遇见Doris:Doris on ES在快手商业化的最佳实践
作者:资深肥宅2021.09.06 11:21浏览量:629简介:业务场景分享
作者:贺祥 快手商业化团队数据架构高级工程师,主要负责商业化报表引擎
快手商业化报表引擎为外部广告主提供广告投放效果的实时多维分析报表在线查询服务,以及为商业化内部各系统提供多维分析报表查询服务。致力于解决多维分析报表场景的高性能、高并发、高稳定的查询问题。
1 业务场景介绍
1.1 服务介绍
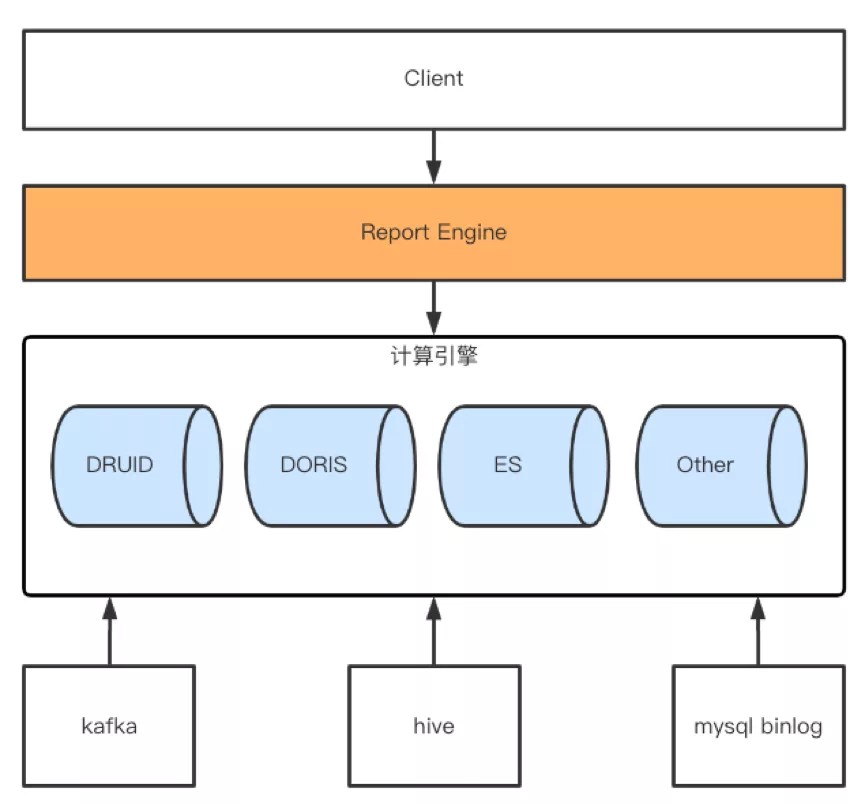
本文主要侧重介绍Doris on ES(DOE)在我们业务场景的实践,所以我们的数据架构在这里只做简单介绍,如上如图所示。
总体来说数据分为实时+离线两块事实数据写入,外加mysql binlong同步这一部分的维度数据写入。
实时主要是flink+kafka,离线部分基本各大公司都是统一解决方案-HIVE。数据最终导入计算引擎都是由各个引擎适配的工具或组件配合来完成的。如DRUID的KIS(kafka index service)+index_hadoop,Doris的routine load + broker load。这里就不一一详细展开了。
1.2 业务场景
业务场景主要为两大块——传统型的OLAP分析查询场景+星型模型join场景下的OLAP多维分析查询。
1.2.1 传统OLAP多维分析查询
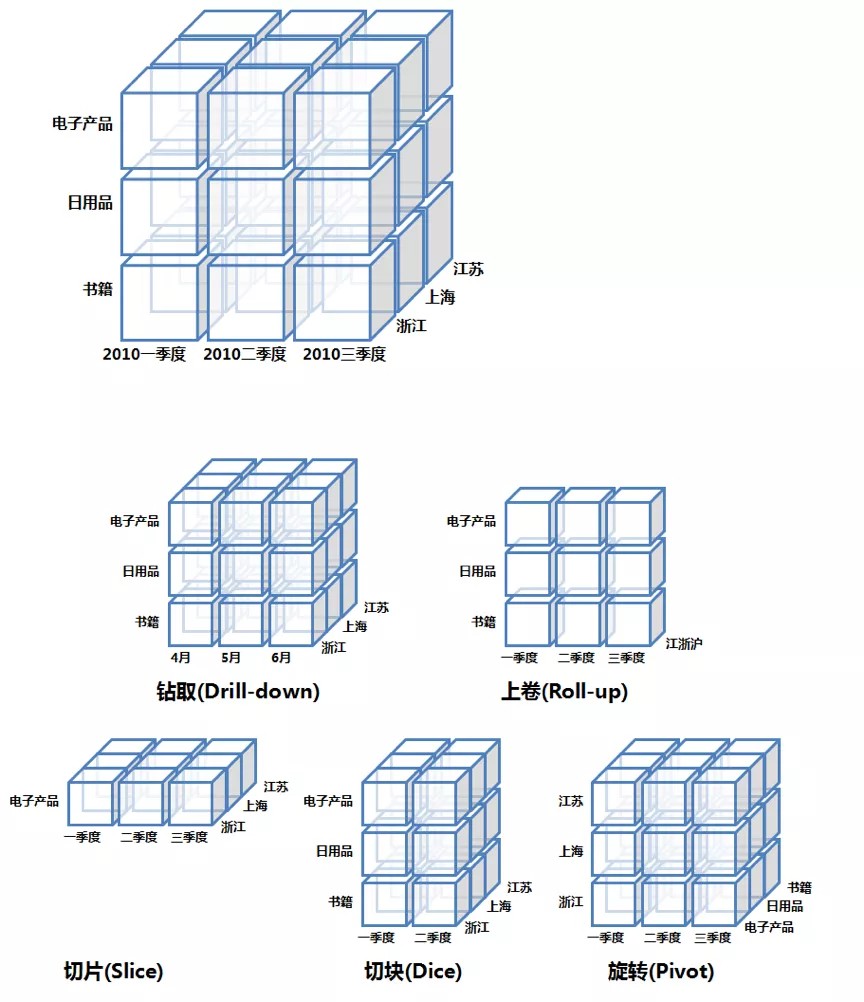
如上图,传统OLAP多维分析查询基本上是对事实数据(fact table)的下钻、上卷、切片、切块、旋转操作。
