深入理解RDMA和socket-----比较RDMA和socket编程异同
作者:翟文杰2021.12.27 11:05浏览量:1500简介:介绍对比RDAM编程和socket编程异同
1.简介
作者简介:翟文杰,百度人百度魂
深入理解SOCKET三板斧recv,send,epoll。
浅浅理解RDMA三板斧ibv_post_send,ibv_post_recv,ibv_poll_cq。
TODO:
- 内核中的nvme_tcp_data_ready(网卡将数据直接DMA至傲腾内存?),source code:https://elixir.bootlin.com/linux/latest/source/drivers/nvme/host/tcp.c#L1498
- ep_poll_callback如何找到相关联的epitem并插入到rdlist中的。
- RDMA内存注册时,mlock如何锁住物理页不被换出。
- cqe如何完成回调。source code :https://elixir.bootlin.com/linux/latest/source/include/rdma/ib_verbs.h#L1349
巨人肩膀:
https://zhuanlan.zhihu.com/p/164908617
ref:
linux5.12.9
RDMA Aware Networks Programming User Manual Rev 1.7
linux源码快速跳转
https://elixir.bootlin.com/linux/latest/source
2.SOCKET编程
2.1 SOCK
2.1.1 SOCK中的wait_queue
如下代码所示sk_wq是sock中实现异步回调的重要结构。sk_wq中含wait_queue,用于实现回调。
struct sock{
....
union {
struct socket_wq __rcu *sk_wq;
/* private: */
struct socket_wq *sk_wq_raw;
/* public: */
};
...
}
在wait_queue其存放的数据实体如下代码所示。
struct wait_queue_entry {
unsigned int flags;
void *private;
wait_queue_func_t func;
struct list_head entry;
};
private:推测为task_struct结构
func 人如其名,是一个函数
其余两个,后续分析没有用到,所以暂未知。
2.1.2 SOCK双子星
sock中有接收队列和发送队列,其类型为sk_buff。
struct sock{
....
struct sk_buff_head sk_receive_queue;
struct sk_buff_head sk_write_queue;
....
}
sk_buff_head封装sk_buff链表头,含lock保证互斥访问,其中qlen表示链表中元素。
struct sk_buff_head {
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
__u32 qlen;
spinlock_t lock;
};
sk_buff为索引结构,四个指针(tail,end,head,data)指向实际存储地址。
struct sk_buff{
...
sk_buff_data_t tail;
sk_buff_data_t end;
unsigned char *head,
*data;
...
}
sk_buff由alloc_skb装配,该函数首先尝试在内核cache上分配sk_buff,不行就换到内核上。分配器是在numa架构上分配,为了支持numa进行了多层封装(具体如何在numa上分配,未知),最后跳到do_kmalloc,分配内核地址空间。
struct sk_buff *__alloc_skb(unsigned int size, gfp_t gfp_mask,
int flags, int node)
{
struct kmem_cache *cache;
struct sk_buff *skb;
u8 *data;
bool pfmemalloc;
cache = (flags & SKB_ALLOC_FCLONE)
? skbuff_fclone_cache : skbuff_head_cache;
/* Get the HEAD */
if ((flags & (SKB_ALLOC_FCLONE | SKB_ALLOC_NAPI)) == SKB_ALLOC_NAPI &&
likely(node == NUMA_NO_NODE || node == numa_mem_id()))
skb = napi_skb_cache_get();
else
skb = kmem_cache_alloc_node(cache, gfp_mask & ~GFP_DMA, node);
...
data = kmalloc_reserve(size, gfp_mask, node, &pfmemalloc);
...
return skb;
}
总结,sk_buff和其实际存储地址data均在内核地址空间上分配。
2.1.3 sock和进程
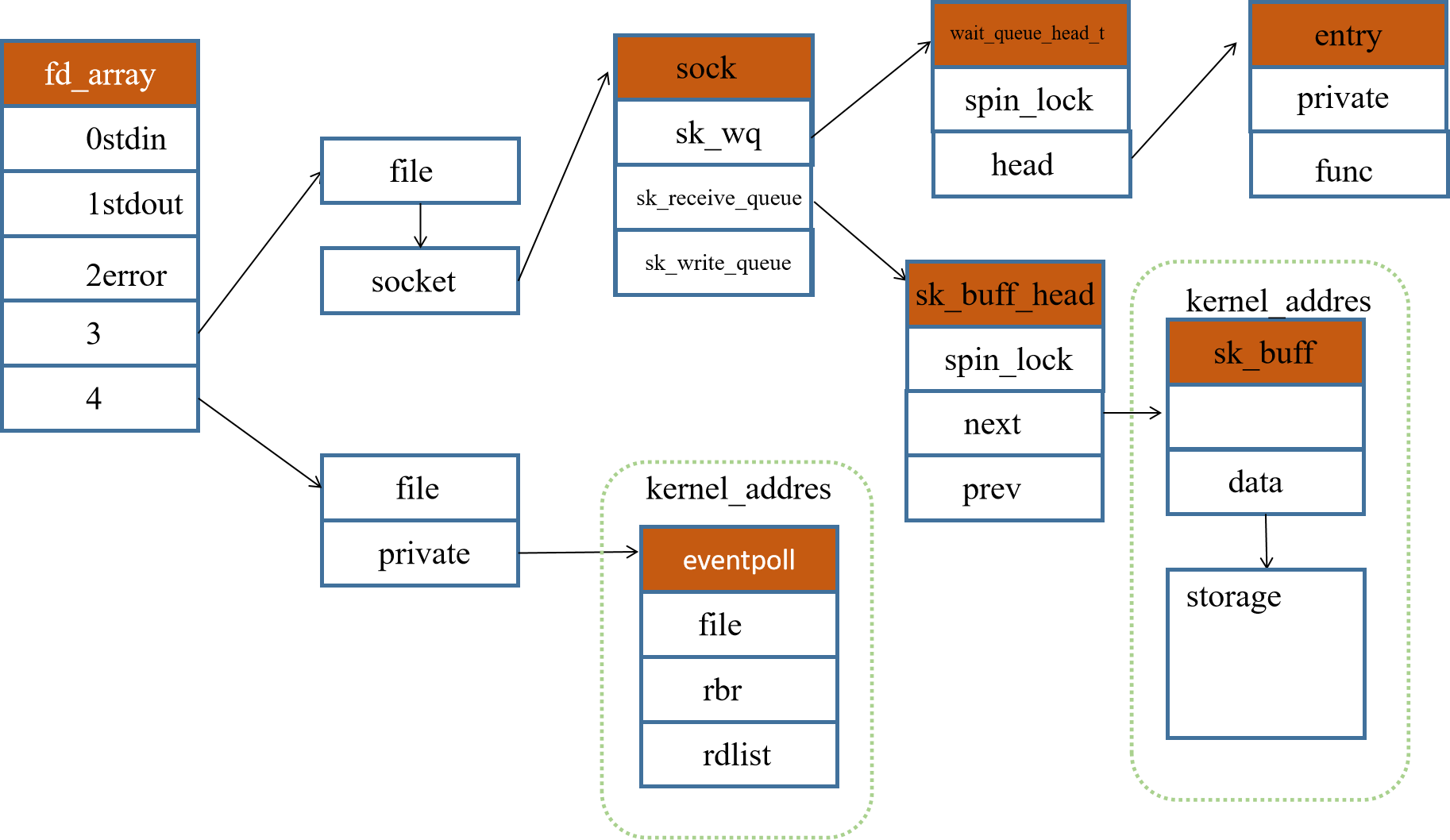
2.2 Recv
2.2.1 Recv工作流程
在上节中,提到了sock中的等待队列中的实体中有一个func指针,用于回调。那么现在看看这个func是如何被赋值的,即当数据包抵达网卡时,具体是如何完成回调通知用户程序数据已到。假设recv传入socket是tcp协议,recv实际调用tcp_recvmsg。
int tcp_recvmsg(struct sock *sk, struct msghdr *msg, size_t len, int nonblock,
int flags, int *addr_len)
{
...
lock_sock(sk);
ret = tcp_recvmsg_locked(sk, msg, len, nonblock, flags, &tss,
&cmsg_flags);
release_sock(sk);
...
