带你详细了解Llama 2
作者:渣渣辉2023.08.10 10:18浏览量:13简介:详细了解Llama 2
一、概述
此次 Meta 发布的 Llama 2 模型系列包含 70 亿、130 亿和 700 亿三种参数变体。此外还训练了 340 亿参数变体,但并没有发布,只在技术报告中提到了。
据介绍,相比于 Llama 1,Llama 2 的训练数据多了 40%,上下文长度也翻倍,并采用了分组查询注意力机制。具体来说,Llama 2 预训练模型是在 2 万亿的 token 上训练的,精调 Chat 模型是在 100 万人类标记数据上训练的。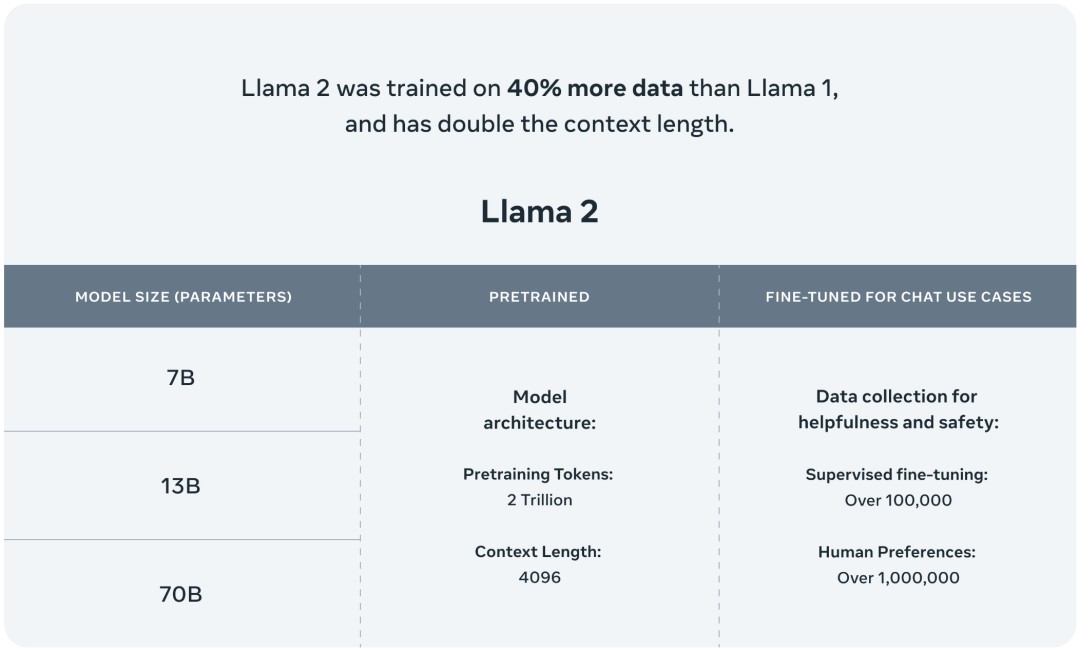 ragmentbodyhtml.jpg">
ragmentbodyhtml.jpg">
公布的测评结果显示,Llama 2 在包括推理、编码、精通性和知识测试等许多外部基准测试中都优于其他开源语言模型。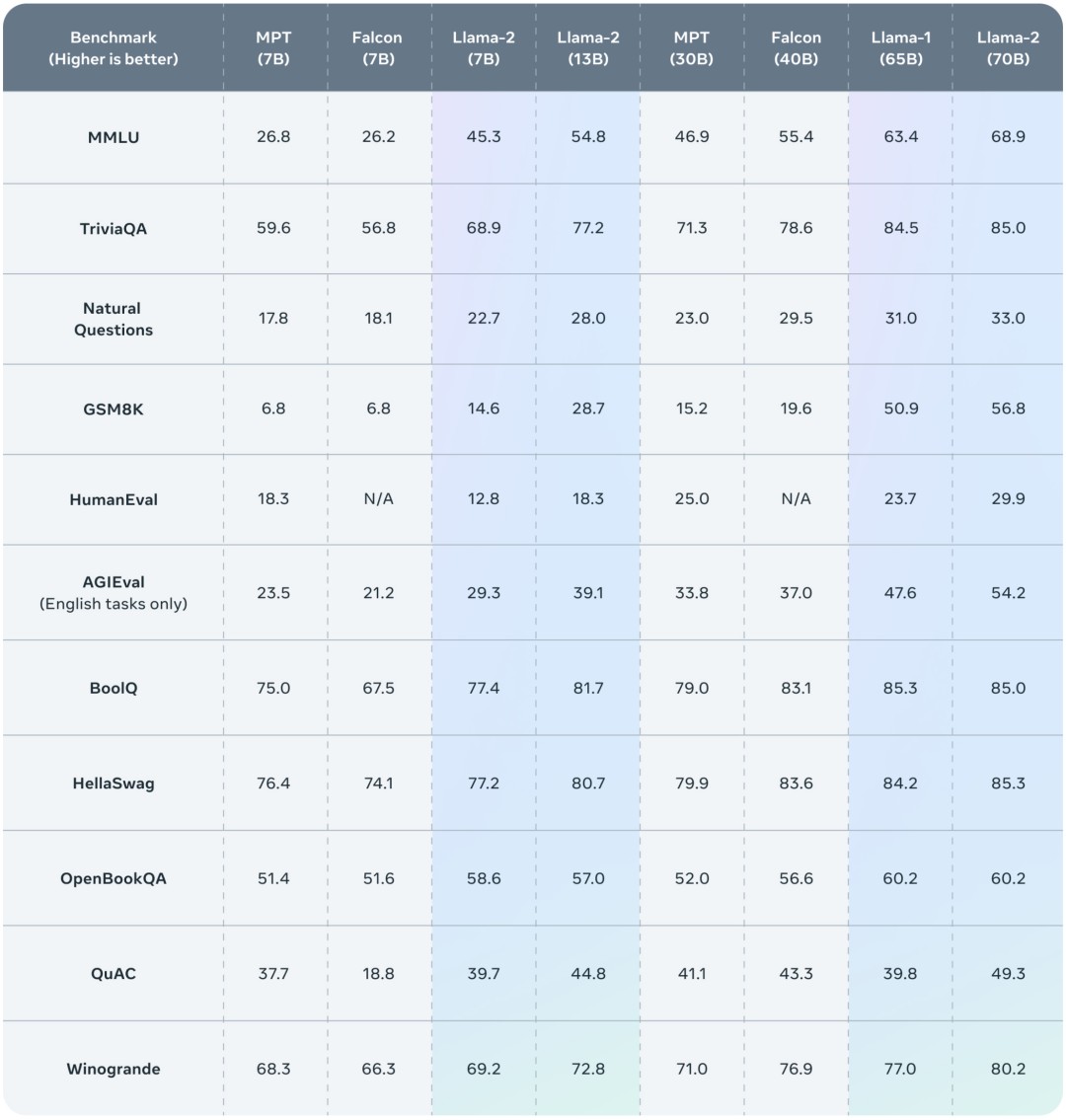
二、详细信息
模型下载请访问:https://huggingface.co/meta-llama
