新闻资讯
关注百度智能云最新动态,了解产业智能化最新成果
面向大数据存算分离场景的数据湖加速方案
2022-07-28 10:48:321.大数据方案概览
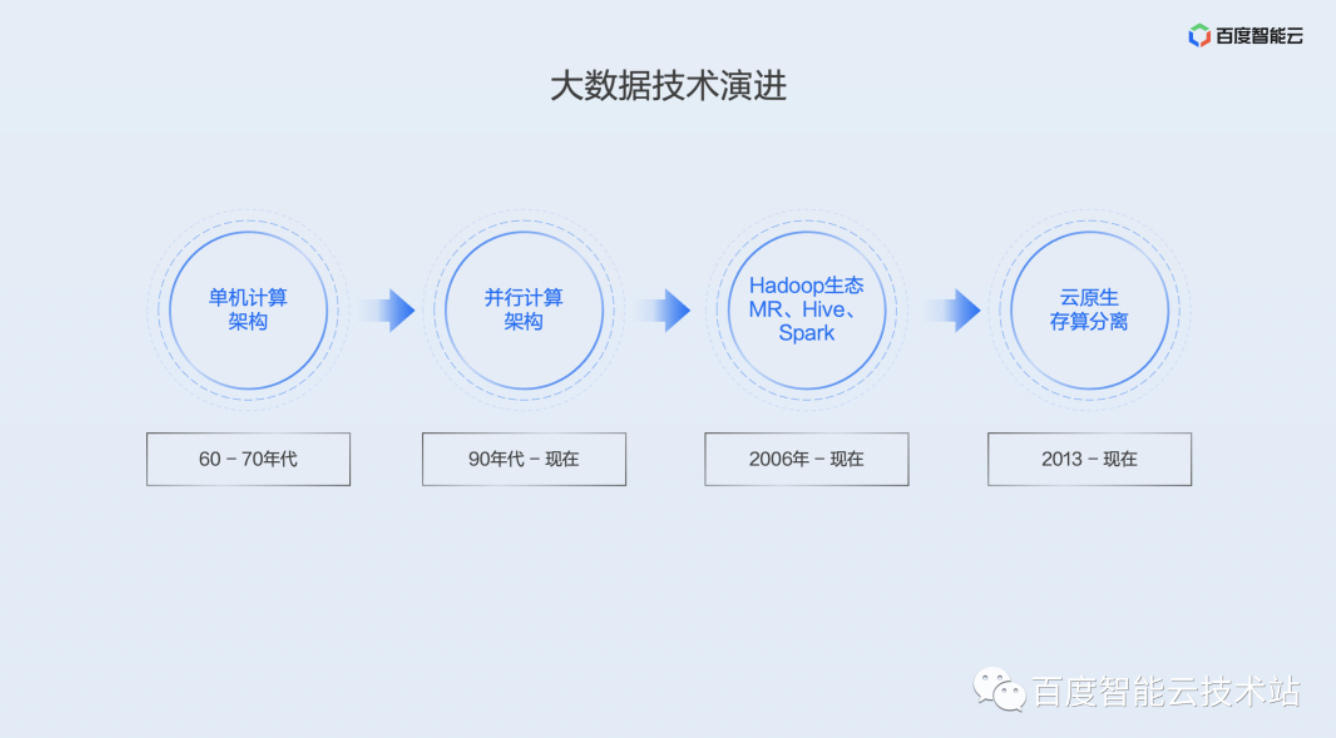
· 大数据技术的演进
在介绍百度智能云的大数据方案之前,先简单回顾一下大数据技术的演进。在上个世纪六七十年代,主要以单机计算架构为主,后面随着数据量增加,出现了并行的 MPP 架构,可以多台机器并行处理,加快计算速度。在 2006 年出现了 Hadoop 之后,大数据技术呈现出一个非常繁荣的发展态势,涌现出来一代又一代非常优秀的计算存储的引擎,像 MapReduce、Hive、Spark、Flink 等等。从 2013 年以后,随着大规模云业务的兴起,大数据技术呈现出新的一些特点,比如云原生、数据湖、存算分离等等。
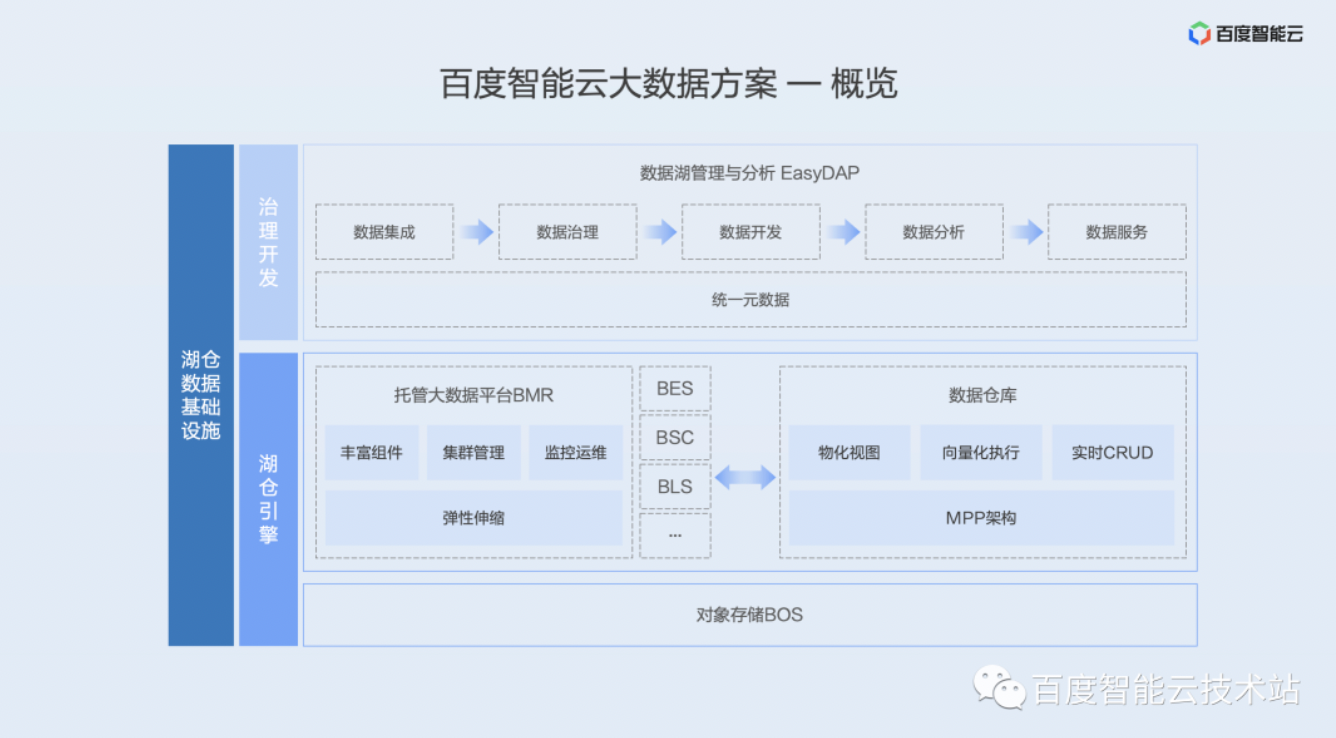
· 百度智能云大数据方案概览
下面这张图展示的是百度智能云大数据的整体的方案,最底层的数据湖存储使用的是对象存储 BOS。对象存储 BOS 支撑网盘近十年的时间,文件数超过万亿,存储规模超过数十个 EB,长期稳定运行。
在数据湖上面的计算引擎有两种:
第一种是托管大数据平台 BMR。BMR 完全兼容社区生态,有着非常丰富的主流的计算存储的组件,集群管理和运维监控也非常的完善,并且支持弹性的扩缩容。
另外一种是企业级的数据仓库 Doris。它通过物化视图向量化的一个执行以及现代化的 MPP 架构,以及极致的列式存储引擎等等,轻松的实现 PB 级数据的高效查询和报表工作。
最上层的平台是数据湖管理分析 EasyDAP 平台。EasyDAP 平台能够轻松的一站式的完成数据集成、数据治理、数据开发、数据分析和数据服务,并且有统一的元数据管理。
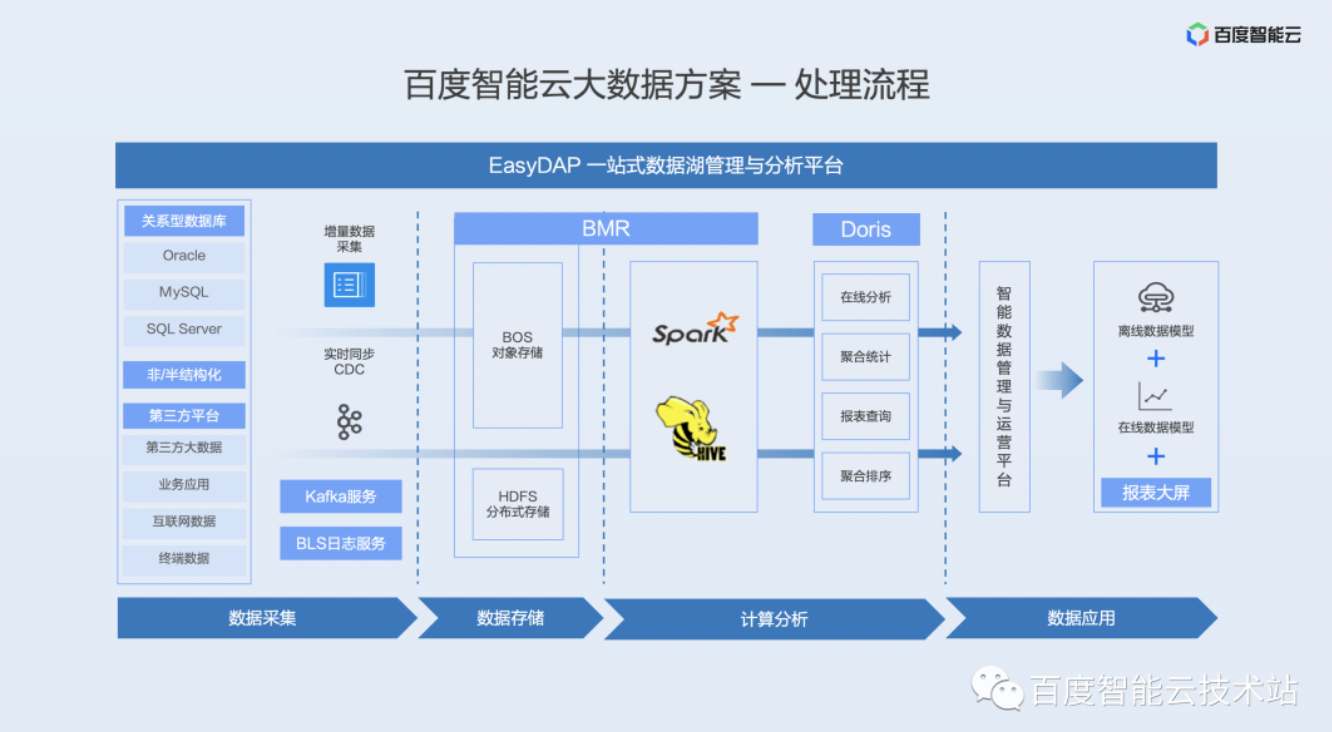
下图是百度智能云大数据的一个处理流程,分为四个部分,数据采集、数据存储、计算分析和数据应用。
