
自建SQL Server迁移至RDS SQL Server
本文主要介绍自建 SQL Server 实例和云数据库 RDS SQL Server 实例之间的数据迁移。
前提条件
- 已创建存储空间大于自建 SQL Server 数据库占用存储空间的目标 RDS SQL Server 实例。创建方式,请参见 创建 SQL Server 实例。
限制说明
结构迁移限制
- SQL Server→SQL Server 的同构数据库迁移支持表、视图、自定义数据类型、函数、存储过程和触发器的结构迁移。
全量迁移限制
- 如果源库中待迁移的表没有主键或唯一约束,且所有字段没有唯一性,可能会导致目标数据库中出现重复数据。
- 数据类型 MONEY 和 SMALLMONEY 仅支持小数点后两位。
增量同步限制
-
SQL Server 增量迁移依赖 SQL Server CDC 功能,需要先启动 CDC 功能,详见官网:About Change Data Capture (SQL Server)
- SQL Server 启动 CDC 功能需要 SQL Server 代理服务的支持。
- CDC 要求采用独占方式使用 cdc 架构和 cdc 用户,如果某数据库中当前存在名为 cdc 的架构或数据库用户,那么在删除或重命名此架构或用户之前,不能对此数据库启用变更数据捕获。
- 如需对启动了 CDC 功能的源表执行 DDL,只能由角色 sysadmin、database role db_owner 成员或 database role db_ddladmin 成员操作。
- 用来启动数据库级别 CDC 功能的账号,必须是 sysadmin 角色的成员;用来启动表级别 CDC 功能的账号,必须是 sysadmin 或 db_owner 角色的成员。
- 不支持列集的增量更改。
- 不支持计算列的增量更改。
- 不支持数据类型 sql_variant、cursor 和 table。
- 暂不支持无主键表增量迁移的 DELETE 操作。
- 数据类型 MONEY 和 SMALLMONEY 仅支持小数点后两位。
数据库账号权限要求
说明
如使用拥有 sysadmin 服务器角色的账号,则不受下面权限限制,如 sa 账号。
| 数据库 | 结构迁移 | 全量迁移 | 增量迁移 |
|---|---|---|---|
| 源端 | 至少 db_datareader 权限 | 至少 db_datareader 权限 | 至少 db_owner 权限 |
| 目标端 | 至少 db_owner(读写)权限 | 至少 db_owner(读写)权限 | 至少 db_owner(读写)权限 |
准备工作
本文以公网自建数据库到百度智能云 RDS 上云迁移为例,迁移对象是 mssql_test.dbo.table1/mssql_test.dbo.table2/mssql_test.dbo.table3,迁移类型是结构/全量/增量,数据源准备:
- 自建 SQL Server 2012 实例。
- 百度智能云 RDS SQL Server 2012 实例。
对于源端和目标端实例的其他要求详见文档:将SQL Server作为源端 和 将SQL Server作为目标端。