}
实际调用到tcp_recvmsg_locked。当sock缓冲队列中无数据时,调用到sk_waid_data
static int tcp_recvmsg_locked(struct sock *sk, struct msghdr *msg, size_t len,
int nonblock, int flags,
struct scm_timestamping_internal *tss,
int *cmsg_flags)
{
int copied = 0;
int target; /* Read at least this many bytes */
...
if (copied >= target) {
/* Do not sleep, just process backlog. */
release_sock(sk);
lock_sock(sk);
} else {
sk_wait_data(sk, &timeo, last);
}
...
}
进入到sk_wait_data中,看到了希望的曙光,因为太过激动故特意贴出代码连接:https://elixir.bootlin.com/linux/latest/source/net/core/sock.c#L2585。这段代码逻辑简单,即生成waitqueue实体,赋值其func为woken_wake_function,然后将这个实体加入到sk_wq中去。最后sk_wait_event休眠自己。
int sk_wait_data(struct sock *sk, long *timeo, const struct sk_buff *skb)
{
DEFINE_WAIT_FUNC(wait, woken_wake_function);
int rc;
add_wait_queue(sk_sleep(sk), &wait);
sk_set_bit(SOCKWQ_ASYNC_WAITDATA, sk);
rc = sk_wait_event(sk, timeo, skb_peek_tail(&sk->sk_receive_queue) != skb, &wait);
sk_clear_bit(SOCKWQ_ASYNC_WAITDATA, sk);
remove_wait_queue(sk_sleep(sk), &wait);
return rc;
}
其中DEFINE_WAIT_FUNC为宏定义,用于产生wait实体,可以看见在这里定义其回调函数为woken_wake_function,进一步推进可知它实际最后调用到了default_wake_function。设置private为current,人如其名,我推测这个current应该就是当前进程的task_struct。这样唤醒的时候才知道是谁在等待。
#define DEFINE_WAIT_FUNC(name, function) \
struct wait_queue_entry name = { \
.private = current, \
.func = function, \
.entry = LIST_HEAD_INIT((name).entry), \
}
进到sk_wait_event瞅一瞅,current果然应该是task_struct,修改当前进程的状态,然后sched一次,让出cpu。
#define sk_wait_event(__sk, __timeo, __condition, __wait) \
({ int __rc; \
release_sock(__sk); \
__rc = __condition; \
if (!__rc) { \
*(__timeo) = wait_woken(__wait, \
TASK_INTERRUPTIBLE, \
*(__timeo)); \
} \
sched_annotate_sleep(); \
lock_sock(__sk); \
__rc = __condition; \
__rc; \
})
2.2.2 Recv后,数据结构的变化
sk_wq队列中喜提小弟一个,程序在sk_wait_event处让出cpu,回来的时候继续往下执行。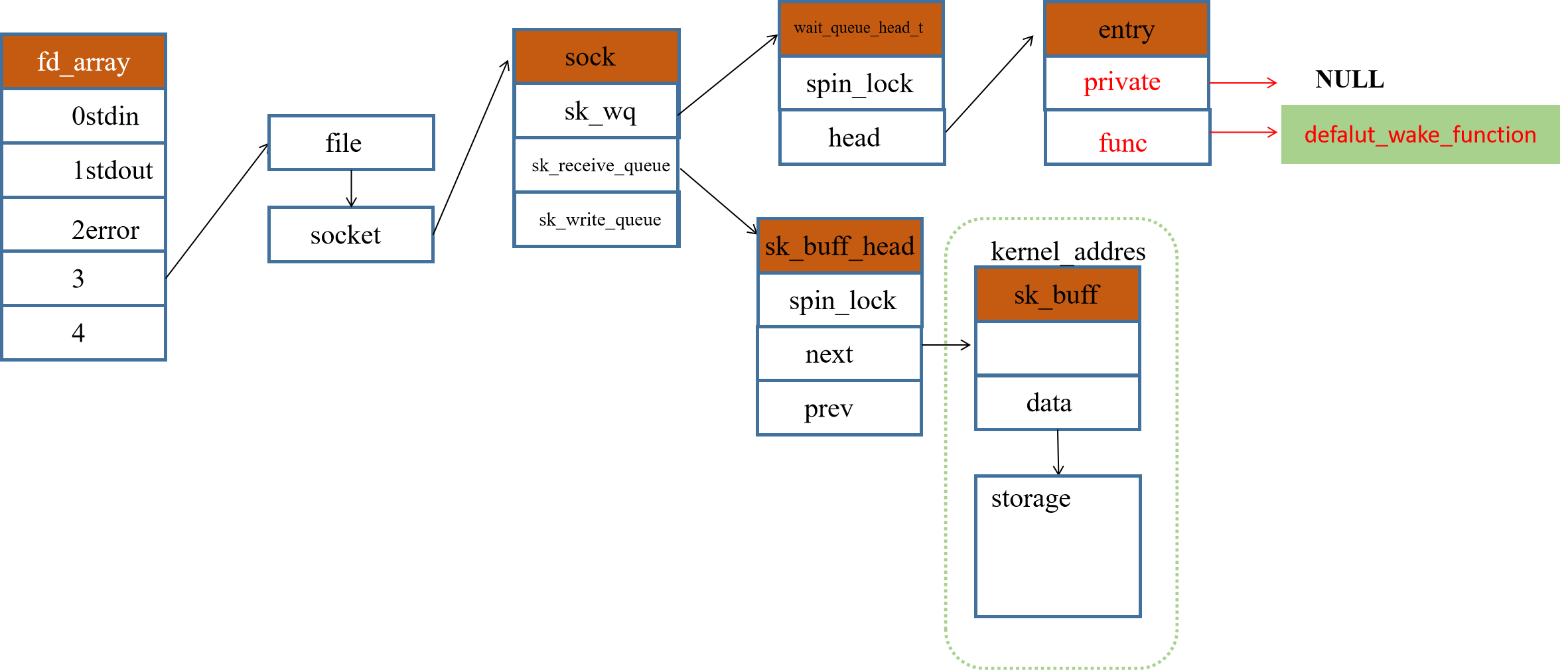
2.2.3 收到数据包后,recv如何被唤醒的
在recv之后,相应的数据结构都被设置好。接下来从tcp协议栈总入口tcp_v4_rcv分析,数据到达网卡后的工作流程。这部分直接进到tcp_rcv_established中,如下所示两句代码负责将数据加入到sock中的接收队列中并唤醒。
void tcp_rcv_established(struct sock *sk, struct sk_buff *skb)
{
...
tcp_event_data_recv(sk, skb);
tcp_data_ready(sk);
...
}
tcp_queue_rcv的代码如下所示,首先使用skb_peek_tail取出sk_receive_queued的tail,然后使用tcp_try_coalesce,将收到的skb合并到该sk_receive_queue中。
static int __must_check tcp_queue_rcv(struct sock *sk, struct sk_buff *skb,
bool *fragstolen)
{
int eaten;
struct sk_buff *tail = skb_peek_tail(&sk->sk_receive_queue);
eaten = (tail && tcp_try_coalesce(sk, tail,skb, fragstolen)) ? 1 : 0;
tcp_rcv_nxt_update(tcp_sk(sk), TCP_SKB_CB(skb)->end_seq);
if (!eaten) {
__skb_queue_tail(&sk->sk_receive_queue, skb);
skb_set_owner_r(skb, sk);
}
return eaten;
}
在将收到的skb加入到sk_receive_queue中后,使用tcp_data_ready回调注册在sock等待队列中的函数。如下代码所示,该函数调用sock中的函数指针sk_data_ready。要知道这个函数指针指向哪里,可以使用vscdoe全文件搜索大法即输入搜索关键字”sk->sk_data_ready =“ 。有一定概率成功,因为不一定是空格,比如这里赋值的时候后面跟的是一个tab。
void tcp_data_ready(struct sock *sk)
{
if (tcp_epollin_ready(sk, sk->sk_rcvlowat) || sock_flag(sk, SOCK_DONE))
sk->sk_data_ready(sk);
}
最后发现sk_data_ready是在调用sock_def_readable
void sock_init_data(struct socket *sock, struct sock *sk)
{
...
sk->sk_data_ready = sock_def_readable;
...
