认识一下ceph
作者:皮皮的皮2021.07.05 20:18浏览量:791简介: DAS的全称是Direct Attached Storage(直接附加存储)
浅谈ceph(nautilus版本)
1.前言
之前有简单了解了一下ceph,刚好小组有个ceph大佬,我就趁着周六日多学学ceph这块内容,我司目前用的是N版,我就看N版的了。看看有啥可以请教大佬的,我感觉在ceph这块玩得熟的人都yyds。害,菜鸡开启学习之路!!!
2.存储分类
DAS
DAS的全称是Direct Attached Storage(直接附加存储),早期的时候服务器的计算能力是有限的,存储插槽也是相对有限的,随着业务空间不断增长的时候,本地的存储空间可能就不够用了,早期的时候都是服务器直接采用SCSI或者FC协议连接到存储阵列,在操作系统当中的表现形式:一块钱空间大小的磁盘,如 /dev/sdb。
「DAS的优点:」
- 组网简单,成本低
「DAS的缺点:」
- 可扩展性差、不灵活、无法多机共享
NAS
NAS的全称是Network Attached Storage(网络附加存储),NAS的组网方式跟DAS的区别比较大,NAS是借助TCP网络协议连接至文件共享存储,NAS主要是通过NFS或者CIFS协议共享出来,客户端通过TCP协议就可以访问了,在操作系统当中的表现形式:映射到存储当中的一个目录,如/data
「优点:」
- 造价低,随便一台机器就可以了
- 方便文件共享
- 使用简单、通过IP协议实现互相访问、多机同享同个存储
「缺点:」
- 读写速率低
- 传输速率慢
- 可靠性不高
「使用场景:」
SAN
SAN的全称是Storage Area Network(存储区域网络),SAN的组网方式是通过使用一个存储区域网络IP或者FC连接到存储阵列,协议类型是:IP-SAN、FC-SAN;在操作系统当中的表现形式:一块空间大小的裸磁盘,如/dev/sdb。
「优点:」
- 通过Raid与LVM等手段,对数据提供了保护
- 多块廉价的硬盘组合起来,提高容量
- 多块磁盘组合出来的逻辑盘,提升读写效率
「缺点:」
- 采用SAN架构组网时,光纤交换机,造价成本高 (FC-SAN,需要HBA卡、FC交换机、FC存储;(IP-SAN的话成本相对低一些,使用的是以太网交换机,但是性能也会下降))
- 主机之间无法共享数据
「使用场景:」
- docker容器、虚拟机磁盘存储分配
- 日志存储
- 文件存储
Object Storage
Object Storage(对象存储),组网方式是通过网络使用API的形式访问一个无限扩展的分布式存储系统,Object Storage的协议类型:兼容AWS S3的风格、原生的PUT和GET类型;在操作系统当中的表现形式:通过GET跟PUT无限下载和上传文件
「优点:」