在数据采集的这部分,通过 Kafka、日志传输服务、实时同步或者增量同步的方案,把数据从关系型的数据库如 Oracle、MySQL、SQL Server,或者半结构或者非结化的存储平台以及第三方的业务、互联网数据等等,传输到存储系统。
存储系统包括对象存储 BOS 和分布式的存储 HDFS 等,然后再通过 BMR 或者 Doris 的计算和分析,最后提供给数据应用使用。
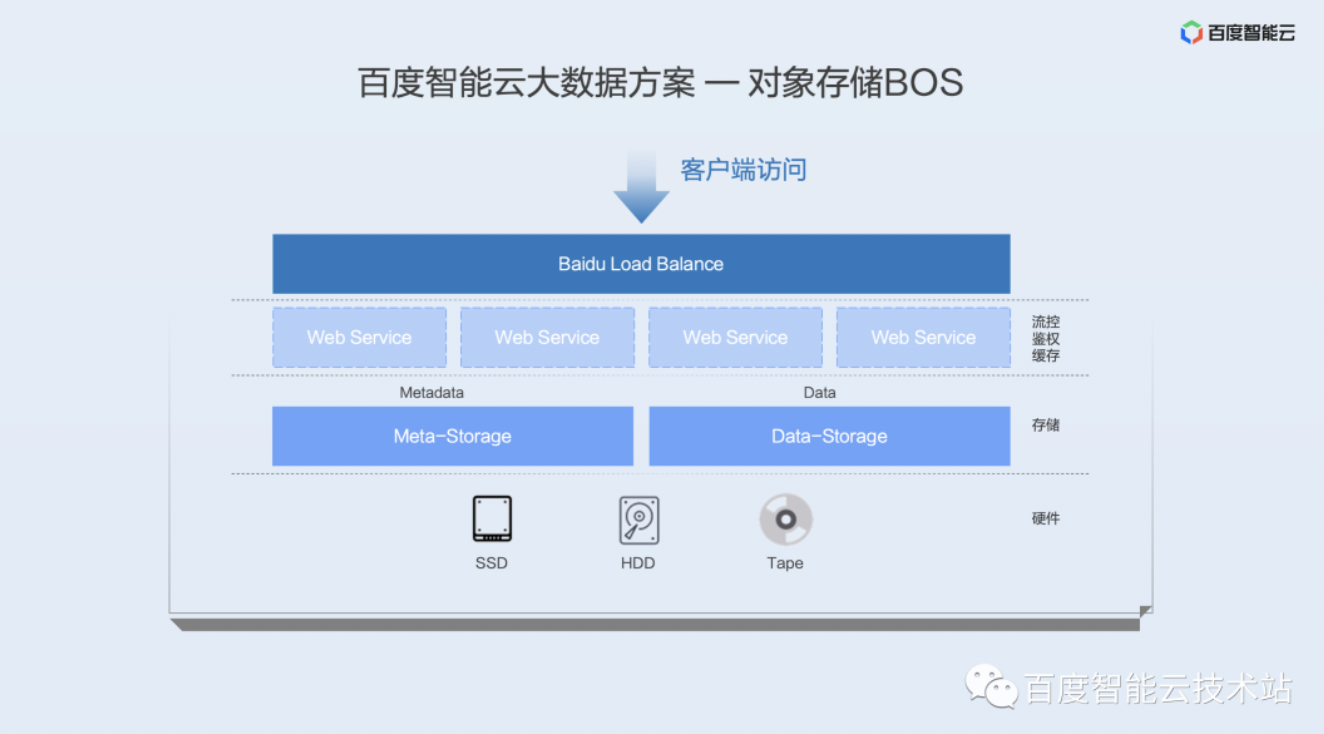
因为后面介绍的数据湖加速方案都是基于对象存储 BOS 做的,所以在这里我简单的介绍一下 BOS 的架构。
百度智能云的对象存储 BOS 对外提供 RESTful 访问的 API,在最外层有一层四层负载均衡设备,四层负载均衡设备的下一层是 Webservice 服务,Webservice 提供标准的 HTTP(S) 访问,有流控、鉴权和切块校验等一些前置功能。
Webservice 下一层有两个分布式的集群,第一个分布式集群是存储 Metadata,就是元数据存储,第二个集群是一个数据存储集群,负责存储真正的数据。元数据存储集群采用 3 副本的全局有序的 Table 系统,数据存储采用的是在线 ErasureCoding 模式的存储系统。Blob Storage 有几种存储模式:第一种方式是多副本,第二种方式是离线 EC,第三种方式是在线 EC。EC 的方式相对于多副本存储方案有明显的一个成本优势。一般 EC 可以做到 1.5 副本、1.3 副本这样,但是如果是多副本的话,那可能最少是要 3 副本。
对象存储 BOS 采用的是在线 EC 的方案,它直接在写入的时候就把原始数据进行切块,计算出校验块,然后分多个 Shard 写入对应的存储位置上。在线 EC 另外一个好处是可以利用多块磁盘 I/O 并行操作,降低读写延迟。相对于异步 EC 模式,在线 EC 也能节省异步 EC 所带来的二次 I/O 消耗。
最底层是存储硬件介质,对象存储 BOS 的 6 级存储等级中,标准存储、多 AZ 标准存储、低频存储,多 AZ 低频存储和冷存储是基于 NVMe SSD 和 Sata HDD 的混合存储介质,归档存储则是基于磁带。
