数据处理中常见的归一化方法有哪些?为什么要对数据进行归一化?
作者:文心快码BaiduComate2024.10.14 11:34浏览量:1536简介:数据处理中常见的归一化方法有哪些?为什么要对数据进行归一化?

🎁👉点击进入文心快码 Baidu Comate 官网,体验智能编码之旅,还有超多福利!🎁
🔍【大厂面试真题】系列,带你攻克大厂面试真题,秒变offer收割机!
❓今日问题:数据处理中常见的归一化方法有哪些?为什么要对数据进行归一化?
❤️一起看看文心快码Baidu Comate给出的答案吧!如果这个问题你也会,也可以在评论区写出你的答案哦~
@Comate
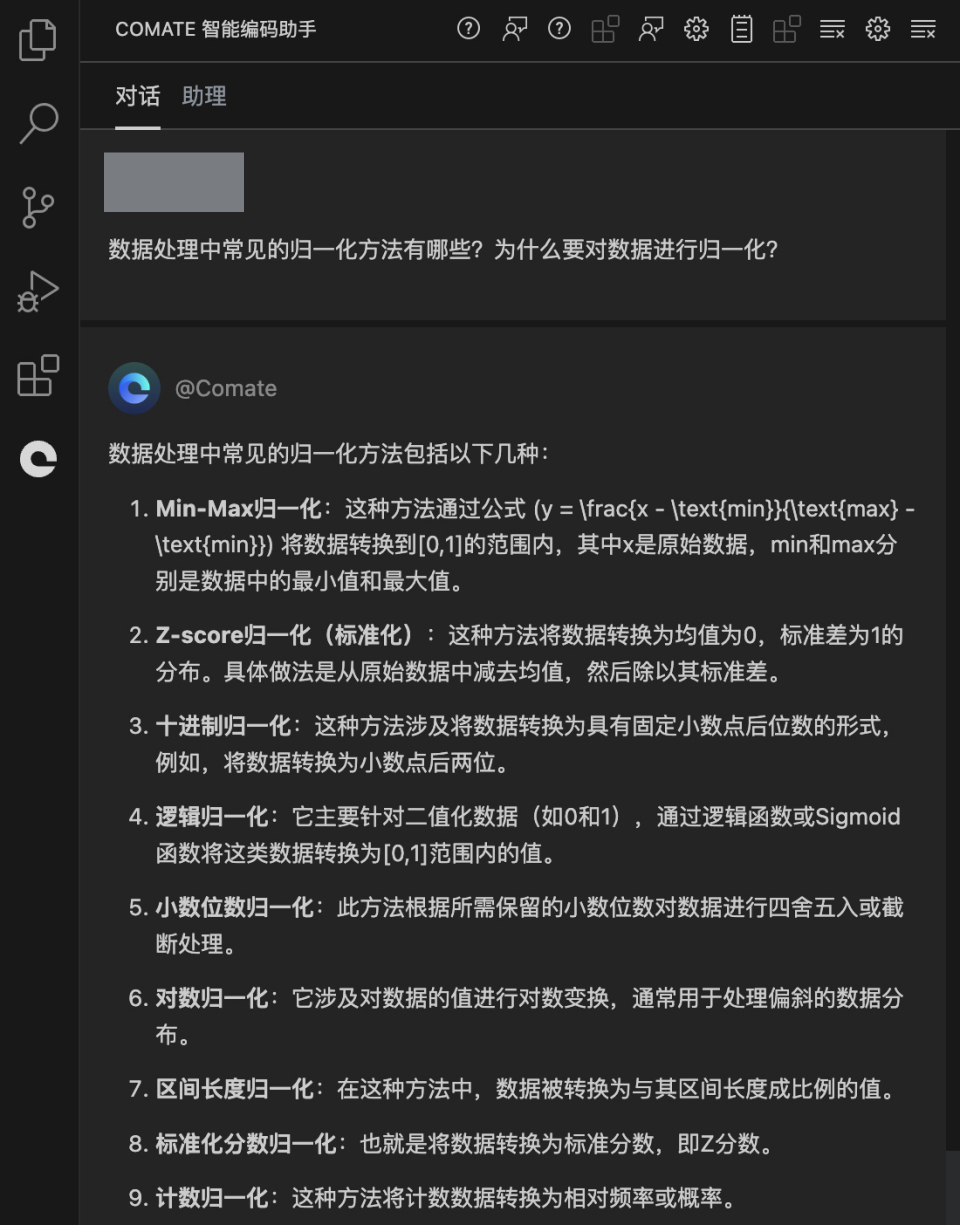
数据处理中常见的归一化方法包括以下几种:
Min-Max归一化:这种方法通过公式 (y = \frac{x - \text{min}}{\text{max} - \text{min}}) 将数据转换到[0,1]的范围内,其中x是原始数据,min和max分别是数据中的最小值和最大值。
Z-score归一化(标准化):这种方法将数据转换为均值为0,标准差为1的分布。具体做法是从原始数据中减去均值,然后除以其标准差。
十进制归一化:这种方法涉及将数据转换为具有固定小数点后位数的形式,例如,将数据转换为小数点后两位。
逻辑归一化:它主要针对二值化数据(如0和1),通过逻辑函数或Sigmoid函数将这类数据转换为[0,1]范围内的值。