源端公网自建 SQL Server 的准备工作
数据库迁移账号授权
-
在 SSMS 左侧对象资源管理器中,列表中打开安全性中的登录名,右击对待迁移账号,点击 属性,如 dts_online,如图所示:
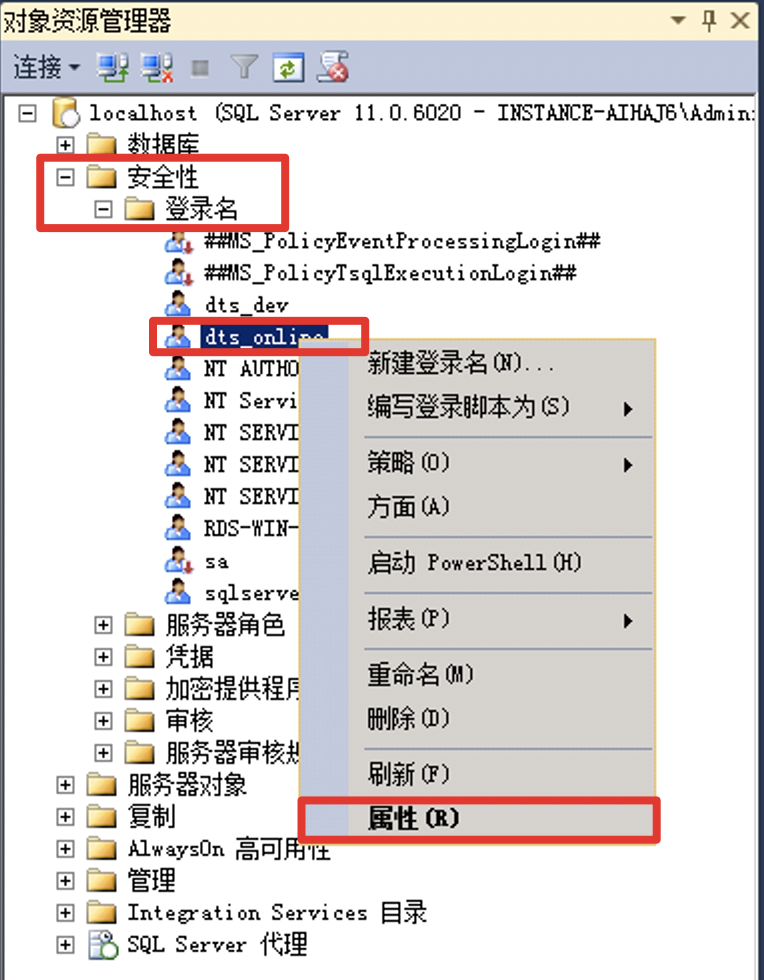
-
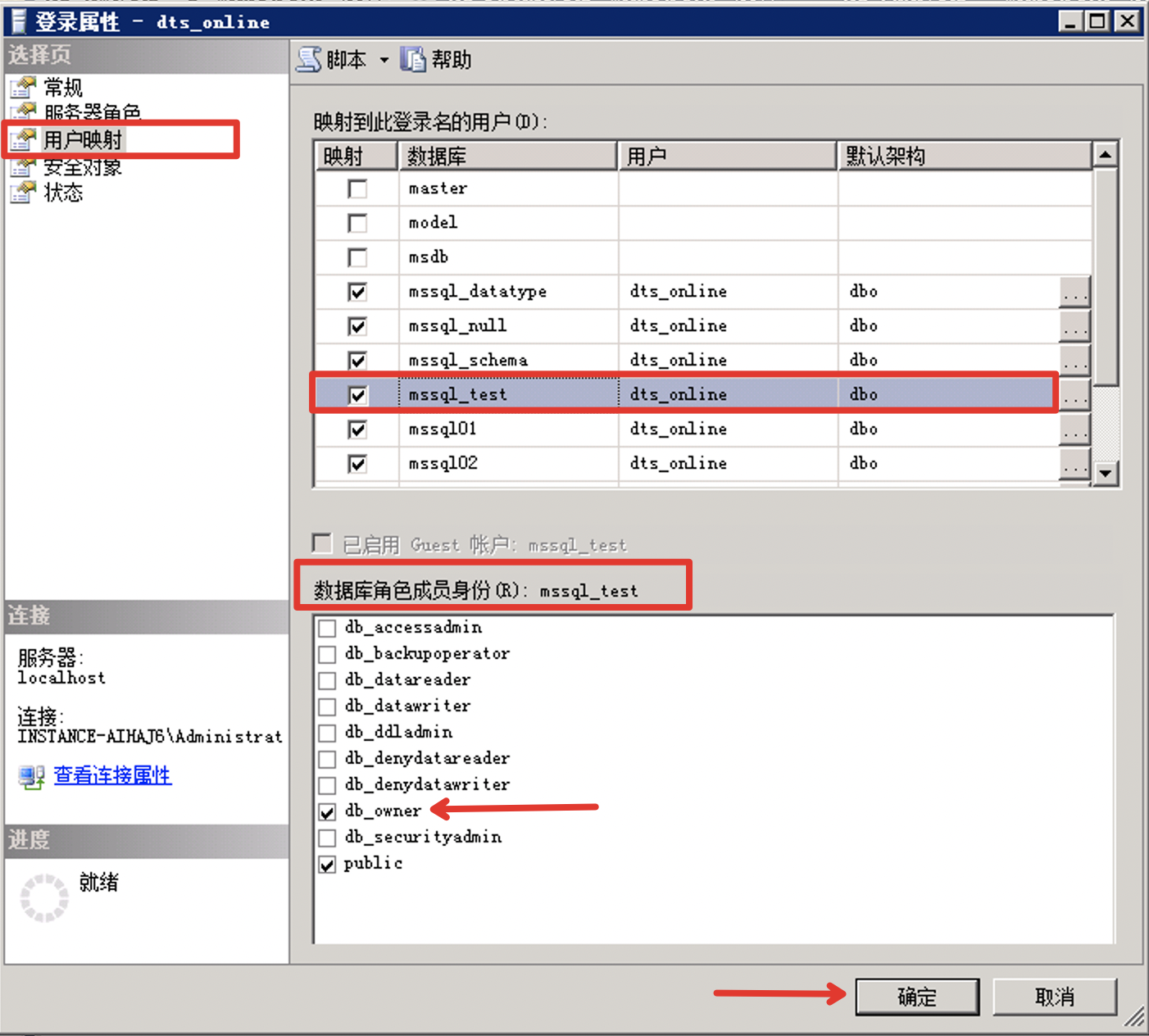
弹出登录属性框,在左侧选择用户映射,点击数据库查看账号对数据库拥有的权限,可以勾选添加账号对数据库的权限,如读写权限 db_owner,设置之后点击 确定。
源端增量迁移开启 CDC 准备工作
注意:
如果不选择增量迁移,可忽略本节准备工作。
-
启动数据库级别 CDC 功能
SQL1-- 启动数据库级别CDC命令。 2EXEC sys.sp_cdc_enable_db; 3-- 检查是否启动成功。 4SELECT name,is_cdc_enabled FROM sys.databases WHERE name = 'DB_name'如果您遇到如下报错:
SQL1Could not update the metadata that indicates database DB_name is enabled for Change Data Capture. The failure occurred when executing the command 'SetCDCTracked(Value = 1)'. The error returned was 15404: 'Could not obtain information about Windows NT group/user 'RDS-WIN-TESTAdministrator', error code 0x534.'. Use the action and error to determine the cause of the failure and resubmit the request.执行以下命令然后再次执行启动数据库级别 CDC 命令即可:
SQL1ALTER AUTHORIZATION ON DATABASE::[DB_name] TO [sa] 2或者 3EXEC sp_changedbowner 'sa' -
启动每个需要增量迁移表的表级别 CDC 功能
SQL1-- 启动表级别CDC命令 2EXEC sys.sp_cdc_enable_table 3@source_schema= N'schema_name',-- 源表所属的架构的名称,无默认值,且不能为NULL 4@source_name = N'table_name',-- 源表的名称,无默认值,且不能为NULL 5@role_name = NULL,-- 建议设置为NULL,用于访问更改数据的数据库角色的名称。必须指定。如果显式设置为NULL,则没有控制角色用于限制对更改数据的访问。可以为现有的固定服务器角色或数据库角色,如果指定的角色不存在则会自动创建该名称的数据库角色 6@capture_instance = DEFAULT,-- 用于命名特定于实例的变更数据捕获对象的捕获实例的名称。且不能为NULL,源表最多可以有两个捕获实例。 