2. 存算分离的优势与挑战
存算分离相对于存算一体有哪些优势呢?
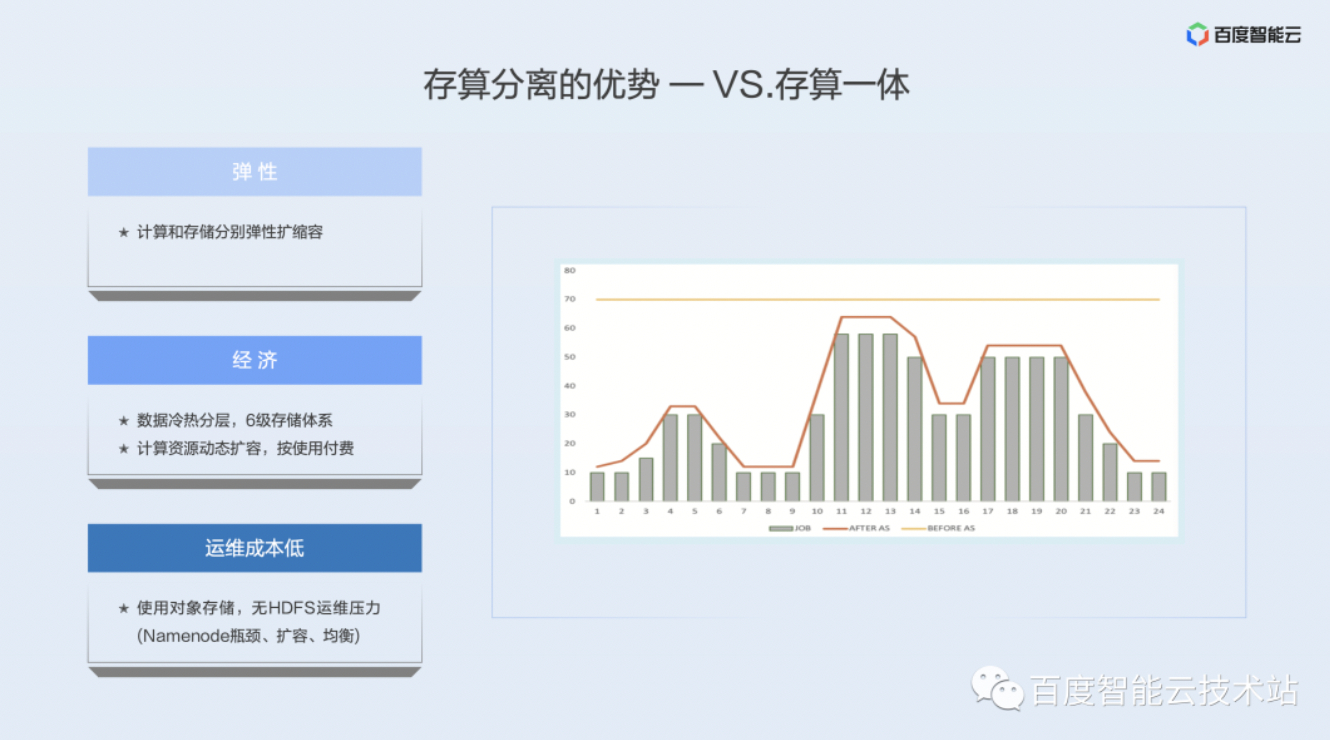
· 第一个优势就是弹性
从字面意思来理解,计算和存储分离开之后,计算资源和存储资源可以分别扩容。在集群最开始规划的时候,可能很容易设计出来一种机型,能够使计算资源和存储资源是匹配的,但是随着业务模式的变化,一定会出现计算资源和存储资源不匹配的情况。如果存算一体的话,扩容一定是计算和存储一起扩容,一定会出现某种资源的浪费。但是存算分离之后,计算资源有缺就扩计算资源,存储资源缺就扩存储资源,可以实现很好的弹性。
· 第二个优势是经济
把数据存到对象存储中可以很容易的实现数据的冷热分层,对象存储 BOS 有 6 级存储体系,最冷的一层归档存储,它的目录价是标准存储的1/8,也就是说长期不使用的数据下沉到最冷的归档存储当中去,这个时候它的成本直接会减少 87.5%,这是一个很大的节省力度。如果是存算一体,那么数据仍然要存储在 3 副本的 HDFS 中。另外一个层面是计算资源可以动态的扩缩容,按使用付费。因为使存算分离之后,数据等有状态的服务都是采用对象存储或者 RDS 等一些有状态的服务存储,这时候的计算资源完全是无状态的,可以有任务的时候把它启动起来,没有任务的时候把计算资源关闭,不需要长期的维持一个常驻的计算集群。如果是存算一体的话,因为有 HDFS 的存在,那必须要维持一个跑 HDFS 存储集群的机器,没有办法实现资源的动态缩容。
· 第三个优势是运维成本低
如果数据是基于对象存储,那么运维压力已经转嫁给了云服务的厂商,云服务厂商自己有专业的运维团队去运维。HDFS 的运维压力在超大数据规模的情况下是非常大的,有一些他难以弥合的一些缺陷,比如说 Namenode 的瓶颈,HDFS Namenode 的架构是基于全内存的,单 Namenode 最大也就是十亿左右的规模,也就是说如果整个的计算规模在百亿甚至千亿的时候,那么就是需要 10 个甚至 100 个以上的 HDFS 集群,这样的集群对于运维压力是非常大的。另外从数据面上看,如果数据达到百 PB 以上,数据的扩容和均衡也是一个非常大的挑战。
