
AI Fallback
概述
AI 原生网关支持模型 Fallback 功能。当系统中配置的 AI 模型无法响应或出错时,网关能自动将请求切换至 Fallback 模型,有效保证应用程序的稳定性和可靠性。本文介绍如何在百度智能云 AI 原生网关上配置 Fallback 模型。
名词解释
AI Fallback 是指在 AI 原生网关上配置的主模型服务不可用时,网关自动将请求切换到 Fallback 备用模型,从而保证应用程序的稳定性和可靠性,避免因为某个模型服务的异常或者高负载造成的请求不可用。
典型应用场景:
- 主模型限流或熔断:主模型服务因 QPS/TPM 限流被拒绝时,自动降级到备用模型继续提供服务。
- 主模型故障:主模型服务连接失败、超时或返回 5xx 错误时,无缝切换到 Fallback 模型。
- 多模型供应商容灾:主模型为供应商 A 提供的模型服务,Fallback 配置为供应商 B 提供的模型服务,构成跨模型供应商的高可用兜底。
- 新旧模型灰度过渡:将稳定的旧模型作为 Fallback,新模型作为主模型,新模型异常时无感切回。
1 ┌──────────────────┐
2 │ 主模型服务 │
3 客户端 ───→ AI ─→│ (正常时返回) │───→ 响应
4 原生 └────────┬─────────┘
5 网关 │ 4xx / 5xx
6 ↓
7 ┌──────────────────┐