并请在相关页面提交申请:https://ai.meta.com/resources/models-and-libraries/llama-downloads
代码详见:https://github.com/facebookresearch/llama/tree/main/llama
2.1、基本信息
总的来说,作为一组经过预训练和微调的大语言模型(LLM),Llama 2 模型系列的参数规模从 70 亿到 700 亿不等。其中的 Llama 2-Chat 针对对话用例进行了专门优化。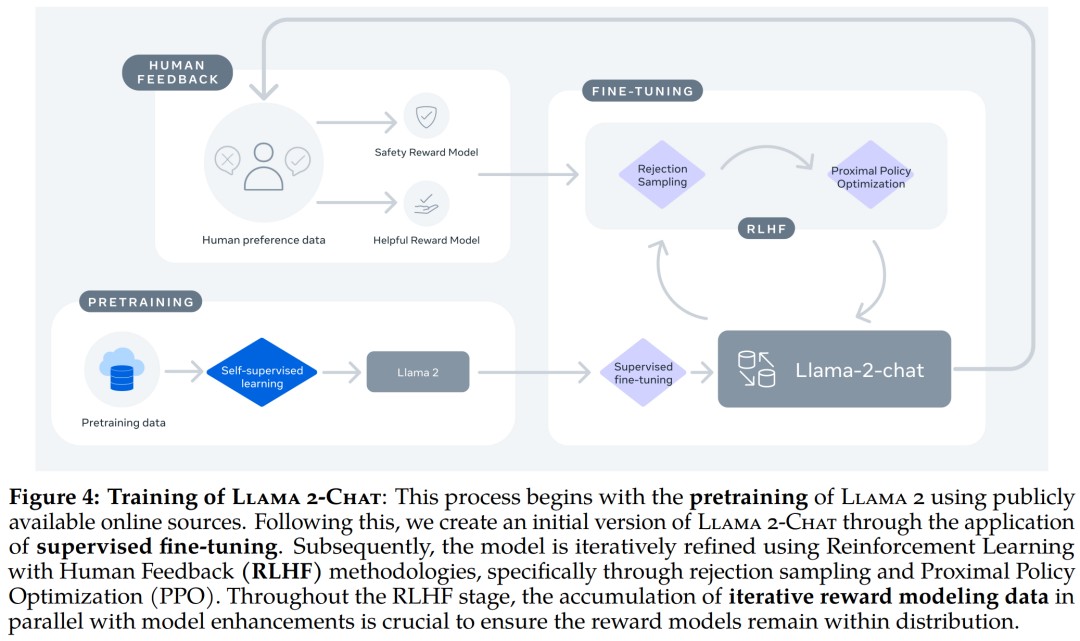
Llama 2 模型系列除了在大多数基准测试中优于开源模型之外,根据 Meta 对有用性和安全性的人工评估,它或许也是闭源模型的合适替代品。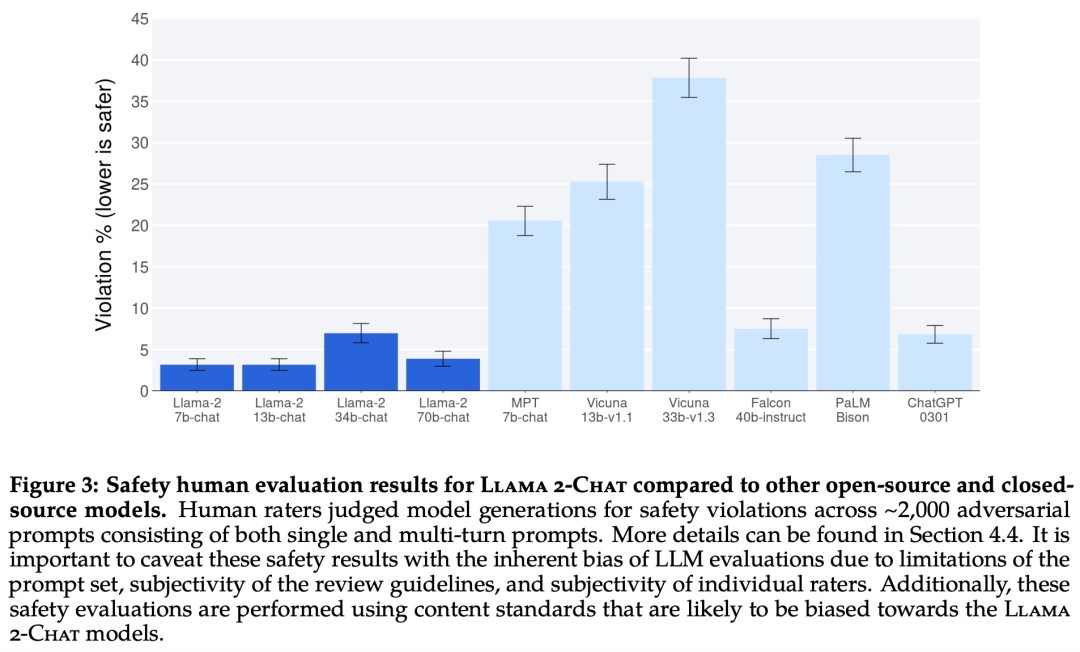
2.2、预训练
为了创建全新的 Llama 2 模型系列,Meta 以 Llama 1 论文中描述的预训练方法为基础,使用了优化的自回归 transformer,并做了一些改变以提升性能。