既然存算分离有那么多的优势,它相对于存算一体,能在所有维度都比存算一体更好么?也不是。存算分离有它的挑战。
首先就是对象存储的平坦 Namespace 的问题。因为对象存储为了极高的扩展性,要支持万亿的文件数的规模,一般本来说它是一个平坦的 Namenode,就是说一个文件的元信息存储,在有序 table 里面存储了从根目录到最终文件的完整的 key,key 和 key 之间并没有联系,如下图所示,这里边有五个文件,对象存储的元数据存了五条元数据信息,这五条信息之间没有任何关系。这个时候如果要去实现 HDFS 的目录的 rename 接口,比如把 a/b/c rename 成 a/b/c.1,这时候要转换成对象存储的操作是这样的:首先要把 a/b/c 下面的文件都 list 出来,拿到这个列表之后,再去逐条的做 rename,把这些文件一条一条的 mv 到目标文件夹去。
这个时候它的耗时跟原目录下的文件数成正相关的,如果这个单目录有上万的文件,那么耗时就在数分钟以上。这个时候对于大数据任务的耗时是不可接受的。还有另外一个问题,因为有多次的单个文件操作,中间可能会因为网络或者某个存储节点的原因导致一部分文件操作失败。如果中间出现失败,那就会有一部分的文件在原目录,有一部分的文件在目的目录,这时候会导致任务执行失败。

除了元数据的挑战之外,在数据面也有一些挑战。
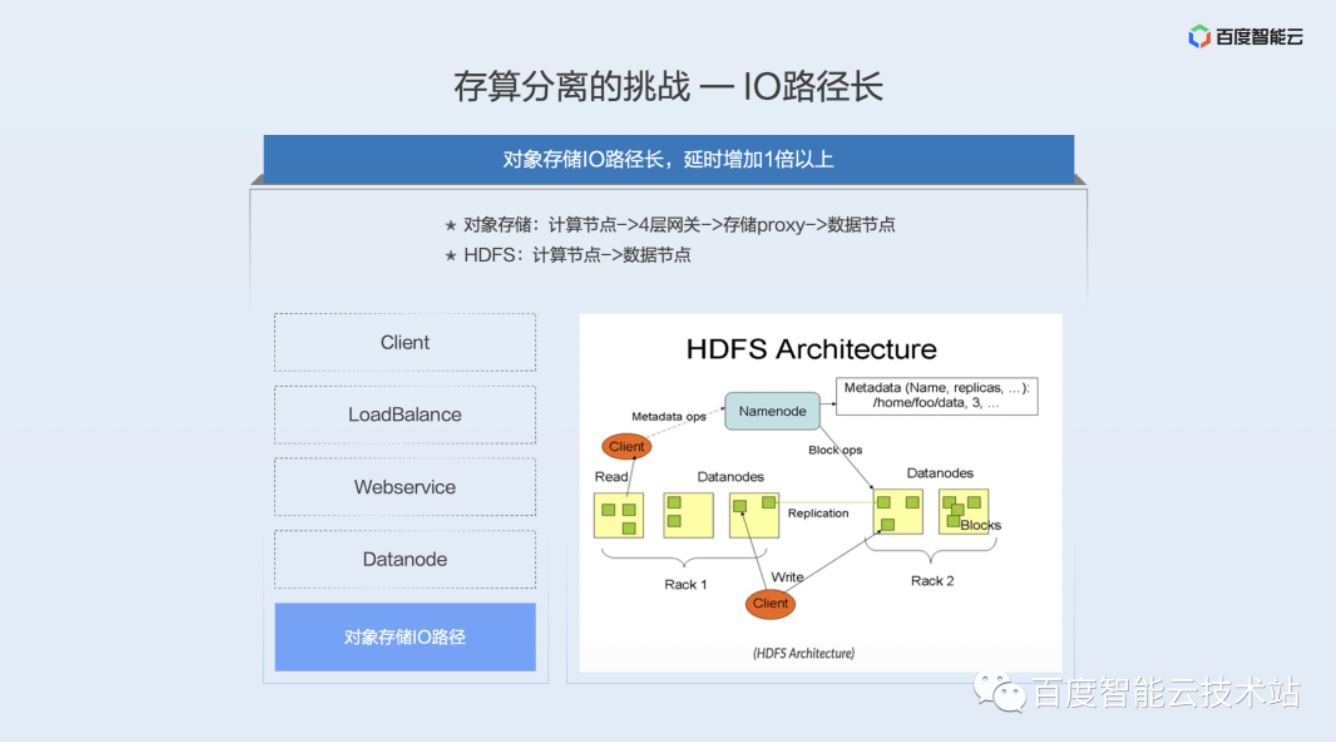
第一个问题是 I/O 路径长。前面提到的对象存储架构,数据流从计算节点访问至少要经过四层的负载均衡设备 Load Balance、Webservice、再去访问元数据,拿到 blob 数据的实际的存储位置,然后再去实际的存储节点拿到数据,至少要经过四个步骤。
而 HDFS 架构如下图所示,Client 直接通过访问 Namenode,知道这些数据在哪些 Datanode 上面去,然后再去访问 Datanode 上面的数据,它其实只有两跳。对象存储要比 HDFS 访问的路径要长一倍。这个注定单流的性能是要比 HDFS 差的。
