- 概览
- 方案概述
- 数据采集
- 创建消息服务BMS Topic
- 安装BLS收集器
- 创建BLS传输任务
- 数据计算(Python)
- 创建BMR Spark集群
- 下载Spark Kafka Streaming依赖
- 编写Spark Streaming程序
- 下载百度消息服务的证书
- 创建连接Kafka配置文件
- 提交Streaming作业
- 查看作业输出
- 注意事项
- 数据计算(Scala)
- 创建BMR Spark集群
- 下载Spark Kafka Streaming依赖
- 下载百度消息服务的证书
- 创建连接Kafka配置文件
- 提交Streaming作业
- 查看作业输出
- 注意事项
- 相关产品
流式应用场景
概览
实现云上流式场景下数据流打通,方便用户在百度智能云上使用各个产品实现流式需求,实现流式数据处理全流程。
## 需求场景
### 事件流
事件流具能够持续产生大量的数据,这类数据最早出现与传统的银行和股票交易领域,也在互联网监控、无线通信网等领域出现、需要以近实时的方式对更新数据流进行复杂分析如趋势分析、预测、监控等。简单来说,事件流采用的是查询保持静态,语句是固定的,数据不断变化的方式。
### 持续计算
比如对于大型网站的流式数据:网站的访问PV/UV、用户访问了什么内容、搜索了什么内容等,实时的数据计算和分析可以动态实时地刷新用户访问数据,展示网站实时流量的变化情况,分析每天各小时的流量和用户分布情况;比如金融行业,毫秒级延迟的需求至关重要。一些需要实时处理数据的场景也可以应用Flink/Kafka,比如根据用户行为产生的日志文件进行实时分析,对用户进行商品的实时推荐等。
方案概述
本场景应用于数据流式处理,使用到BLS(百度Log Service)、BMS(百度消息服务)以及BMR(MapReduce)三个产品。
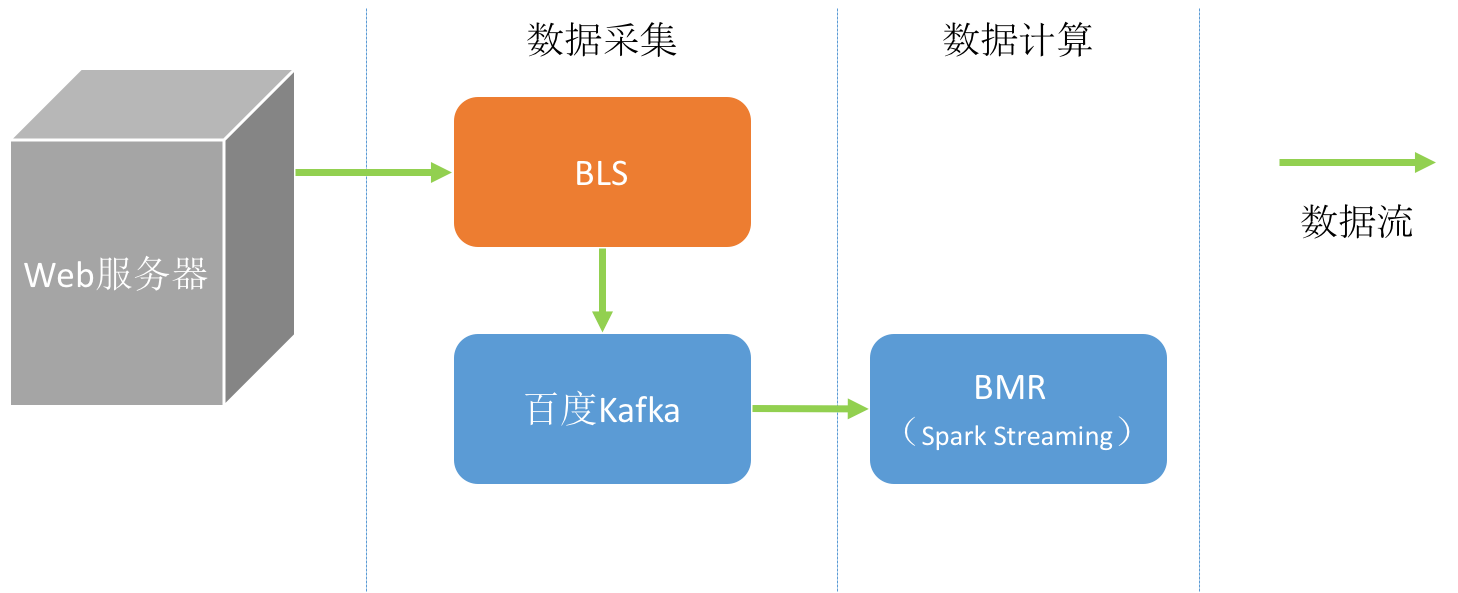
整个流程分为数据采集和数据计算两部分。
数据采集
数据采集过程通过BLS以及百度消息服务BMS实现。
创建消息服务BMS Topic
参考文档:创建BMS主题。
目前百度消息服务BMS支持“华北-北京”、“华南-广州”以及“香港2区”三个地区,创建主题前可以根据具体需求选择不同的区域。

安装BLS收集器
参考文档:安装收集器
选择“收集器安装”,选择相应的操作系统后,点击“复制”;
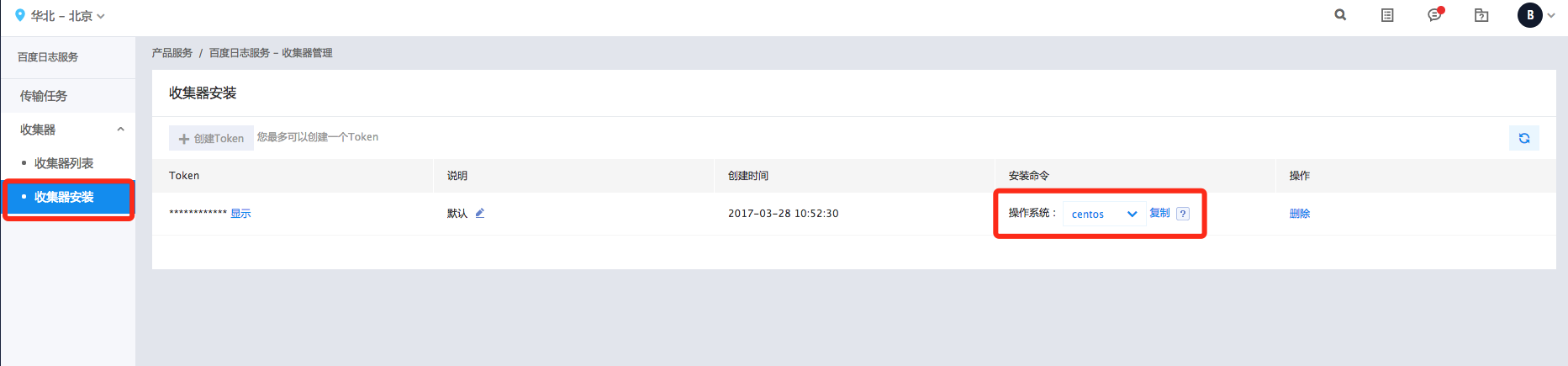
