新闻资讯
关注百度智能云最新动态,了解产业智能化最新成果
端到端问答新突破:百度提出RocketQA,登顶MSMARCO榜首!
2020-10-21 17:19:37开放域问答(Open-domain QA)一直是自然语言处理领域的重要研究课题。百度从面向端到端问答的检索模型出发,提出了RocketQA训练方法,大幅提升了对偶式检索模型的效果,为实现端到端问答迈出了重要的一步。RocketQA已逐步应用在百度搜索、广告等核心业务中,并将在更多场景中发挥作用。
近日,百度提出了面向端到端问答的检索模型训练方法RocketQA,该方法针对模型训练中存在的问题,通过跨批次负采样(cross-batch negatives)、去噪的强负例采样(denoised hard negative sampling)与数据增强(data augmentation)等技术,大幅提升了对偶式检索模型的效果。RocketQA不仅在多个问答相关数据集中取得了SOTA,同时也刷新了微软MSMARCO数据集段落排序任务的榜单,超越谷歌、微软、Facebook、阿里、美团、卡内基梅隆大学、清华大学、滑铁卢大学等企业和高校位居第一,为实现“端到端问答”迈出了重要的一步。
论文名称:RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering
论文地址:https://arxiv.org/abs/2010.08191
一、开放域问答系统
开放域问答(Open-domain QA)是自然语言处理领域的重要研究课题。它的任务是,基于用户用自然语言提出的问题,从海量候选文本中快速、精准地找出答案。开放领域问答在智能搜索、智能助手、智能客服等多个场景下,都发挥着重要作用。特别是近些年,随着各种智能手机、智能音箱的普及,智能搜索快速进化,通过开放域问答系统直接给出唯一的精准答案(如图 1 所示),可以帮助用户在这些小屏和无屏设备上更快速、准确地获取有用信息。
