
实时语音翻译
更新时间:2025-08-14
接口描述
实时语音翻译api采用websocket协议的连接方式,能够将音频流实时识别为文字,支持智能断句,实时输出带有标点的语音识别结果和翻译结果,支持45个语种的识别和相互翻译。
接口限制
- 目前支持45个语言的互译,见语言列表
-
音频参数要求:目前只支持pcm格式的原始音频数据
- 采样率:8kHz、16kHz、44.1kHz
- 位深:16bits
- 单声道
- 小端序
接入方式
- 接口协议:
WebSocket - 请求URL:
wss://aip.baidubce.com/ws/realtime_speech_trans
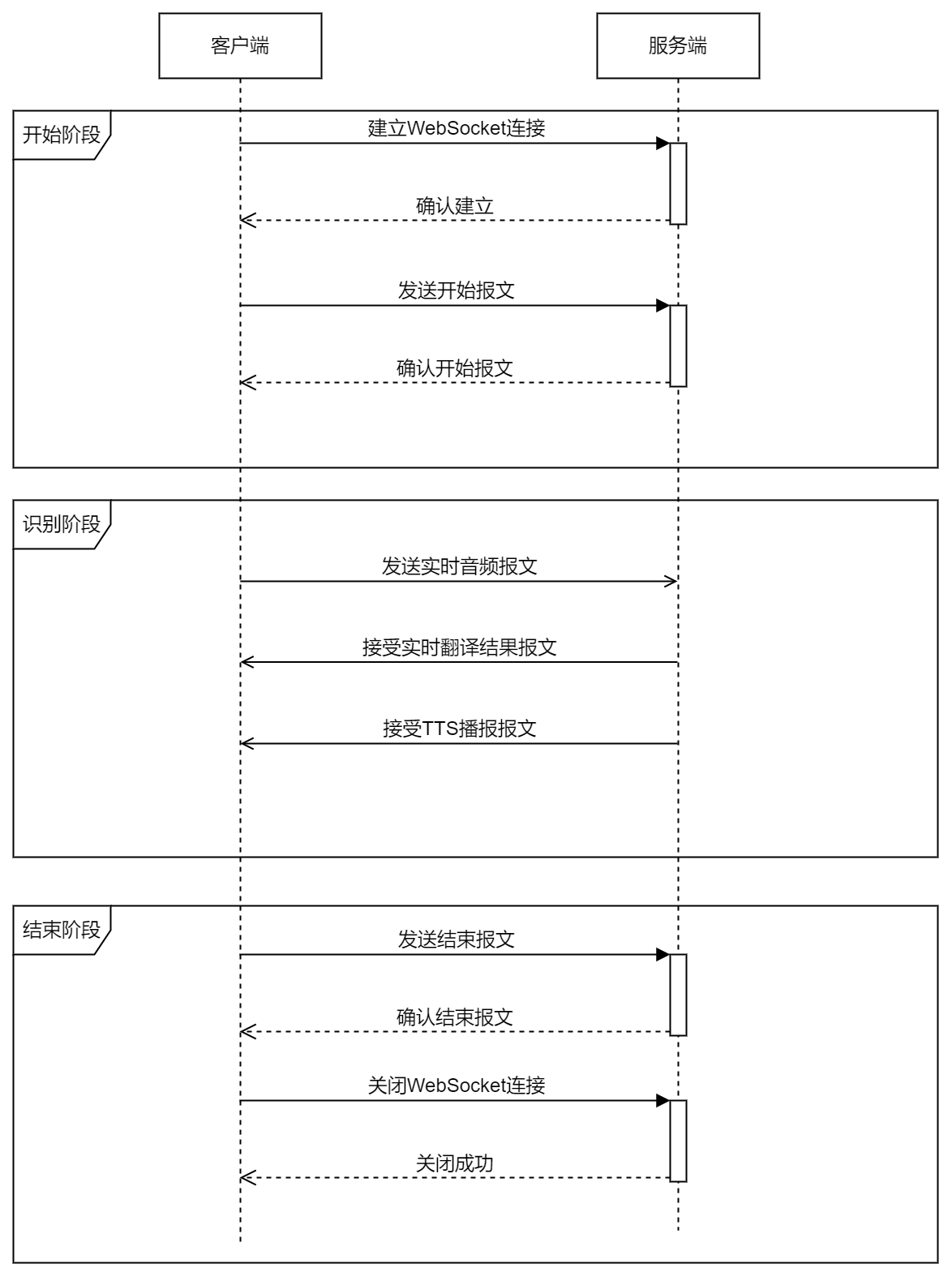
主要流程
实时语音翻译API基于WebSocket协议进行全双工的流式消息发送和接受。实现逻辑如下:
- 建立WebSocket连接,并发送开始报文
- 发送实时音频流报文
- 接收实时翻译结果报文、TTS播报报文
- 发送结束报文并关闭WebSocket连接
报文格式
| 方向 | 报文类型 | WebSocket opcode | WebSocket消息体序列化协议 |
|---|---|---|---|
| 客户端请求报文 | 开始报文 | text | json |
| 实时音频报文 | binary | 无。音频原始二进制数据 | |
| 结束报文 | text | json | |
|
服务端响应报文
|
确认开始报文 | text | json |
| 实时翻译结果报文 | text | json | |
| TTS播报报文 | binary | 实时语音翻译二进制响应报文序列化协议(见下) | |
| 确认结束报文 | text | json |