具体而言,Meta 执行了更稳健的数据清理,更新了混合数据,训练 token 总数增加了 40%,上下文长度翻倍。下表比较了 Llama 2 与 Llama 1 的详细数据。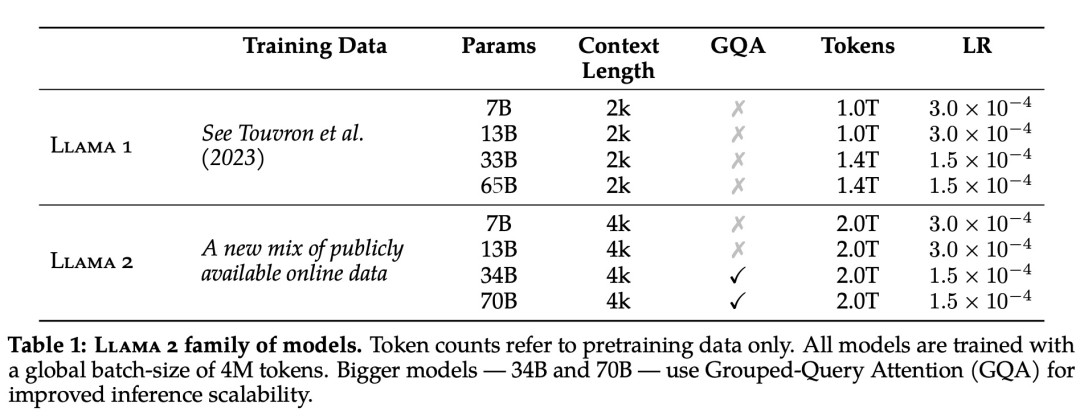
Llama 2 的训练语料库包含了来自公开可用资源的混合数据,并且不包括 Meta 产品或服务相关的数据。Llama 2 采用了 Llama 1 中的大部分预训练设置和模型架构,包括标准 Transformer 架构、使用 RMSNorm 的预归一化、SwiGLU 激活函数和旋转位置嵌入。
在超参数方面,Meta 使用 AdamW 优化器进行训练,其中 β_1 = 0.9,β_2 = 0.95,eps = 10^−5。同时使用余弦学习率计划(预热 2000 步),并将最终学习率衰减到了峰值学习率的 10%。
下图 为这些超参数设置下 Llama 2 的训练损失曲线。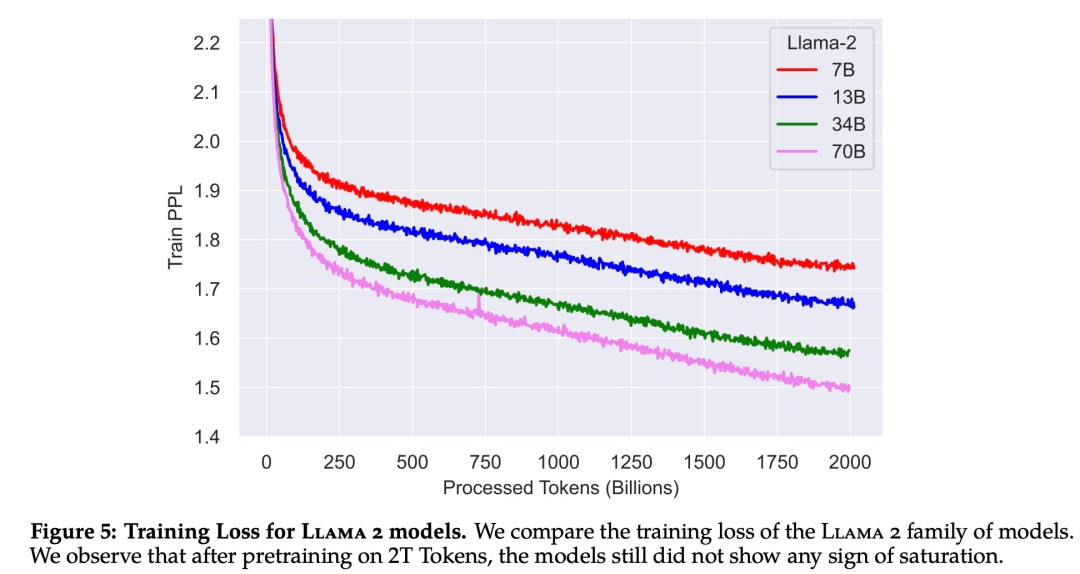
在训练硬件方面,Meta 在其研究超级集群(Research Super Cluster, RSC)以及内部生产集群上对模型进行了预训练。两个集群均使用了 NVIDIA A100。
2.3、Llama 2 预训练模型评估