}
ps.这里发现了一个nvme_tcp_data_ready()函数,看起来是tcp协议栈也针对nvme做了改动。
https://elixir.bootlin.com/linux/latest/source/drivers/nvme/host/tcp.c#L1498
回到主线,进入到sock_def_readable如下代码所示。
void sock_def_readable(struct sock *sk)
{
struct socket_wq *wq;
rcu_read_lock();
wq = rcu_dereference(sk->sk_wq);
if (skwq_has_sleeper(wq))
wake_up_interruptible_sync_poll(&wq->wait, EPOLLIN | EPOLLPRI |
EPOLLRDNORM | EPOLLRDBAND);
sk_wake_async(sk, SOCK_WAKE_WAITD, POLL_IN);
rcu_read_unlock();
}
然后再依次进入到
wake_up_interruptible_sync_poll->wake_up_sync_key->wake_up_common_lock->__wake_up_common中。如下代码所示,遍历sock中sk_wq中的所有实体,然后依次使用curr->func调用唤醒被挂起的进程。这样完成了唤醒停在sk_wait_event处的进程继续执行。
static int __wake_up_common(struct wait_queue_head *wq_head, unsigned int mode,
int nr_exclusive, int wake_flags, void *key,
wait_queue_entry_t *bookmark)
{
wait_queue_entry_t *curr, *next;
...
list_for_each_entry_safe_from(curr, next, &wq_head->head, entry) {
ret = curr->func(curr, mode, wake_flags, key);
}
...
}
2.2.4 唤醒时的数据结构
即先准备好数据后,再唤醒sk_wq中的所有小弟,小弟醒来后发现数据都有,只需要拿来用就好了。这种感觉就像是未来星际旅行一样,先冰冻睡觉,驾驶任务交给计算机自动驾驶,睡个几十年起来发现就到目的地了。
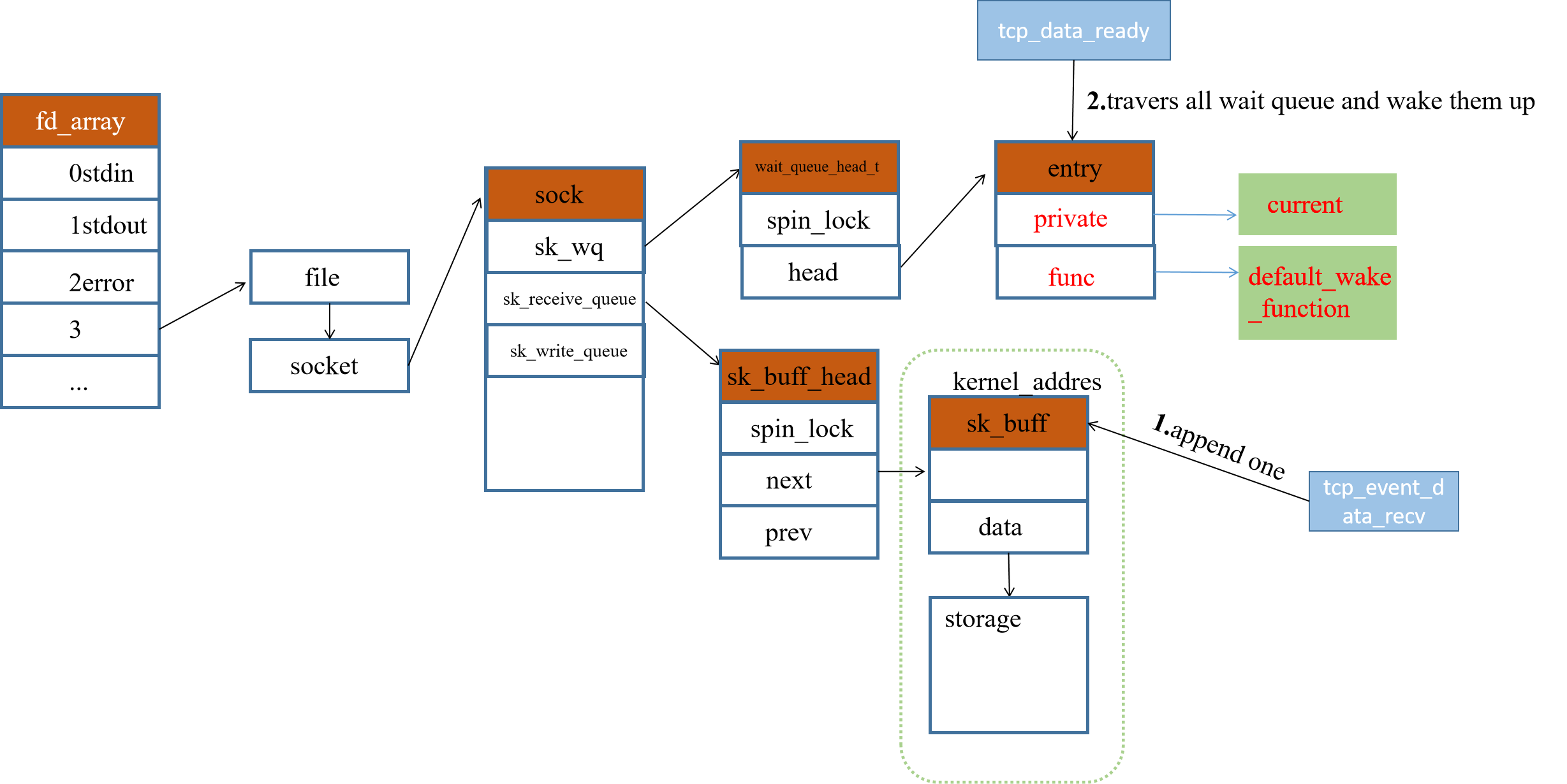
2.3 epoll
2.3.1 eventpoll 三剑客
epoll主要使用到的数据结构如下代码所示,一个wait_queue_head_t(上文已介绍用到) ,一个rdllist存放就绪的描述符,rbr红黑树。
最后一个file可以将这个结构体和进程的fd_array关联上(同socket中的file)
struct eventpoll {
wait_queue_head_t wq;
struct list_head rdllist;
struct rb_root_cached rbr;
struct file *file;
};
eventpoll 对象通过do_epoll_create创建,其代码逻辑如下所示。首先使用ep_alloc创建结构体,后使用get_unused_fd,返回文件描述符,并将该对象注册到fd_array上。
static int do_epoll_create(int flags)
{
int error, fd;
struct eventpoll *ep = NULL;
struct file *file;
...
error = ep_alloc(&ep);
...
fd = get_unused_fd_flags(O_RDWR | (flags & O_CLOEXEC));
...
file = anon_inode_getfile("[eventpoll]", &eventpoll_fops, ep,
O_RDWR | (flags & O_CLOEXEC));
ep->file = file;
fd_install(fd, file);
return fd;
}
ep_alloc调用kzalloc分配内核地址空间,因此eventpoll是一个内核地址上的对象。GFP_KERNEL这个flag在无内存可用时就进入休眠。
static int ep_alloc(struct eventpoll **pep)
{
ep = kzalloc(sizeof(*ep), GFP_KERNEL);
}
如下所示,可以看到kzalloc对kmalloc封装,__GFP_ZERO会清0存储空间内容。
static inline void *kzalloc(size_t size, gfp_t flags)
{
return kmalloc(size, flags | __GFP_ZERO);
}
调用epoll_create后,数据结构如下图所示
2.3.2 epoll_ctl 插入工作流程
epoll_ctl的工作流程如下图所示,首先根据传入的epfd和fd从fd_arrays中找到其对应的file,然后从file中取出其相应的结构。在逻辑中还会判断该fd是否已经被加入到了eventpoll对象中。在最后逻辑中,进入到ep_insert这个函数中。
int do_epoll_ctl(int epfd, int op, int fd, struct epoll_event *epds,
bool nonblock)
{
int error;
int full_check = 0;
struct fd f, tf;
struct eventpoll *ep;
struct epitem *epi;
struct eventpoll *tep = NULL;
...
f = fdget(epfd);
tf = fdget(fd);
...
ep = f.file->private_data;
...
if (op == EPOLL_CTL_ADD) {
if (READ_ONCE(f.file->f_ep) || ep->gen == loop_check_gen ||
is_file_epoll(tf.file)) {
mutex_unlock(&ep->mtx);
error = epoll_mutex_lock(&epmutex, 0, nonblock);
if (error)
goto error_tgt_fput;
loop_check_gen++;
full_check = 1;
if (is_file_epoll(tf.file)) {
tep = tf.file->private_data;
error = -ELOOP;
if (ep_loop_check(ep, tep) != 0)
goto error_tgt_fput;
}
error = epoll_mutex_lock(&ep->mtx, 0, nonblock);
if (error)
goto error_tgt_fput;
}
}
...
epi = ep_find(ep, tf.file, fd);
...
error = -EINVAL;
switch (op) {
case EPOLL_CTL_ADD:
if (!epi) {
epds->events |= EPOLLERR | EPOLLHUP;
error = ep_insert(ep, epds, tf.file, fd, full_check);
} else
error = -EEXIST;
break
.....