登录需要传输日志的主机,在root权限下执行所“复制”的安装命令。

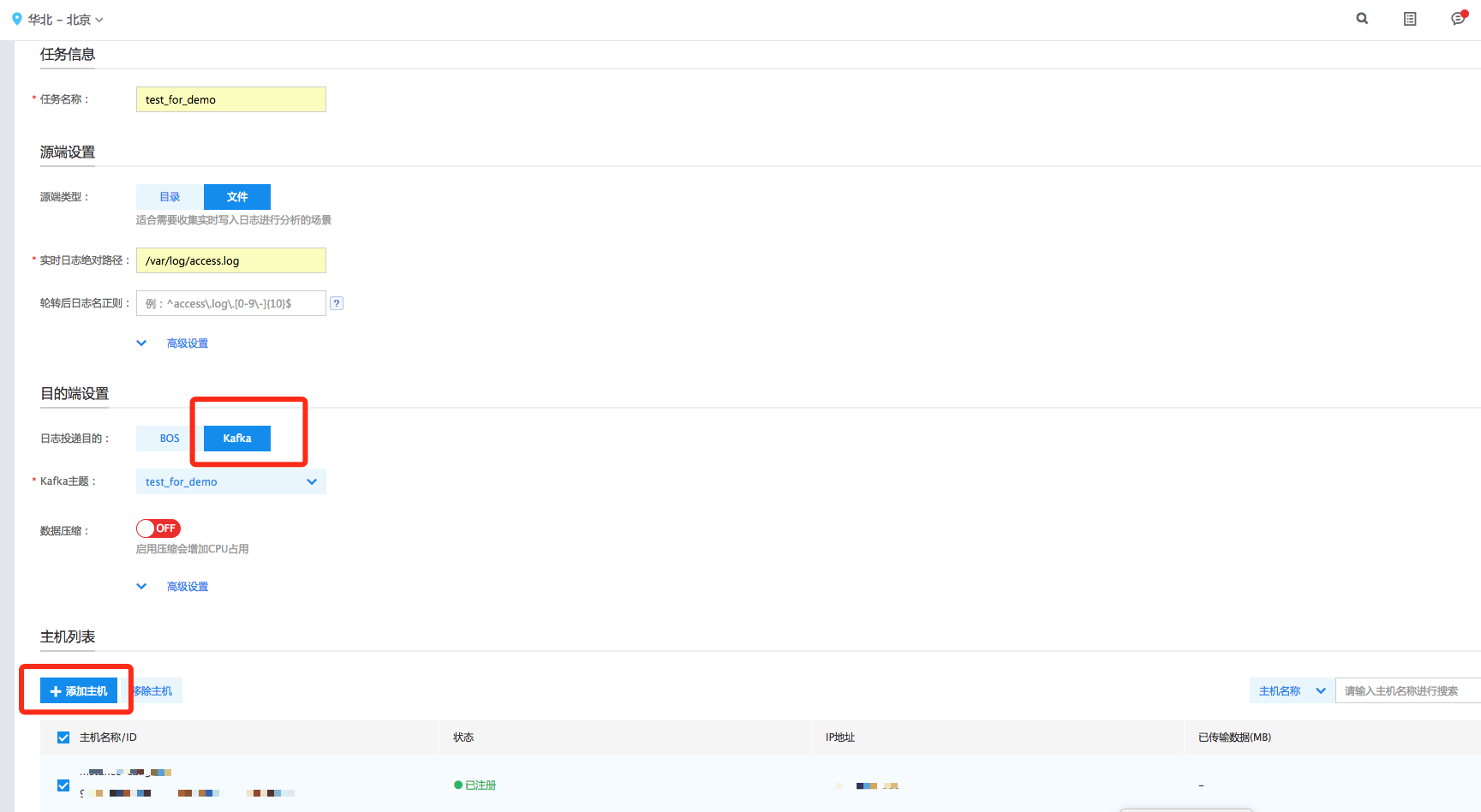
创建BLS传输任务
具体步骤为: 1. 在传输任务列表页面,点击“创建传输任务”,进入创建传输任务页面; 2. 在“任务信息”区,输入任务名称; 3. 在“源端设置”区,根据源数据类型,选择不通的源端类型以及进行相应的配置; 4. 在“目的端设置”区,选择“Kafka”作为日志投递目的; 5. 在“主机列表”区,点击“添加主机”,选择安装好“收集器”的主机; 6. 在“主机列表”区,选择需部署该传输任务的主机,点击“创建”;
详细操作步骤请参考文档:创建传输任务。
目前百度消息服务支持“华北-北京”、“华南-广州”两个地区,创建topic前可以根据具体需求选择不同的区域。
数据计算(Python)
数据计算过程通过BMR的Spark Streaming连接百度消息服务。本文以使用PySpark为例,Spark版本1.6,线上Kafka版本0.10。具体步骤如下:
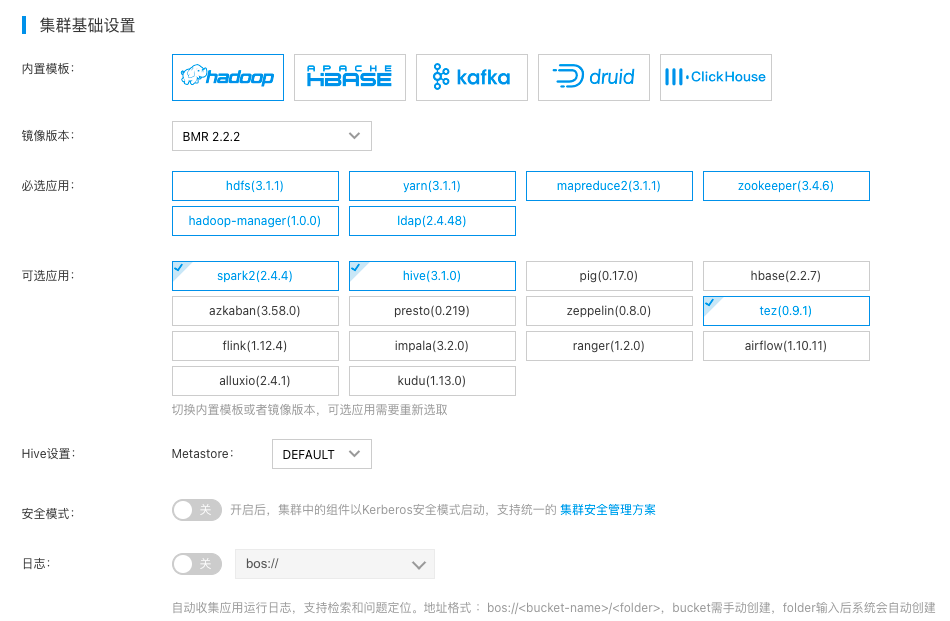
创建BMR Spark集群
参考文档:创建集群
注意:在“集群配置”区,选择“Spark”内置模板,并将Spark选上。
下载Spark Kafka Streaming依赖
# eip可以在BMR Console集群详情页的实例列表获取
ssh root@eip
# 切换到hdfs用户
su hdfs
cd
# 下载依赖
wget http://bmr-public-bj.bj.bcebos.com/sample/spark-streaming-kafka-0-10-assembly_2.10-1.6.0.jar备注
获取集群登录公网IP
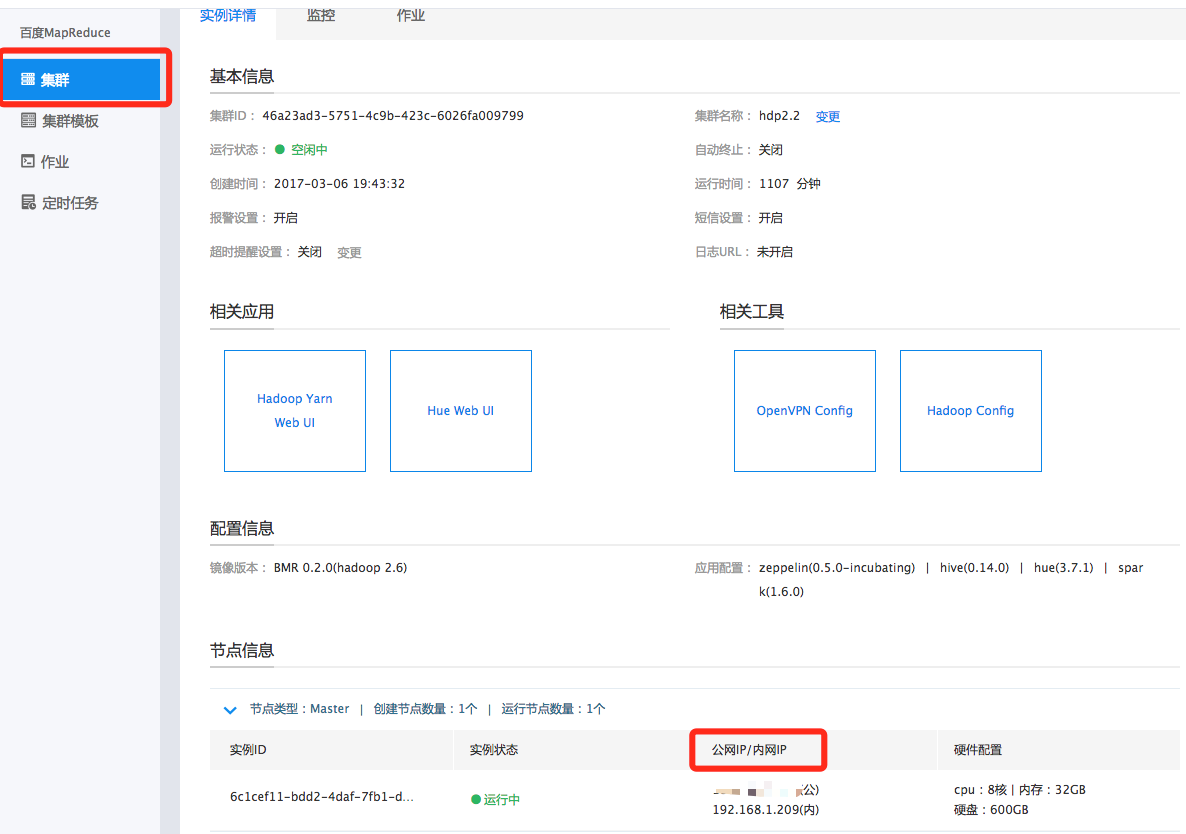
编写Spark Streaming程序
以Kafka_wordcount为例,使用前请删除文中注释:
from __future__ import print_function
import sys
import ConfigParser
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka010 import KafkaUtils
from pyspark.streaming.kafka010 import PreferConsistent