Meta 报告了 Llama 1、Llama 2 基础模型、MPT(MosaicML)和 Falcon 等开源模型在标准学术基准上的结果。
下表总结了这些模型在一系列流行基准上的整体性能,结果表明,Llama 2 优于 Llama 1 。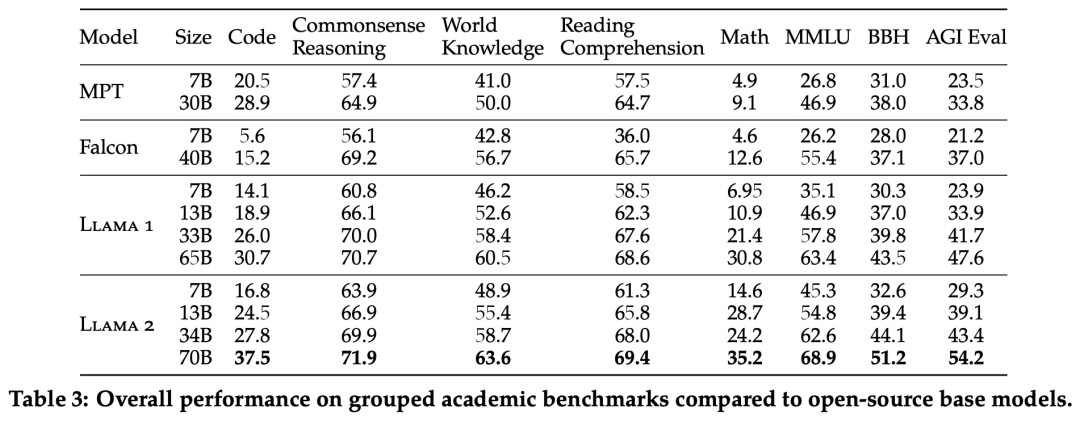
其中:
- 代码,包括HumanEval 和MBPP ,指标为平均pass@1分数。
- 常识性推理,包括PIQA 、SIQA 、HellaSwag、WinoGrande、ARC easy and challenge 、OpenBookQA 和CommonsenseQA ,指标为准确率的平均值。
- 世界知识,包括NaturalQuestions 和TriviaQA ,指标为准确率的平均值。
- 阅读理解,包括SQuAD 、QuAC 和BoolQ ,指标为准确率的。
- 数学。包括GSM8K和MATH,指标为准确率。
- Standard Benchmarks基准。包括MMLU、Big Bench Hard BBH和AGI Eval。对于AGI Eval,只评估英语任务。指标为准确率。
