SquirREL :基于深度强化学习对区块链激励机制进行自动化攻击分析
作者:小门神2021.06.23 10:02浏览量:803简介:基于深度强化学习对区块链激励机制进行自动化攻击分析
论文标题: SquirRL: Automating Attack Analysis on Blockchain Incentive Mechanisms with Deep Reinforcement Learning
论文作者: Charlie Hou; Mingxun Zhou;
发表会议: NDSS 2021
论文地址: https://arxiv.org/pdf/1912.01798.pdf
激励机制是无许可区块链的核心,它可以激励参与者参与以保证共识协议的安全,然而设计激励机制是非常困难的。即使是在传统背景下具有强大理论安全保障的系统,用户也要么是拜占庭式要么是诚实的,缺少对理性用户的分析。而理性用户会利用激励去偏离诚实行为,因此,大多数今天的公链使用激励机制的安全性缺乏深入分析且未经测试。
本文提出了SquirRL,它使用深度强化学习去识别区块链激励机制下的攻击策略,使用较短步骤,方法在BitCoin协议上复现了其著名的理论结果。另外,在更复杂的场景下,即当矿工的挖矿算力随时间改变的场景,SquirRL也比目前其他论文更好的识别攻击策略。最后,SquirRL发现针对比特币的传统自私挖矿攻击在多个攻击者场景下是无效的。这些结果阐明了为什么迄今为止在网络里还未发现的自私挖掘可能是一种糟糕的攻击策略。
Introduction
区块链在过去的数十年内以去中心化信任的特性存储和处理数据的能力让人兴奋。区块链计算模型需要参与者消耗资源(存储资源,计算资源,电力资源)去确保其他用户数据的正确性。这些代价是巨大的,因此大多数公链依赖于激励机制去刺激用户参与区块链共识协议。公共区块链里激励机制是非常重要的。用户通常会被奖励因为参与维护彼此的数据。一个例子就是Bitcoin的共识协议,它需要参与者(矿工)建立连续的数据去看,每个区块都需要完成巨大的计算代价后才能形成。为了激励用户,在自己挖的区块获得网络的认可后,Bitcoin矿工会收到奖励。矿工也会因为打包到区块的交易收到交易费。这样做是为了防止矿工的区块没有被认可的情况下自己白白消耗了资源而没有获得奖励。这样的整个奖励机制极大地增加了BitCoin的参与用户数目。无许可区块链系统里一般都有自己的一套激励机制,虽然大多数模仿Bitcoin,但是因为共识协议的不同,其激励机制还是有所差异。
A. 针对激励机制的攻击
激励机制很容易受到攻击者博弈的影响,self mining是一个针对Bitcoin激励机制的著名攻击手段,它允许一个矿工通过不完全遵循共识协议来获得超过它在正常情况下获得的区块奖励。目前,对区块链激励机制的攻击通常是通过漫长的建模和理论分析过程发现的,在这个领域里获得一个大家都能接受的结果是很困难的。由于许多加密货币缺乏基本分析,所以绝大多数区块链激励机制根本没有被分析过。因此,目前存在于加密货币中的大量资金可能容易受到未知攻击。
B. SquirRL框架
在本文里,我们提出了名为SquirRL的方法,它可被区块链开发者用作测试激励机制漏洞。但是它不提供理论上的保证:他不能发现攻击并不代表诚实行为是主导的策略。我们在实际中发现,方法在识别对手策略上是有效的,这只能证明激励机制是不安全的。我们的贡献有三点:
1)框架的提出:涉及了模拟环境的创建,即定义agent的状态和动作空间。攻击模型的选择,包括了不同种类和数目agent。一个合适的RL算法和奖励函数的选择。在我们的评估过程中,我们将展示如何灵活地使用这个框架来处理涉及不同环境、不同agent数量、奖励等场景。