小数位数归一化:此方法根据所需保留的小数位数对数据进行四舍五入或截断处理。
对数归一化:它涉及对数据的值进行对数变换,通常用于处理偏斜的数据分布。
区间长度归一化:在这种方法中,数据被转换为与其区间长度成比例的值。
标准化分数归一化:也就是将数据转换为标准分数,即Z分数。
计数归一化:这种方法将计数数据转换为相对频率或概率。
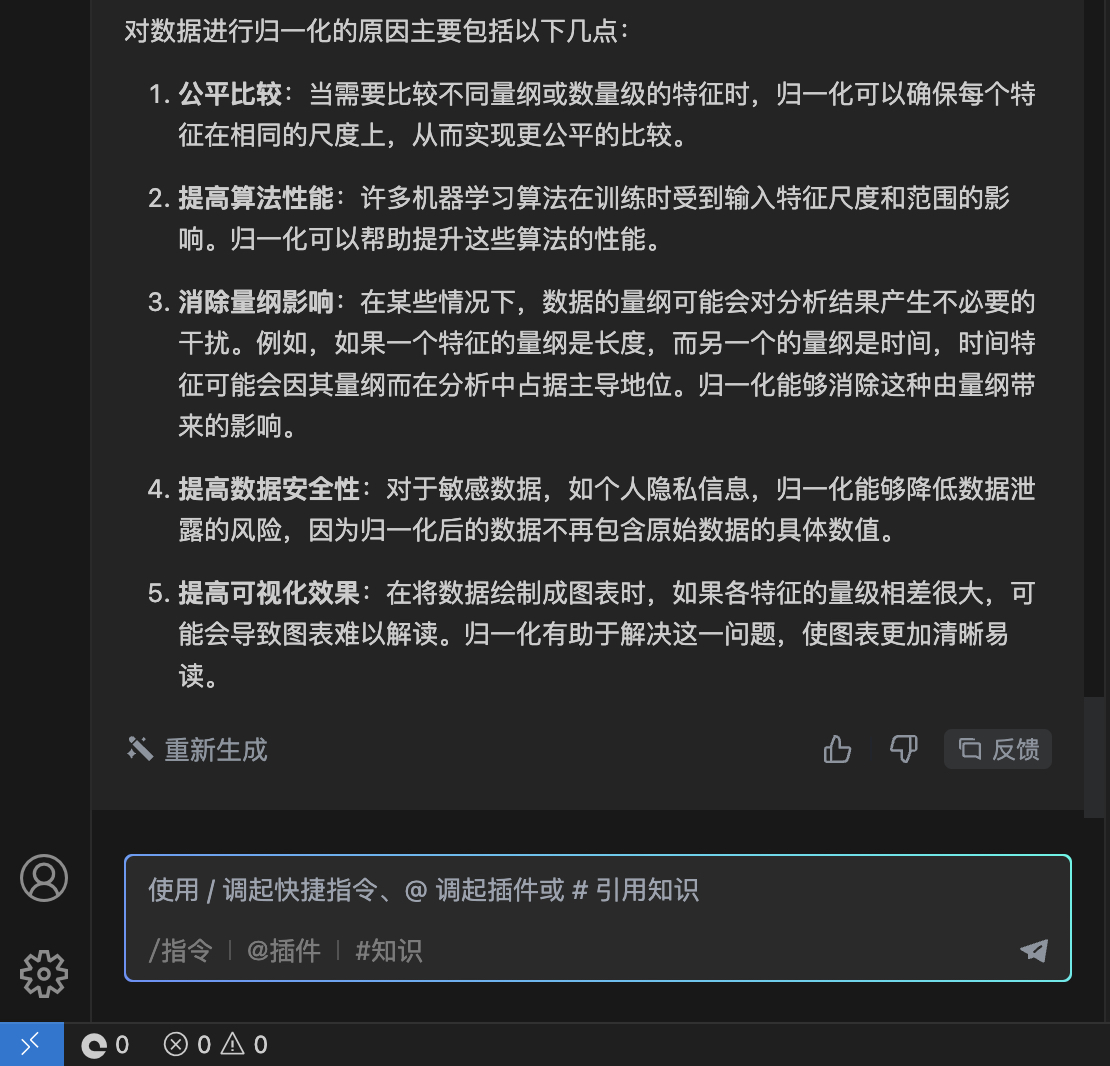
对数据进行归一化的原因主要包括以下几点:
公平比较:当需要比较不同量纲或数量级的特征时,归一化可以确保每个特征在相同的尺度上,从而实现更公平的比较。
提高算法性能:许多机器学习算法在训练时受到输入特征尺度和范围的影响。归一化可以帮助提升这些算法的性能。
消除量纲影响:在某些情况下,数据的量纲可能会对分析结果产生不必要的干扰。例如,如果一个特征的量纲是长度,而另一个的量纲是时间,时间特征可能会因其量纲而在分析中占据主导地位。归一化能够消除这种由量纲带来的影响。
提高数据安全性:对于敏感数据,如个人隐私信息,归一化能够降低数据泄露的风险,因为归一化后的数据不再包含原始数据的具体数值。
提高可视化效果:在将数据绘制成图表时,如果各特征的量级相差很大,可能会导致图表难以解读。归一化有助于解决这一问题,使图表更加清晰易读。
🎁👉点击进入文心快码 Baidu Comate 官网,体验智能编码之旅,还有超多福利!🎁
