基于 EMQX 和 Neuron 的工业物联网 MQTT Sparkplug 解决方案
作者:EMQ映云科技2023.07.13 17:08浏览量:307简介:我们将详细探讨 Sparkplug 解决方案的架构
引言
Sparkplug 是基于 MQTT 的一种专门为工业自动化和物联网应用而设计的通信协议。要搭建 Sparkplug 解决方案,需要两个核心组件:一个是 MQTT Broker,负责消息的分发和管理;另一个是边缘节点,负责将本地设备接入 Broker,以实现实时数据的处理和分析。
在本文中,我们将使用开源分布式 MQTT Broker EMQX,以及边缘工业协议网关软件 Neuron,来构建一个可扩展和稳健的平台,用于实现 Sparkplug 解决方案。我们将详细探讨 Sparkplug 解决方案的架构,并深入了解 EMQX 和 Neuron 在其中所扮演的角色。
EMQX 在 Sparkplug 中的角色
EMQX 用于创建符合 Sparkplug 规范的 MQTT 主题命名空间。Sparkplug 命名空间定义了设备发布和订阅的 MQTT 消息的结构和内容。通过 EMQX,我们可以确保所有发送到和接收自 Sparkplug 命名空间的消息都被正确格式化并符合 Sparkplug 规范。
Neuron 在 Sparkplug 中的角色
Neuron 用于将边缘设备连接到 EMQX Broker 上的 Sparkplug 命名空间。它充当网关的角色,负责从本地传感器和控制器收集数据,并使用 Sparkplug 有效载荷格式将其发布到 EMQX。同时,Neuron 还会订阅 Sparkplug 命名空间中的消息,并根据需要将其转发到本地设备。
EMQX 和 Neuron 共同扮演的新角色
通过协同使用 EMQX 和 Neuron,可以为工业物联网应用创建统一的命名空间。这是一种基于 MQTT 主题的通用命名方式,让设备和应用可以在任何位置使用任何协议进行相互通信。所有的设备和应用都使用相同的 MQTT 主题层次结构,基于一套通用的命名规则和数据模型。这样就实现了设备间的自动发现和通信,无需复杂的路由或转换机制。
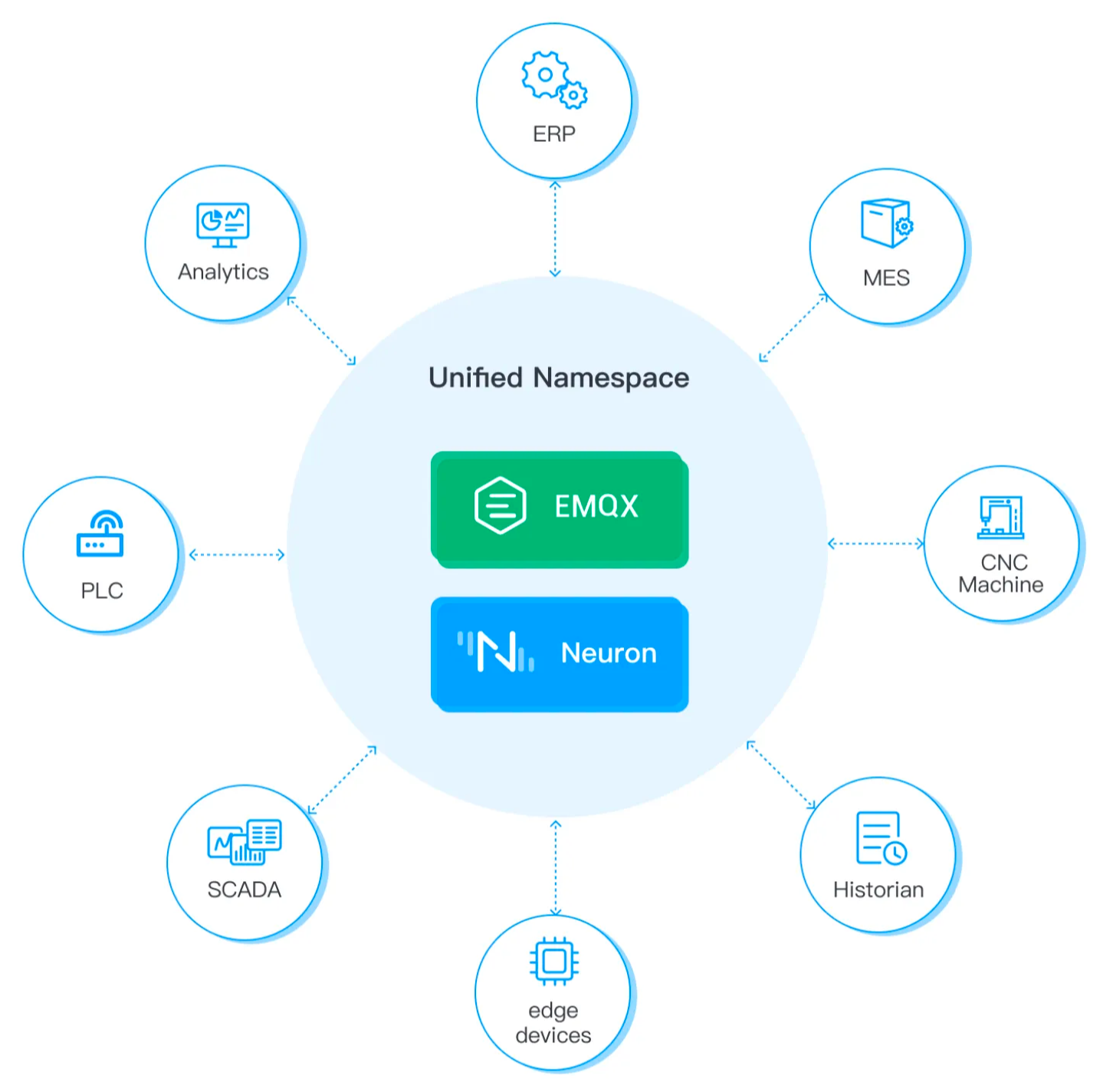