数据面第二个问题是带宽消耗大。因为计算节点是一个集群,而存储节点是另一个集群,两个集群通过网络设备光纤连接起来。现在一个大的离线作业,都会在 TB 级别的读写,如果有几十个这样的业务,那带宽会到 10TB 以上。这么大的东西向的流量,对中间的网络交换机和光纤都有一个非常大的成本压力,如果出现陡增,对其他业务会产生影响。
还有另外一个问题也不可忽视,就是计算节点无法就近访问数据。因为中间经过了一层 Proxy 的代理,计算节点是没有办法真正地感知到数据分布的。而 HDFS 是可以做到这一点。对象存储无法做到直接感知数据位置,那么它需要无差别的去访问所有数据,这样的特性进一步的增加了 I/O 消耗。

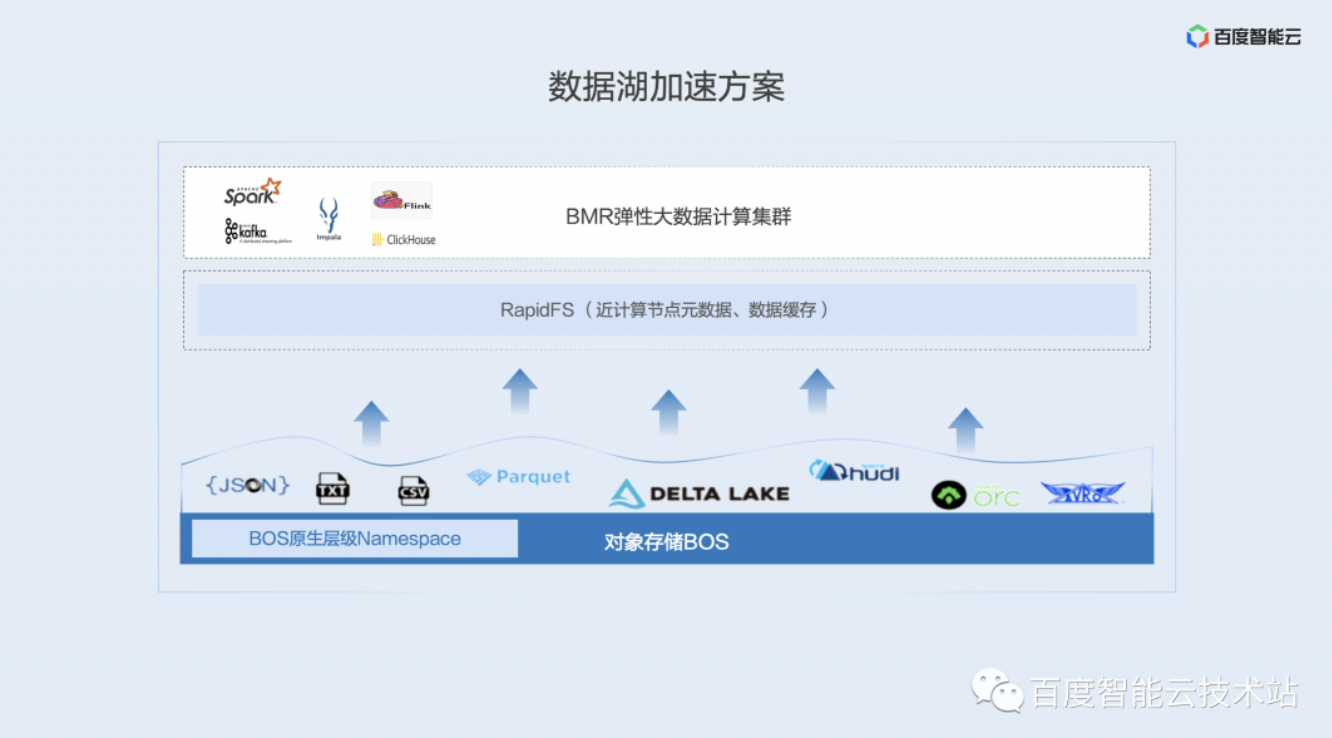
3. 百度智能云的数据湖加速方案
面对前面的这些挑战,百度智能云的数据湖加速方案是如何做的呢?也分为了两个部分:
第一个部分是针对 BOS 平坦 Namespace 带来的性能和原子性问题,BOS 开发了原生的层级 Namespace,也就是把原来平坦的目录数转化成一个层级的目录数,这样就能够以更高效的方式供大数据应用使用。
第二个优化是我们在进计算节点增加了元数据和数据的缓存产品 RapidFS。
下面我就重点介绍这两个数据湖加速方案。
· 原生层级 Namespace
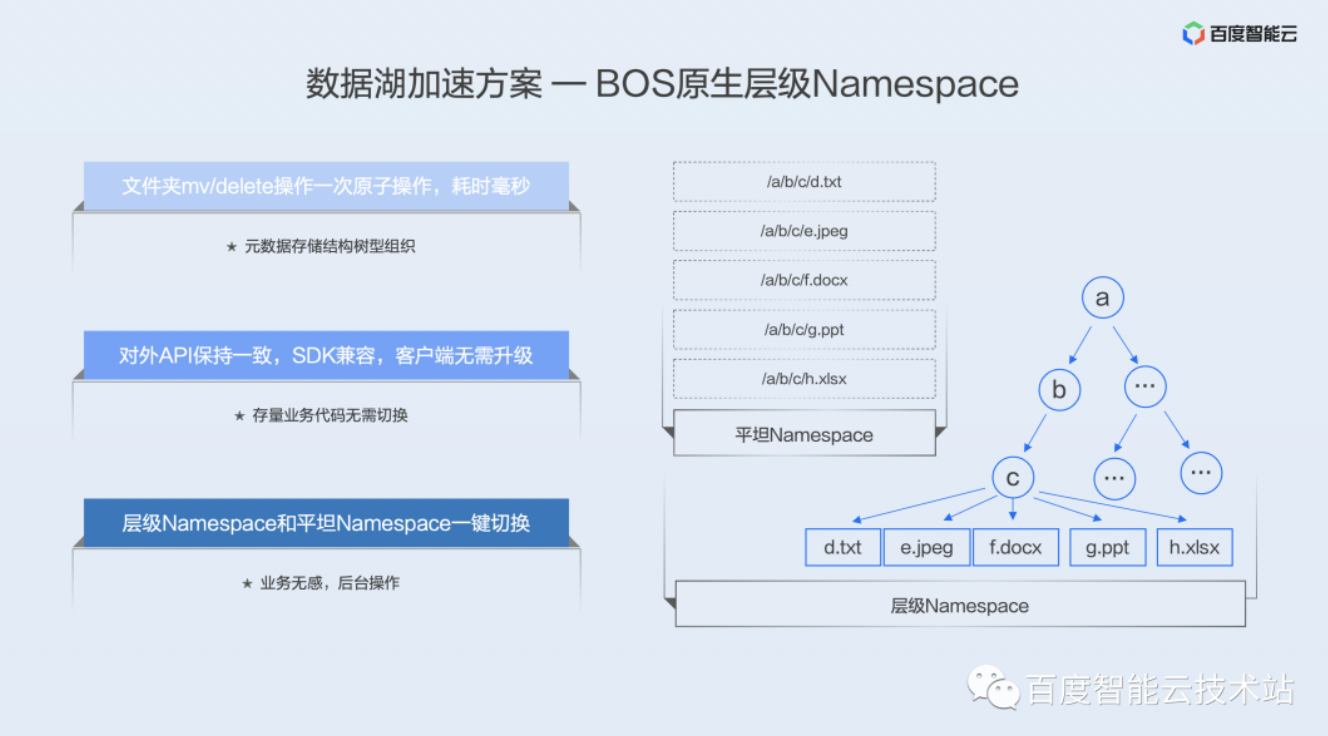
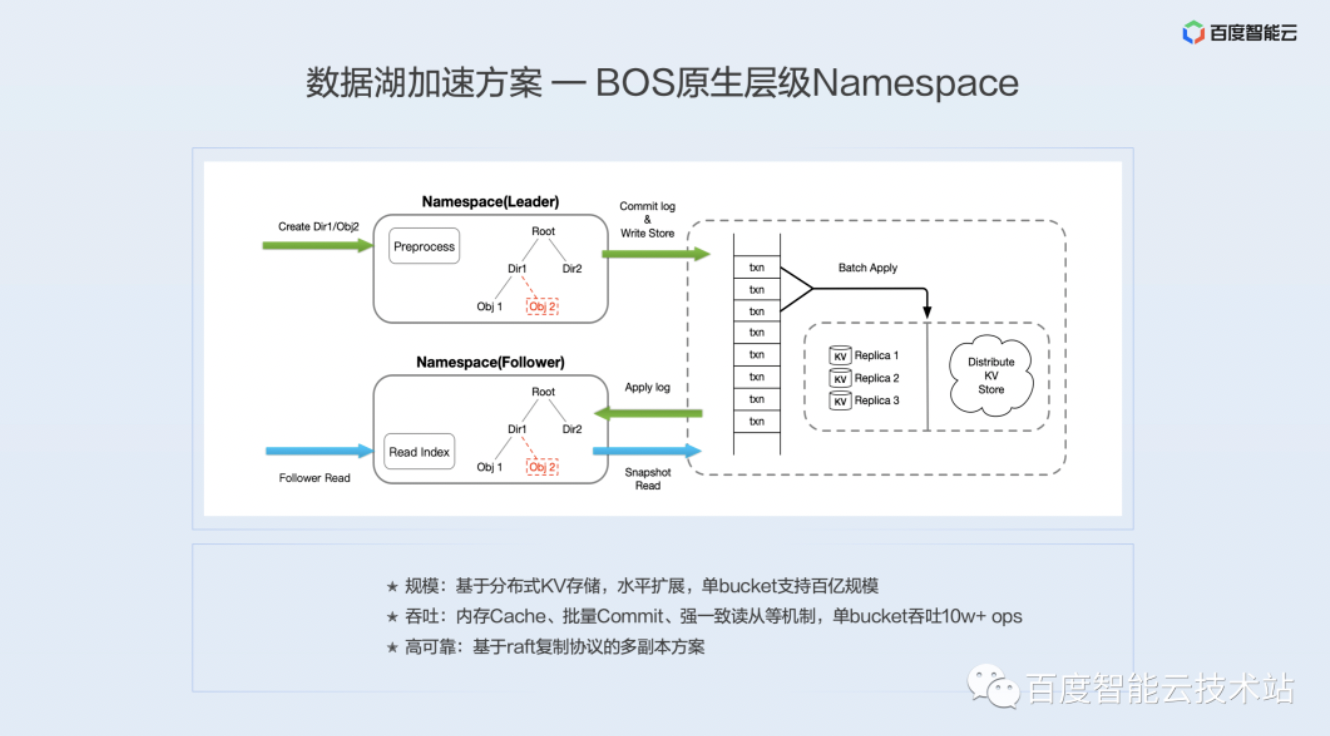
BOS 原生层级 Namespace,就是把之前提到的平坦 Namespace 的一个目录的组织转化成一个树状的结构,如下图所示。
如果这个时候再去做一个目录的 rename 的时候,只需要去把这些所有文件的父目录节点号换一下就可以了,这样一次操作就可以完成,而且耗时是毫秒级的。这个操作跟这个目录下的文件数没有任何关系,是一个常量级的操作,无论是这个文件夹下面有几万、几十万还是几百万的一个文件,mv 文件夹都是一个常量级的毫秒级的操作。