from pyspark.streaming.kafka010 import Subscribe
# 读取配置文件
def read_config(file_name):
cf = ConfigParser.ConfigParser()
# read config file
cf.read(file_name)
# read kafka config
section = "kafka"
opts = cf.options(section)
config = {}
for opt in opts:
# topics should be a list
if opt == "topics":
config[opt] = str.split(cf.get(section, opt), ",")
else:
config[opt] = cf.get(section, opt)
return config
if __name__ == "__main__":
"""
if len(sys.argv) != 3:
print("Usage: kafka_wordcount.py <bootstrap-server> <topic>", file=sys.stderr)
exit(-1)
"""
# 建立SparkContext和StreamingContext,demo处理间隔为20s
sc = SparkContext(appName="PythonStreamingKafkaWordCount")
ssc = StreamingContext(sc, 20)
# 读取配置文件test.conf,获取连接百度Kafka参数
config_file = "test.conf"
kafkaParams = read_config(config_file)
# 建立kafka输入流
topics = kafkaParams["topics"]
kvs = KafkaUtils.createDirectStream(ssc, PreferConsistent(), Subscribe(topics, kafkaParams))
lines = kvs.map(lambda x: x[1])
counts = lines.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a+b)
counts.pprint()
# 启动StreamingContext
ssc.start()