参考blog:
https://blog.csdn.net/xwc35047/article/details/86369465
1.2.1 星型模型join场景下的OLAP多维分析查询
星型模型Join场景下的OLAP多维分析查询与传统OLAP多维分析的区分主要是引入了维度数据(dim table)Join。
用SQL表达如下:
select
f.key_1,
f.key_2,
d.key_3,
d.key_4,
AGGR_FUNC(f.value_1),
AGGR_FUNC(f.value_2)
from
f left join d on d.key = f.key_1 -- 维度表必须具有主键,与事实表进行关联
where
f.dt in (xxx) and
f.key_xx in (xxx) and
d.col_2 in (xxx) and -- 可以基于维度表的col做filter
d.key_3 match('xxx') -- match在这里表达的含义是分词模糊匹配场景
group by
f.key_1,
f.key_2,
d.key_3,
d.key_4
order by
AGGR_FUNC(f.value_1) DESC
having AGGR_FUNC(f.value_2) > xxx
limit N
维度数据主要有两大用处:
1.过滤筛选
2.填充其他维度信息,如name等。
这里解释一下为何我们不能做成大宽表模式。通常来说,针对类似场景通用解决方案一般有两种:
大宽表,数据以尽可能全的维度,先join好再写入引擎
星型模型关联查询,查询的时候才去做关联join
对于以上两种方案各有什么优劣势呢?