}
}
ep_insert的代码如下所示,改函数主要创造构建epitem结构体,并对其中元素赋值。epitem使用kmem_cache_zalloc函数分配内存,由此可见该结构体也是一个内核地址上的结构体。ffd和ep由ep_set_ffd赋值,让其指向所关联对象的file struct和相应的epfd的file struct
struct epitem {
union {
struct rb_node rbn;
struct rcu_head rcu;
};
...
struct epoll_filefd ffd;
struct eventpoll *ep;
...
};
在分配创建出epiem之后,首先将其插入到红黑树中,然后修改sock中_sk_wq的回调函数。
static int ep_insert(struct eventpoll *ep, const struct epoll_event *event,
struct file *tfile, int fd, int full_check)
{
struct epitem *epi;
if (!(epi = kmem_cache_zalloc(epi_cache, GFP_KERNEL)))
return -ENOMEM;
/* Item initialization follow here ... */
INIT_LIST_HEAD(&epi->rdllink);
epi->ep = ep;
ep_set_ffd(&epi->ffd, tfile, fd);
epi->event = *event;
epi->next = EP_UNACTIVE_PTR;
...
ep_rbtree_insert(ep, epi);
....
/* Initialize the poll table using the queue callback */
epq.epi = epi;
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
....
revents = ep_item_poll(epi, &epq.pt, 1);
...
return 0;
}
在追踪ep_item_poll时追丢了,只能从其注释和前面的init_poll_funcptr赋值来推测其进入到了ep_ptable_queue_proc这个函数里。最后终于在init_waitqueue_func_entry这里看到最后将其sock中的回调函数注册为ep_poll_callback。
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback);
}
//该函数位于wait.h下
init_waitqueue_func_entry(struct wait_queue_entry *wq_entry, wait_queue_func_t func)
{
wq_entry->flags = 0;
wq_entry->private = NULL;
wq_entry->func = func;
}
调用epoll_ctl后的数据结构如下所示:
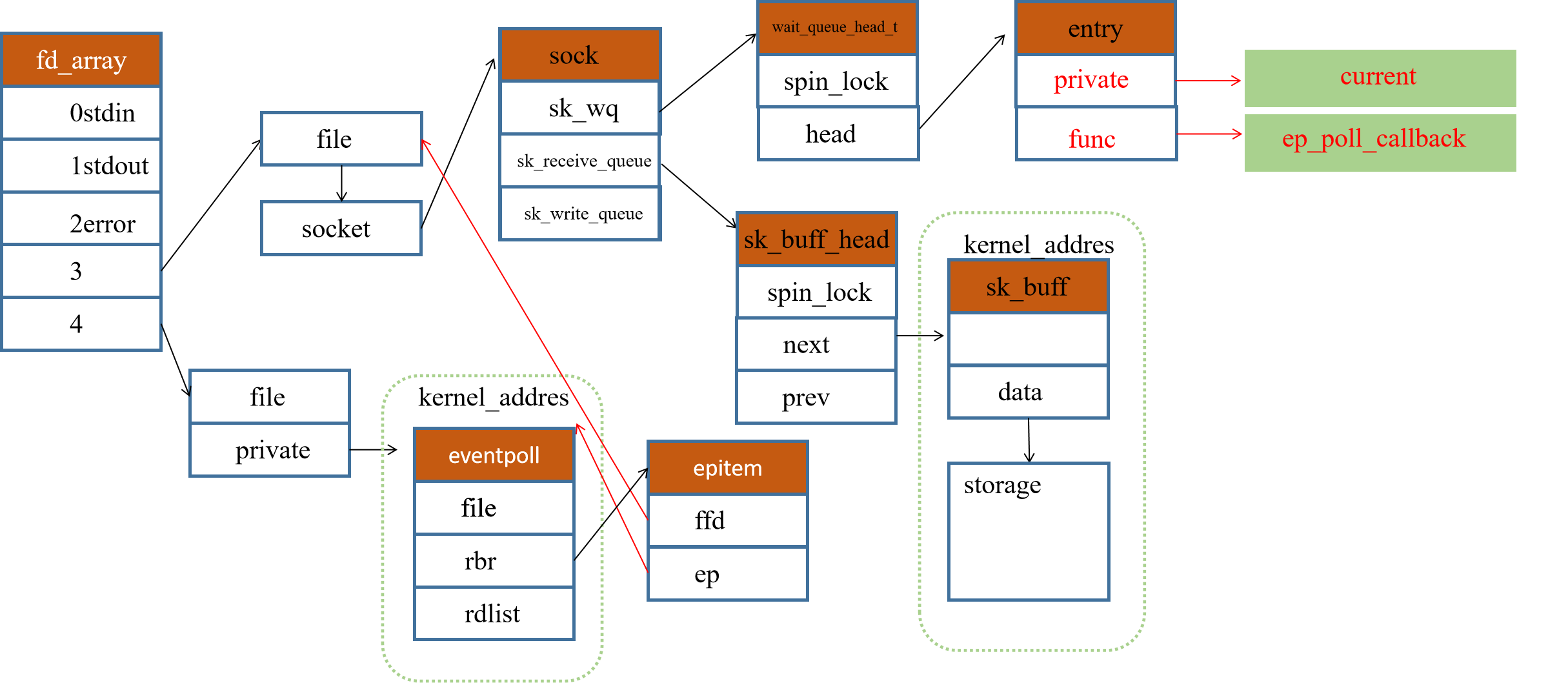
至此,epoll_ctl的整个流程结束。一旦当有数据到达相应的sock后,就会调用ep_poll_callback函数返回,其全部流程如上所示。
吼吼吼,终于快结束了,简单看看ep_poll_callback
2.3.3 ep_poll_callback
