
吕声辉,飞桨开发者技术专家(PPDE),某网络科技公司研发工程师。主要研究方向为图像识别,自然语言处理等。
• AI Studio主页
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/227158
01 项目背景
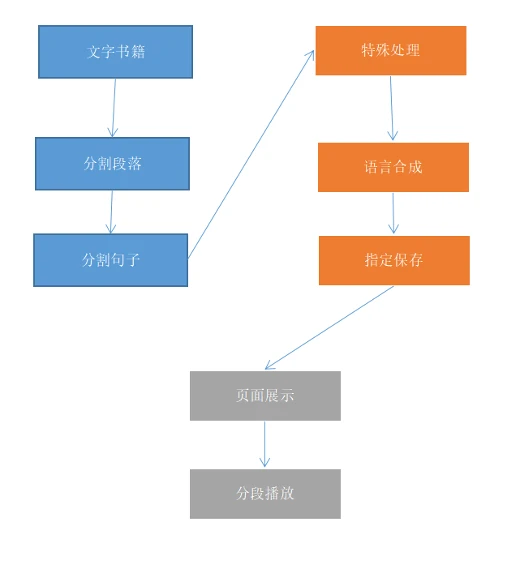
随着互联网的发展,普通用户对于书籍展示形式的需求已由纯文字变成了图文、语音、视频等多种形式,因此将文本书籍转换为有声读物具有很大的市场需求。本文以飞桨语音模型库PaddleSpeech提供的语音合成技术为核心,通过音色克隆、语速设置、音量调整等附加功能,展示有声书籍的技术可行方案。