大宽表,空间换时间。理论上都是维表主键为唯一ID来填充所有维度,这样只是冗余存储了多条维度数据,但是在OLAP引擎里,不管是DRUID、KYLIN还是DORIS都不会造成数据量的基数膨胀。优势:应用层查询的时候非常方便,无需关联额外的维表,直接面向大而全的宽表查询。劣势:对应的弊端就是如果有维度数据update场景,支持的代价非常大。如果update非常频繁,这种方式就不可行了。
星型模型关联查询。优势:维度数据与事实数据完全分离,维度数据用专门的引擎存储(如mysql、elasticsearch等等),可以支持高频update操作,查询时通过主键关联查询维度数据。劣势:查询层逻辑相对复杂,且多表join会导致性能受损。
1.3 业务挑战
超大数据量:单表原始数据每天增量百亿
查询高QPS:平均QPS千级别
高稳定性要求:在线服务要求稳定性4个9
星型模型中,维表需要支持高频的UPDATE操作(update qps约1千),且维表需要支持模糊匹配、分词检索
2 架构实现
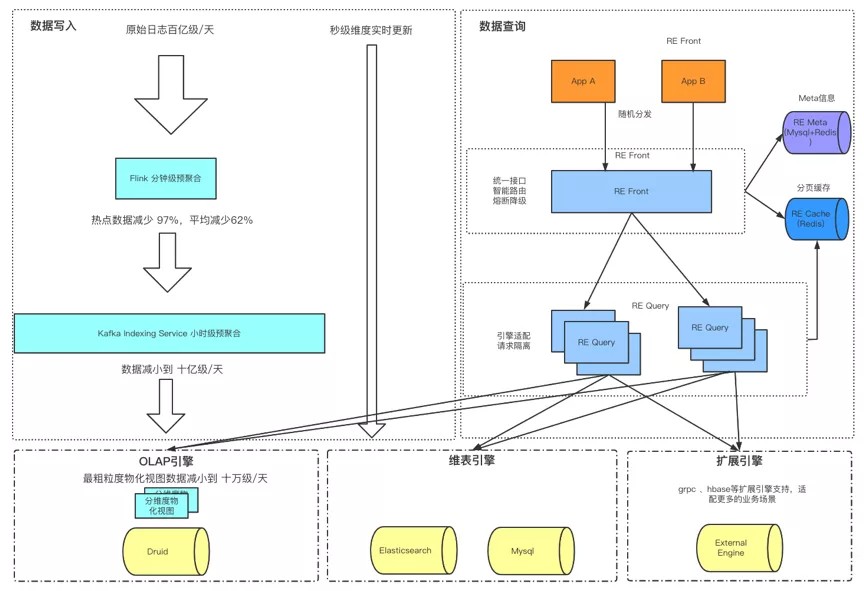
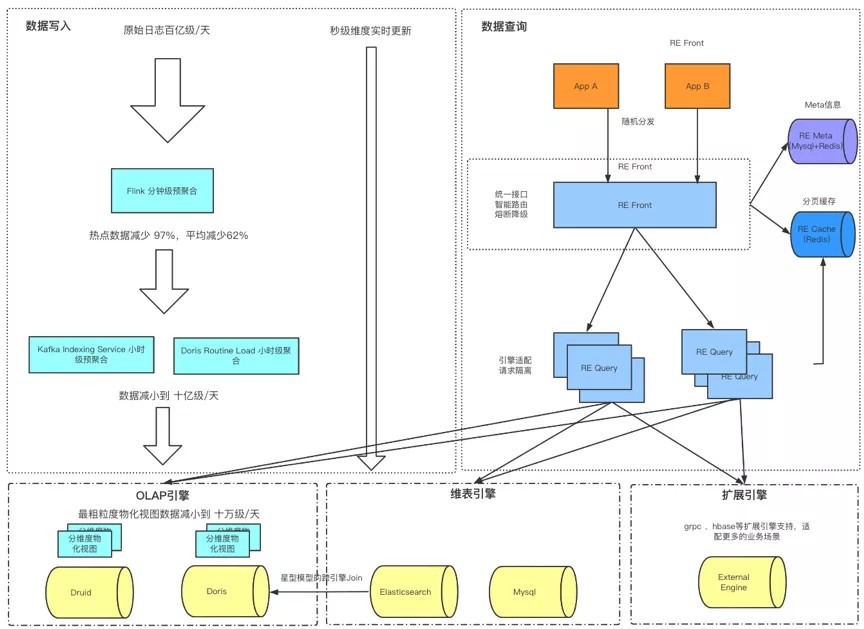
2.1 数据生产
2.1.1 事实数据
如上图,数据写入部分:实时数据通过Flink处理,再写入Kafka。最后通过Kafka Index Service摄入到Druid。
事实数据一般量级是非常大的,在我们的场景下,实时数据量比较大,为了减少下游KIS的压力,我们在Flink层加了一层窗口聚合。并且对最终写入kafka的数据进行了KeyBy处理,将相同维度相同取值的数据都发送到同一个topic partion。
做KeyBy操作的核心目的是为了适配Druid引擎的特性。如果以随机的方式发往kafka topic的各个partion,会导致每个partion都可能涵盖所有取值的数据。进而导致每个KIS task包含了所有取值的数据(我们生成环境KIS task数目与topic的partion数是一一对应的),造成KIS task的segment文件大幅膨胀(两种区别的理论值为key By处理生成的segment大小为不做key by的 1/partion总数),影响实时数据的查询性能(这里如果没太看明白可以参考阅读Druid官方文档,了解Druid数据聚合、索引构建原理)。
注意:Key By操作可能会导致引发数据热点,可以通过热点数据动态加盐解决。
2.1.2 维度数据
为什么选用ES做维度数据存储引擎?