ssc.awaitTermination()下载百度消息服务的证书
下载证书:
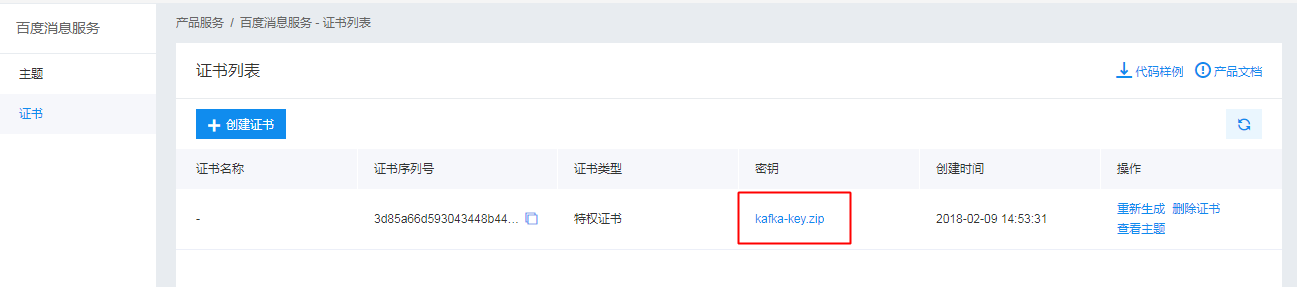
创建连接Kafka配置文件
以“test.conf"为例:
vi test.conf
# 写入如下内容
[kafka]
bootstrap.servers = kafka.bj.baidubce.com:9091
topics = test_for_demo
group.id = test
# 以下为SSL配置,根据client.properties中的内容进行更换
security.protocol = SSL
ssl.truststore.password = test_truststore_password
ssl.truststore.location = client.truststore.jks
ssl.keystore.location = client.keystore.jks
ssl.keystore.password = test_keystore_password参数说明:
bootstrap.servers: kafka服务地址
topics: 需要消费的topic,如需消费多个topic,以逗号分割,如topic1,topic2,topic3
group.id: consumer group的id,请不要随意设置,以免与其他用户冲突(kafka服务未来将支持groupId隔离)更多配置见:http://kafka.apache.org/0100/documentation.html#newconsumerconfigs
提交Streaming作业
按照如上四步,当前目录(hdfs home目录)有五个文件:test.conf、client.truststore.jks、client.keystore.jks、kafka_wordcount.py、spark-streaming-kafka-0-10-assembly_2.10-1.6.0.jar:

使用spark-submit提交streaming作业:
/usr/bin/spark-submit --master yarn --deploy-mode cluster --files test.conf,client.keystore.jks,client.truststore.jks --jars spark-streaming-kafka-0-10-assembly_2.10-1.6.0.jar kafka_wordcount.py查看作业输出
