百度智能云新一代云原生产品加速 AI 原生应用落地
作者:xxinjiang2024.10.23 18:10浏览量:13515简介:围绕 AI 原生大背景下,百度智能云在基础公有云的计算、存储、网络以及云原生等产品和技术方面工作分享
本文整理自百度云智峰会 2024 —— 云原生论坛的同名演讲。
今天为大家分享在过去的一年里,围绕 AI 原生的大背景下,百度智能云在基础公有云的计算、存储、网络以及云原生等产品和技术方面所做出的核心工作。
随着大模型所带来的 AI 技术的代际演化,我们总结在云上存在三种典型的工作负载: 以「数据并行」为核心思想的「大数据」计算负载,以「应用并行」为核心思想的「云原生」工作负载,以及以分布式「张量并行」计算来实现大模型训练和推理的「大模型」工作负载。
为了更好的支撑这三种典型的工作负载,我们以云原生架构和 AI 原生架构的深度技术融合为中心思想,重点围绕云原生计算、云原生网络、云原生存储和云原生应用这 4 个方向来打造新一代的基础公有云产品和技术体系。
云原生计算:基于新一代 CPU 和 GPU 芯片实现算力升级,结合 DPU 技术,打造极致的性价比计算产品;
云原生网络:基于云原生架构和软硬结合技术,在性能和规模上全面升级,实现高效组网;
- 云原生存储:基于新一代目录树架构,打造云原生数据湖产品体系,为 AI 应用提供数据存储底座;
- 云原生应用:面向开发者友好,建设云原生应用产品的企业级特性,提升应用部署管理效率。

在云原生计算方向,发布全新一代的计算实例和一系列企业级能力的升级。
在通用计算方面,结合新一代 Intel 和 AMD cpu 芯片,百度智能云上全新一代的 Intel EMR 和 AMD genoa 计算实例已经全面开放售卖。同时我们明年会推出基于 Intel 至强 6 的计算产品,全系产品主频在 3.3GHz 以上,满足对高主频算力有需求的场景。
在异构计算方面,百度智能云提供支持多种异构芯片的计算产品,包括国际主流的 L20/H20 等 GPU,以及自研加速芯片等计算产品,面向推理和训练场景全面优化性能,最高配备 3.2T 的 RDMA 高速网络,实现算力和网络的最佳配比,形成形态丰富的异构算力矩阵。