7@supports_net_changes = 0,-- 是否为此捕获实例启用用于查询净更改的支持,默认值为1, 如果supports_net_changes设置为1,则必须指定index_name ,否则源表必须具有定义的主键 8@index_name = NULL,-- 唯一标识源表中的行的唯一索引的名称,可以为NULL。未使用则CDC将使用主键,如果表也没有主键,则将忽略后来添加的主键 9@captured_column_list = NULL,-- 标识要包含在变更表中的源表列,NULL则所有列都将包括在变更表中,以逗号分隔的列名称列表,可以选择将列表中的单个列名称放在双引号("")或方括号([])中,不能包含以下保留列名:__$start_lsn、__$end_lsn、__$seqval、__$operation和__$update_mask。 10@filegroup_name = DEFAULT, -- 要用于为捕获实例创建的变更表的文件组,为 NULL则使用默认文件组,建议为变更数据捕获的变更表创建一个单独的文件组。 11@allow_partition_switch = 1 -- 是否可以对启用了变更数据捕获的表执行ALTER TABLE的SWITCH PARTITION命令,默认值为1,对于非分区表,此开关设置始终为 1,并忽略实际的设置。如果您遇到如下报错:
SQL1消息 22832,级别 16,状态 1,过程 sp_cdc_enable_table_internal,第 623 行 2无法更新元数据来指示已对表 [aqadmin].[AQ_TEST_1] 启用了变更数据捕获。执行命令 '[sys].[sp_cdc_add_job] @job_type = N'capture'' 时失败。返回的错误为 22836: '无法更新数据库 aq11 的元数据来指示已添加某变更数据捕获作业。执行命令 'sp_add_jobstep_internal' 时失败。返回的错误为 14234: '指定的 @server无效(有效值由 sp_helpserver 返回)。'。请使用此操作和错误来确定失败的原因并重新提交请求。'。请使用此操作和错误来确定失败的原因并重新提交请求。SQL Server 安装后修改了主机名,导致两个语句结果的 servname 不一致,执行以下命令然后再次执行启动表级别 CDC 命令即可:
SQL1IF serverproperty('servername')<>@@servername 2 BEGIN 3 DECLARE @server SYSNAME 4 SET @server=@@servername 5 EXEC sp_dropserver @server=@server 6 SET @server=cast(serverproperty('servername') AS SYSNAME) 7 EXEC sp_addserver @server=@server,@local='LOCAL' 8 PRINT 'ok!' 9 END 10ELSE 11 PRINT 'undo! -
第一次启动表 CDC 功能会提示启动两个作业:捕获作业和清除作业。
- 修改清除作业执行周期(可选)
