
应用场景
AI 训练
在 AI 训练场景中,海量数据集的高效读取与 Checkpoint 的快速保存/加载,直接决定了训练效率与 GPU 利用率。RapidFS 通过提供极致读写性能与灵活的数据流转能力,可在数据湖之上显著加速模型训练流程,减少因 IO 瓶颈带来的训练阻塞。
RapidFS 支持将对象存储中的训练数据预热至高性能缓存,实现数百 GBps 吞吐与亚毫秒级读取时延;同时通过并行写与异步持久化机制,大幅缩短 Checkpoint 保存时间,降低 GPU 等待开销。此外,基于智能预热与淘汰策略,系统可实现冷热数据分层与透明流转,在保障性能的同时有效控制存储成本。

推理模型分发
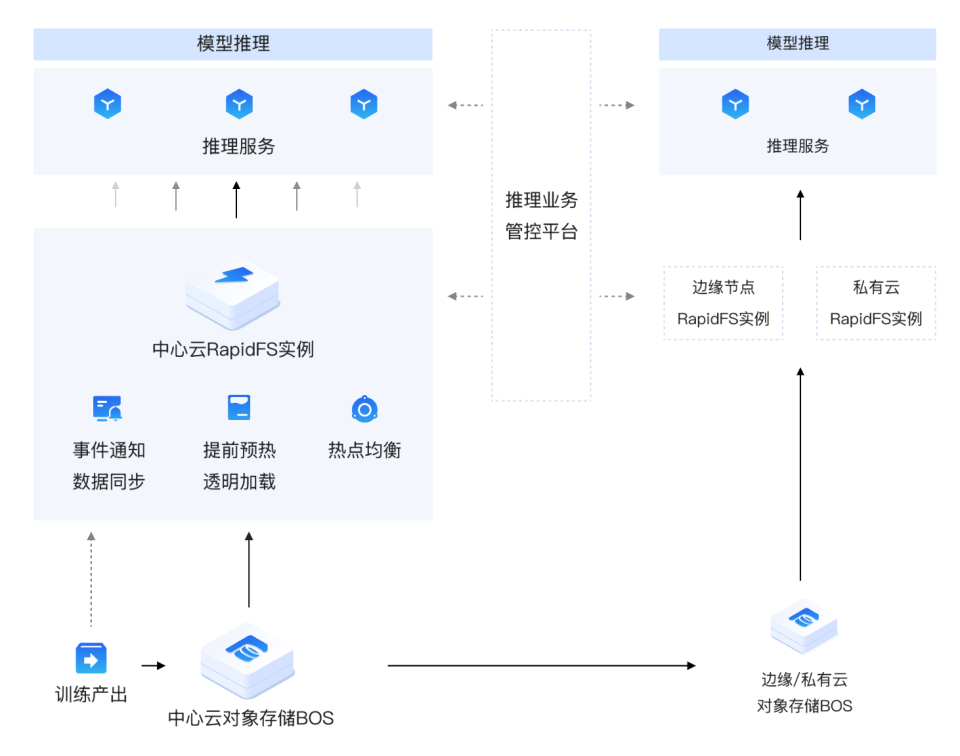
在大模型推理场景中,模型文件需要在极短时间内分发至成百上千的推理节点,并能够灵活响应模型迭代与算力调度带来的频繁变更,这对存储系统的并发读取能力与分发效率提出了极高要求。RapidFS 依托高吞吐、高并发访问能力及数据透明访问机制,可高效支撑超大规模推理服务的模型分发与部署。
RapidFS 通过近计算缓存、细粒度分片与多副本负载均衡能力,加速千卡乃至万卡规模下的并发启动与模型加载;同时在模型迭代时自动触发数据同步与预热,实现模型快速上线与平滑切换。此外,结合对象存储的跨地域复制与事件通知机制,可实现多地域、多 IDC 及云边私环境下的模型协同分发与统一管理。
数据处理与分析
在数据处理与分析场景中,通常面临数据规模庞大、吞吐需求高以及对计算生态依赖广泛等挑战。基于 BOS 数据湖存储底座,结合 RapidFS 的加速能力,可在兼顾性能与语义的同时,相比传统 HDFS 或单独对象存储方案提供更优的整体体验,满足大规模数据分析与计算需求。
RapidFS 提供顺序读写百 GBps 级吞吐能力,并在随机读密集型分析任务中实现数倍 IO 性能提升;同时支持 HCFS SDK、POSIX 挂载等多种访问方式,兼容主流大数据与分析引擎。在语义层面,系统提供原生层级目录结构与完善文件语义,结合流式处理能力,为数据湖之上的批处理与实时分析提供更加高效、易用的基础支撑。
评价此篇文章