- 具备块存储的读写高速。
- 具备文件存储的共享等特性。
「缺点:」
- 只使用静态不可更改的文件、无法为服务器提供块存储
「使用场景:」 (适合更新变动较少的数据)
- 图片存储。
- 视频存储。
「产品举例:」
HDFS、FastDFS、swift;公有云主要有:AWS S3、腾讯云COS、阿里云OSS
3.ceph介绍

ceph是一个统一存储,ceph可以提供三种存储:对象、块、文件存储;ceph有着高可用、容易管理、免费使用的特点;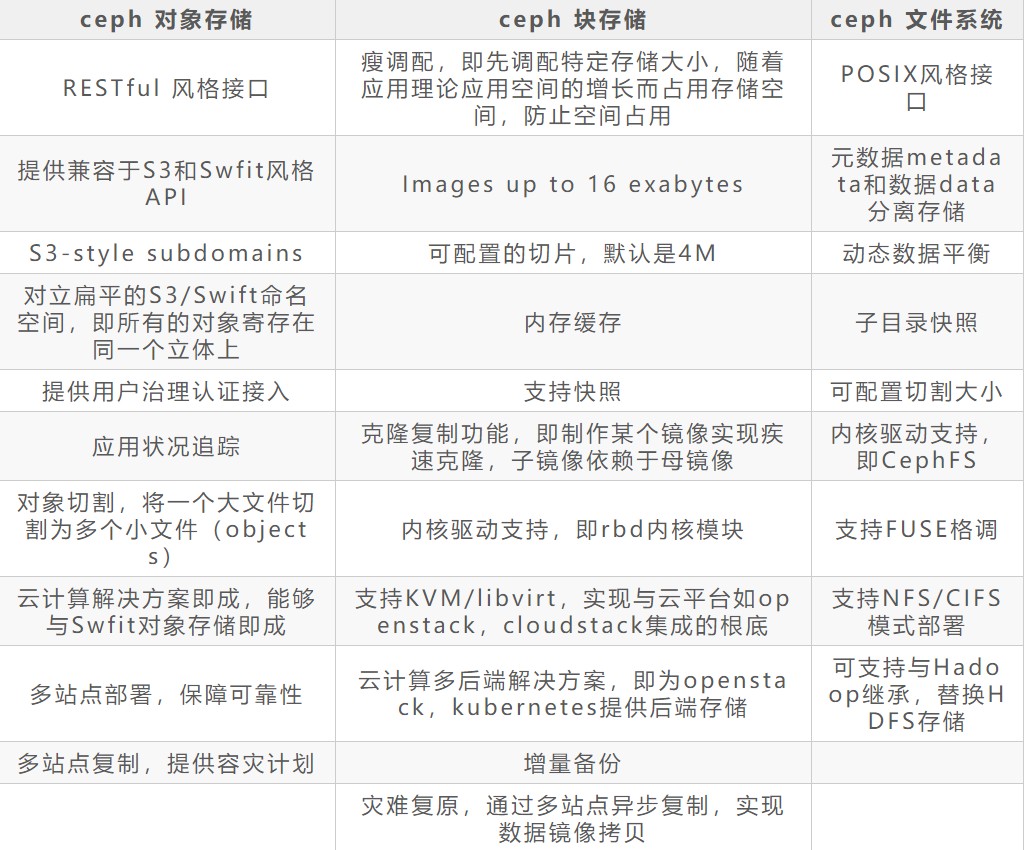
Ceph提供了三种存储接口:块存储RBD,对象存储RGW和文件存储CephFS,每种存储都有其相应的性能和个性
4.ceph的组件结构
Ceph 存储由几个不同的守护进程组成,这些守护进程彼此之间是相互独立的,每一个组件提供特定的功能。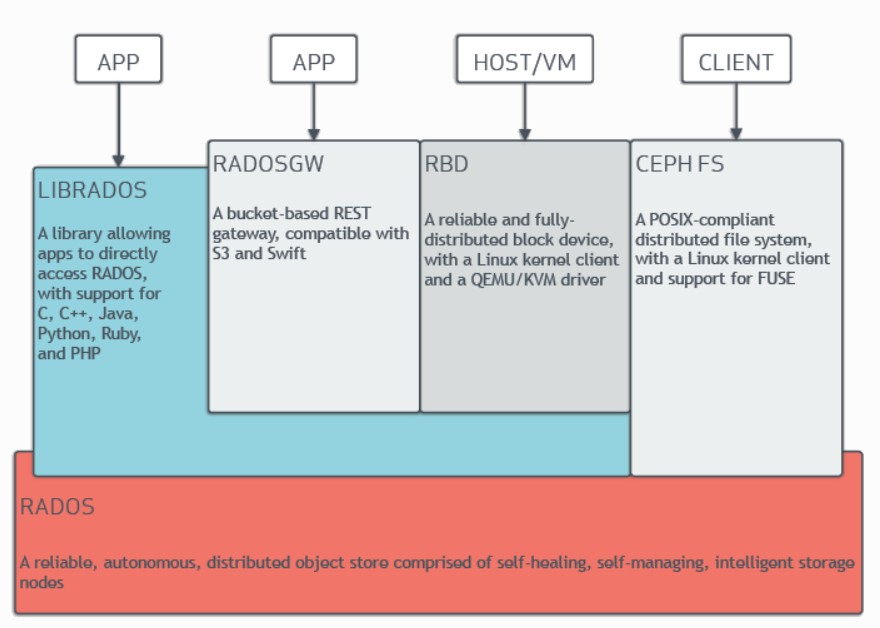
Ceph核心组件
- 「RADOS(Reliable Autonomic Distributed Object Store 可靠、自动,分布式对象存储)」 是ceph存储组件的基础。ceph 将一切都以对象的方式存储,RADOS就负责存储这些对象,而不考虑他们的数据类型。RADOS层组件确保数据的一致性,和可靠性。包括数据的复制,故障检测和恢复,数据在节点之间的迁移和再平衡。RADOS由大量的存储设备和节点集群组成。RADOS采用C++开发。
- 「LIBRADOS(基础库,又叫做RADOS库)」 主要功能是对RADOS进行抽象和封装,并向上提供API,以便直接基于RADOS进行应用开发。RADOS是一个对象存储系统,LIBRADOS实现的是API是针对对象存储的功能。支持C,C++, Java, Python, Ruby 和PHP。同时,LIBRADOS还是RBD,RGW等服务的基础。
- 「RADOSGW(CEPH对象网关,也叫做RADOS网关RGW)」 它提供了S3和Swift兼容的RESTful API的网关,支持多租户和openstack的身份验证。相对于LIBRADOS它提供的API抽象层次更高,能在使用类S3和Swift场景下进行更加便捷的管理。
- 「RDB(Reliable Block Device)」 提供了一个标准的块设备接口,对外提供块存储,它可以被映射,格式化,像其他磁盘一样挂载到服务器。常用于虚拟化场景下创建volume,云硬盘等。目前red Hat已经将RBD的驱动集成到KVM/QEMU中。
- 「CephFS (Ceph 文件系统)」 是一个兼容POSIX的分布式文件系统。它使用MDS作为守护进程。libcephfs拥有本地Linux内核驱动程序支持,可以使用mount命令进行挂载操作。能与支持CIFS和SMB协议。