默认 4320(分钟)后清除捕获的增量数据,您可以修改增量数据的保留时间。例如,如下命令将保留时间修改为 129600(分钟)。
SQL1EXECUTE sys.sp_cdc_change_job 2@job_type = N'cleanup', 3@retention = 129600; 4 5-- 重新启动 6EXECUTE sys.sp_cdc_start_job 7@job_type = N'cleanup';- 修改捕获作业读取事务日志的周期(可选)
默认时间间隔为 5(秒),当间隔时间越长,增量数据记录到变更表的时间就可能越长,因此您可以适当调整周期间隔时间。例如,如下命令将周期间隔时间修改为 1(秒)。
SQL1EXECUTE sys.sp_cdc_change_job 2@job_type = N'capture', 3@pollinginterval = 1; 4 5-- 重新启动 6EXECUTE sys.sp_cdc_start_job 7@job_type = N'capture';
目标端 RDS SQL Server 的准备工作
-
数据库迁移账号授权
- 进入待迁移目标端实例的详情页后,点击 账号管理,点击 创建账号。创建对应数据库具有读写权限的账号,例如创建账号 dts_online,并且对目标数据库 mssql_test 授权读写权限(db_owner),点击 确定。
说明
如果已经存在迁移账号则忽略该步骤。
- 如果已经存在迁移账号,在账号列表中点击 修改权限,对迁移的目标数据库添加读写权限,点击 确定 按钮。
-
开通百度智能云云数据库公网访问
- 登录百度智能云访问控制台,点击实例名称,进入待迁移目标端实例的详情页。
- 进入实例详情页后,在公网访问选项点击 开通,弹出公网开通的确认框后点击 确定 按钮。
- 开通成功后,可以在详情页中看到公网访问状态变成已开通。点击 获取 IP 可以查看外网 IPV4,后续可以使用该地址配置 DTS 任务。
-
创建百度智能云云数据库待迁移数据库
- 进入待迁移目标端实例的详情页后,点击 数据库管理,点击 创建数据库。
- 例如上云迁移至目标库 mssql_test,则需要手动创建对应的数据库名,即需要在百度智能云 RDS 中已存在数据库。点击 确定。
操作步骤
- 登录 DTS 控制台。
-
点击 创建数据传输任务 进入 DTS 创建任务页面,详情参见 购买流程。
参数 说明 源端位置 选择自建数据存储。 源端接入类型 支持公网、BCC/BBC/DCC、VPC、专线接入方式。 源端数据类型 选择 SQL Server。 源端地域 选择迁移链路的源端所属的地域,购买后不支持更换地域,请谨慎选择。 专线接入所在网络 仅接入类型选择专线接入时需配置。专线接入有三个可选项分别为:该地域的 VPC 列表、该地域的可用区列表、选定可用区对应的子网列表。VPC 列表中请选择专线所在的 VPC。 目标端位置 选择自建数据存储。 目标端接入类型 支持公网、BCC/BBC/DCC、VPC、专线接入方式。 目标数据类型 选择 SQL Server。 目标端地域 选择迁移链路的目标端所属的地域,购买后不支持更换地域,请谨慎选择。 同步方向 仅支持单向同步。 链路规格 DTS 为您提供了不同性能的链路规格,迁移链路规格的不同会影响迁移速率,您可以根据业务场景进行选择,详情请参见 链路规格说明。 - 创建任务成功后自动返回任务列表页面,选择新创建的任务,点击 更多操作—>配置任务。