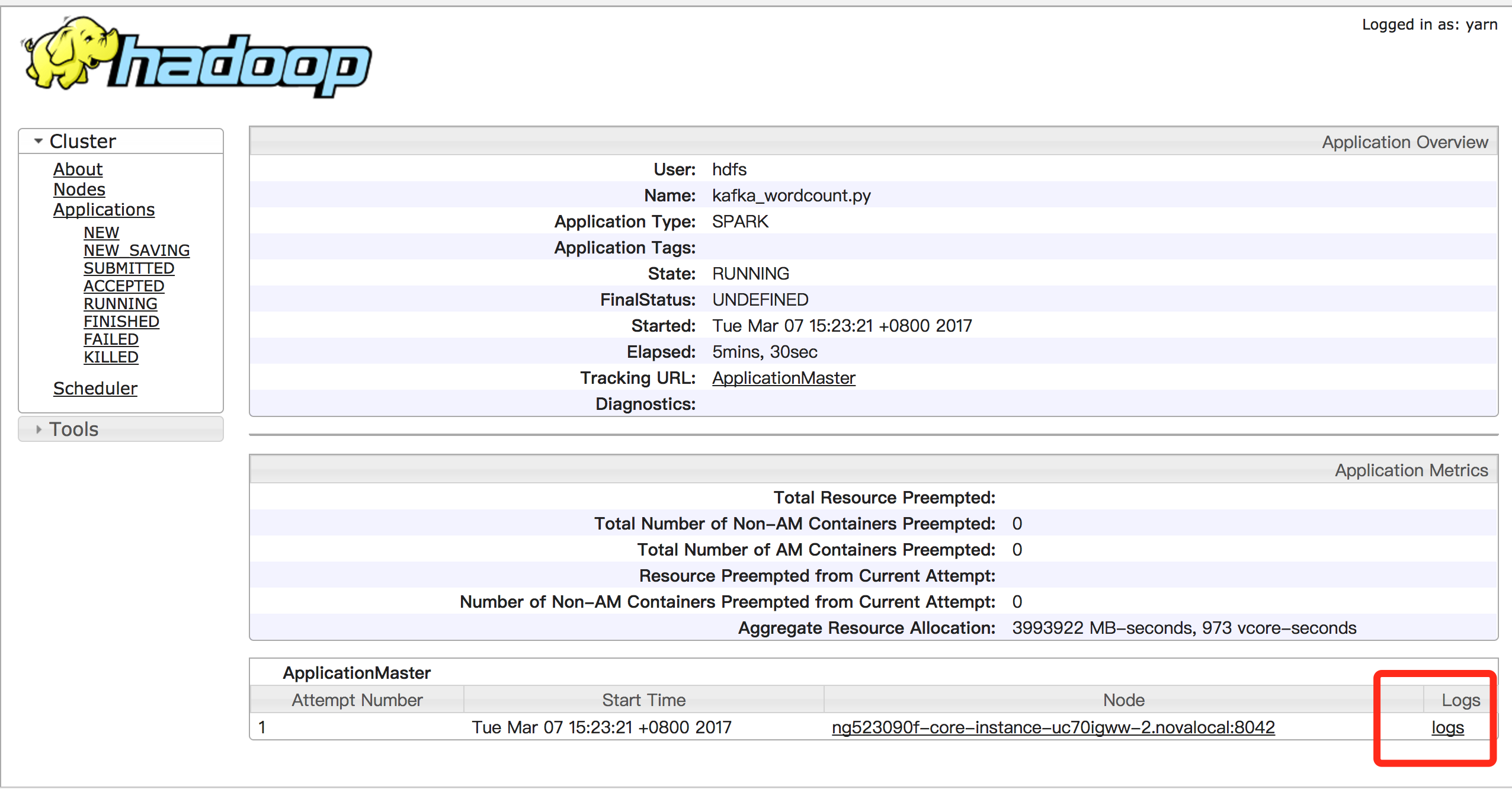
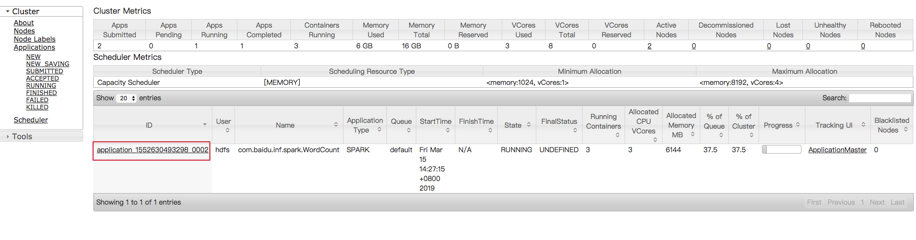
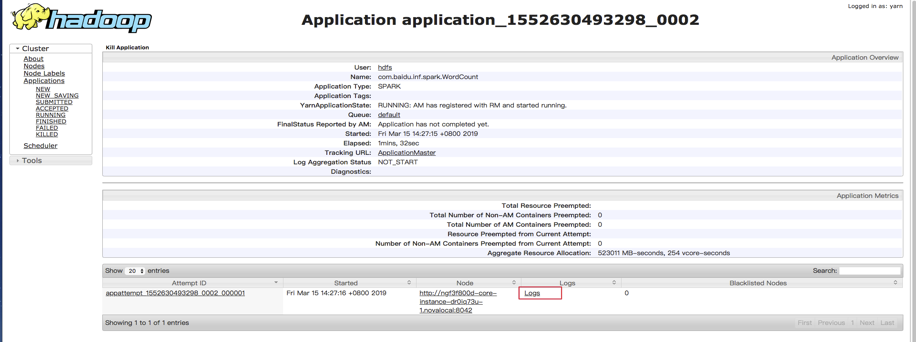
在“集群详情页”点开“Hadoop Yarn Web UI”,即可打开yarn console:
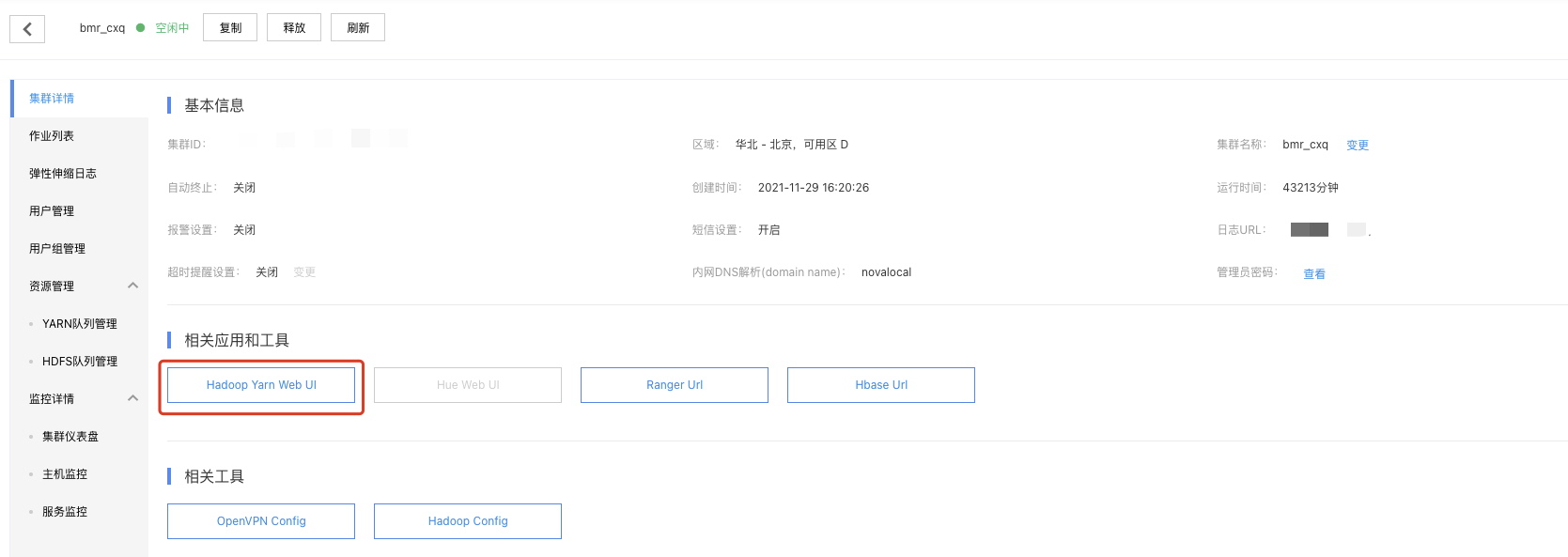
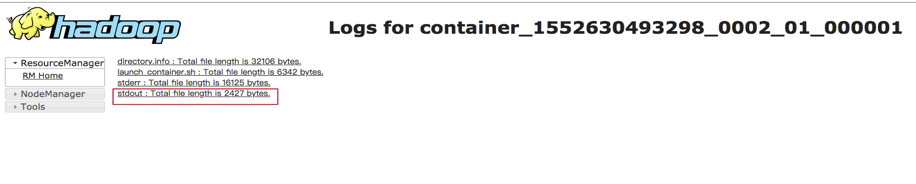
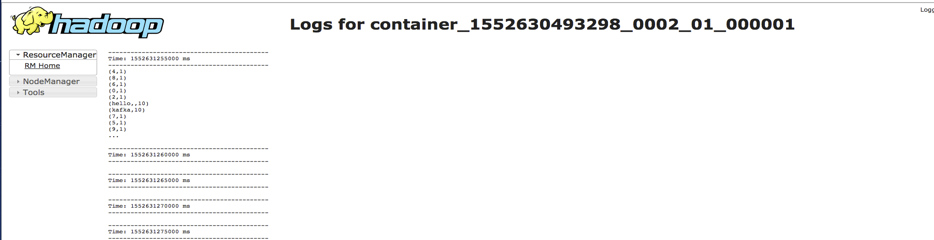
在yarn console可以查看对应application的日志,用以查看程序的输出,以kafka_wordcount为例,输出在stdout中:
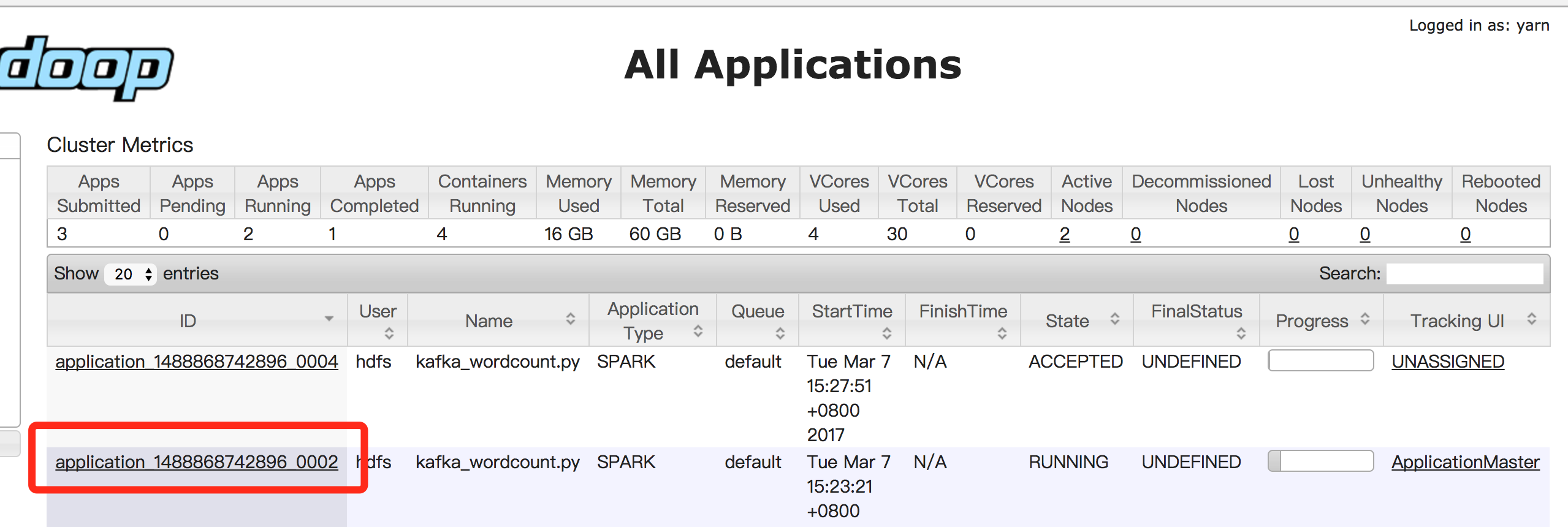
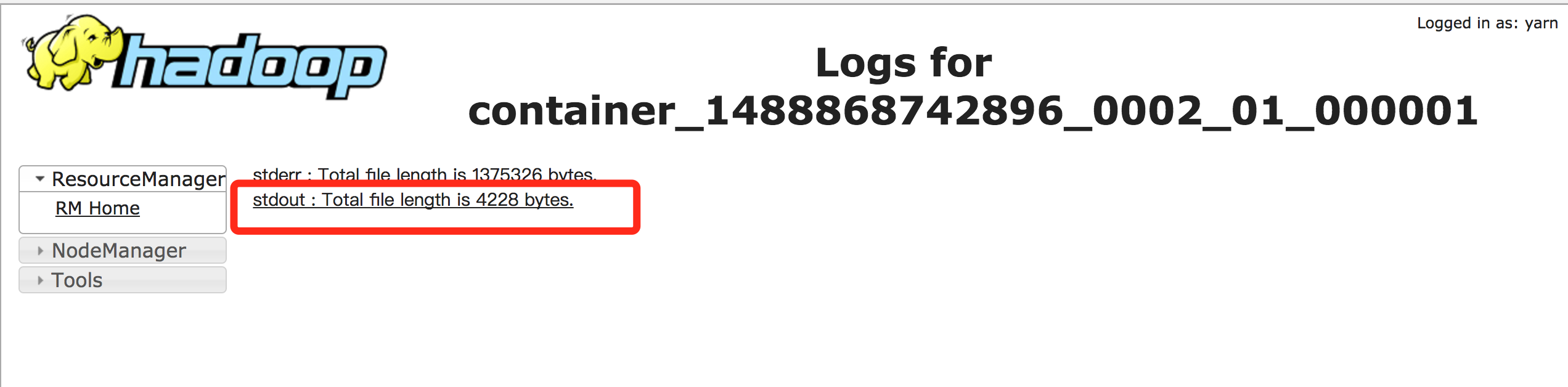

注意事项
如果需要停掉某个作业,可以使用“yarn application -kill applicationId”命令,例如:
yarn application -kill application_1488868742896_0002同时跑多个作业,请注意修改test.conf中的group.id配置
数据计算(Scala)
数据计算过程通过BMR的Spark Streaming连接百度消息服务BMS。本文以使用Scala为例,Spark版本2.1,线上Kafka版本0.10。具体步骤如下:
创建BMR Spark集群
参考文档:创建集群
注意:在“集群配置”区,选择“Spark2”内置模板,并将Spark选上。
下载Spark Kafka Streaming依赖
# eip可以在BMR Console集群详情页的实例列表获取
ssh root@eip
# 切换到hdfs用户
su hdfs
cd
# 下载依赖
wget https://bmr-public-bj.bj.bcebos.com/sample/original-kafke-read-streaming-1.0-SNAPSHOT.jar下载百度消息服务的证书
下载证书:
创建连接Kafka配置文件
以“test.conf"为例:
vi test.conf
# 写入如下内容
[kafka]