我们对外保持了 API 的一致,SDK 是完全兼容的,同时后台做了大量的兼容性工作,使得现在访问平坦 Namespace 所有的代码能够无缝的去访问层级Namespace,无需去改变业务的代码。
我们也提供了层级 Namespace 和平坦 Namespace 的一键切换。因为现在有很多大数据业务已经是基于平坦 Namespace 去做的,我们后台做了大量的研发工作来支撑可以一键转换成层级 Namespace。这对业务是无感的,只需要前台做一键的操作,后台就可以批量的把平坦 Namespace 做一次转换。
下图是 BOS 层级 Namespace 的架构图,它底层的存储是基于一个分布式的 KV,而不是类似 HDFS Namenode 使用内存。
关于 BOS 层级 Namespace 和分布式 KV 这两个话题,我们将在数据湖系列中做更详细的介绍。
因为底层基于一个分布式的 KV 存储,它可以做到水平的扩展,单 bucket 可以支持到百亿的规模,而不是像 HDFS 是十亿级别的一个规模。
我们也通过各种各样的优化手段,比如读写路径锁、内存 Cache、批量 Commit 机制、强一致性读从等手段来提升吞吐,单 bucket 吞吐在优化完之后可以到 10w+/s 以上。这套系统使用基于 raft 复制协议多副本的方案,实现高可靠。
整体上来看,BOS 原生的层级 Namespace 这套架构是要比 HDFS 的 Namenode 架构是更加优秀的。
· 缓存加速 RapidFS
下面介绍另外一个加速组件 RapidFS。
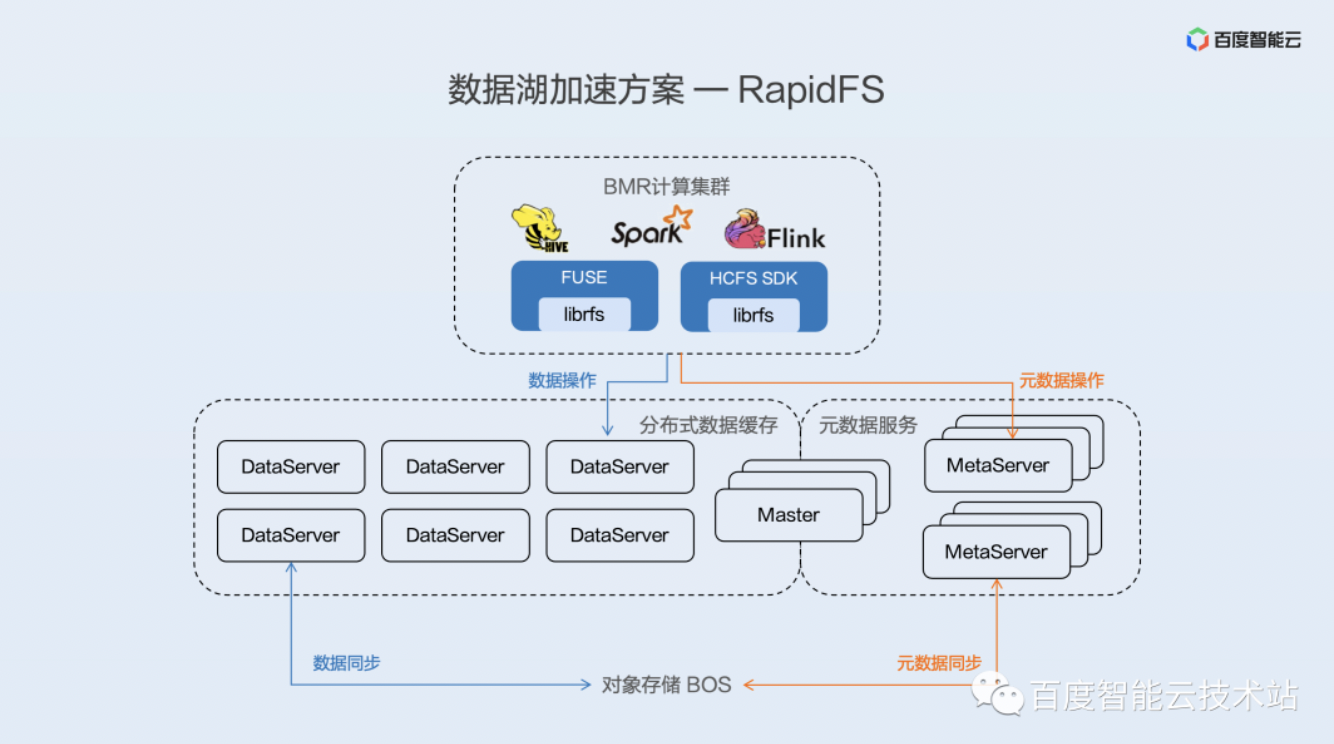
RapidFS 实现两种功能,第一种功能是元数据加速,第二种功能是数据面的缓存。
在元数据加速这块有两种模式,第一种模式是 Cache 模式,第二种模式是 Block 模式。所谓的 Cache 模式,是指 RapidFS 的元数据跟 BOS 的元数据是一一对应的关系,RapidFS 只是提供 Cache 加速。第二种 Block 模式,则是 RapidFS 的 Metadata 做了持久化的存储,这个存储在 RapidFS 里面只有一份,而对象存储里边的元数据已经变成了无意义的一个字符串,它需要通过 RapidFS 的元数据去访问BOS,这时候 BOS 的存储只作为一个 RapidFS 的数据存储部分。