维表数据量级较高,Mysql存储需要做分库分表支持,但是性能无法满足需求
更新频率较高,update QPS约1000
业务侧需要支持分词模糊检索
综合以上几点,Elasticsearch(ES)引擎能够非常好的解决上述问题。
ES拥有强大的分词检索能力,支持较高频率的update操作,和很好的横向扩展能力。其他如Hbase、Redis等都不能满足上述需求。
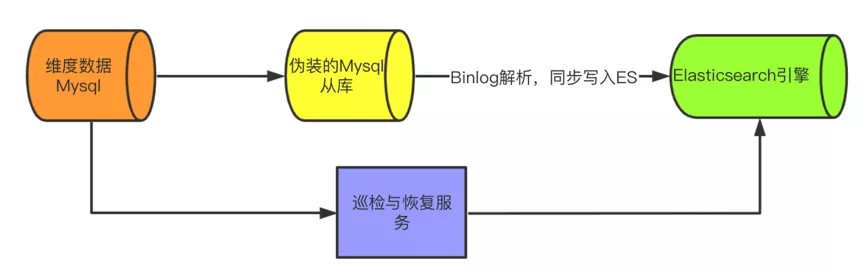
数据同步ES过程:
如上图所示,维度数据原本存储在Mysql引擎,通过伪装的Mysql从库来监听binlog,将维度数据同步到ES。并且有一个检查与恢复的服务做数据同步监控,支持按时间增量check、全量check、增量回刷、全量回刷等操作。
2.2 报表引擎
报表引擎架构实现整体分为REFront 和 REQuery两层,REMeta为独立的元数据管理模块。
REFront
REFront 为统一的查询入口层,特点是轻量级、高可用。
核心职能为:查询标记、业务逻辑处理、查询分发、流控、熔断降级。REQuery
REQuery 为查询执行层,分组部署,为不同的业务场景提供物理隔离。
核心职能为:多引擎适配、多集群路由调度、查询优化、MEM Join、结果分页cache等。
报表引擎通过抽象,在REQuery内部实现MEM Join。支持Druid引擎中的事实数据与ES引擎中的维度数据做关联查询。为上层业务提供虚拟的cube表查询。屏蔽复杂的跨引擎管理查询逻辑。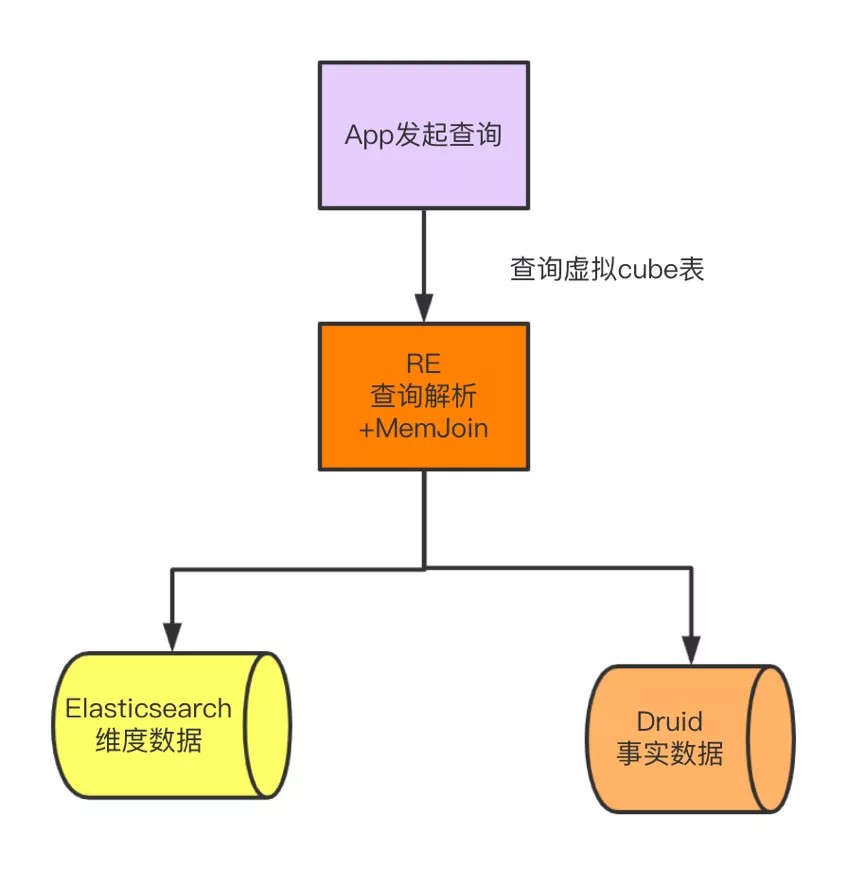
3 基于Doris on ES的架构实现
3.1 Mem Join架构遗留的核心问题
Mem Join是单机实现与串行执行,到单次从ES中拉取的数据量超过10W时,响应时间已经接近10s,大户体验差。而且单节点实现大规模数据Join处理,内存消耗大,有Full GC风险。