bootstrap.servers = kafka.bj.baidubce.com:9091
topics = test_for_demo
group.id = test
# 以下为SSL配置,根据client.properties中的内容进行更换
security.protocol = SSL
ssl.truststore.password = test_truststore_password
ssl.truststore.location = client.truststore.jks
ssl.keystore.location = client.keystore.jks
ssl.keystore.password = test_keystore_password参数说明:
bootstrap.servers: kafka服务地址
topics: 需要消费的topic,如需消费多个topic,以逗号分割,如topic1,topic2,topic3
group.id: consumer group的id,请不要随意设置,以免与其他用户冲突(kafka服务未来将支持groupId隔离)更多配置见:http://kafka.apache.org/0100/documentation.html#newconsumerconfigs
提交Streaming作业
按照如上四步,当前目录有四个文件:test.conf、client.truststore.jks、client.keystore.jks、

使用spark-submit提交streaming作业:
spark-submit --class com.baidu.inf.spark.WordCount --master yarn --deploy-mode cluster --files test.conf,client.keystore.jks,client.truststore.jks ./original-kafke-read-streaming-1.0-SNAPSHOT.jar "$topics" "$bootstrap.servers" "$group.id" "$ssl.truststore.password" "$ssl.keystore.password"(注意:这里请替换掉命令中最后面5个参数值为实际的值,即文件test.conf中描述的字段。)
例子:
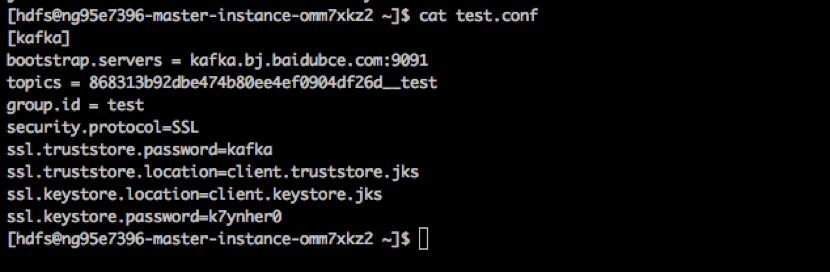