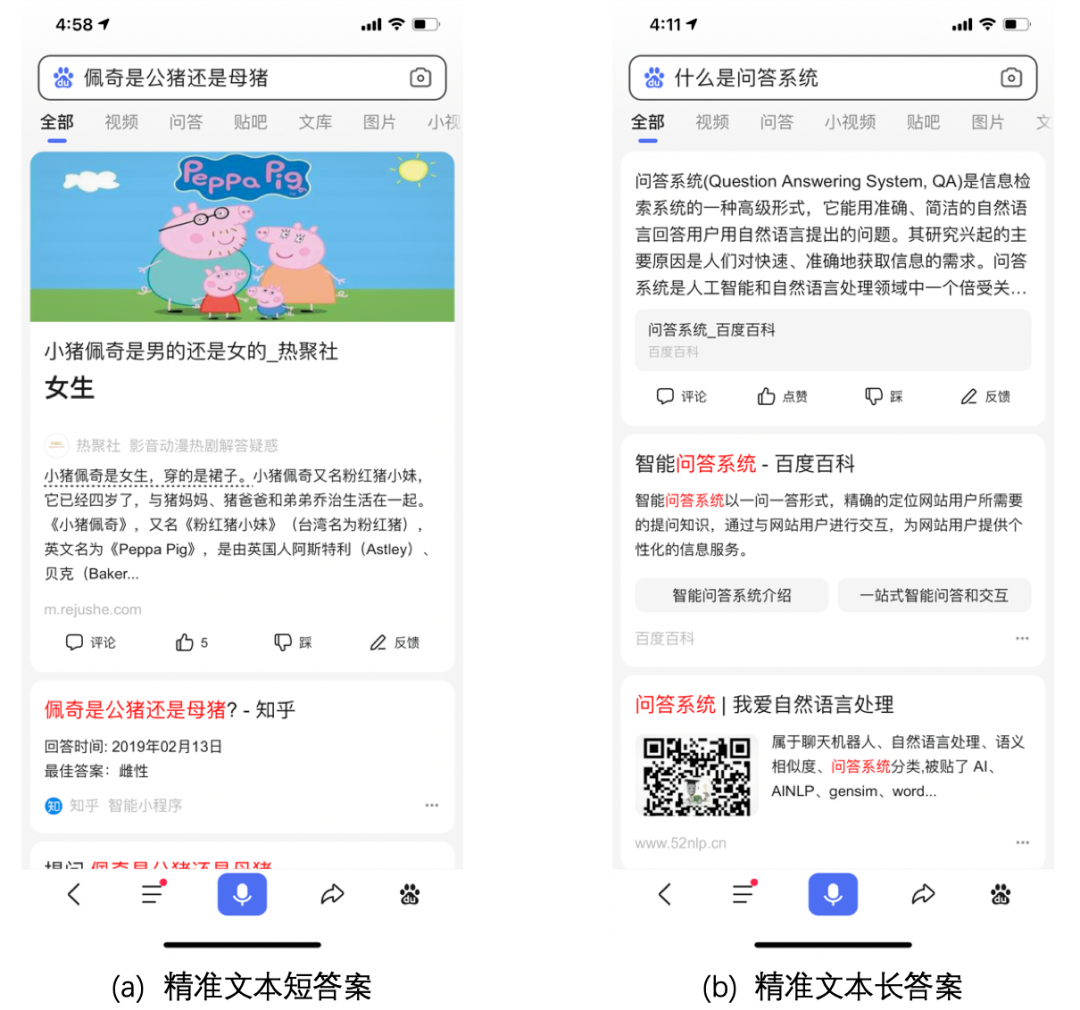
图1:百度搜索的TOP1结果:将问题的答案展现在搜索结果的首位,提升用户体验
不同于传统的级联式问答系统,“端到端问答”摒弃了传统系统中繁杂的构件,系统复杂性大大降低,并且其中每个模块(段落检索和答案定位)都是可学习的,这样的设计能够让整个系统实现端到端训练。这意味着问答系统可以基于用户实时的反馈实现在线训练,而不是只在封闭的数据集上闭门造车。这是智能问答技术的发展趋势,可能会引发问答系统的新一代技术变革。
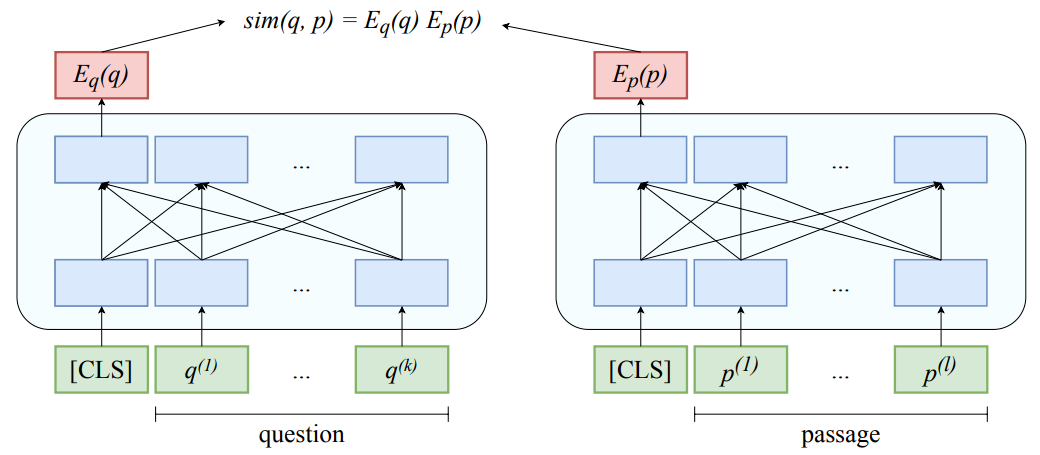
图2:基于稠密向量表示的对偶模型
不同于传统的检索模型使用基于关键词的稀疏表示对问题和候选段落进行建模,基于深度语义表示的对偶式检索模型(如图 2 所示)通过两个对称的网络分别对问题和候选段落进行编码并计算语义相似度。这样能够利用强大的网络结构进行更深层次的学习,同时基于预训练语言模型,使语义理解更加丰富。在过去的工作中,对偶模型大多采用批次内负采样 (in-batch negatives) 的方式进行训练,将批次内其他问题的正确答案作为当前问题的错误答案(负例),从而减少重复计算和提高训练效率。然而,由于检索场景不同于常见的分类问题,对偶式检索模型的训练仍然存在如下的挑战:
训练场景和预测场景中样本数量存在较大差异
开放域问答场景下候选段落的数量往往非常大,标注出问题的全部正确答案几乎是不可能的。在MSMARCO数据集中,候选段落的总数为880万,但每个问题平均只标注了1.1个正确答案。研究人员发现,在使用对偶模型检索出的首条结果中,70% 的错误结果其实是漏标的正确答案。这种情况下,构造训练数据中的强负例时很容易引入假负例(false negative),给模型训练带来负面影响。