8 │ Fallback 模型 │───→ 响应
9 └──────────────────┘说明:当前 Fallback 功能仅支持配置 单个 Fallback 模型服务,暂不支持多级 Fallback 链式回退。
触发条件
当调用主模型服务,返回任意 HTTP 的 4xx、5xx 错误状态码时,均会触发 AI Fallback,由网关将请求自动转发至 Fallback 模型。
具体触发场景包括但不限于:
| 错误码段 | 典型原因 | 是否触发 Fallback |
|---|---|---|
4xx |
鉴权失败、参数错误、配额耗尽、限流(429) | 是 |
5xx |
服务内部错误、网关错误、上游不可用、超时(504) | 是 |
| 连接级错误 | 主模型 Upstream 不可达、TLS 握手失败、连接 reset | 是 |
| 网关本地 2xx | 主模型正常响应 | 否 |
注意:Fallback 触发后会消耗 Fallback 模型的额度,请合理评估容量与费用。
前提条件
- 已开通主模型服务和 Fallback 模型服务,并获取调用所需的 API Key。
- 已创建 AI 原生网关实例,详情参见 创建网关实例。
- 已将主模型和 Fallback 模型添加为目标服务,详情参见 创建服务。支持的服务来源: AI 模型代理。
操作步骤
步骤一:进入推理服务创建/编辑页面
- 登录 AI 原生网关控制台。