EMQX 通过定义符合设备和应用的命名规范和数据模型的主题层次结构,来实现对统一命名空间的支持。这样的主题层次结构可以包括设备数据、控制命令、报警和事件等主题,而所有这些主题都以一种标准化的方式组织。这种统一的命名空间设计使得设备和应用能够相互发现和交互。
Neuron 通过使用与 MQTT Broker 一致的命名规则和数据模型,来支持统一的命名空间。这让 Neuron 能够与物联网系统的其他组件进行无缝集成,实现设备在不同地点不同协议的情况下进行通信。
Sparkplug 解决方案架构
使用 EMQX 和 Neuron 的 MQTT Sparkplug 解决方案可以构建为三层架构。如下图所示,所有连接到统一命名空间的设备和应用都可以划分到两个层级,底层的数据生产者或者顶层的数据消费者。而 EMQX 和 Neuron 则位于中间层,扮演了数据交换的角色,实现了数据生产者和消费者之间的通信。
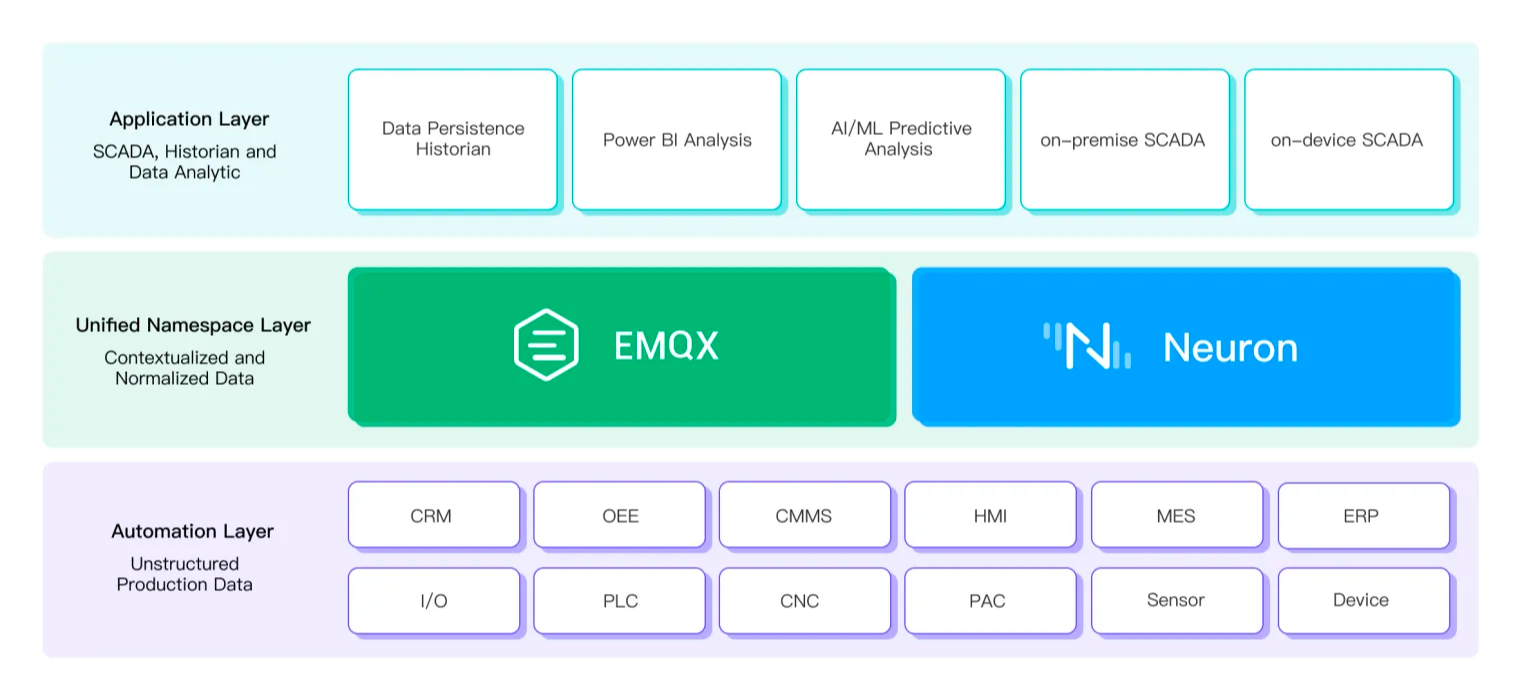
- 自动化层:在自动化生产过程中,自动化层由各种设备和应用组成,它们生成大量的原始和非结构化数据。这些设备和应用多数部署在工厂车间或数据中心。
- 统一命名空间层:这层由 EMQX MQTT Broker 和 Neuron 网关组成,它们负责数据的传输和转换。Neuron 帮助将传感器或设备数据以 Sparkplug 消息格式发布到 EMQX,EMQX 将数据从生产者转发给订阅者。EMQX 还负责维护系统的状态信息,包括设备及其相关数据。
- 应用层:这是由应用构成的层级,它们从统一命名空间层获取数据,并用于分析、监控、控制等功能。这些应用可以根据系统的需求选择在本地或云端部署。
接下来,我们将分别介绍每个层级的情况。
自动化层
自动化层能够提供工厂整个自动化生产过程的信息。这些信息来源于以下几类设备或系统:
- 现场设备:在物理世界中进行数据收集和控制的设备,如数控机床、传感器和执行器等。
- 控制设备:用于控制现场设备运行的各种控制器,如 PLC、PAC、DCS 等。它们执行控制算法,并与现场设备通信。
- 监控系统:人机界面(HMI)和监控控制和数据采集(SCADA)系统之类的设备。
- 信息系统:数据库、数据历史记录器、制造执行系统(MES)、企业资源规划(ERP)等软件应用程序,用于存储和分析从上述设备或系统获取的数据。