尽管目前已有较多大规模的问答数据集,但是相较于开放域的用户问题来说,仍然是冰山一角。有限的标注数据集无法覆盖到全面的领域和类型,导致模型泛化性差。想要增大标注数据的规模和质量,需要很高的人工成本。
因此百度提出了一种对偶式检索模型的增强训练方法RocketQA,通过跨批次负采样、去噪的强负例采样与数据增强三项技术,解决上述挑战。接下来将对这三个技术进行详细的介绍。
采用传统的批次内负采样方法训练时,每个问题的候选段落个数与批次大小相同。为了进一步增加训练过程中候选段落的数量,百度提出了跨批次负采样方法(如图 3 所示)。该方法能够在使用多GPU并行训练时,将其它GPU批次内的全部段落作为当前问题的负样本。这样可以直接复用各个GPU上已经计算好的段落表示,不额外增加计算量;同时基于飞桨分布式训练扩展工具包FleetX的all-gather算子实现,只需要使用很少的通信量和内存开销,就达到了增加每个问题候选段落的目的。随着GPU个数的增加,每个问题的候选段落个数线性增加,训练场景中的任务难度也更加接近真实场景。百度在MSMARCO数据集上进行了实验,在使用跨批次负采样后,随着训练时候选段落数量增加,模型的效果稳步提升(如图 4 所示)。
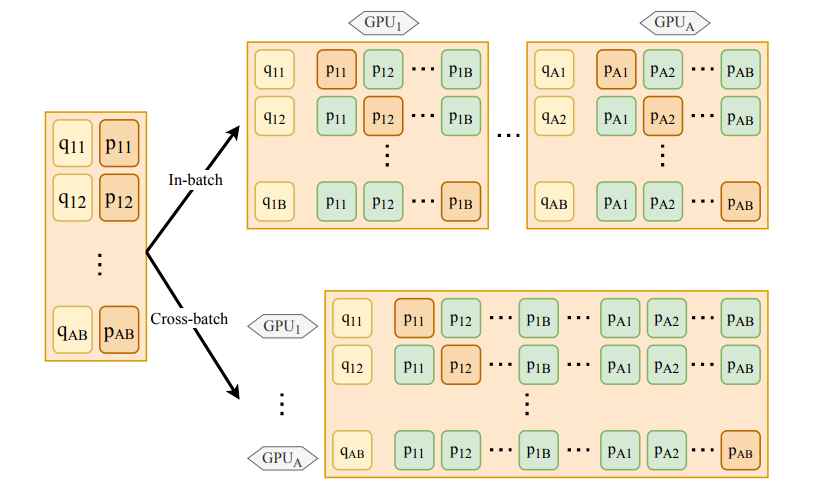
图3:批次内负采样(上)和跨批次负采样(下)的对比
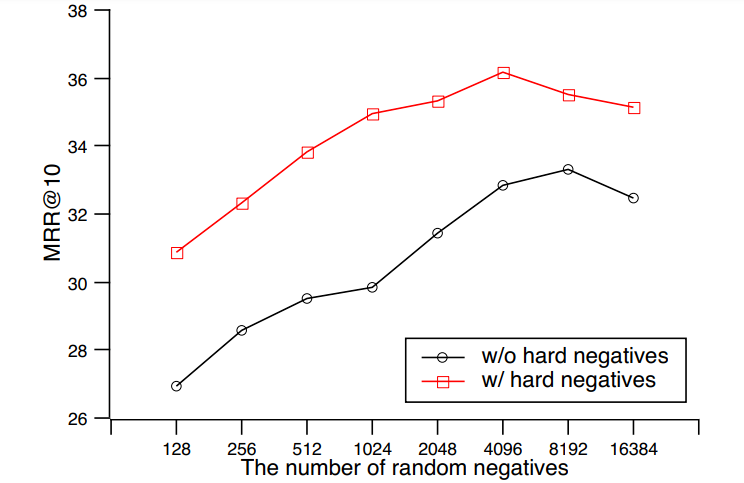
图4:MSMARCO数据集中,训练阶段候选段落的个数对模型效果的影响
在对偶模型的训练中,适当增加训练数据中的强负例的难度,有助于提升模型效果。一般的做法是,从一个排序的候选段落中进行采样,越靠前的负例对模型来说难度越大。但是由于难以避免的漏标注情况,直接采样很大概率会引入假负例。