02 环境准备
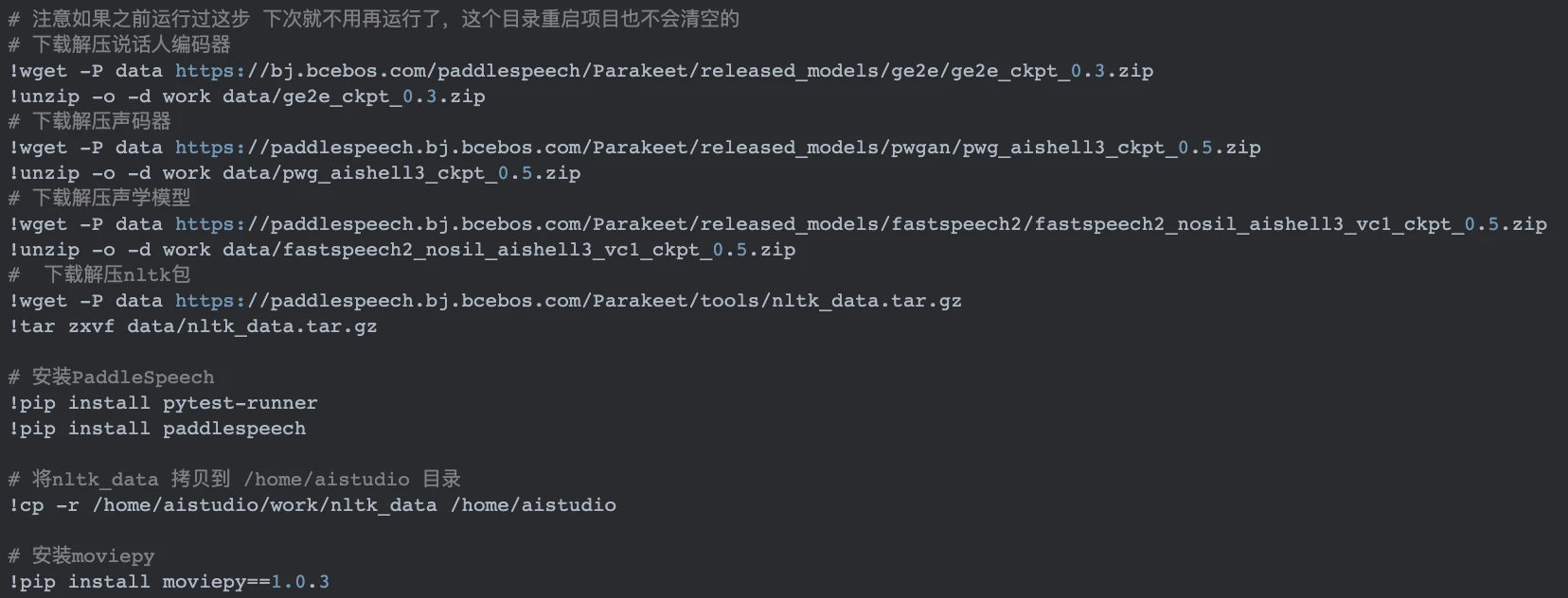
PaddleSpeech 是基于飞桨的语音方向开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习的前沿和有影响力的模型。首先进行PaddleSpeech安装环境的配置,配置如下:
03 数据处理
每本书的内容均以json格式存放在txt文本中,路径为/work/books/inputs/bookname.txt。为方便演示,这里以三国演义为例。

04 音频合成
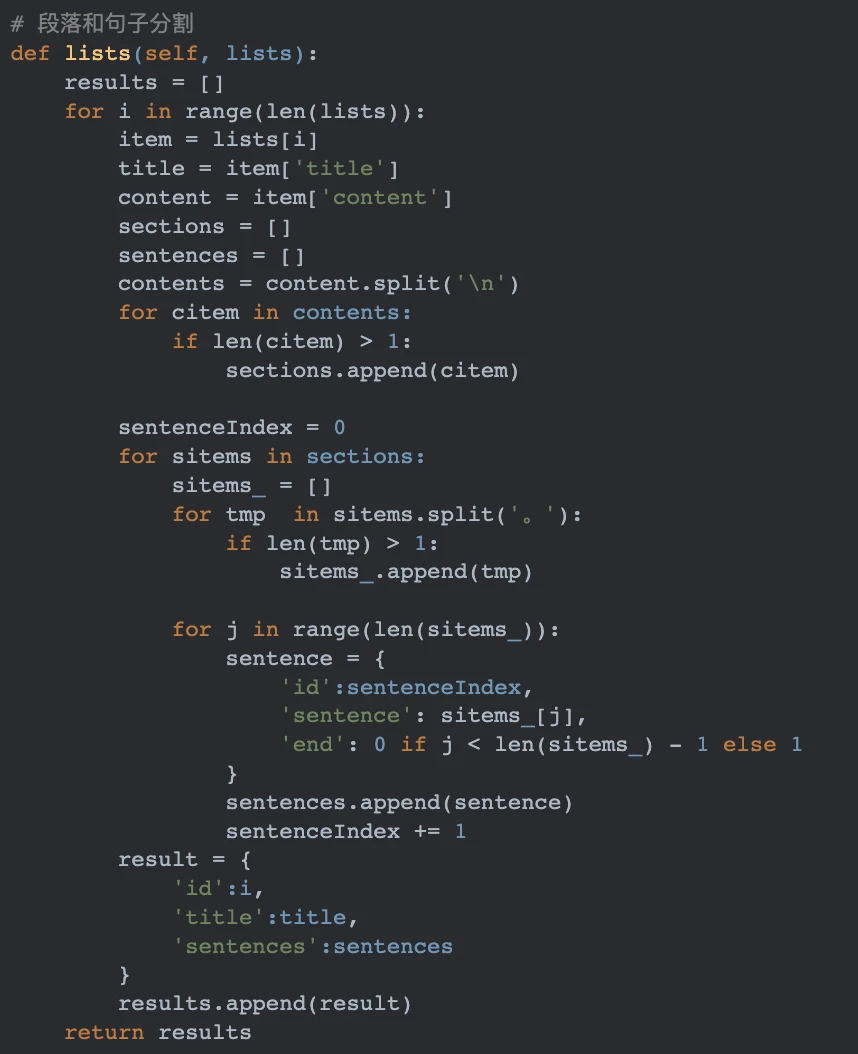