在日常生产中,现场设备负责从物理世界中收集数据,并将其发送给控制设备。控制设备则处理这些数据,并向现场设备发送命令以控制它们的行为。监控系统对控制设备的运行状况进行监测,并向操作员和信息系统反馈信息。信息系统则负责从各个低层设备和系统收集并存储数据,并向其他企业系统提供信息查询服务。这种信息流使得自动化系统能够高效、可靠地运行。但是,这些信息都是原始的、非结构化的数据,需要经过规范化并赋予上下文语义后才能用于更深入的分析。
统一命名空间层
统一命名空间层将自动化层产生的所有非结构化和原始数据进行整合并进行上下文语义处理。这是一个数据规范化和赋予上下文语义的过程,它把来自各种不同来源的数据汇集到一个带有时间戳的统一信息源中。这些数据无论来源或格式如何,都按照一致和标准化的方式进行组织和访问。
这种规范化和具有上下文语义的数据包含了与特定目的相关的所有信息,比如设备性能、环境条件、生产产量和其他对工业运营重要的指标。也就是说,赋予上下文语义为组织内的所有数据提供了一个单一的、有意义的、统一的视角。工业组织可以利用这种具有上下文语义的数据,全面而整体地了解其运营情况,从而能够做出更明智的决策,并优化其流程,以提高效率和盈利能力。
应用层
应用层是应用程序利用具有上下文语义的数据进行分析的地方,例如人工智能/机器学习和预测性维护,并根据分析结果对工厂运营进行优化。这些应用可以订阅感兴趣的数据点或设备节点,实时获取更新信息,使工厂能够及时应对生产过程的变化。
具有上下文语义的数据能够提高人工智能和机器学习模型使用的数据质量。这些模型可以利用额外的上下文信息和元数据,更好地理解和解释数据,降低错误并提高准确性。此外,具有上下文语义的数据还提升了人工智能和机器学习模型的预测能力。模型可以根据更多的上下文信息,对未来发生的事件或结果做出更精确的预测。
结语
总之,通过在 Sparkplug 解决方案中同时使用 EMQX 和 Neuron,可以轻松实现上下文分析,并确保数据在系统中以准确一致的方式进行共享。这个解决方案不仅能够实现不同命名系统的设备和应用之间的发现和通信,还能够支持各种分析应用,如人工智能/机器学习、BI 业务分析和预测控制。这样,决策者就可以得到更精确的洞察和可行的结果,从而能够基于可信的数据和分析做出明智的决策。
版权声明: 本文为 EMQ 原创,转载请注明出处。
原文链接:https://www.emqx.com/zh/blog/mqtt-sparkplug-solution-for-industrial-iot-using-emqx-and-neuron