3.2 Doris+Doris on ES完美配合
上文提到,OLAP分析场景,经常会遇到一个大难题:针对需要关联维度查询的场景,究竟是做成大宽表还是查询时Join?
总结来说,如果要支持维度数据存储,并且支持Join,目前开源的各类引擎或多或少都存在一些局限性。Druid的lookup Join实现太弱了,真实业务场景如果基本上很难适用。Doris和Clickhouse这里引擎都支持Join,并且支持明细数据存储,但是如要要高频Update,也是没办法做到。如果跳出Olap引擎,在应用层做Join实现,也是一种解法,但是实现成本高。
直到遇见了Doris on ES!
Doris on ES 查询性能如何?
Doris引擎为MPP架构,本身就具备很强的性能及横向扩展能力。Doris on ES构建在这个能力之上,并且对查询做了大量的优化,这给对ES原理理解不深的同学带来了方便。
主要的优化点如下:
Shard级别并发
行列扫描自动适配,优先列式扫描
顺序读取,提前终止
两阶段查询变为一阶段查询
Join场景使用Broadcast Join,对于小批量数据Join特别友好
不太完善的地方:
目前Doris on ES还不支持聚合下推,但是对于我们维度数据查询场景其实是用不到聚合操作。需要用到聚合操作的场景需要注意一下。不过目前社区也正在开发支持。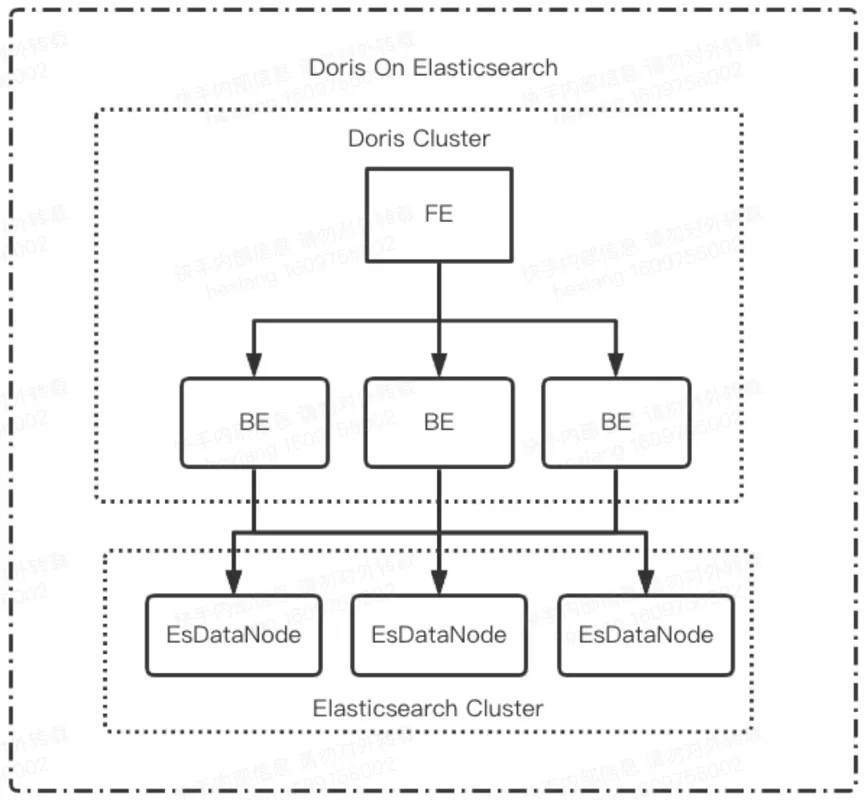
3.3 基于DOE的架构实现
3.3.1 数据链路升级
数据链路升级适配比较简单
Doris构建新的Olap表,配置好物化视图。
实时导入基于之前事实数据的kafka topic启动routine load。
离线校准通过broker load从hive中导入。
Doris创建on ES外表(社区正在开发自动同步建表)
3.4.1 贡献
动态分区小时支持: https://github.com/apache/incubator-doris/pull/4514
