 anchor |
|---|---|---|
| "com.cnn.www" | t9 | anchor:cnnsi.com = "CNN" |
| "com.cnn.www" | t8 | anchor:my.look.ca = "CNN.com" |
如上表所示,没有值的空白单元格完全没有被存储,自然也不占用物理存储空间。对这些空白单元格的查询不会返回任何值。但是,如果用户在查询时不提供时间戳,HBase会返回特定列的最新值。在HBase中,同一单元格的不同版本数据按照时间戳降序排列,因此HBase只需要返回第一个找到的值即可。
数据模型操作
HBase共有四个常用的数据模型操作,分别为Get、Put、Scan和Delete。这些操作的操作对象都是一张表。
Get
获取特定行的一些值。
Put
在表中插入新行(如果行不存在)或者更新行中的某些值(如果行存在)。
Scan
使用迭代器(iterator)访问一些行。
Delete
从表中删除特定行。
数据排列顺序
对于所有的数据模型操作,HBase都会按照一个特定顺序返回数据。数据会首先按行排列,随后按列族排列,接着按列标识符排列,最后按时间戳降序排列。
列元数据
在列族之外,HBase并不会在某些地方存储列的元数据(如列标识符等)。因此,HBase可以支持列标识符的动态修改,以及支持同一列族中拥有大量不同的列标识符。用户需要自己妥善处理并保管列族中的列标识符,保证其符合用户预期。如果用户不慎遗失了列元数据,那么重新获得该数据的方式只有scan整个列族并重新构建元数据。
Join
HBase不支持,或者说不像RDBMS那样支持Join操作。如同数据模型操作中所提到的,HBase支持两种读操作:Get和Scan。
但是这不意味着用户无法实现Join操作。事实上,用户可以使用四种常用数据模型操作手动实现定制化的Join操作。
ACID
ACID,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)与持久性(Durability)。关于HBase的ACID特性,请参考Lars Hofhansl的ACID in HBase。
如果您想知道更多关于HBase数据模型的详细内容,请参阅HBase官方文档。
评价此篇文章