(未完待续)
3 RDMA编程
巨人的肩膀:https://www.zhihu.com/column/c_1231181516811390976
3.1 RDMA入门
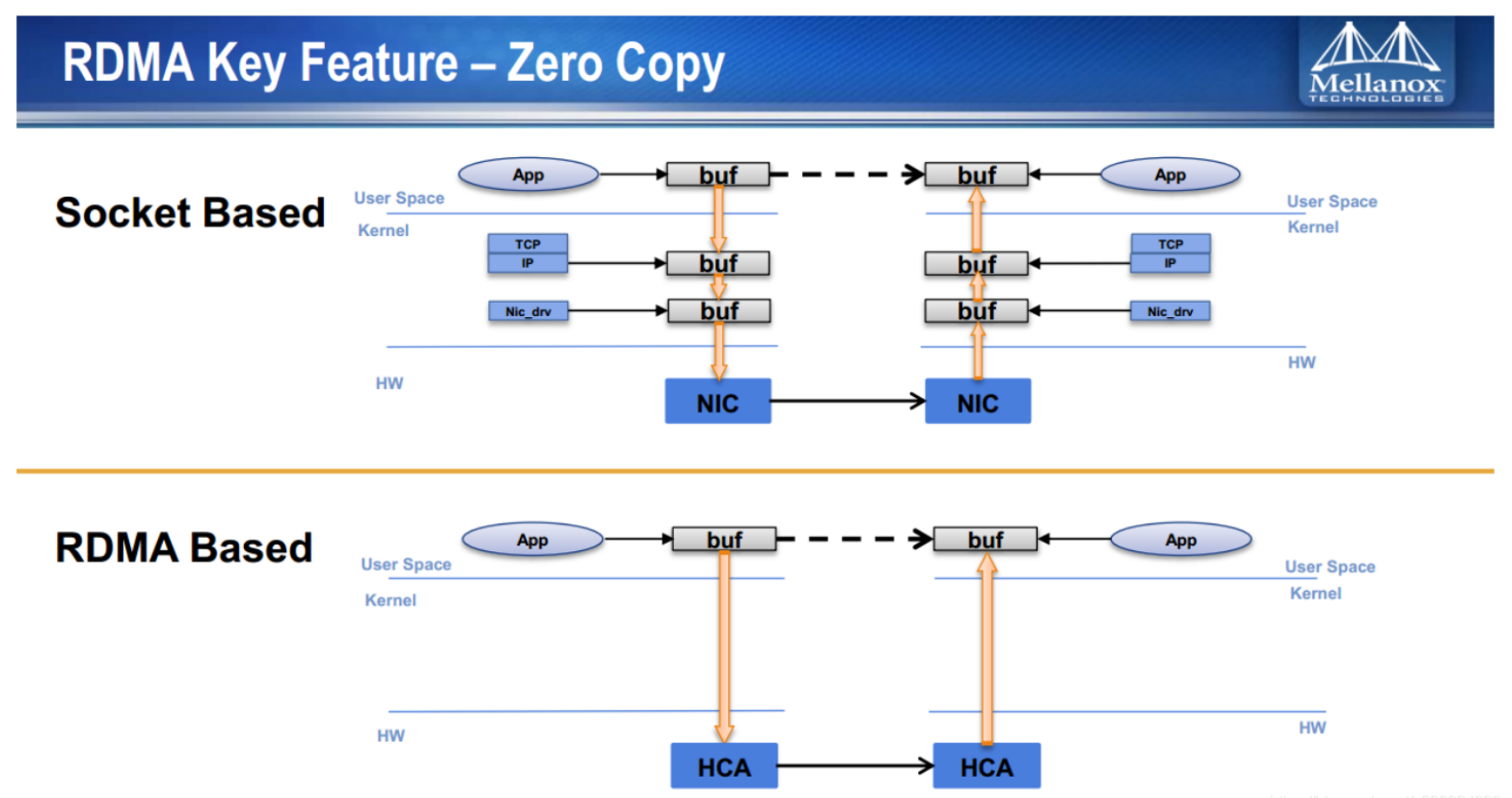
RDMA与socket的最大不同就是旁路内核,收发消息不用经过内核,同DAX旁路内核一样。application提交任务后由网卡直接DMA到远程节点内存中。下面这张图是在博客上是比较容易见到的,直接就贴过来了。
3.1.1 one more step
那么具体到内核代码上,是如何旁路内核的?用户程序通过Verbs收发数据,对应API命名规则为:ib_xxxx内核RDMA子系统,ibv_xxxx用户程序API。
在linux内核中为RDMA定义了一个ib_verbs.h的头文件,以ib_post_send为例。如果调用该函数,直接由ib_qp结构体下的device中的成员函数执行。
static inline int ib_post_send(struct ib_qp *qp,
const struct ib_send_wr *send_wr,
const struct ib_send_wr **bad_send_wr)
{
const struct ib_send_wr *dummy;
return qp->device->ops.post_send(qp, send_wr, bad_send_wr ? : &dummy);
}
从其命名中可以推测是由硬件设备直接完成。能够完成RDMA的硬件都被定义为了struct ib_device。
那么ib_device中的ops是在哪里被赋值的?暂时未知。不过从代码上,可以直接看到使用rdma发送消息的确没有经过臃肿的内核协议栈,用户态直接调用到驱动程序进行收发。
3.2 RDMA基本元素
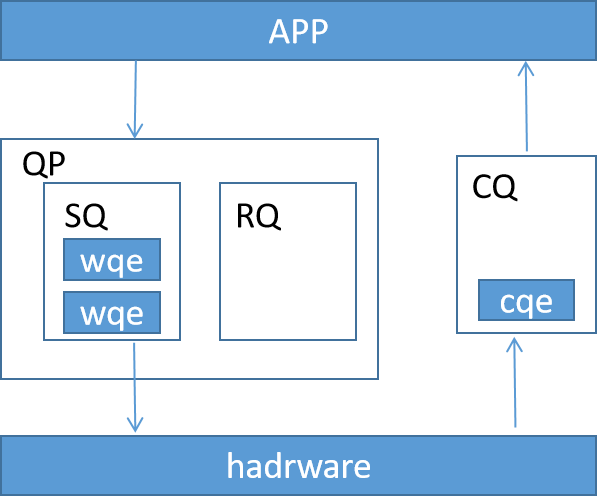
RDMA概念上的元素有很多QP、WQ,CQ等,下图能够比较清楚的解释各个元素之间的关系。在rdma编程中,最重要的元素的QP(queue pair),rdma在进行通信时是按照QP进行通信,网络节点中的每一个QP都被赋予了一个唯一的id。QP是RDMA中基本的通信单元,一个物理机可以有多个QP。
QP包含SQ(send queue)和RQ(recieve queue),是存放WQE的实体。WQ是抽象概念,SQ和RQ是WQ的具体实现。
CQ是工作完成队列,硬件每完成一个wqe,就会将一个cqe放入到cq中,用于提示APP请求的完成状态(成功,错误等)。ib_poll_cq用于获取CQ中的cqe。
3.2.1 CQE何时创建
每当硬件处理完一个WQE之后,都会产生一个CQE放在CQ队列中。如果一个WQE对应的CQE没有产生,那么这个WQE就会一直被认为还未处理完。
因此在使用ib_poll_cq获取到CQE之前:
- 必须认为这片内存区域仍在使用中,不能将所有相关的内存资源进行释放。
- 这段用于存放接收数据的内存区域中的内容是不可信的。
so far so good,如果说ib_poll_cq这个函数是阻塞的。就像上文提到的epoll那样,当且仅当数据都被DMA到内核空间后,再返回。那么返回时,在CQ中一定存在cqe并消费。
可问题就在于,ib_poll_cq这个函数竟然是不阻塞的?那么这样就不得不使用轮询的方式来完成这个取CQE的动作?
do{
num_cqes = ibv_poll_cq()
}while(num_cqes==0)
...