spark-submit --class com.baidu.inf.spark.WordCount --master yarn --deploy-mode cluster --files test.conf,client.keystore.jks,client.truststore.jks ./original-kafke-read-streaming-1.0-SNAPSHOT.jar "868313b92dbe474b80ee4ef0904df26d__test" "kafka.bj.baidubce.com:9091" "test" "kafka" "k7ynher0"附上WordCount 示例代码:
package com.baidu.inf.spark
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WordCount {
def className = this.getClass.getName.stripSuffix("$")
def main(args: Array[String]): Unit = {
if (args.length < 4) {
System.err.println(
s"Usage:Input Params: "
+ " <topic> "
+ " <bootstrap.servers> "
+ " <group.id> "
+ " <ssl.truststore.password>"
+ " <ssl.keystore.password>"
)
sys.exit(1)
}
val Array(topic, bootstrap, group,
truststore, keystore, _*) = args
val conf = new SparkConf().setAppName(className).setIfMissing("spark.master", "local[2]")
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val ssc = new StreamingContext(conf, Seconds(5))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> bootstrap,
"key.deserializer" -> classOf[StringDeserializer].getName,
"value.deserializer" -> classOf[StringDeserializer].getName,
"group.id" -> group,
"auto.offset.reset" -> "latest",
"serializer.class" -> "kafka.serializer.StringEncoder",
"ssl.truststore.location" -> "client.truststore.jks",
"ssl.keystore.location" -> "client.keystore.jks",
"security.protocol" -> "SSL",
"ssl.truststore.password" -> truststore,
"ssl.keystore.password" -> keystore,
"enable.auto.commit" -> (true: java.lang.Boolean)
)
ssc.sparkContext.setLogLevel("WARN")
val topics = Array(topic)
// 消费kafka数据
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,~~~~
Subscribe[String, String](topics, kafkaParams)
).map(record => record.value())
val counts = stream.flatMap(_.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.print()
ssc.start()
ssc.awaitTermination()
ssc.stop(true, true)
}
}查看作业输出
在“集群详情页”点开“Hadoop Yarn Web UI”,即可打开yarn console:
在yarn console可以查看对应application的日志,用以查看程序的输出,以kafka_wordcount为例,输出在stdout中:
注意事项
如果需要停掉某个作业,可以使用“yarn application -kill applicationId”命令,例如:
yarn application -kill application_1488868742896_0002同时跑多个作业,请注意修改test.conf中的group.id配置