- 「Ceph RADOS」RADOS是ceph 存储系统的核心,也称为ceph存储集群。ceph的所有优秀的特性都是由RADOS提供的,包括分布式对象存储,高可用性,自我修复和自我管理等。
4.RADOS

RADOS 包含两个核心组件:Ceph Monitor 和Ceph OSD。
Ceph Monitor
Ceph Monitor 是负责监视整个集群的运行状态的, 为了实现高可用性,通常配置为一个小型的集群(一般是3个节点,集群通常是有一个leader和两个slave,当leader故障后集群通过选举产生新的leader,来保障系统的高可用性。)
Ceph OSD
OSD是Ceph 存储的重要组件。OSD将数据以对象的方式存储到集群中各个节点的磁盘上,完成数据存储的绝大部分工作是由OSD 守护进程来实现的。
Ceph 集群中通常包含有多个OSD,对于任何读写操作,客户端从Ceph Monitor获取Cluster Map之后,客户端将直接与OSD进行I/O操作,而不再需要Monitor干预。这使得数据读写过程更加迅速,不需要其他额外层级的数据处理来增加开销。
OSD通常有多个相同的副本,每个数据对象都有一个主副本和若干个从副本,这些副本默认情况下分布在不同的节点上,当主副本出现故障时(磁盘故障或者节点故障),Ceph OSD Deamon 会选取一个从副本提升为主副本,同时,会产生以一个新的副本,这样就保证了数据的可靠性。
[注]ceph使用的Cluster来实现数据分布算法
Ceph Monitor集群状态保证
Monitor中的信息都是集群成员中的守护程序来提供的,包含了各个节点之间的状态,集群的配置信息。主要用于管理Cluster Map,Cluster Map是整个RADOS系统的关键数据结构,类似元数据信息。Monitor中的Cluster Map 包含五个,分别是:「The Monitor Map」、「The OSD Map」、「The PG Map」、「The CRUSH Map」和「The MDS Map」
- 「mon Map:」 记录了mon集群的信息和集群的ID. 命令ceph mon dump
- 「OSD Map:」 记录了osd集群的信息和集群的ID. 命令ceph osd dump
- 「PG Map:」 pg的全称是placement group,中文译为放置组,是用于存放object的一个载体,pg的创建是在创建ceph存储池的时候指定的,同时跟指定的副本数也有关系,比如是3副本的则会有3个相同的pg存在于3个不同的osd上,pg其实在osd的存在形式就是一个目录,pg作为存储单元,pg的使用情况也反应了当前集群的存储状态。在集群中,PG有多种状态,不同的状态反应了集群当前的健康状态。命令 ceph pg dump