如果不定期poll出cqe,当cq队列满后cq会被关掉。并发送IBV_EVENT_CQ_ERR信号。
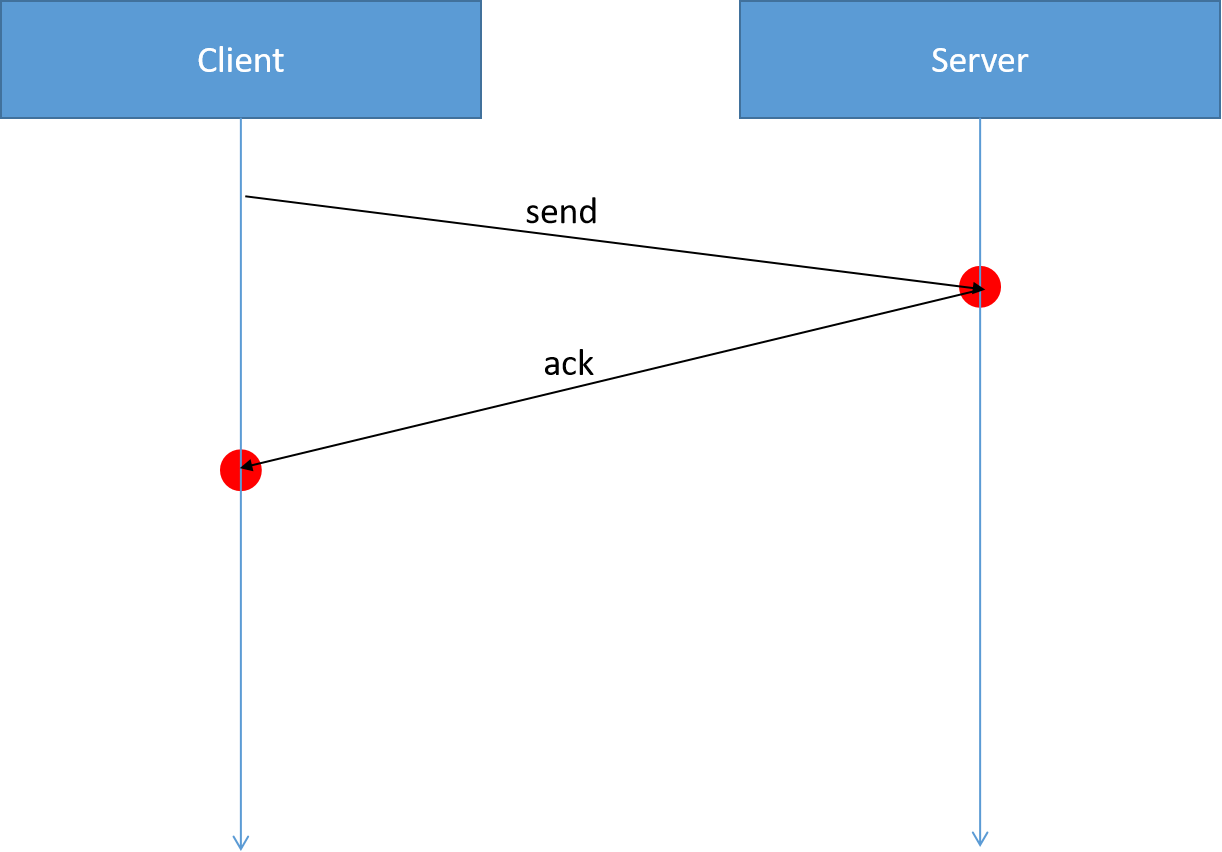
对于write操做,cqe的产生时间用红点标出

对于send操做,cqe的产生时间用红点标出
3.2.2 one more step
如下代码ib_qp描述了RDMA中的元素QP。每一个QP都有一个device指针,指向ib_device,在实际发出动作时均采用device下的ops来完成。counter即唯一标识符(订正:该counter只在本机唯一,网络中并不是唯一的),用于表示这个qp。SQ和RQ均使用结构体ib_cq描述。
struct ib_qp {
struct ib_device *device;
struct ib_pd *pd;
struct ib_cq *send_cq;
struct ib_cq *recv_cq;
....
struct rdma_counter *counter;
};
ib_cq结构体代码如下,推测应该是CQ的实现。虽然在概念上SQ和RQ是不同的两个东西,但在具体实现时,SQ和RQ使用CQ实现。
struct ib_cq {
struct ib_device *device;
struct ib_ucq_object *uobject;
ib_comp_handler comp_handler;
void (*event_handler)(struct ib_event *, void *);
void *cq_context;
int cqe;
unsigned int cqe_used;
atomic_t usecnt; /* count number of work queues */
enum ib_poll_context poll_ctx;
struct ib_wc *wc;
struct list_head pool_entry;
union {
struct irq_poll iop;
struct work_struct work;
};
struct workqueue_struct *comp_wq;
struct dim *dim;
};
cqe是一个函数指针,应该是用于实现回调。推测实现机制应该同上文所述的sock和recv。
struct ib_cqe {
void (*done)(struct ib_cq *cq, struct ib_wc *wc);
};
ib_send_wr实际存储cqe的数据结构,每一个QP都会有ib_send_wr和ib_recv_wr,ib_recv_wr以链表形式组织。
struct ib_send_wr {
struct ib_send_wr *next;
union {
u64 wr_id;
struct ib_cqe *wr_cqe;
};
struct ib_sge *sg_list;
int num_sge;
enum ib_wr_opcode opcode;
int send_flags;
union {
__be32 imm_data;
u32 invalidate_rkey;
} ex;
};
3.2.3 数据结构
总结上述数据结构如下图所示。
另:ib_post_send(struct ibv_qp qp, struct ibv_send_wr wr, struct ibv_send_wr **bad_wr):该函数按序依次处理wr链表,在处理过程中遇到第一个错误就返回,并将bad_wr指向该错误wr。

3.2.4 数据结构存储介质
这部分的问题主要是,struct ib_qp,send_cq这些数据结构被分配在哪里?是在DRAM上,还是在inifbnad上?(未完待续)
3.3 SEND和WRITE
send和recv为双端操做。A send数据,B 需要调用 recv接受。而write直接将数据发送到 B 节点中,单端操做。
(未完待续)
3.4 内存注册
