新闻资讯
关注百度智能云最新动态,了解产业智能化最新成果
IDC发布《云原生AI-加速AI工程化落地》报告,百度智能云领跑云原生AI能力
2022-07-12 22:08:14近年来,AI 模型愈发复杂,数据量不断增大,千亿级甚至万亿级参数的超大规模模型的出现,对 AI 工程化能力以及成本控制能力提出了更多的挑战。云原生和 AI 的组合成了大家的首要选择。据 Gartner 预测,到2023年70%的 AI 应用会基于容器和 Serverless 技术开发。实际生产中,越来越多的 AI 业务比如自动驾驶、NLP 等也正在转向容器化部署。
如何充分地利用以容器技术为代表的云原生的技术优势,降低 AI 工程化建设复杂度、降低学习成本、提升资源利用率,进而推进 AI 应用落地、加速产业智能化升级,是摆在众多企业面前的一道难题。
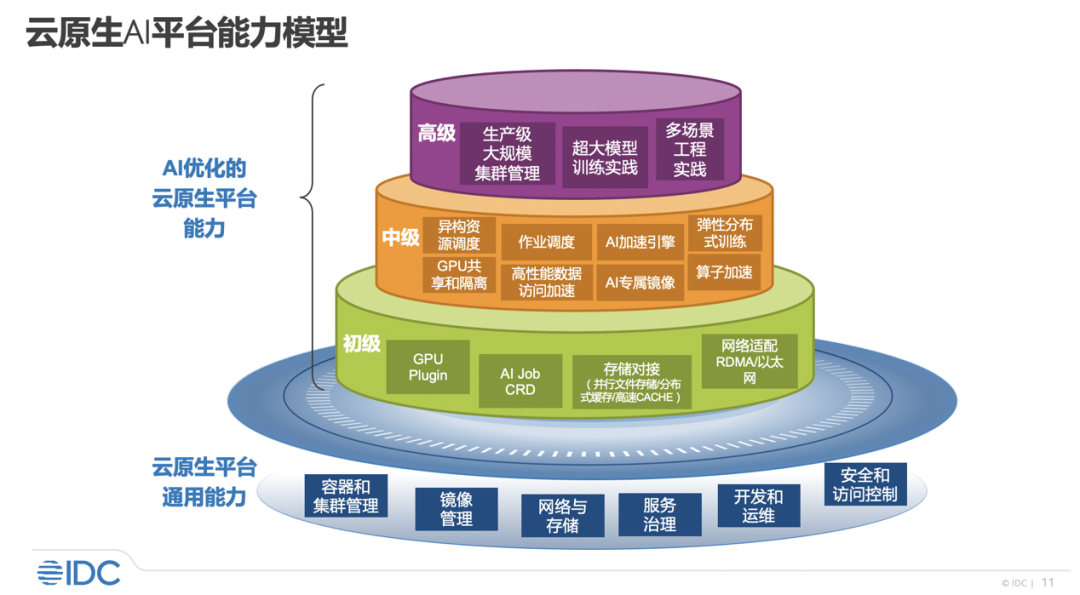
近日,IDC 发布了《云原生 AI-加速 AI 工程化落地》的报告,报告中指出云原生 AI 能够有效加速 AI 工程化落地,并对云原生 AI 的能力划分了三个等级,通过这些能力划分,能够帮助企业更好结合自己的实际业务需求选择合适的云原生 AI 能力,具体而言:
· 初级:通过 GPU Plugin、AI Job CRD 等使得 K8S 能够对接纳管异构资源和 AI 作业。
· 中级:能实现异构资源调度、GPU 共享和隔离、作业调度、AI 专属镜像,算子加速等能力,提升资源利用率,加速模型开发效率。
· 高级:拥有大规模集群管理经验及超大模型训练的实践能力,可应对复杂场景的生产级实践,全面加速大模型落地。
也就是说,初级能力使得云原生 AI 平台具备支持 AI 应用的能力;中级能力使得云原生 AI 平台在技术上获得较好的效能;而高级能力使得云原生 AI 平台在具体 AI 业务中高效稳定落地。
百度智能云的云原生 AI 解决方案最近升级发布了2.0版本,2.0版本融合了百度在 AI 大模型落地以及资源利用率提升方面的深厚经验。在跨节点架构感知、效率提升、资源弹性伸缩等多方面的能力显著提升,已经达到了 IDC 云原生 AI 能力等级划分的高级能力标准,能够支持数千卡分布式训练,将最大化地帮助企业实现 AI 应用的快速交付与落地。
百度智能云的云原生 AI2.0方案,针对超大模型的预训练提供了以下特色能力:
· 网络:全 IB 网络,盒式组网最大规模,单机转发延迟200ns,千卡通信近线性扩展。
· 通信库:自研的异构集合通信库 ECCL。支持各类异构芯片,比如不同代的 GPU,昆仑芯等。支持拓扑探测、拓扑感知、通信算法的高性能实现。