- 「CRUSH Map:」 包含集群存储设备的信息,故障层次结构和存储数据是定义失败域规则信息。命令 ceph osd crush dump
- 「MDS map:」 只有在使用Ceph FS时才会使用MDS,MDS是Ceph FS的元数据服务。集群中至少需要一个MDS的服务。
5.ceph的数据写入流程
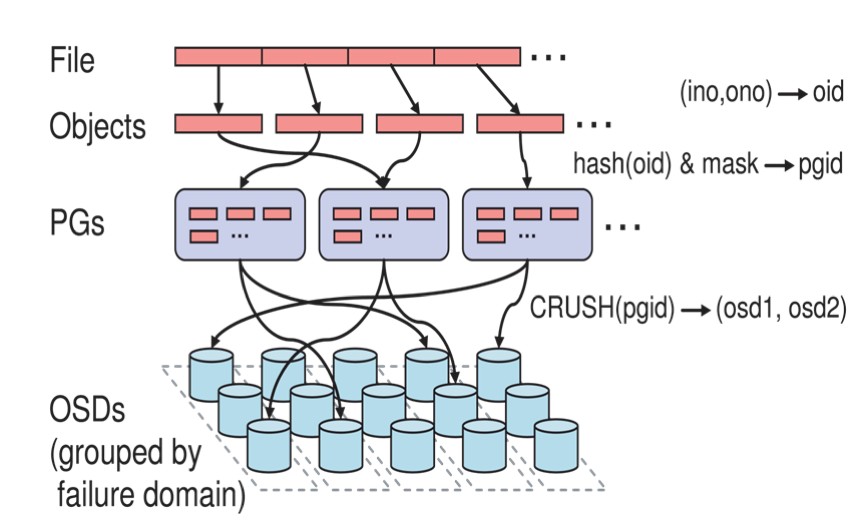
File => Obejct
用户操作的是File,但是对于ceph来说,存储的是Object,所以需要将File映射为Object,这个映射过程比较简单:本质上就是按照object的最大size对file进行切分,相当于RAID中的条带化过程。这种切分的好处有二:一是让大小不限的file变成大小一直的size(默认的切割大小是4兆),可以被RADOS高效管理的object;二是让对单一file实施的串行处理变为对多个object实施的并行化处理。
每一个切分后产生的object将获得唯一的oid,即object id。其产生方式也是线性映射,极其简单。图中,ino是待操作file的元数据,可以简单理解为该file的唯一id。ono则是由该file切分产生的某个object的序号。而oid就是将这个序号简单连缀在该file id之后得到的。举例而言,如果一个id为filename的file被切分成了三个object,则其object序号依次为0、1和2,而最终得到的oid就依次为filename0、filename1和filename2。
Object => PG
在file被映射为一个或多个object之后,就需要将每个object独立地映射到一个PG中去。
映射的计算公式为:hash(oid) & mask -> pgid
计算分为两步:首先是使用Ceph系统指定的一个静态哈希函数计算oid的哈希值,将oid映射成为一个近似均匀分布的伪随机值。然后,将这个伪随机值和mask按位相与,得到最终的PG序号(pgid)。mask的值是PG的总数-1;
ps:可以理解PG就是Object的目录
PG => OSD
PG到OSD的映射其实就是将作为object的逻辑组织单元的PG映射到数据的实际存储单元OSD。如图所示,RADOS采用一个名为CRUSH
的算法,将pgid代入其中,然后得到一组共n个OSD。这n个OSD即共同负责存储和维护一个PG中的所有object。前已述及,n的数值可以
根据实际应用中对于可靠性的需求而配置,在生产环境下通常为3(一般都是为奇数个)。具体到每个OSD,则由其上运行的OSD deamon负责执行映射到本地
的object在本地文件系统中的存储、访问、元数据维护等操作。
CRUSH算法的结果不是绝对不变的,而是受到其他因素的影响。其影响因素主要有:当前系统状态、存储策略配置