- 在左侧导航栏选择实例列表,单击目标实例名称进入实例详情。
- 在实例详情页左侧菜单选择 AI 服务 > 模型推理服务。
- 单击创建推理服务(或选择已有推理服务,单击操作列编辑)。
步骤二:开启 Fallback 并配置 Fallback 模型
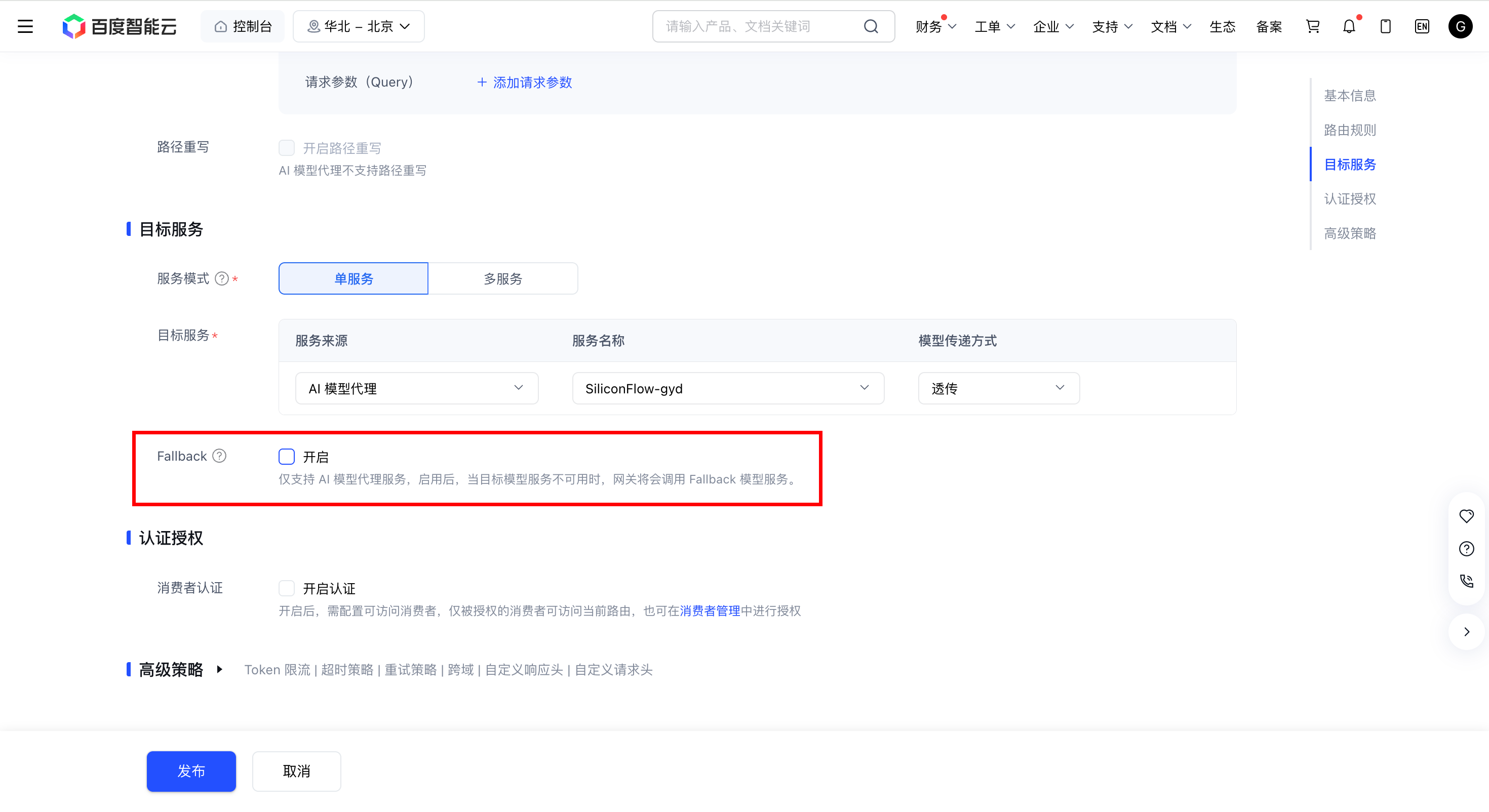
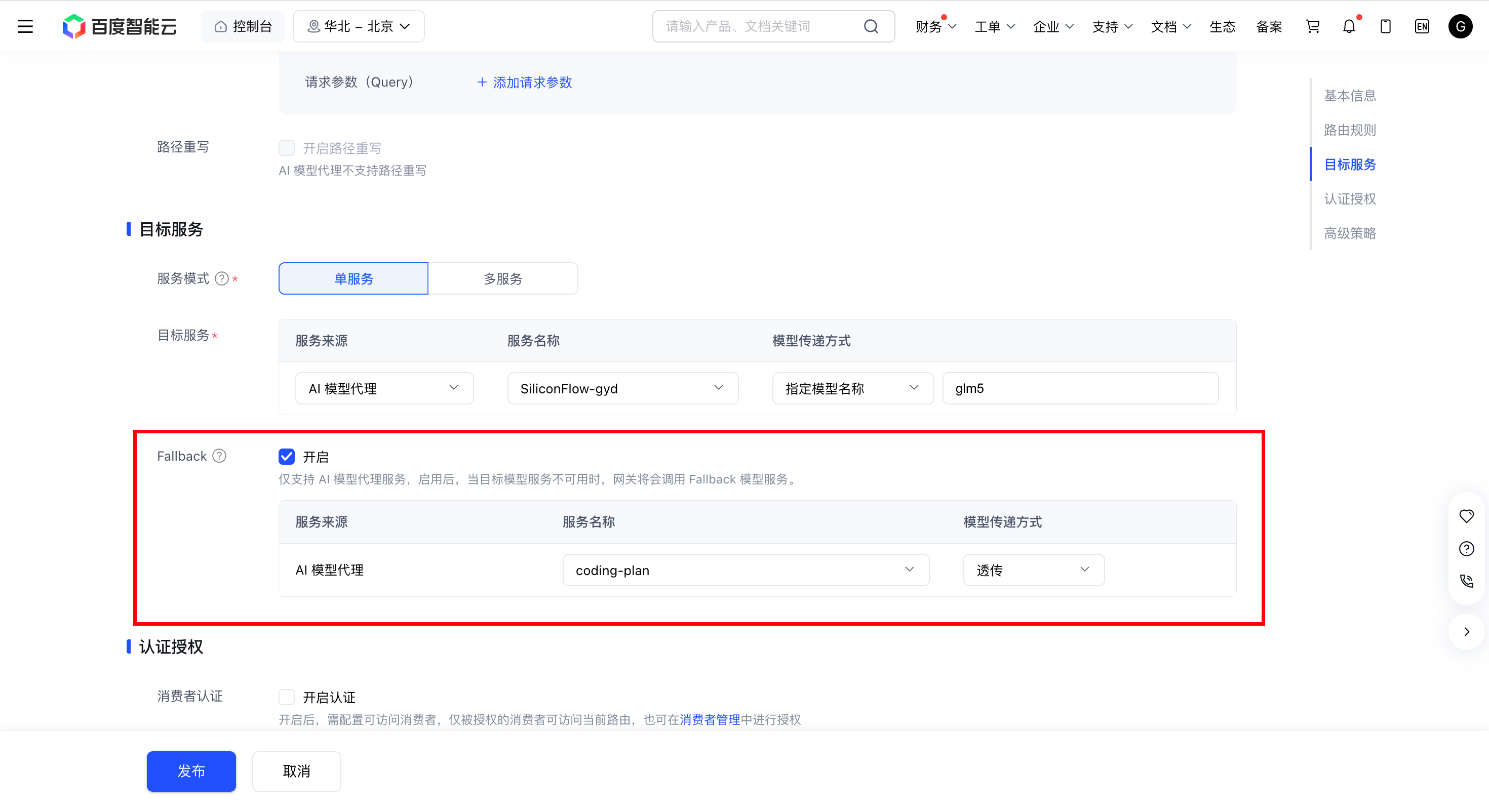
在推理服务配置页的目标服务模块,开启 Fallback 开关,并配置 Fallback 模型。注意:仅当目标服务中服务来源为 AI 模型代理时支持开启 Fallback。
Fallback 配置项说明:
| 配置项 | 说明 |
|---|---|
| Fallback | 是否开启 AI 模型 Fallback 功能。开启后,当后端主模型返回 4xx 或 5xx 错误码时,AI 原生网关会自动将请求切换至 Fallback 模型。 |
| 服务名称 | 配置 Fallback 模型的目标服务,需提前在后端服务列表中创建。 |
| 模型传递方式 | 配置 Fallback 实际调用的目标模型名称。若为透传,则默认透传客户端请求中的 model 字段。若为指定模型名称,则将强制变更为指定模型名称。 |
步骤三:完成配置
确认其他配置项(匹配规则、消费者认证、Token 限流、超时与重试策略等)后,单击确定保存推理服务配置。