为什么需要注册内存?用户程序只能访问虚拟内存地址VA,在访问介质内存时需要用页表机制翻译VA->PA。在ib_send_wr中存有内存地址、数据长度等信息、权限控制lkey等(如下代码所示)。其中lkey的赋值,由RDMA通信双方在建立连接时获得。
struct ib_send_wr {
struct ib_sge *sg_list; <- 从这里进入
};
struct ib_sge {
u64 addr; <-虚拟地址
u32 length;
u32 lkey;
};
问题就在于地址信息都是VA地址并非PA地址,若两个节点要通信,那么就需要确保有双方能够相互理解的VA转换。因此内存注册就是在硬件上创建一张VA to PA的转换页表,同时内存注册也保证了内核不会换出被注册的部分。总结下来内存注册主要有以下几点用处:
- 虚拟地址与物理地址转换
- 控制HCA访问内存的权限
- 避免换页
3.4.1 one more step
既然上面提到内存注册要锁页,保证注册后的物理页不会被linux轻易换出,linux中通过调用mlock来锁页。
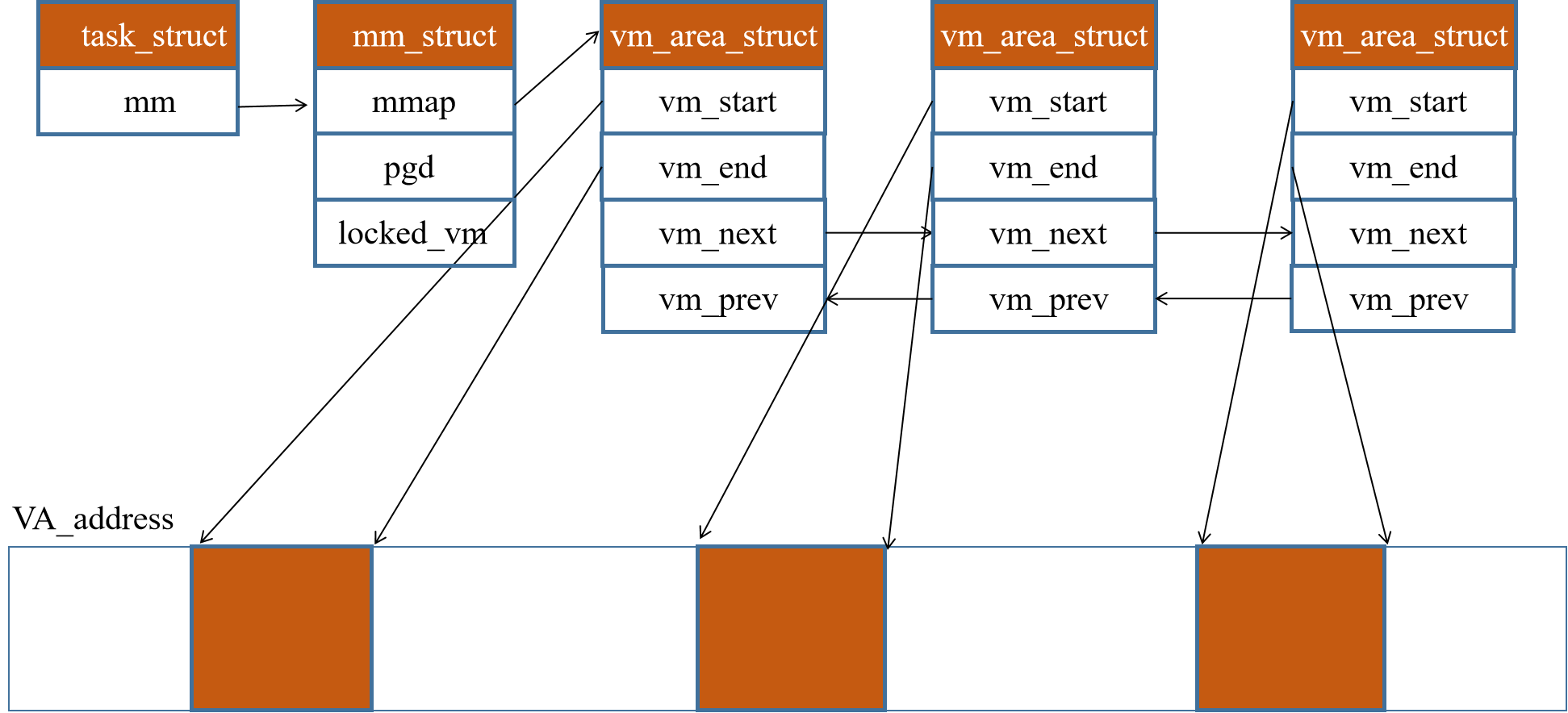
虚拟内存用到的数据结构如下所示,在进程的task_struct中mm_struct用于管理虚拟内存。
struct task_struct {
struct mm_struct *mm;
}
在mm_struct中,存有一个mmap指针和pgd指针,mmap指针指向vm_area_struct 结构体,而pgd指向第一级页表。
struct mm_struct {
struct {
struct vm_area_struct *mmap;
pgd_t * pgd;
unsigned long locked_vm;
} __randomize_layout
};
每一个vm_area_struct被组织成双向链表形式,vm_start指向VA的起始地址,vm_end指向VA的末尾地址。
struct vm_area_struct {
unsigned long vm_start;
unsigned long vm_end;
struct vm_area_struct *vm_next, *vm_prev;
} __randomize_layout;
数据结构之间的关系如下图所示。
(未完待续)
3.4.3 内存注册与pd(protection domain)
用户态调用如下API函数,进行内存注册,其要求传入ibv_pd pd与其关联。事实上,上述所有资源QP等,都需要在某个PD下创建,否则则会返回创建错误。
struct ib_mr *ibv_reg_mr(struct ibv_pd *pd, void *addr, size_t length, enum ibv_access_flags access)
pd则有下面这个函数调用创建,一台物理机至少需要一个pd0
struct ibv_pd *ibv_alloc_pd(struct ibv_context *context)
pd的作用类似于cgroup(我认为),使用pd来隔离不同资源,从而达到控制访问的权限。值得注意的是,内存注册仅仅只和pd关联,并不会和QP关联。
如下所示,QP1和QP3建立了连接。QP3是可以访问到MR0中数据,但如果QP3发出一个想要获取MR0数据的请求,这时会返回错误。因为QP1是在pd0下创建的资源,这个pair(QP1,MR0)才是合法请求。
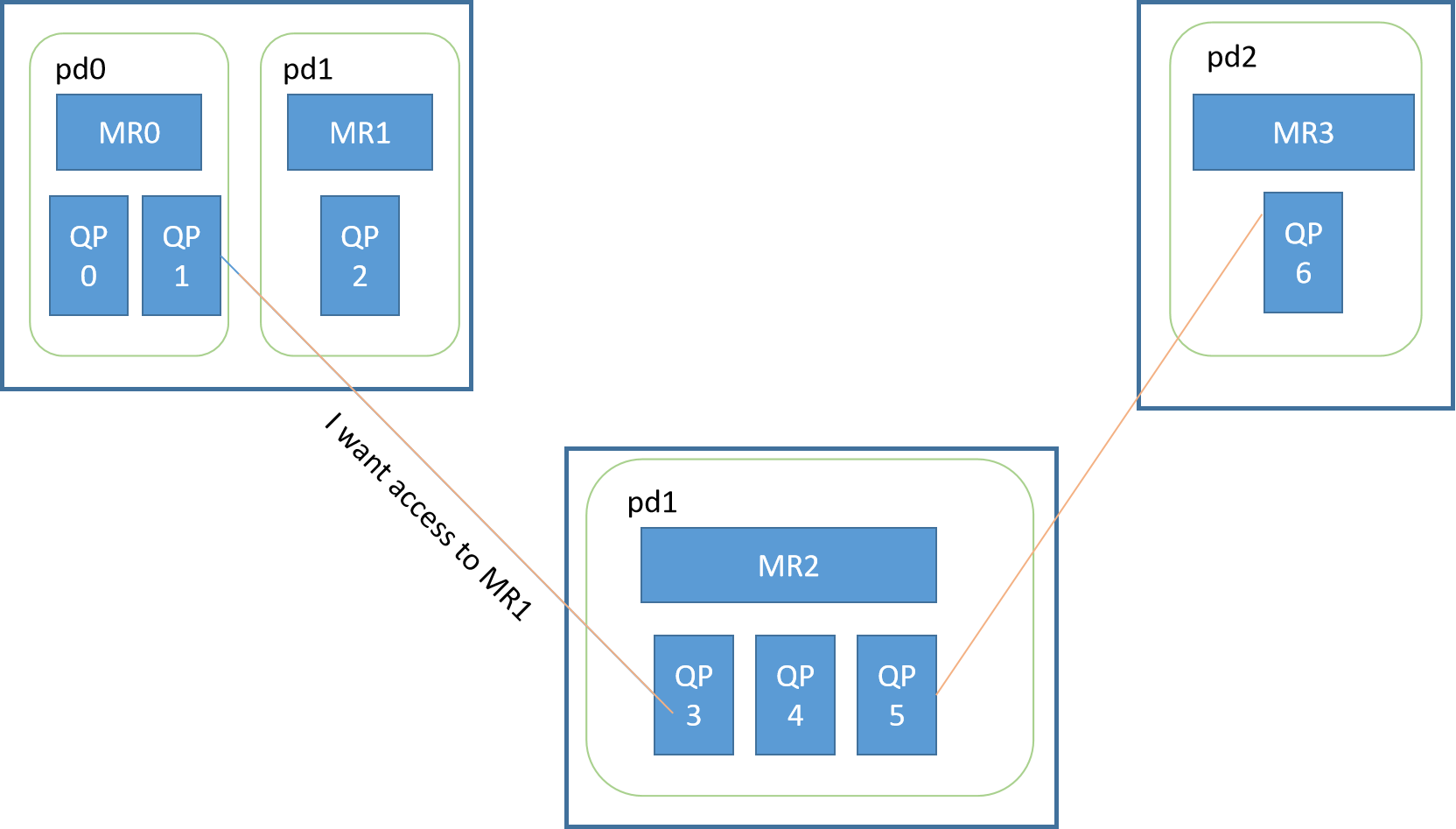
(图注修改,QP0,QP1为系统序号,用户创建QPN从2开始分配。)
MR对其他节点可见,PD只是本地概念
3.5 SRQ shared recviev queue
共享接收队列,如上文所述,RDMA通信的基本单位是QP,每个QP都由一个发送队列SQ和接收队列RQ组成。