DOE解决查询路由异常: https://github.com/apache/incubator-doris/pull/4352
multi fields在多text类型情况下空指针异常:https://github.com/apache/incubator-doris/pull/4300
3.4.2 Tips
routine load参数问题,主要关注desired_concurrent_number并发数,max_batch_interval,max_batch_rows,max_batch_size,目的是增大单次导入的数据量,提高导入性能
compact参数问题,主要调整cumulative_compaction_num_threads_per_disk、base_compaction_num_threads_per_disk、min_compaction_failure_interval_sec并且在代码中对因为没拿到锁的异常进行过滤,目的是提高compact频率,加快compact速度,减少小文件的产生
高并发下的所有fe hang死问题,主要调整fragment_pool_thread_num_max, fragment_pool_thread_num_min,fragment_pool_queue_size,过小的fragment_pool_thread会导致fragment死锁
提高高并发查询性能,高并发下需要降低每个查询的资源使用,主要降低doris_scanner_queue_size、doris_scanner_thread_pool_thread_num,避免创建过多scanner线程
3.4.3 报表引擎适配升级
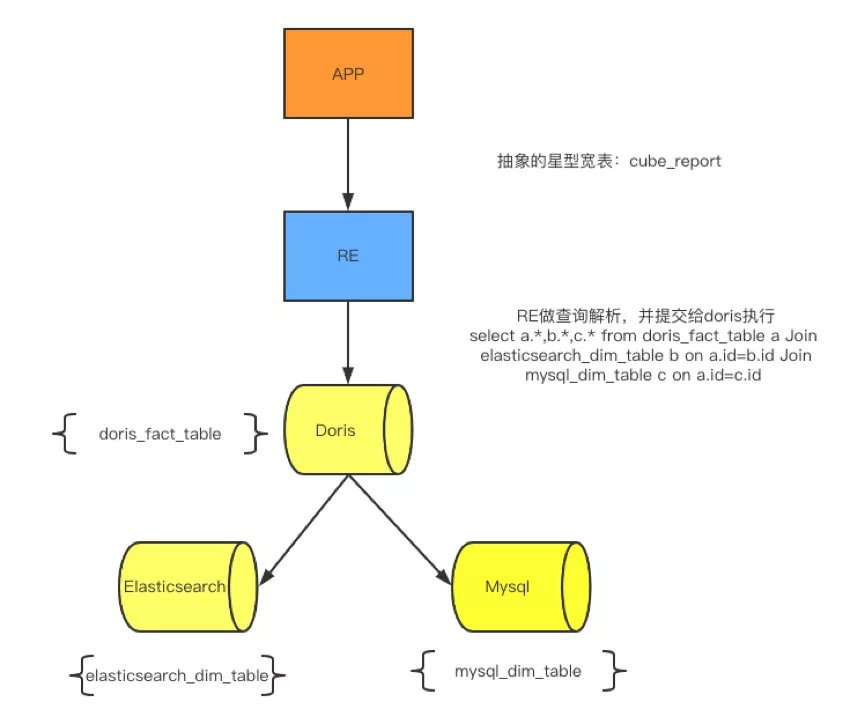
注:上图关联的mysql维表是基于未来规划,目前主要是ES做维表引擎
报表引擎适配
- 抽象基于Doris的星型模型虚拟cube表