2)Selfish-mining评估:将SquirRL应用于不同的区块链协议里,使用它我们能够在Bitcoin协议中复现已有的理论自私挖掘结果,同时也将最先进的结果扩展到以前难以处理的领域(更大的动作空间,多agent场景,不同的协议)。我们的研究结果表明,在Bitcoin协议中,随着agent数量的增加,自私挖矿及其变体的利润逐渐减少。此外本文考虑了更大的策略空间,在多agent场景下进行了实验。
3)拓展性:方法不仅仅针对self mining,也对其他论文提出的withholding attack进行了测试。我们发现了SquirRL发现了可收敛于纳什均衡的两个参与者策略。
Motivation
目前,发现区块链激励机制攻击仍然是手动且极其耗时的。针对这些系统的博弈分析是很困难的,因为博弈是重复的,有多个参与方且状态空间巨大。事实上,现有的很多分析都集中在只有一两个不诚实挖矿的agent的场景上。
A. Use Case
我们想让协议设计者使用我们的框架去研究攻击模型和实验的自然过渡以解决激励机制的关键安全和激励一致性问题,如下表所示。
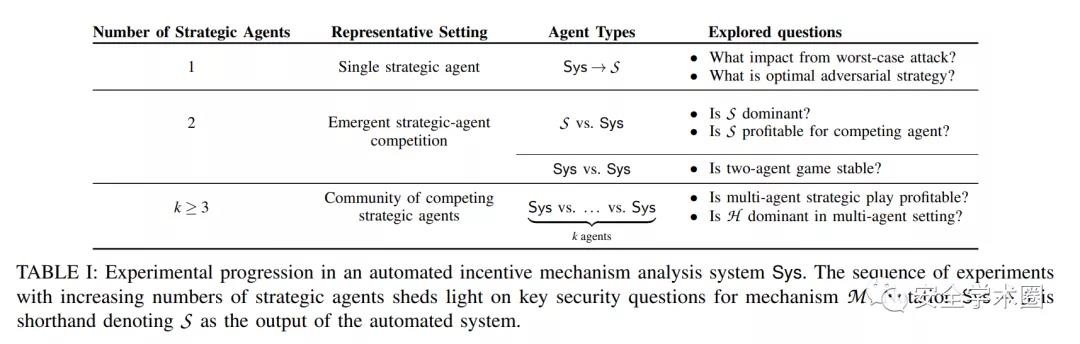
B. Straw-man solution
解决上表里问题的一个首选方法是Markov Decision Processes(MDPs), MDP solvers通常被用于在一个已知但随机的环境里学习最大化一个agent的奖励的策略。在前人的工作里,针对Bitcoin协议的双agent场景,MDP solvers已经被有效地利用去计算最优的对抗策略。
Deep reinforcement learning
强化学习是一类在某个环境里让agent学习到最大化自己累计收益的机器学习算法。深度强化学习是一种使用神经网络学习策略的强化学习,通常不需要明确指定系统的动态性。深度强化学习可以很好地解决具有两类特征的问题,其一是规则被很好地定义,其二是状态空间极大。在区块链中,参与者添加到账本中的每一个区块通常都会获得奖励,这让参与者能够事先评估自己的奖励,通过提供更快地反馈,更容易训练出自动系统去学习出有效的策略。因此深度强化学习适合解决我们的问题。
SquirRL: System description
下图展示了SquirRL框架图,这个框架包括针对激励机制的一个发现和分析对抗策略的三个管道。首先,协议设计者建立环境,模拟激励机制的执行,协议设计者在环境中实例化将状态表示,以及agent可能采取的动作空间。第二步,协议设计者将选择攻击者模型。第三步,协议设计者将根据环境和攻击者模型去选择RL算法,协议设计者将奖励函数和超参数和RL算法关联起来。
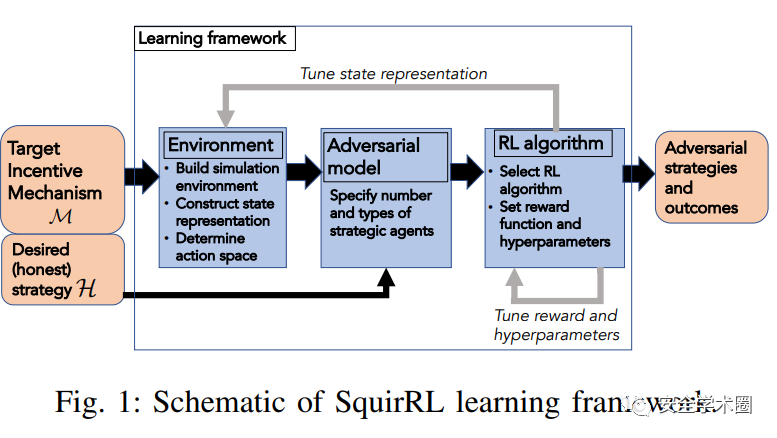
Discussion
强化学习在测试区块链协议激励机制上具有良好前景,本文提出了SquirRL,一个基于深度强化学习的自动识别区块链激励机制漏洞的框架。我们显示了SquirRL可以接近对区块链机制攻击理论分析的结果,也可以拓展到使用传统技术如MDP solvers无法考虑的地方。
方法缺点在于,实验结果显示了协议是安全,但这并不能说明协议是安全的。由于超参数设置的原因,从协议测试的角度来看,RL agent没有发现漏洞的事实可能是安全协议糟糕的超参数造成的。我们将SquirRL看作一个工具,当理论分析不现实的情况下,让协议设计者对协议进行安全性分析。
在未来,可以对agent的不同攻击行为和意图进行模拟。比如,agent之间合作的影响是未知的。我们的多agent实验只做了竞争agent,假设如果两个agent联合,且是完全联合,等价于竞争的agent变少了,这样的情况需要在未来被考虑。因为现实下agent可能是合作的。