新闻资讯
关注百度智能云最新动态,了解产业智能化最新成果
十分钟明白GaiaDB架构
2023-08-23 12:04:48GaiaDB 整体架构
GaiaDB是百度自研的全新架构云原生数据库产品。早期的云数据库架构存在资源利用率低、弹性扩展能力差、故障恢复慢、维护成本高等问题。基于这些痛点,GaiaDB采用全新的计算与存储分离架构,不仅在性能、扩展性和高可用方面有大幅提升,而且架构的解耦使得计算层和存储层都获得了很大的优化空间。
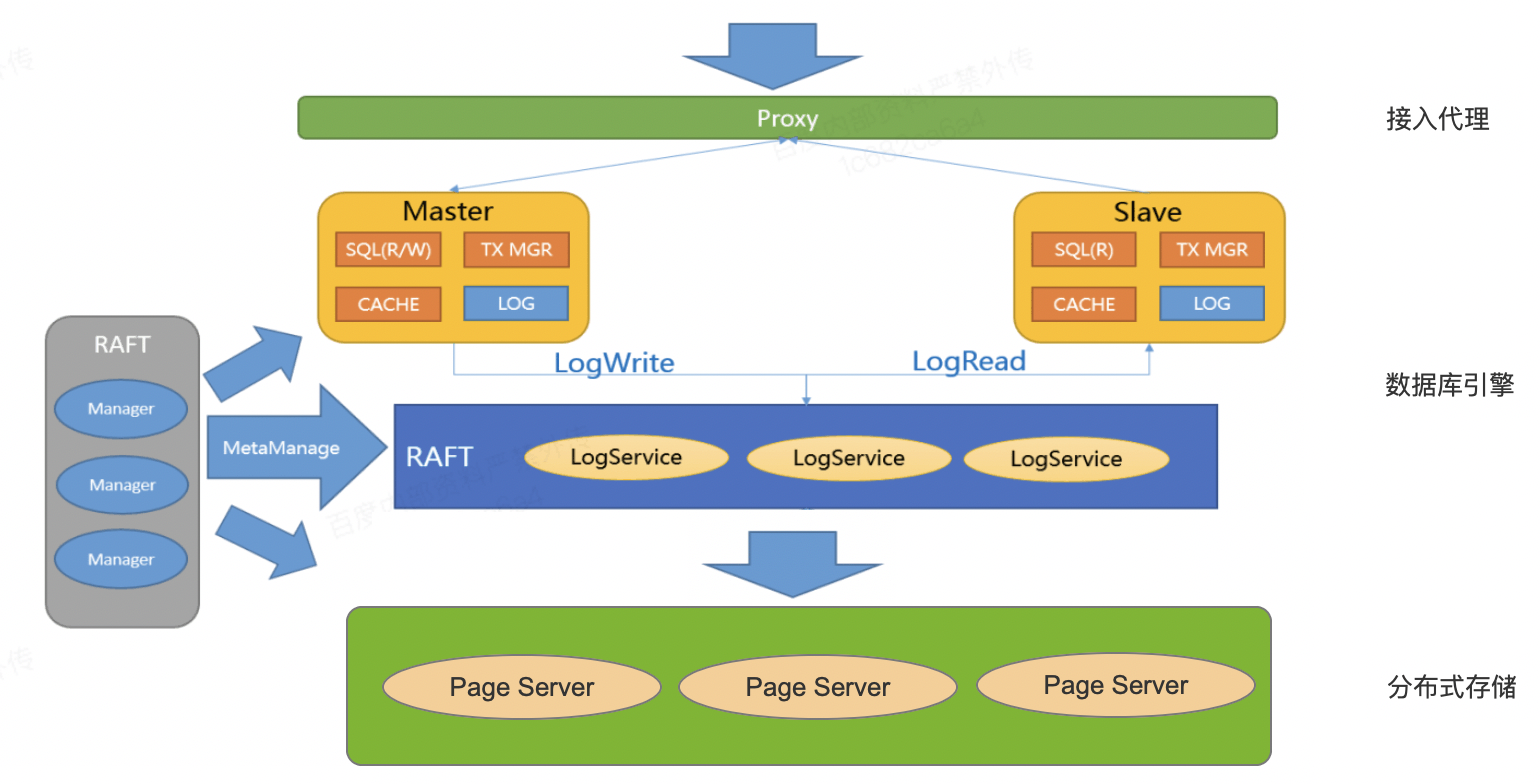
GaiaDB代理层
Proxy提供安全认证和保护。
Proxy解析SQL,把写操作(比如事务、Update、Insert、Delete、DDL等)发送到主节点,把读操作(比如Select)均衡地分发到多个读节点,这个也叫读写分离。
通过Proxy把不同的业务用不同的连接地址,使用不同的数据节点。这样就可以避免相互影响,不会影响在线业务。
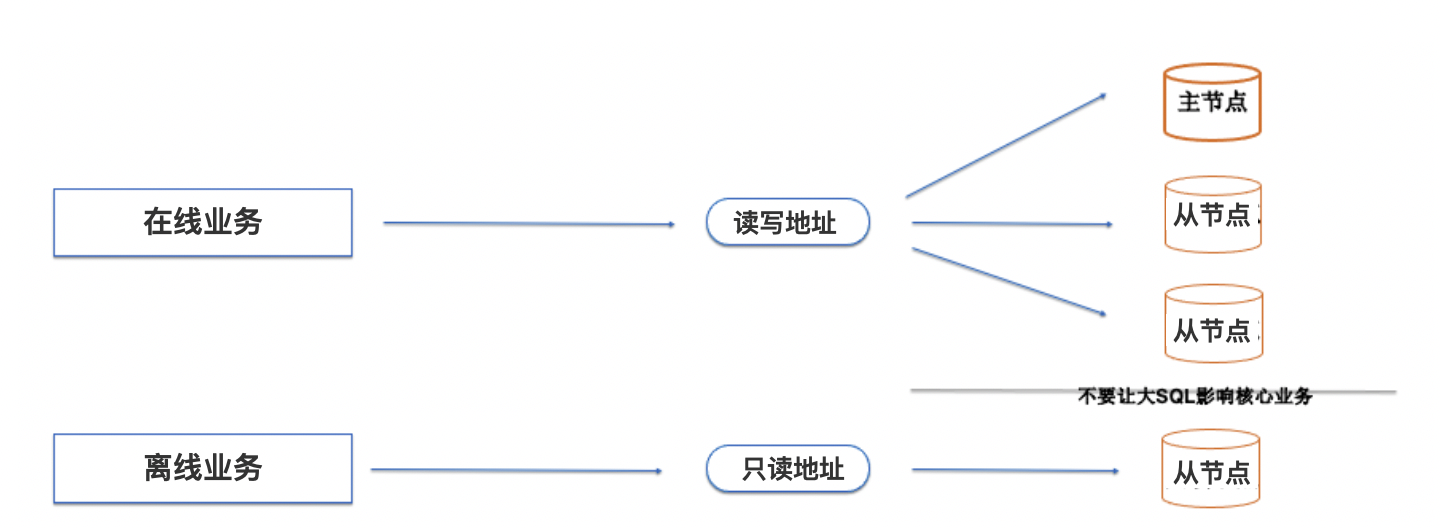
GaiaDB计算层