共享接收队列人如其名,即两个不同的QP可以将他们的recv_cq指向同一个ib_cq,完成共享,这个公用的RQ就称为SRQ。当与其关联的QP想要下发接收WQE时,都填写到这个SRQ中。然后每当硬件接收到数据后,就根据SRQ中的下一个WQE的内容把数据存放到指定位置。
3.5.1 QP使用SRQ接收流程
创建SRQ
通过Post SRQ Recv接口,用户向SRQ中下发两个接收WQE,WQE中包含接收到数据后放到哪块内存区域的信息。
硬件收到数据。
硬件发现是发给QP3的,从SRQ1中取出第一个WQE1,根据WQE内容存放收到的数据。
硬件发现QP3的RQ关联的CQ是CQ3,所以向其中产生一个CQE。
用户从CQ3中取出CQE,从指定内存区域取走数据。
硬件收到数据。
硬件发现是发给QP2的,从SRQ1中取出第一个WQE2,根据WQE内容存放收到的数据。
硬件发现QP2的RQ关联的CQ是CQ3,所以向其中产生一个CQE。
用户从CQ3中取出CQE,从指定内存区域取走数据。
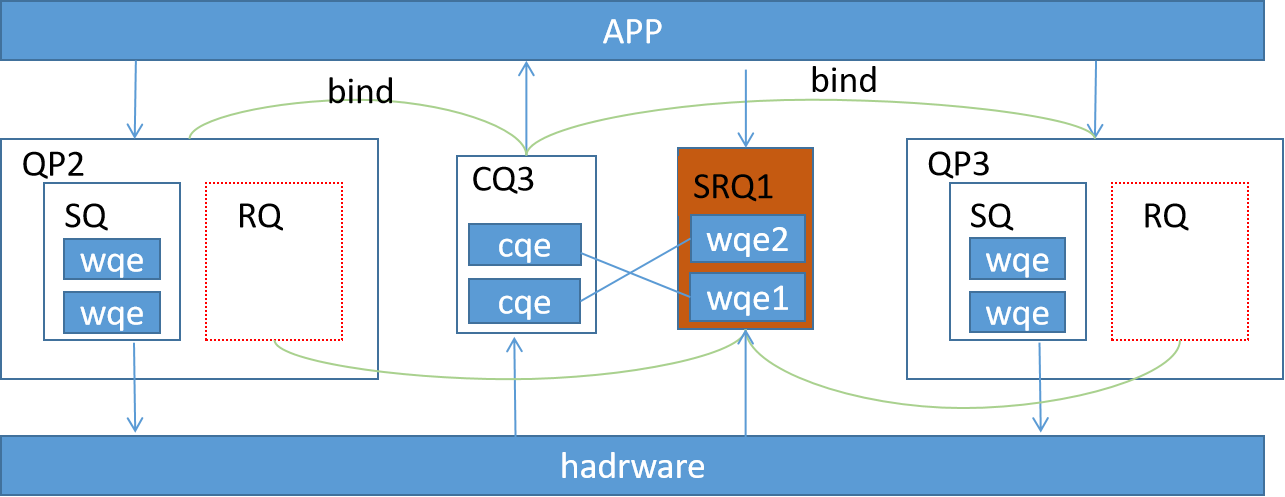
SRQ中的WQE使用wr_id来标记不同用户的信息。不同QP中的RQ可以关联到一个SRQ,不同QP也可以关联到同一个CQ
3.6 RDAM编程
main route
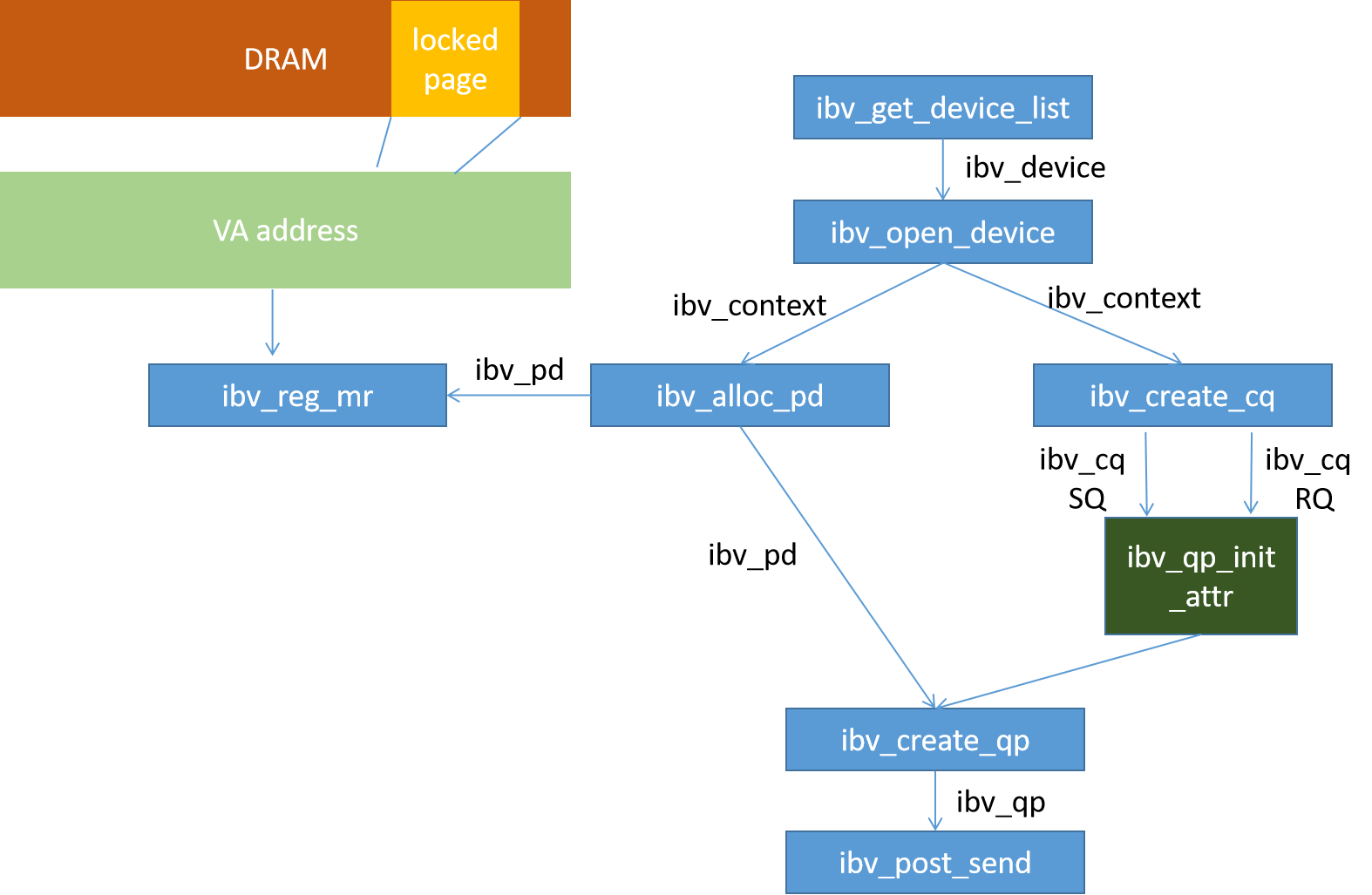
以ibv_post_send函数反推建立RDMA编程步骤。
int ibv_post_send(struct ibv_qp *qp, struct ibv_send_wr *wr, struct ibv_send_wr **bad_wr)
在调用该函数之前需要准备ibv_qp,该结构体由如下代码创建。创建qp,需要准备pd和qp_init_attr。
struct ibv_qp *ibv_create_qp(struct ibv_pd *pd, struct ibv_qp_init_attr *qp_init_attr)
ibv_pd这个结构体由下述代码创建,创建该函数需要传入ibv_context。
struct ibv_pd *ibv_alloc_pd(struct ibv_context *context)
ibv_context这个由ibv_open_device创建,该函数需要传入ibv_device
struct ibv_context *ibv_open_device(struct ibv_device *device)
ibv_device 由ibv_get_device_list这个函数返回一个ibv_device二维数组,至此,第一个函数从这里开始。
struct ibv_device **ibv_get_device_list(int *num_devices)
brach
内存注册用于绑定DRAM地址和pd
struct ibv_mr *ibv_reg_mr(struct ibv_pd *pd, void *addr, size_t length, enum ibv_access_flags
access)
在初始化qp时需要用到下面这个结构体,其中ibv_cq由ibv_create_cq创建。
struct ibv_qp_init_attr {
void *qp_context;
struct ibv_cq *send_cq;
struct ibv_cq *recv_cq;
struct ibv_srq *srq;
struct ibv_qp_cap cap;
enum ibv_qp_type qp_type;
int sq_sig_all;
struct ibv_xrc_domain *xrc_domain;
}
struct ibv_cq *ibv_create_cq(struct ibv_context *context, int cqe, void *cq_context, struct ibv_comp_channel *channel, int comp_vector)
RDMA编程步骤图
一个最大的不同点在于:整个流程中并没有将QP关联到CQ的操做,相反SQ和RQ其本身的实现就是一个CQ