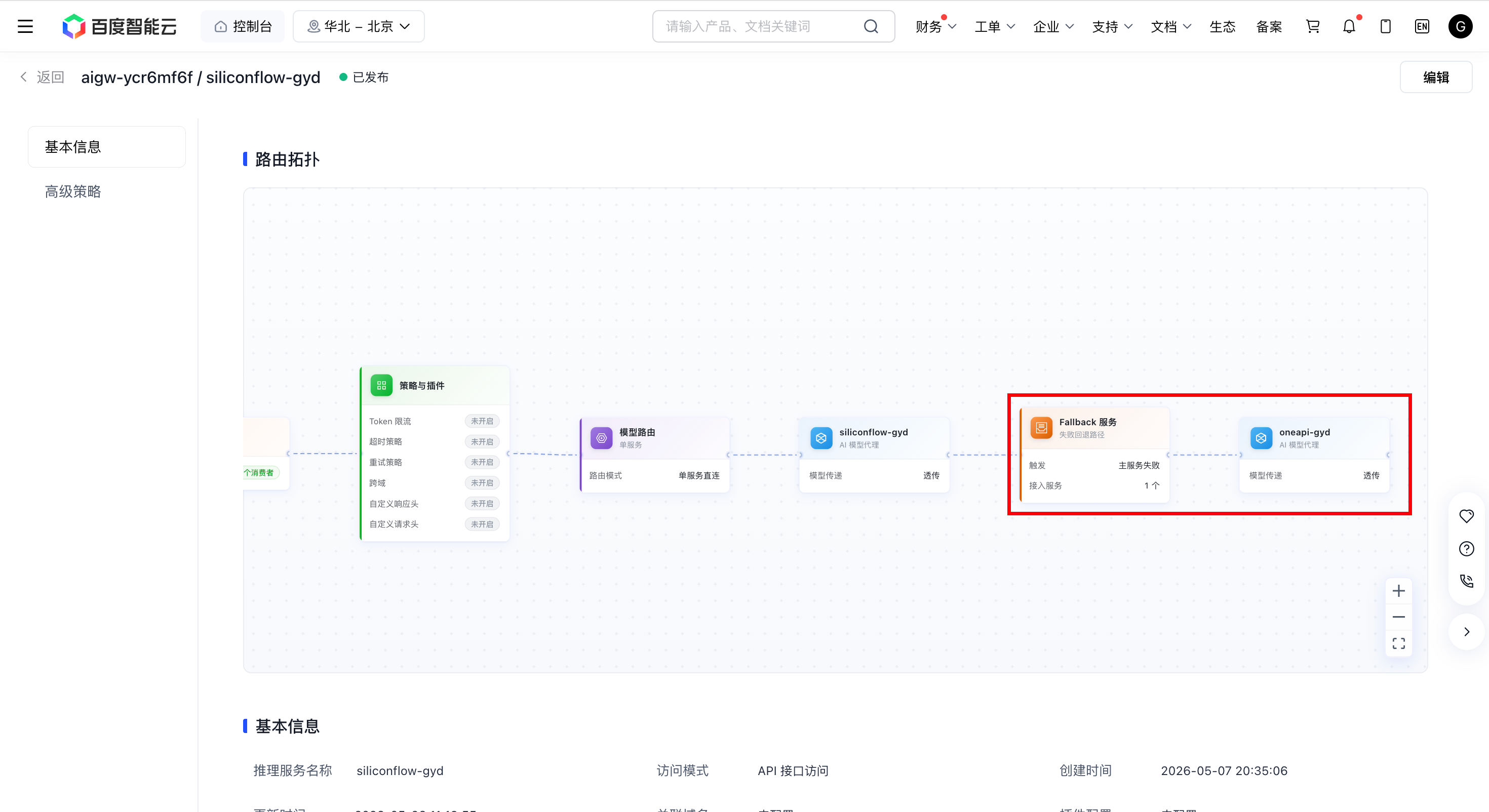
配置完成后,可在推理服务详情页的目标服务模块查看到 Fallback 已生效,并在拓扑视图中看到 Fallback 节点的连线。
常见问题
Q1:开启 Fallback 后,超时策略和重试策略还会生效吗?
会。请求处理顺序为:主模型调用 → 触发主模型的超时与重试策略 → 重试仍失败时触发 Fallback → 调用 Fallback 模型。Fallback 模型本身不参与主模型的重试计数。
Q2:Fallback 模型也失败了怎么办?
如果 Fallback 模型也返回 4xx/5xx,网关会将 Fallback 模型的错误响应返回给客户端,不会再触发二次 Fallback。本期暂不支持多级 Fallback。
Q3:Fallback 流量会被计入 Token 限流吗?
会。Token 限流是基于推理服务粒度的,无论实际命中主模型还是 Fallback,只要存在大模型的响应,消耗的 Token 都计入同一限流计数。
Q4:可以为不同请求路径配置不同的 Fallback 吗?
可以。Fallback 是推理服务粒度的配置,为不同推理服务(不同的匹配路径 / 域名)配置独立的 Fallback 模型即可。
Q5:百舸来源创建的路由能配置 Fallback 吗?
百舸同步创建的路由暂不支持在 AI 原生网关侧编辑 Fallback 配置。
评价此篇文章