面向 AI 计算对模型安全的强烈需求,结合 Intel TDX 技术,我们发布了机密计算虚机产品,基于硬件实现内存和显存的数据加密,让应用无需修改就能实现加密能力。同时基于我们在虚拟机技术上的深厚积累,在总线拓扑和设备虚拟化等方面做了大量优化,极致降低了性能损耗,满足大模型训练和推理在计算性能和模型安全方面的双重要求。
百度智能云计算产品还实现了一系列企业级的产品能力升级, 基于大模型技术升级了智能终端,全面集成了 AI 助手,面向开发者完善了实例诊断和健康检查能力;面向短链接等应用场景提供了性能优化,面向不同 CPU 平台的应用迁移提供了专属的性能诊断和优化工具 Btune 等;开放了新版维修平台,实现了可订阅和可编程的事件总线。
AI 计算场景对模型数据安全提出了更高要求,基于 Intel TDX 机密技术我们全新发布企业级密算虚机产品。如左图所示,分别展示了普通虚机、加密的纯 CPU 虚机和加密的 GPU 虚机的形态。机密虚机可以实现应用程序内存和显存的数据加密,从而保护模型的安全。
百度智能云提供了 CPU 机密虚机,保护内存数据的机密性和完整性。基于英伟达 Hopper 架构,提供 GPU 机密虚机保证模型数据的安全。除了内存和显存以外,对本地盘和云盘等持久化数据提供端到端加密能力,保证持久化数据的安全。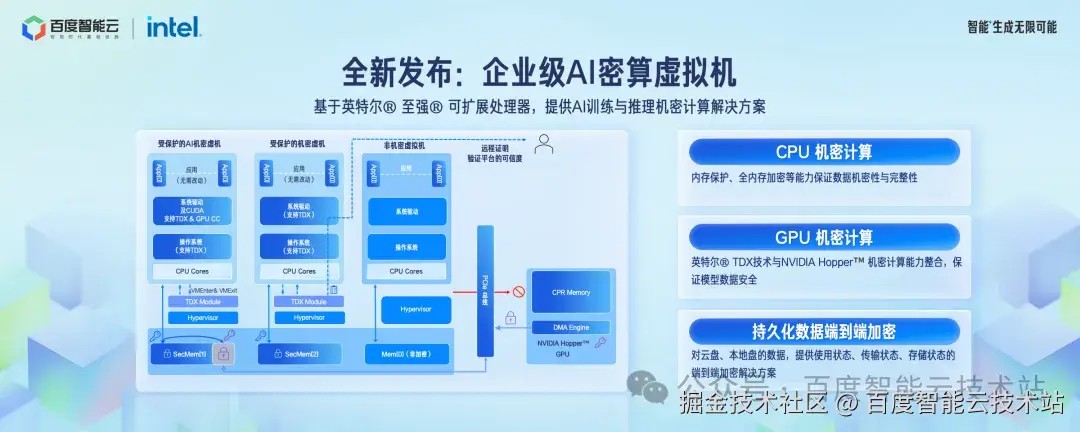
基于百度太行 DPU 2.0 实现了计算架构的全面升级。DPU是云基础设施的底座,我们将虚拟化软件全部卸载到 DPU 上,从而提供了全核售卖的虚拟机能力,同时将存储和网络的 I/O 数据流利用 DPU 进行卸载和硬件加速,提供了可预期的存储和网络 I/O 性能,网络带宽升级到 200Gbps,网络转发性能达到 5000 万 PPS。
基于 DPU 进一步研发了层级 QoS 能力,保证多租户之间的性能公平和隔离。基于 DPU 的卸载能力,实现了弹性裸金属实例 BBC 的分钟级创建和删除,只有依托于 DPU 技术才可能高效的管理裸金属产品。
为了更好地满足客户对云上网络的灵活性诉求,我们对虚拟网络的产品和技术进行了全面的升级和重构,实现了虚拟网络 3.0 版本的进阶,更高效地支持企业在云上组网。网络接入方面,专线接入带宽扩容到百 Tbps 量级,新发布 L2 网关产品,支持云上云下大二层网络的打通。虚拟网络的规模能力实现了全面提升,单 VPC 支持到 300w 个 IP 地址规模,跨地域带宽和单个实例的服务网卡带宽容量实现了整体提升。