这个时候,它的元数据访问性能是最优的,因为 RapidFS 的元数据不需要再跟对象存储产生任何的关系,它就是在本地的一个 VPC 内的一个存储服务。
数据面的缓存则是利用计算节点空闲的内存、磁盘资源,把这个热数据都缓存起来,加速业务的访问。我们做了一个智能识别存储文件类型的这样的模式,可以动态智能的去识别大数据常用的存储文件类型,然后预拉取这些文件中访问非常频繁的索引部分的数据段,把它预先的拿到这个分布式缓存当中来,能够极大的提高业务的访问的性能。
RapidFS 的架构如下图所示,RapidFS 提供两种访问接口给计算集群。第一种是通过文件 FUSE 挂载的方式。第二种是实现了 Java SDK 方式,它的数据操作首先会去操作 RapidFS 的 DataServer,然后 DataServer 通过 write through 的方式同对象存储去做数据同步。同样的元数据操作也先去操作 RapidFS 的元数据服务,然后 RapidFS MetaServer 同对象存储的 Meta 去做同步。
为了更加清楚明晰的对比几种服务的性能,我们分别做了两种测试:
第一种是 BOS 平坦 Namespace 和 BOS 层级 Namespace 的一个对比。
第二种是 RapidFS 和直接访问 BOS 的一个对比。
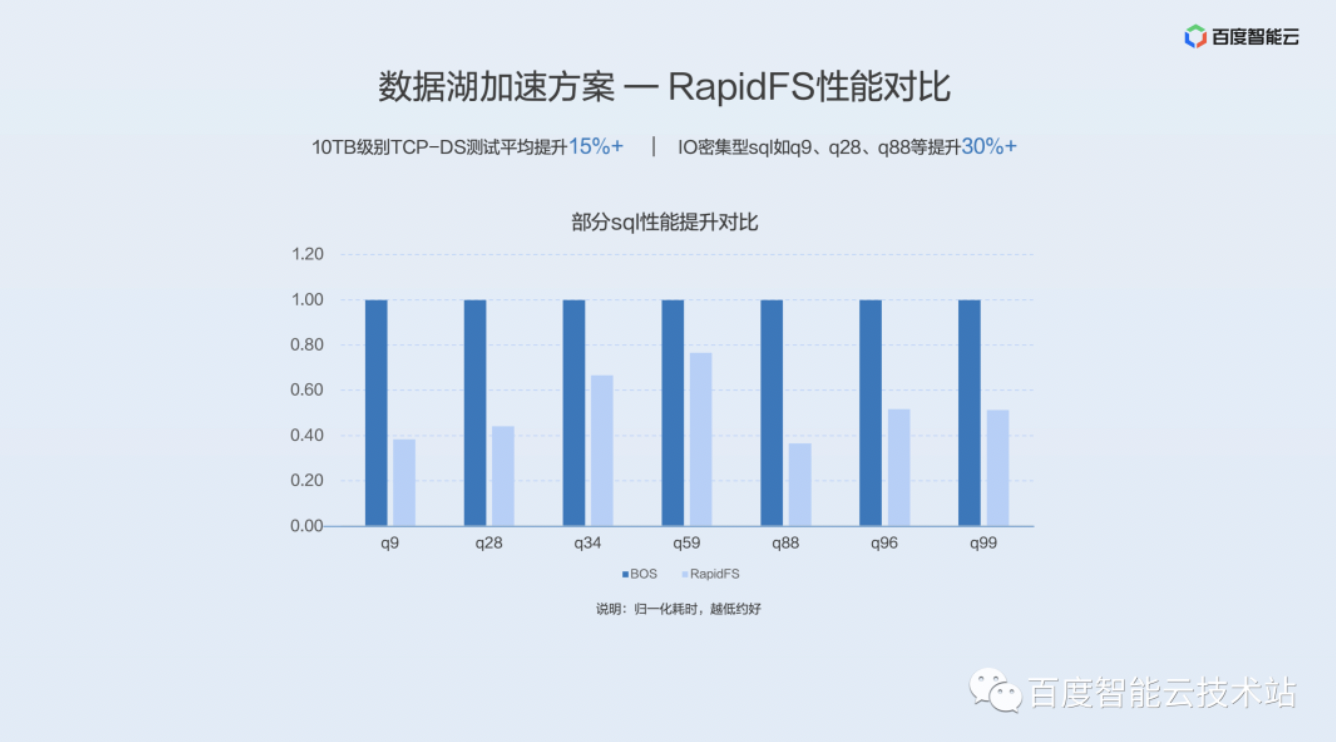
我们做的是 10TB 级别的 TCP-DS 的 SQL,分别做了 SparkSQL 和 Hive 的 Tez 引擎下面的测试,这些测试平均下来都有 10% 左右的提升,元数据访问密集型的,如 q5、q45、q62 等有一个接近 40% 以上的提升。
另外一组是 RapidFS 和没有 RapidFS 直接访问 BOS 的一个对比,这个测试条件跟上面是一样的。我们测试得到的结论是有 RapidFS 的平均性能要提升 15% 以上,I/O 密集型的 SQL,比如 q9、q28、q88 等等有 30% 以上的提升。
