
配置 Token 限流策略
更新时间:2026-05-06
概述
Token 限流策略用于在滚动时间窗口内限制某一调用方在该模型推理服务上可消耗的 Token 速率。命中限流条件后,超过阈值的请求会被网关直接拒绝,不再转发到上游模型,从而避免突发流量打垮后端,或个别调用方耗尽容量影响其他用户。
时间窗口到点后限流计数会自动重置。
Token 限流仅在 API 接口访问模式下生效。同一模型推理服务下可配置多条限流规则,按从上到下的顺序依次匹配,命中即生效。
限流与限额的区别
- 本策略 = 限流(Rate Limiting):在每秒/每分钟/每小时/每天的滚动窗口内限制 Token 速率,窗口到点自动重置,用于平滑流量、保护后端。
- 限额(Quota)= 消费者配额:按账期(每日或每月)累积分配 Token 或请求次数总量,超出后需到下一周期才恢复。如需该能力,请前往「消费者管理 → 消费者详情」中为对应消费者配置「配额限制」。
两者解决的问题不同,可以叠加使用。例如:先通过「消费者配额」限制每月最多 1 亿 Token 来兜住整体成本;再通过本策略将每秒 Token 速率平滑控制在 1 万以内,避免短时突发把后端打挂。
适用场景
下列场景下推荐配置 Token 限流策略:
- 平滑突发流量、保护后端:模型服务的并发或 Token 处理能力有限,希望在每秒/每分钟级别将上游负载控制在安全水位内,避免高峰期把推理后端打挂。
- 多租户共享同一推理服务:不同业务方共用一个网关入口,希望按消费者维度分配独立的限流速率,避免某一租户突增流量挤占其他租户的吞吐能力。
- 防止误用与异常调用:在测试环境或新接入业务上线初期,担心程序 bug 或脚本失控产生异常高频请求,可先按较低的速率阈值兜底,避免单次故障消耗大量算力或费用。
- 按业务等级区分速率:通过「按请求头」或「按请求参数」维度,识别请求的业务等级或客户层级,给不同等级配置不同的速率上限(例如内部研发可放更高速率、外部客户限制较低速率)。
操作步骤
- 登陆百度智能云AI 原生网关控制台。
- 在顶部导航栏选择目标地域,并在实例列表中单击目标实例 ID,进入实例详情页。
- 在左侧导航栏选择 AI 服务 > 模型推理服务。
-
创建或编辑一个模型推理服务:
- 创建场景:单击列表上方的 创建推理服务。
- 编辑场景:在目标服务的操作列单击 编辑。
-
滚动到页面底部的 高级策略 模块,在 Token 限流 下勾选 开启 Token 限流。
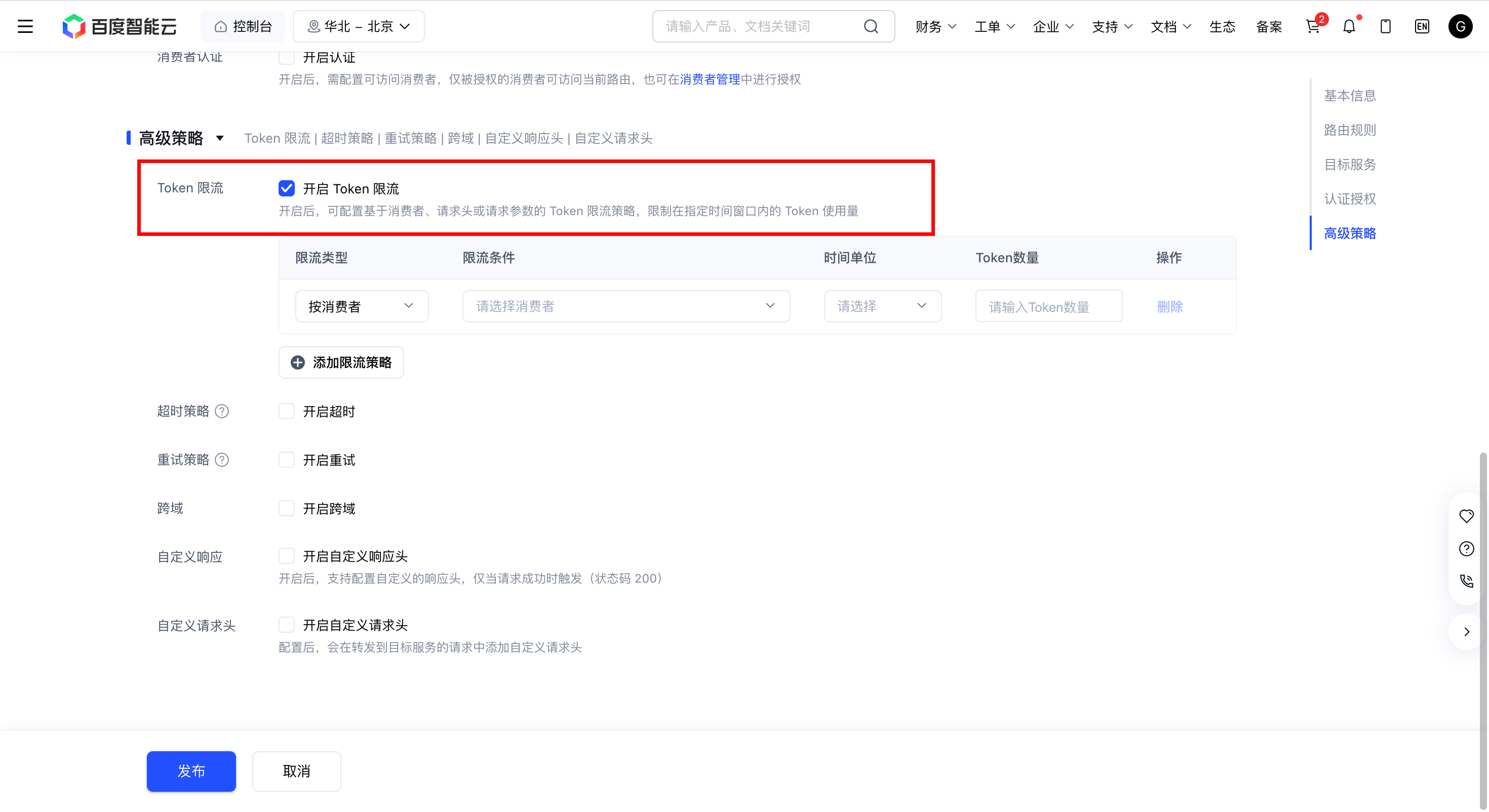
-
在限流策略表格中,单击 添加限流策略 逐条配置规则:
列 说明 限流类型 选择限流的匹配维度,可选项: - 按消费者:以网关消费者(Consumer)为单位限流,常用于多租户场景。
- 按请求头:以请求 Header 中的指定字段值为单位限流,可灵活适配业务自定义标识。
- 按请求参数:以请求 Query 中的指定参数值为单位限流。
限流条件 根据所选限流类型填写: - 按消费者:从下拉列表中选择已存在的消费者。注意:若选择按消费者限流,则需要在认证授权中配置消费者认证。
- 按请求头:填写 Header 名称与对应值,仅命中该精确值的请求计入限流。
- 按请求参数:填写 Query 参数名与对应值,仅命中该精确值的请求计入限流。
时间单位 限流统计的滚动时间窗口,可选 每秒、每分钟、每小时、每天。
窗口到期后限流计数会自动重置,例如选择「每分钟」后,每过 1 分钟阈值重新归零。Token 数量 所选时间窗口内允许消耗的 Token 上限(即限流阈值),取值范围 1–1,000,000。当前窗口内累计消耗超过该上限后,命中该规则的请求将被网关拒绝,直到窗口重置。
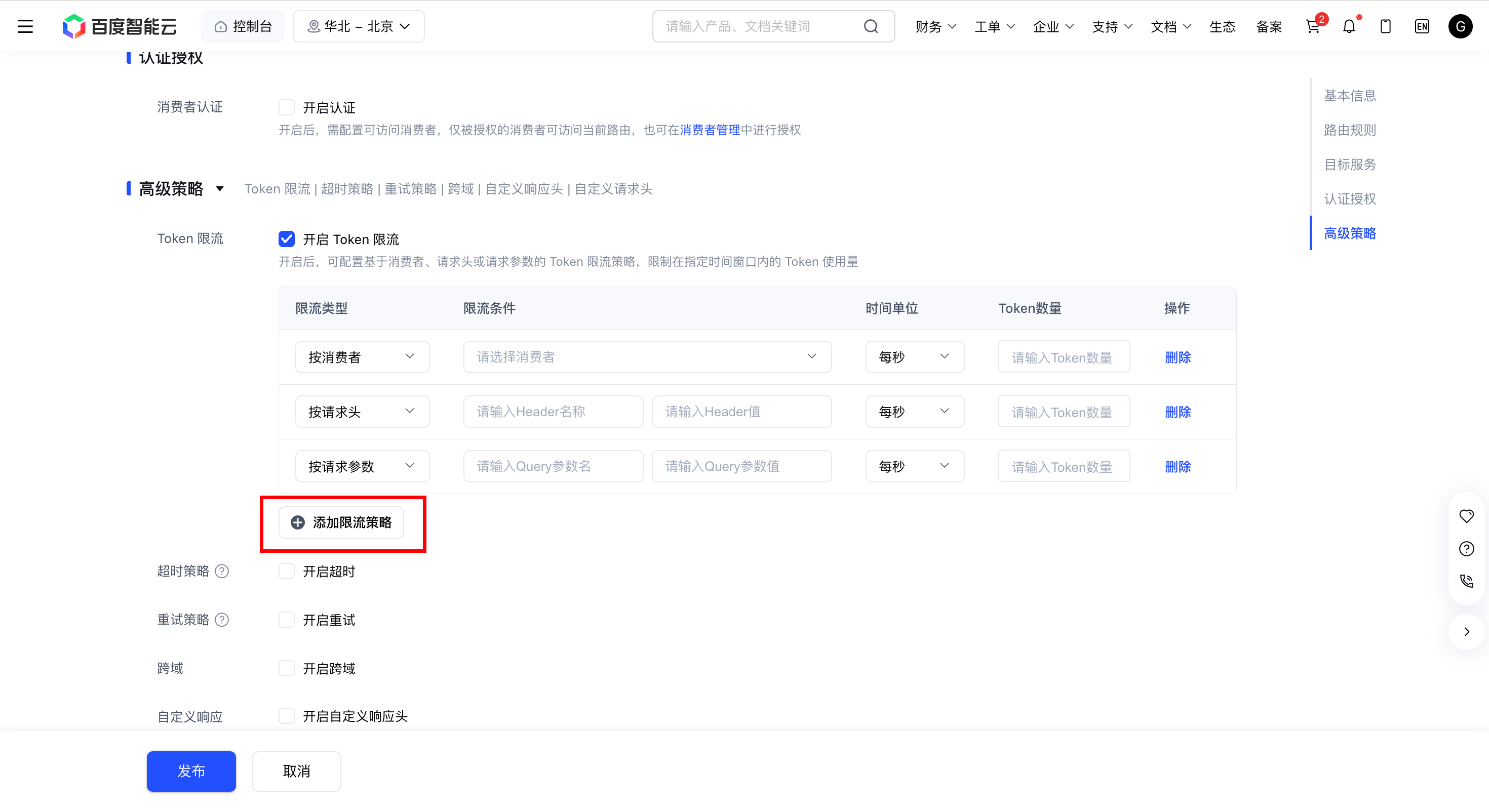
- 如需删除某条限流规则,单击对应行操作列的 删除(至少保留 1 条)。
- 配置完成后,单击页面底部的 发布,策略发布后即时生效。
评价此篇文章