为了解决这一问题,百度使用交互模型(cross-encoder)的打分作为监督信息进行去噪。在选择强负例时,避开交互模型给出高置信度的样例。相较于对偶模型,交互模型具有结构上的优势,能够编码更多的交互信息,从而给出可靠的监督信号,帮助对偶模型选取更可靠的强负例。如表1的第三行和第四行所示,去噪的强负例采样可以显著提升模型效果。
2.3 数据增强(data augmentation)
交互模型可以过滤强负例中的噪声,也可以用来选取未标注的正确答案。因此,当引入大量无标注的问题时,便可以利用交互模型以极低的成本得到大量弱监督数据,进一步增强对偶模型的能力。在MSMARCO数据集的实验中,百度引入了Yahoo!Answers和ORCAS数据集中的150万未标注问题,用交互模型在对偶模型检索出的候选段落上进行打分,并根据置信度选取正负样本。如表1第四行和第五行所示,通过这种方式,对偶模型的效果得到进一步提升。

表1:MSMARCO数据集中,去噪的强负例采样与数据增强策略对模型效果的影响
上述三项技术是层层递进的关系,将它们整合成一套完整的训练方法,类比多级火箭,称之为RocketQA,其完整实现流程如图5所示。在实现中,使用了百度研发并开源的大规模英文预训练模型ERNIE初始化模型参数,然后使用标注数据进行微调。
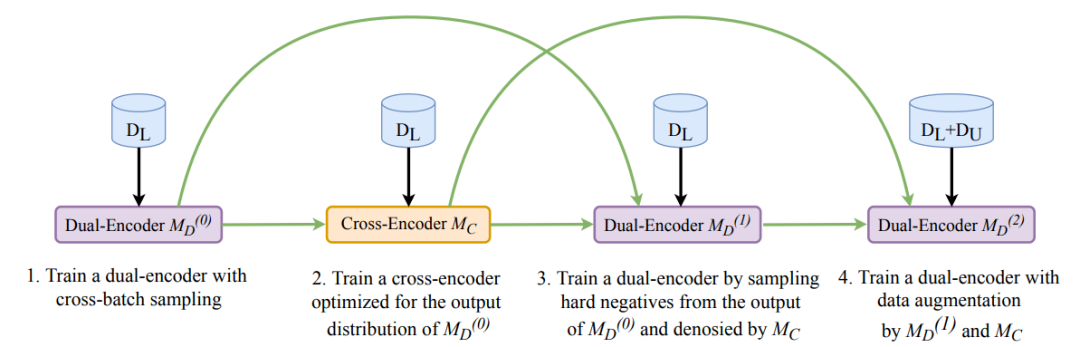
如表2所示,最终的实验结果表明,RocketQA在微软MSMARCO和谷歌Natural Question数据集的效果均大幅超过了已经发表的最好的检索模型。同时,百度也在答案抽取任务上验证了RocketQA检索结果的有效性。如表3所示,在RocketQA做检索的基础上,使用训练好的阅读理解模型,百度在Natural Questions的答案抽取任务上取得了42.0的EM值,超过了已有的相关工作,而这其中的增益来自检索效果的提升。