图中数据是做了规一化划处理的耗时的耗时对比,越低表示这个性能会越好。
4. 最佳实践
现在有 BOS 的平坦 Namespace、层级 Namespace,还有 RapidFS的 Cache 模式、Block 模式,那么这几种使用模式怎么用才是最佳的呢?下面提供几种推荐的使用模式。
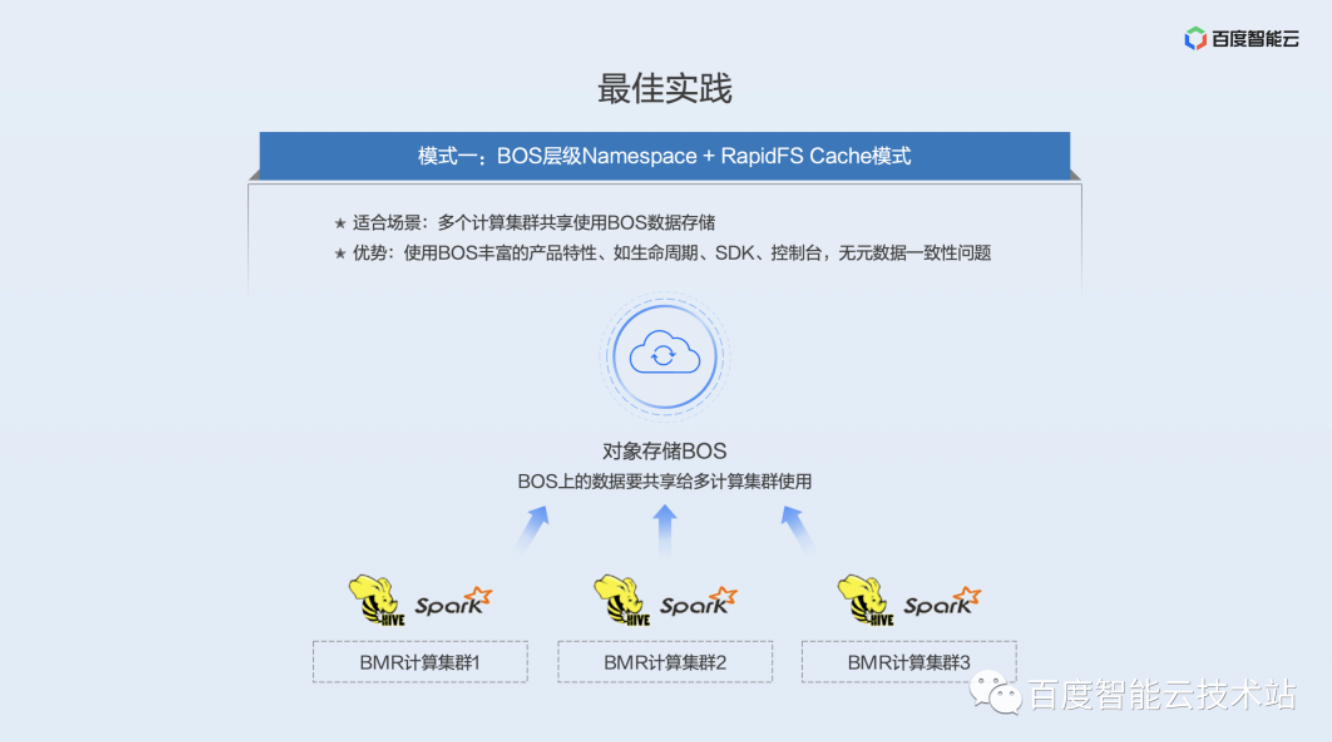
第一种模式是 BOS 的层级 Namespace 加 RapidFS 的 Cache 模式。
这种模式适合有多个计算集群访问同一组 BOS 数据。这种访问模式下,如果用 RapidFS Block 模式,会有一致性更新的问题,并且没有办法去做共享访问,所以要用 RapidFS Cache 模式。而 BOS 的层级 Namespace 能够轻松地利用上 BOS 提供的丰富的产品特性,如生命周期、SDK、控制台等。
第二种访问模式是 BOS 的平坦 Namespace 加 RapidFS 的 Block 模式。
这种模式适合于几个计算集群和对象存储 bucket 里的数据是一对一的关系,也就是 BOS 的数据单独提供给一个 BMR 集群,这个 BMR 集群也只访问 BOS 数据。这个时候的 RapidFS 的 Block 模式是最优的,因为这个时候的元数据访问是不需要跟对象存储后端的元数据做任何交互,只需要 VPC 内访问。这时候元数据面的操作也没有一致性问题,可以做到元数据访问最优。
一般来讲,VPC 内的元数据的访问是在 300-400 微秒之间,如果需要到对象存储后端,有一些协议的消耗延迟的增加,以及鉴权等,需要 1-2 毫秒,这时候 RapidFS Block 模式是最适合的。

第三种模式是 BOS 的平坦 Namespace 和 RapidFS Cache 模式。
这种模式就是在当前的存量业务上增加了一层 Cache,所有的业务代码不需要任何改动。对现有的业务无法迁移或者迁移成本很高的场景想要去做加速,这样的场景就适合 BOS 平坦 Namespace 加 RapidFS 的 Cache 模式。