云上网络安全作为企业应用的守护者,也实现了全方位升级。安全防护产品带宽提升至 Tbps 水平,同时能够支持第三方安全设备的接入,满足自定义的安全防护需求。整体上百度智能云通过虚拟网络 3.0 的全新升级,在弹性、性能、规模和安全等能力上均得到了大幅提升,可以更好的满足企业应用灵活组网的要求。

百度智能云虚拟网络控制器架构基于云原生的设计思想进行了全面的重构,可以更好的满足云原生应用对网络弹性能力的要求。
云原生化的虚拟网络控制器架构主要包括 3 方面的技术改造:通过转发表项的动态学习技术,将 vSwitch 的内存占用降到了最低水平,使得单 VPC 支持的 IP 地址数量达到 300 万个。通过云原生化声明式架构的设计思想,大幅提升了虚拟网络IP地址和网络设备的创建效率,IP 分配速度提升至 3000 个/秒,最终可以实现分钟级交付 10 万核算力的能力。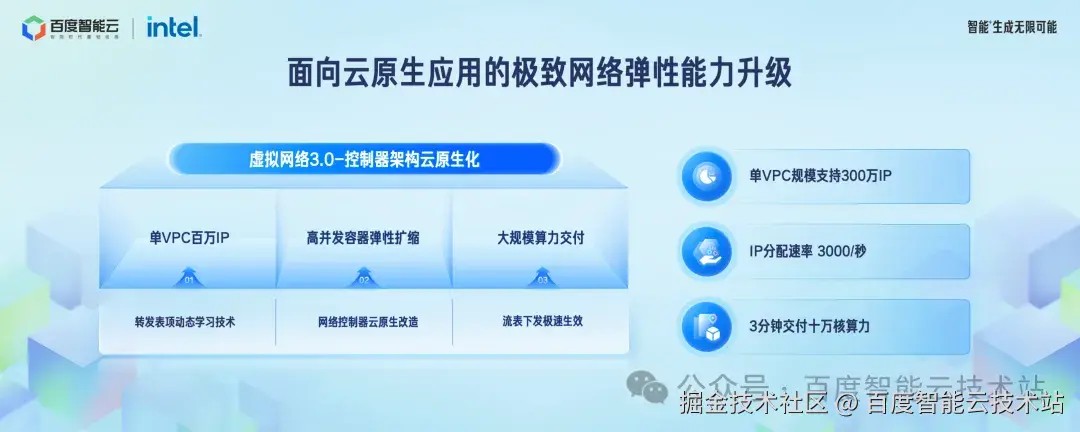
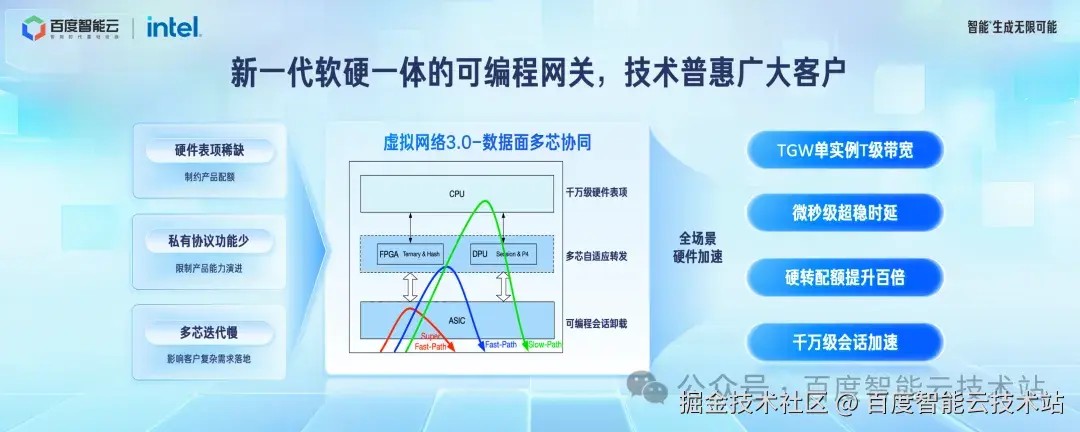
虚拟网络 3.0 数据面部分引入了新一代可编程硬件。传统的可编程芯片存在一定弊端,主要表现在硬件表项不足,私有协议功能弱等问题。我们通过组合 FPGA、DPU、可编程芯片等多种芯片,研发了新一代软硬一体的可编程网关,形成超快速路径、快速路径、慢速路径三条核心转发平面,进而实现了微秒级报文转发时延、千万级 session 加速、Tb 级接入网关等核心能力,让广大用户享受到超高性能和超稳延迟的网络报文转发能力。
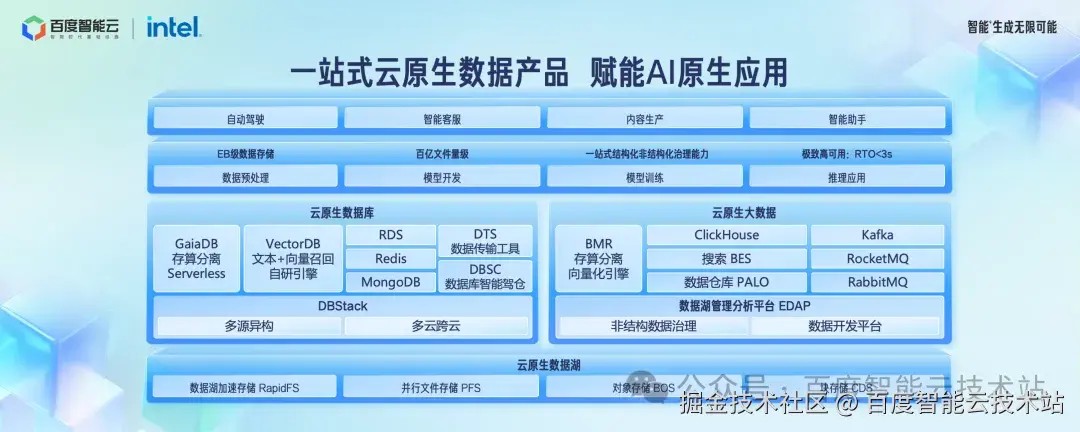
围绕 AI 原生应用场景,百度智能云在数据库和大数据方面做了完整的产品布局。基于新一代目录树架构技术,进一步提升了云原生数据湖的性能和大数据分析的产品功能。同时我们也发布了自研的向量数据库产品,相比开源版本性能更优,在企业级产品管理能力方面。百度智能云数据库和大数据产品涵盖数据处理、模型开发、模型训练、推理应用的主流 AI 原生应用场景。
云原生应用产品体系以面向开发者友好为核心思想,我们进行了全系产品升级。以容器产品为基础,全面加强云原生应用产品的企业级产品特性,简化运维复杂度,做到性能和稳定性的提升,覆盖应用部署、应用可观测和应用可运维的应用全生命周期,释放开发者生产力。