-
在配置任务页面,配置源库及目标库信息,本文以 公网 接入方式为例介绍配置流程。
配置流程 类别 配置 说明 任务基本属性 任务名称 DTS 会自动生成一个任务名称,建议配置具有业务意义的名称(无唯一性要求),便于后续识别。 源端连接设置 IP/端口 填入源端 SQL Server 实例的访问地址,本示例中填入公网地址。 数据库 填入源端 SQL Server 实例的数据库。 账号 填入源端 SQL Server 实例的账号。 密码 填入该数据库账号对应的密码。 目标端连接设置 IP/端口 填入目标端 SQL Server 实例的访问地址,本示例中填入公网地址。 数据库 填入目标端 SQL Server 实例的数据库。 账号 填入目标端 SQL Server 实例的账号。 密码 填入该数据库账号对应的密码。 -
配置完成后,点击页面下方的 授权白名单进入下一步。
如果源或目标数据库是 BCC/BBC/DCC 自建或 IDC 自建数据库或其他云数据库,则需要您手动添加对应地区 DTS 服务的 IP 地址,以允许来自 DTS 服务器的访问。
警告:
DTS 自动添加或您手动添加 DTS 服务的 IP 地址段可能会存在安全风险,一旦使用本产品代表您已理解和确认其中可能存在的安全风险,并且需要您做好基本的安全防护,包括但不限于加强账号密码强度防范、限制各网段开放的端口号、内部各 API 使用鉴权方式通信、定期检查并限制不需要的网段等等。
-
配置任务对象映射。
配置 说明 迁移类型 支持结构迁移、全量迁移和增量同步。 同步语句选择 增量同步阶段,支持指定需要同步的 SQL 语句类型,可多选。 限制传输速度 根据实际情况,选择是否对全量迁移和增量同步任务进行更细粒度的限流策略设置(设置 每秒迁移的行数 和 每秒迁移的数据量),以缓解目标库压力。详情参见:迁移限速。 重试时间 源端/目标端实例无法连接后自动重试,用户可根据实际情况调整重试时间,或者在源端和目标端的实例释放后尽快释放 DTS 实例。 传输对象 整个实例:将源端所有数据迁移到目标端。手动选择:选择此选项时,在页面左侧选择需要迁移的库表,库表信息将会被自动添加到页面右侧。 -
上述配置完成后,点击页面下方的 保存并预检查。
说明
- 在迁移任务正式启动之前,会先进行预检查。只有预检查通过后,才能成功启动迁移任务。
- 如果预检查失败,请查看失败检查项的提示,并根据提示修复后重新进行预检查。
-
如果预检查产生警告:
- 对于不可以忽略的检查项,请查看失败检查项的提示,并根据提示修复后重新进行预检查。
- 对于可以忽略无需修复的检查项,您可以点击 强制通过,在弹出的窗口中勾选风险确认信息并点击 确定,跳过告警检查项重新进行预检查。如果选择屏蔽告警检查项,可能会导致数据不一致等问题,给业务带来风险。
- 前置校验提示校验成功后,点击 立即开启任务。
- 迁移任务正式开始,您可以在任务列表页面查看具体进度。
后续操作(可选)
数据校验
详情参见 配置数据校验。
评价此篇文章