PART 1 段落句子分割
以换行符"\n"分割为段落,以"。"分割为句子。
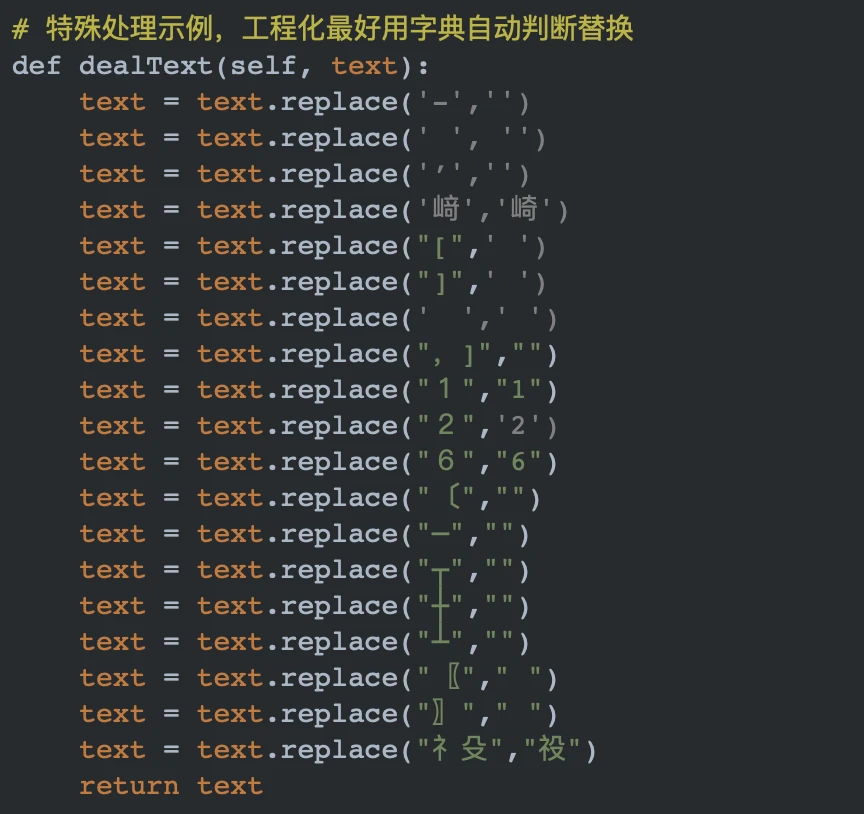
PART2 特殊字符处理
在国学书籍中,有可能出现很多生僻字或者特殊符号,这里需要做针对性的替换。
PART3 音频合成
根据分割的ID,保存到对应位置。
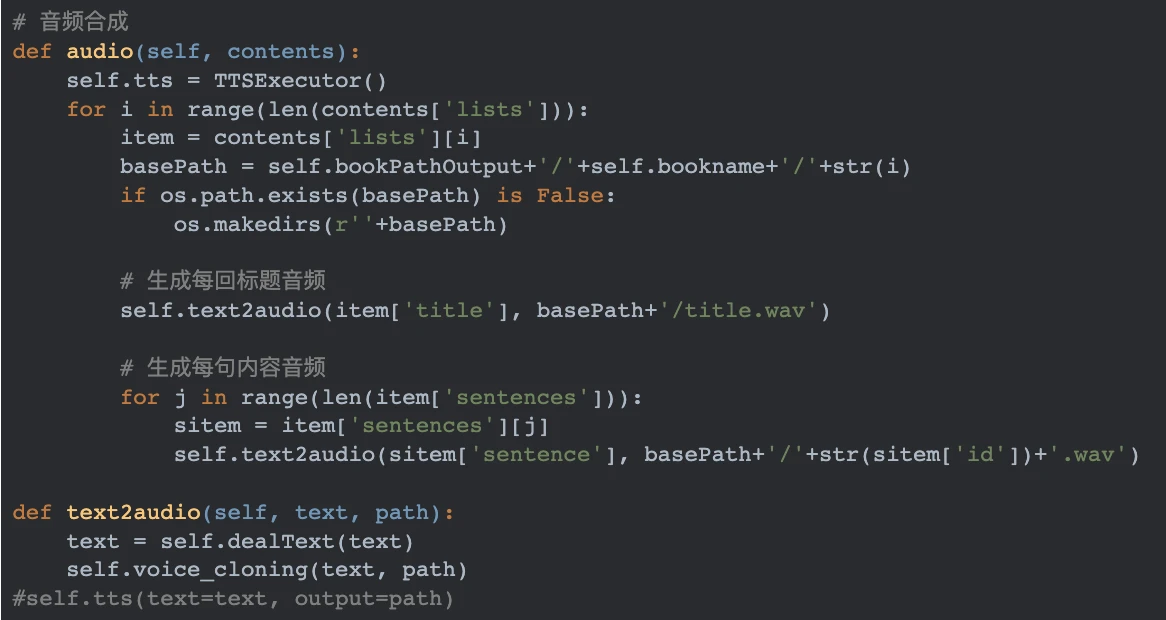
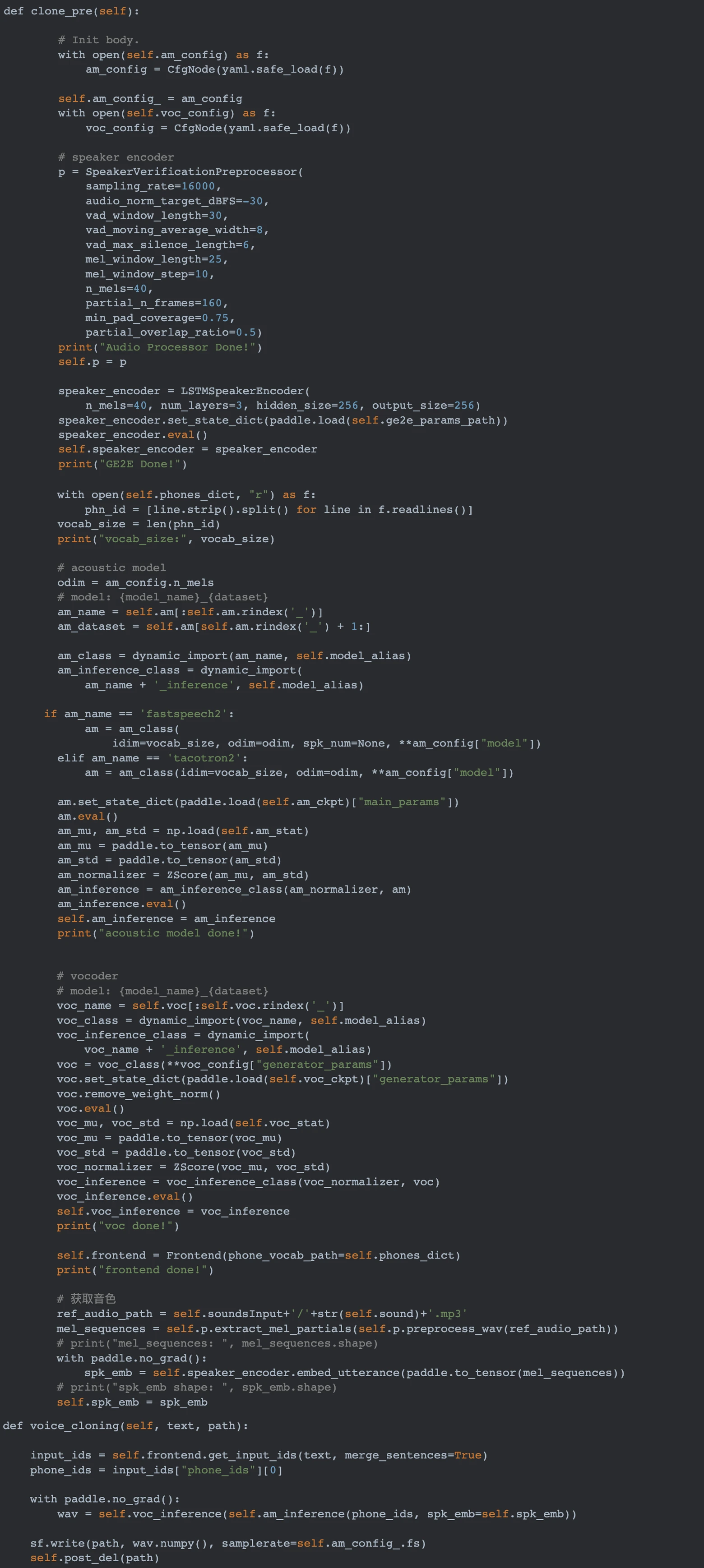
PART4 音色克隆
可以事先将不同音色音频放置在 /work/sounds 目录下。此处音色克隆部分的功能主要参考自PaddleSpeech语音克隆项目。