主节点:处理读写请求,处理事务。相比于MySQL的主节点,GaiaDB的主节点仅需要将日志(RedoLog)发送至日志服务(LogService)持久化,不需要写数据。数据是由数据存储节点(PageServer)从LogService拉取日志并回放。
从节点:处理只读负载。从PageServer拉取最新的数据。
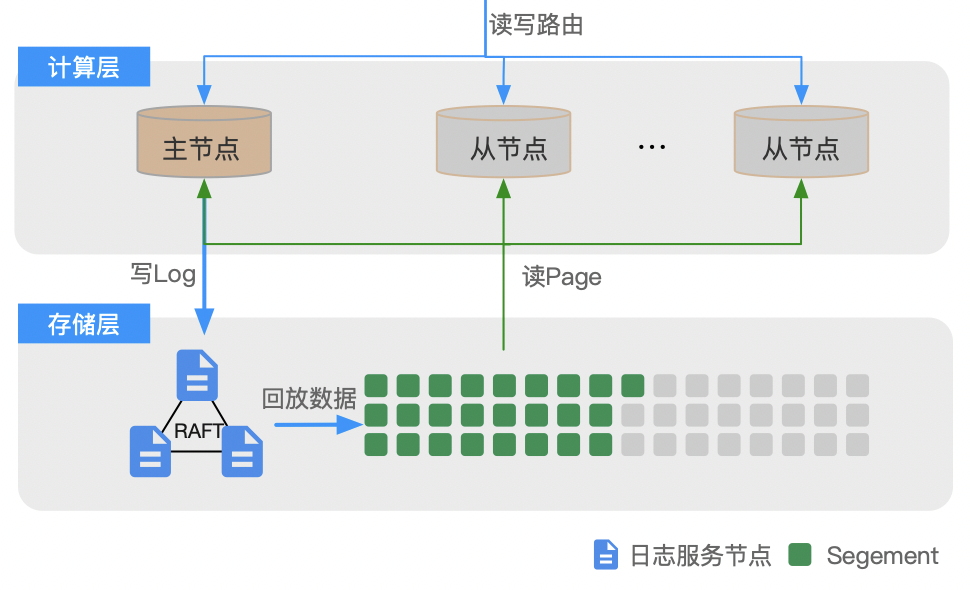
这样的设计具有以下优势:计算节点无状态,弹性快速扩容。计算层节点无持久化数据:本地文件不复存在,包括日志文件,所以支持快速扩容,大概在30秒内就能快速创建从节点并提供服务。
只有单机事务,没有分布式事务问题。集群所有的事务都请求到主节点,主节点自身保障事务的ACID特性。
RPO=0,单机故障不影响集群一致性。事务产生的Redo日志均实时写入LogService,从节点利用PageServer上的数据文件和LogService中的Redo日志,在内存中恢复最新的数据对外提供服务。每一次主备故障切换,从节点均可以获取最新的事务Redo日志,因此不会出现数据丢失(RPO=0)。
GaiaDB存储层
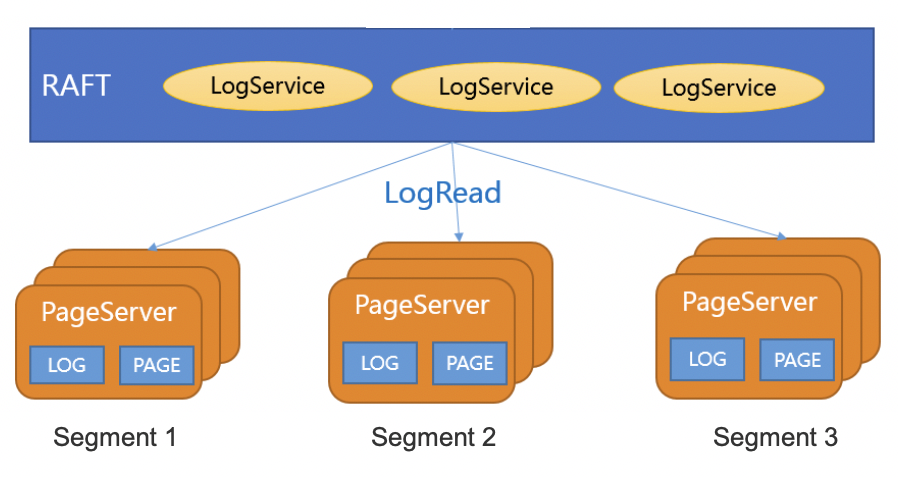
数据的一致性和数据存储分离,LogService专注一致性保障,PageServer专注持久化数据。
PageServer和LogService都采用多副本的方式保障高可用。
PageServer之间逻辑独立。独立从LogService拉取数据,LogService保障数据的一致性。
存储节点的扩容只需要增加PageServer的个数,扩容操作对用户无感。
GaiaDB集群管理
· 容量大
最高128T,不再因为单机容量的天花板而去购买多个MySQL实例做Sharding,甚至也不需要考虑分库分表,简化应用开发,降低运维负担。
· 高性价比
多个节点只收取一份存储的钱,也就是说只读实例越多越划算。
· 秒级弹性
多个节点只收取一份存储的钱,也就是说只读实例越多越划算。
· 毫秒级延迟
利用基于Redo的物理复制代替基于Binlog的逻辑复制,提升主备复制的效率和稳定性。即使是加索引、加字段的大表DDL操作,也不会对数据库造成延迟。
· 百万级吞吐
架构卸载掉很多很重的模块和机制,使得总体性能上获得了很大的提升空间。
· 高可用
计算故障恢复秒级启动,存储故障恢复单/双副本故障无影响。