- 适配cube表查询解析,智能下推
- 支持灰度上线
4 线上表现
4.1 查询响应时间
4.1.1 事实表查询表现对比
Druid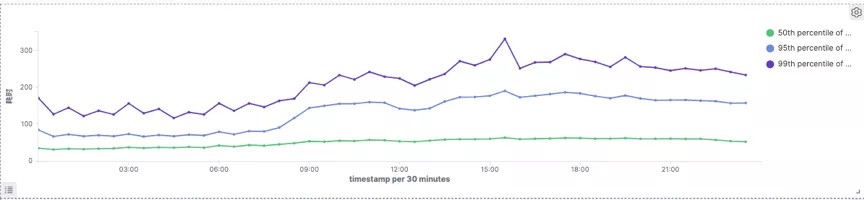
Doris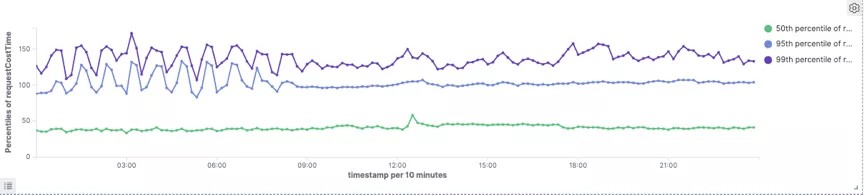
99分位耗时Druid大概为270ms,Doris为150ms,延时下降45%
4.1.2 Join场景下cube表查询表现对比
Druid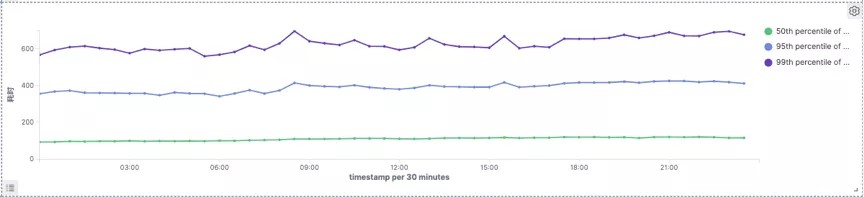
Doris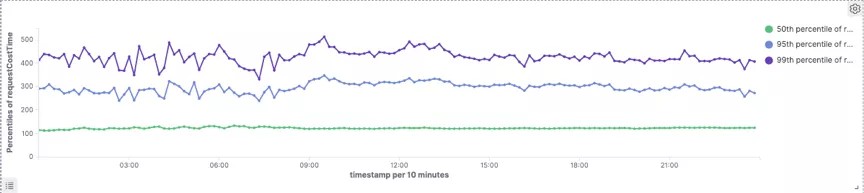
99分位耗时Druid大概为660ms,Doris为440ms,延时下降33%
4.1 收益总结
- 整体p99耗时下降35%左右
- 资源节省50%左右
- 去除报表引擎内部Mem Join的复杂逻辑,下沉至Doris通过DOE实现,在大查询场景下(维表结果超过10W,性能提升超过10倍,10s->1s)
- 更丰富的查询语义(原本Mem Join实现比较简单,不支持复杂的查询)
5 总结与未来规划
从测试和线上的表现来看,Doris引擎的表现还是非常优秀的。
多维分析聚合查询场景对比Druid引擎有很大的性能优势,再加上Doris on ES的加持和上层业务的抽象,可以即拥有ES引擎强大的分词检索能力,又不失Olap场景海量数据的聚合分析性能。两者的结合可以为这类需求提供全新的解决方案与思路。
在快手商业化业务场景里面,维度数据与事实数据Join查询是非常普遍的,有了比较不错的实践成果,后续会在Doris on ES解决方案上继续投入。
致谢
感谢百度智能云 Doris团队对我们的大力支持,在我们使用过程中遇到的问题都非常及时的协助我们排查定位。同时也祝愿 Apache Doris 社区越来越活跃,吸引更多的同学一起参与共建!