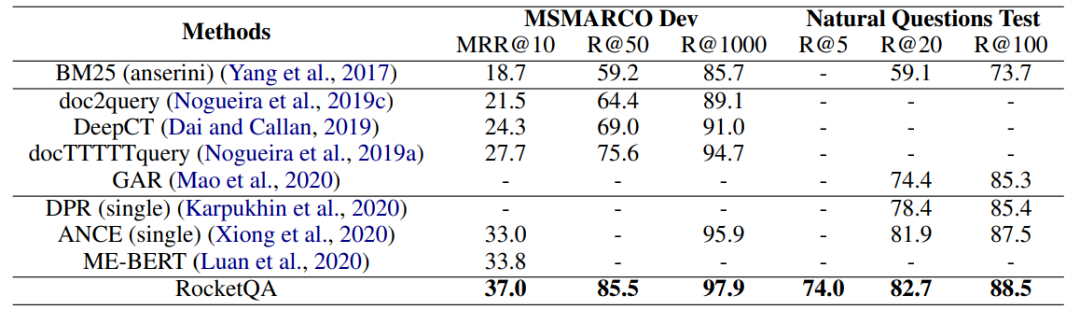
表2:RocketQA在微软MSMARCO和谷歌Natural Questions数据集上段落检索的效果
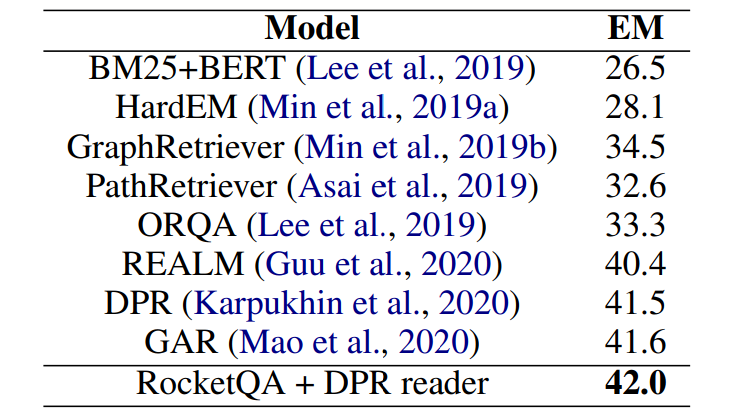
表3:RocketQA在Natural Questions数据集上做阅读理解任务的效果
MSMARCO(Microsoft Machine Reading Comprehension)是微软提出的大规模阅读理解数据集,包含约100万问题、880万相关段落以及人工标注的问题答案。数据集的问题来自Bing搜索引擎的日志, 是真实搜索场景中用户提出的问题,段落来自Bing的搜索结果。基于MSMARCO数据集,微软举办了包括阅读理解、段落排序在内的多个问答相关任务的评测任务。由于数据集规模大、贴近真实场景,MSMARCO的各项任务已经吸引了包括Google、微软、Facebook、阿里巴巴等知名企业,以及清华、CMU等国内外著名高校的参与。如图6所示,百度基于 RocketQA检索模型的结果进一步训练了段落重排序模型,在MSMARCO的段落排序(Passage Ranking)任务中排名第一,超越了谷歌、微软、Facebook、阿里、美团、卡内基梅隆大学、清华大学、滑铁卢大学等企业和高校。
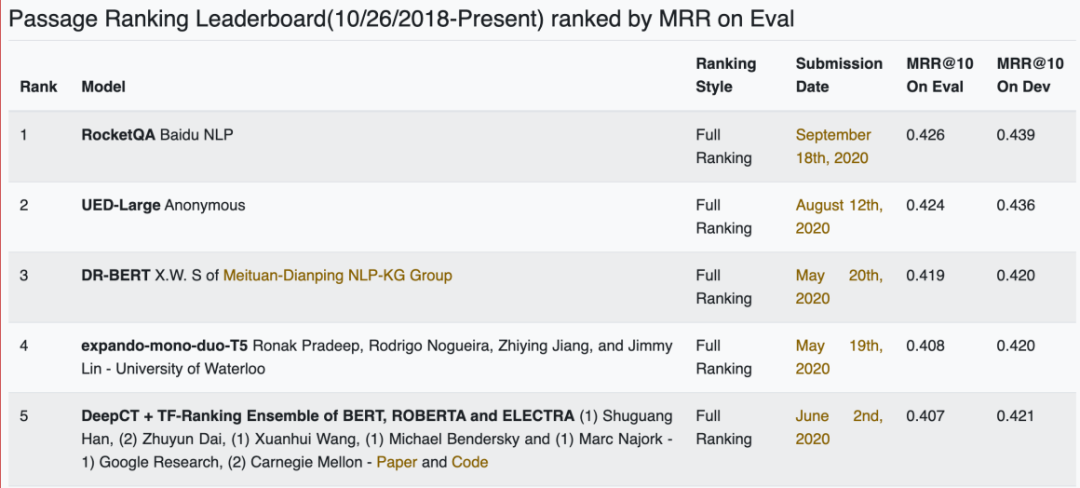
图6:微软MSMARCO Passage Ranking数据集leaderboard截图
飞桨框架通过持续迭代升级,在分布式训练方面真正做到了从产业实践中来,回到开源社区和产业实践中去。在飞桨框架最新版本中,分布式训练继承了之前版本高性能、高扩展的能力,在易用性方面进行了精心的优化。