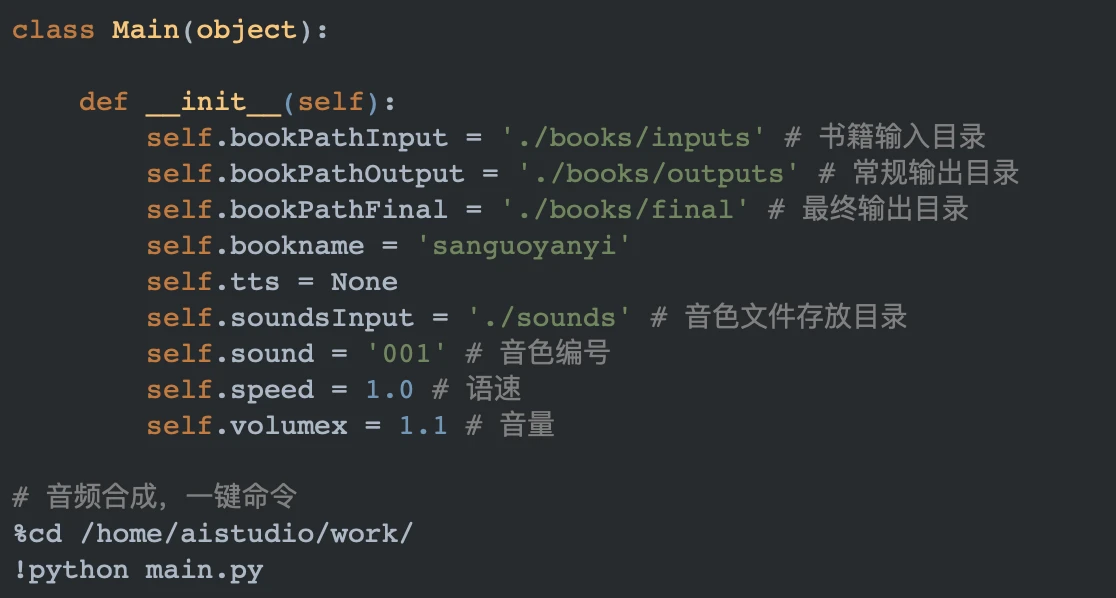
PART5 语速和音量调整

音色、语速和音量需要在 main.py 的头部中设置。
PART6 查看生成结果
最终切分好的数据在/work/outputs/sanguoyanyi目录下,原始语速和音量音频在outputs目录下,指定语速和音量音频在final目录下。其中的outputs.txt为切分内容,而音频会按照每个章节以及每个章节的句子索引排序好。
以下为outputs.txt 内容:

以下为第一回的每个句子wav格式音频。
05 客户端展示
输出第三部分生成好的内容和音频。这里用H5页面简单展示一下有声书阅读的效果,包括内容展示和逐句朗读高亮两种功能。
展示视频可以到飞桨微信公众号查看~
-
H5的具体代码已放在GitHub 上,大家可在下方链接中查看:https://github.com/lvsh2012/book2audio
-
手机或者PC也可直接体验:https://book.weixin12306.com/
06 总结
通过PaddleSpeech可以简单快速地实现语音合成功能,轻松实现书籍有声化。使用者在这里需要关注下,当以H5展示播放效果时,需要注意内容和音频的对应关系。除了语音合成功能外,PaddleSpeech还提供了包括语音识别、声纹提取、标点恢复等其他功能。相信大家基于PaddleSpeech可以在该领域挖掘出更多的可能性!