· 调度:跨节点架构感知高性能调度,支持通过慢节点感知发现分布式训练节点的性能瓶颈。
· 可观测:自研面向模型并行的多机调优 profile 工具,能够发现任务/数据分配不均等问题,经过优化的最终端到端吞吐可提升1倍以上。
不仅仅是超大模型预训练场景中沉淀出了深厚的 AI 工程能力,百度智能云的云原生 AI2.0还对资源弹性、资源利用率、训练推理效率、易用性等通用能力做了全面升级。比如支持用户态、内核态的“双引擎 GPU 容器虚拟化方案”,可满足各类 AI 应用场景;推出了 AI 加速套件 AI Accelerate Kit(简称 AIAK),用来加速 Pytorch、TensorFlow 等深度学习框架的 AI 应用,可使得经典模型的分布式训练加速提升1倍,推理时延降低一半。
目前,百度智能云的云原生 AI 解决方案已经在多个场景落地:
案例一:YY
语音社交产品 YY 语音的 AI 业务主要支撑手游以及 PC 端的媒体智能化业务场景,例如,主播以及连麦相关人物的美颜,语音和图像的审核以及命名昵称等文本的审核,短视频和直播场景的视频理解和识别。
YY 希望建设一个用来支撑机器学习的训练平台,能够在单机多卡以及多机多卡的训练场景中,提升 GPU 资源池的利用率。比如在管理大规模的 GPU 计算资源时,避免独占整张 GPU 卡等。
百度智能云团队利用 GPU device plugin 实现多 Pod 共享单张 GPU 卡时进行显存和算力级别的隔离,解决 AI 训练等场景中独占整张卡造成资源浪费的情况,提升了整体 GPU 资源的利用率,成本降低30%左右。同时内置 Tensorflow 、Pytorch 等多种分布式训练框架,支持一键安装,极大地降低分布式作业部署难度。
案例二:某自动驾驶客户
自动驾驶的感知,决策规划等业务场景,有海量的图像与3D 点云数据,需要数据并行的分布式训练。同时,不同的算法工程师有自己的框架(Pytorch、TensorFlow 等)使用偏好,需要充分考虑满足。而在开发机场景,GPU 间歇使用,存在平均利用率不足,导致资源浪费的问题。
百度智能云提供的云原生 AI 方案支持 GPU 架构感知、 AI 框架作业编排,提供 TensorFlow、Pytorch 等多种深度学习框架的 operator,降低了分布式训练门槛,通过支持 RDMA 网络适配,自研通信库加速,感知调度等全面加速多级多卡训练效率。小模型和开发机训练场景可使用 GPU 资源共享提升单 GPU 的部署密度,提升资源利用率,为仿真业务提供优先级调度,可高优验证重要仿真场景。最终提升 GPU 资源利用率50%以上,极大地减少自建基础设施维护成本。