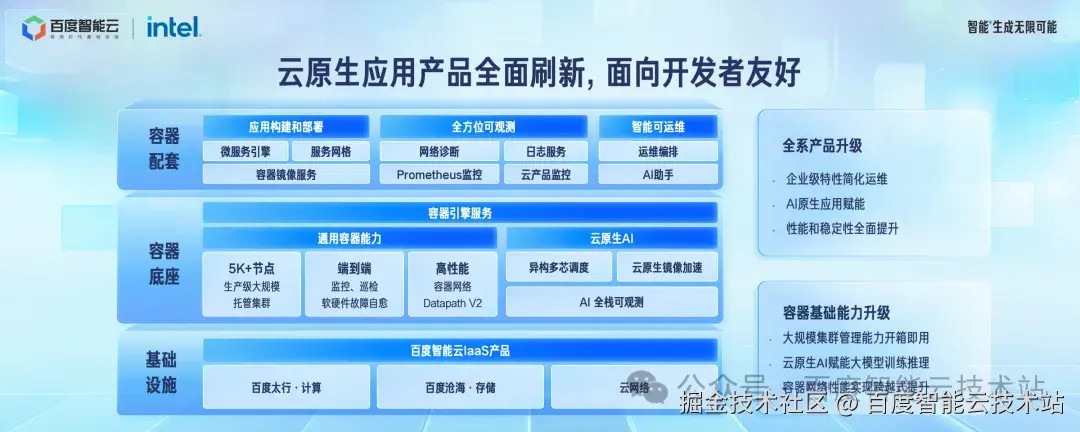
容器产品是云原生的基础,我们围绕容器基础能力进行了全新的设计和优化。在企业级能力上,全新发布容器集群规格的产品化能力,不同规模的集群关联的配套 IaaS 产品整体交付,实现集群开箱即用。我们对集群管理核心架构进行了技术重构,集群节点规模提升了 10 倍, 容器网络数据面路径 bypass 了 host 内核协议栈。相比非容器网络情况下,性能损耗降低到 1% 左右。 我们进一步完善集群托管能力,核心控制面组件全部被托管,节点组提供了操作系统升级和维护能力,可以有效降低运维复杂度。结合 serverless 型容器产品 BCI 可以实现每分钟创建 4000 个容器的能力。

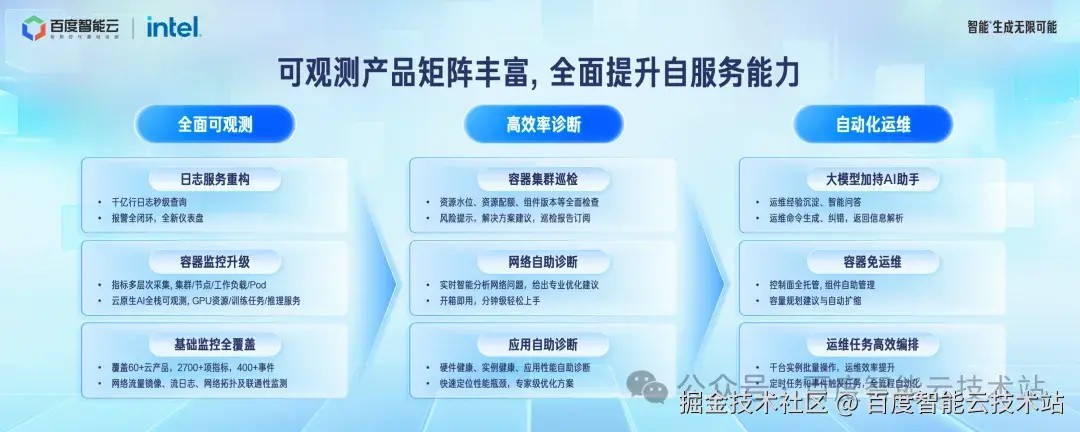
丰富的云上可观测产品矩阵,覆盖从问题发现到问题定位,再到问题解决整个流程,全面提升开发者的自服务能力,可以自助自主的高效解决问题。问题发现方面,可观测产品的覆盖面和问题分析能力进一步提升。日志服务进行了全面重构,实现了千亿行日志的秒级查询。容器监控丰富了云原生 AI 场景的全栈监控指标。问题定位方面,包含了容器集群、应用和网络的自助诊断功能。
应用性能诊断和优化工具 Btune 中集成了大量性能优化经验,不仅可以快速定位性能瓶颈,还会输出优化建议并一键完成性能优化。问题解决方面,进一步丰富了问题解决效率和自动化的运维产品。通过大模型加持的 AI 助手,可以快速生成操作命令。通过运维编排产品,实现千台实例的批量操作,提升运维效率。
新一代核心技术和产品能力的提升,让我们更多的客户享受到了技术的红利。利用虚拟网络性能的提升,搜广推场景的客户应用服务性能得到 2-3 倍提升。基于百度智能云的弹性能力,满足音视频直播类客户极速扩缩容需求,支持国民 3A 游戏大作的热潮。利用可信计算产品,让应用透明地运行在加密虚机内,保障广大金融类客户数据和模型的安全。

在生成式 AI 的技术浪潮下,百度智能云通过不断强化云原生和 AI 原生的双引擎能力,帮助广大企业加速 AI 原生应用的业务落地,共同迎接 AI 原生的新时代。