paddle.distributed.fleet是飞桨框架2.0新API体系下通用分布式训练API,千亿规模稀疏参数服务器和大规模GPU多机多卡训练都可以通过几行代码轻松配置完成。DistributedStrategy作为用户配置并行策略的统一入口,支持大规模异步训练、自动混合精度、深度梯度压缩、重计算、梯度累计、计算算子自动融合、通信梯度智能融合以及自动并行等功能,极大的满足了研究人员日常训练的加速需求。飞桨框架的最新版本同时也开放了能够面向高级编程用户的分布式底层通信接口paddle.distrbuted,使用户能够自主构建诸如自动并行、模型并行等高级并行训练功能。目前,飞桨大规模分布式训练已经在百度日常业务中进行过深入锤炼,并每天都在根据业务的痛点进行改进和优化。
为了实现RocketQA的跨批次负采样,对单卡能够见到的负样本规模有较大的需求,研究人员使用了飞桨paddle.distributed提供的底层集合通信操作all-gather算子,将数据并行训练中各块卡的隐层向量进行汇总,扩大单卡可以见到的负例数量达到GPU卡数倍;为了进一步增加每块卡可以见到的全局负例样本,研究人员还使用了重计算(recompute)策略,该策略以20%左右的计算开销将整个模型的训练使用的显存占用从O(N)降低到O(LogN),在该模型中使用Recompute使训练数据批次大小提升5倍以上,对训练计算图的改写结果如图7所示。这样,跨批次负采样方法与传统的纯数据并行方法相比,实现了负例数量5xGPU卡数的倍数增长,从而加快了收敛速度和收敛效果。
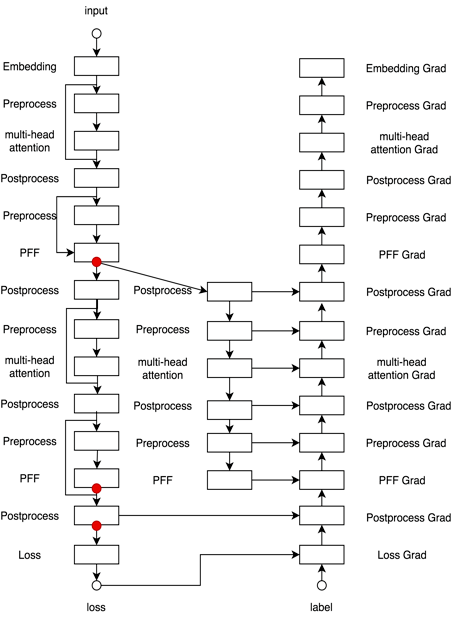
图7:Multi-Head Self Attention利用重计算后的计算图
百度提出的RocketQA训练方法,通过对经典对偶模型进行优化训练,显著提升了模型的检索能力,为实现端到端问答迈出了重要一步。目前,RocketQA已逐步应用在百度搜索、广告等核心业务中,并将在更多场景中发挥作用。