除了开源模型之外,Meta 还将 Llama 2 70B 的结果与闭源模型进行了比较,结果如下表所示。Llama 2 70B 在 MMLU 和 GSM8K 上接近 GPT-3.5,但在编码基准上存在显著差距。
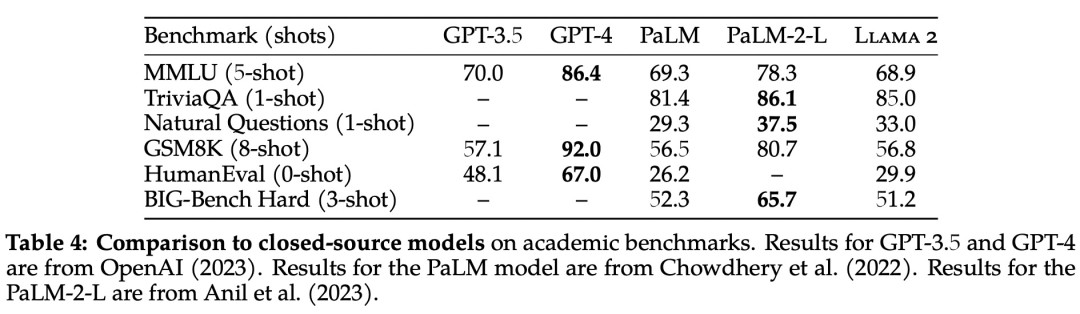
在几乎所有基准上,Llama 2 70B 的结果均与谷歌 PaLM (540B) 持平或表现更好,不过与 GPT-4 和 PaLM-2-L 的性能仍存在较大差距。
此外,有个价值观评测值得很重要。这个采用了 TruthfulQA以及ToxiGen。
其中,对于TruthfulQA,给出了同时具有真实性和信息性的代数百分比(越高越好)。TruthfulQA的目的是测量模型的真实性,即模型识别主张是否真实的能力。”真实 “的定义是指 “真实世界的字面意义上的真实”,而不是仅在信仰体系或传统中才是真实的主张。这一基准可以评估模型产生错误信息或虚假主张的风险。这些问题的写作风格多种多样,涵盖 38 个类别,设计具有对抗性。
对于 ToxiGen,给出了有毒性的百分比(越小越好),这个任务可以检查模型生成内容的毒性,论文地址:https://arxiv.org/pdf/2203.09509.pdf