- 能力全景图
- 方案优势
- 最佳实践
- 联系我们
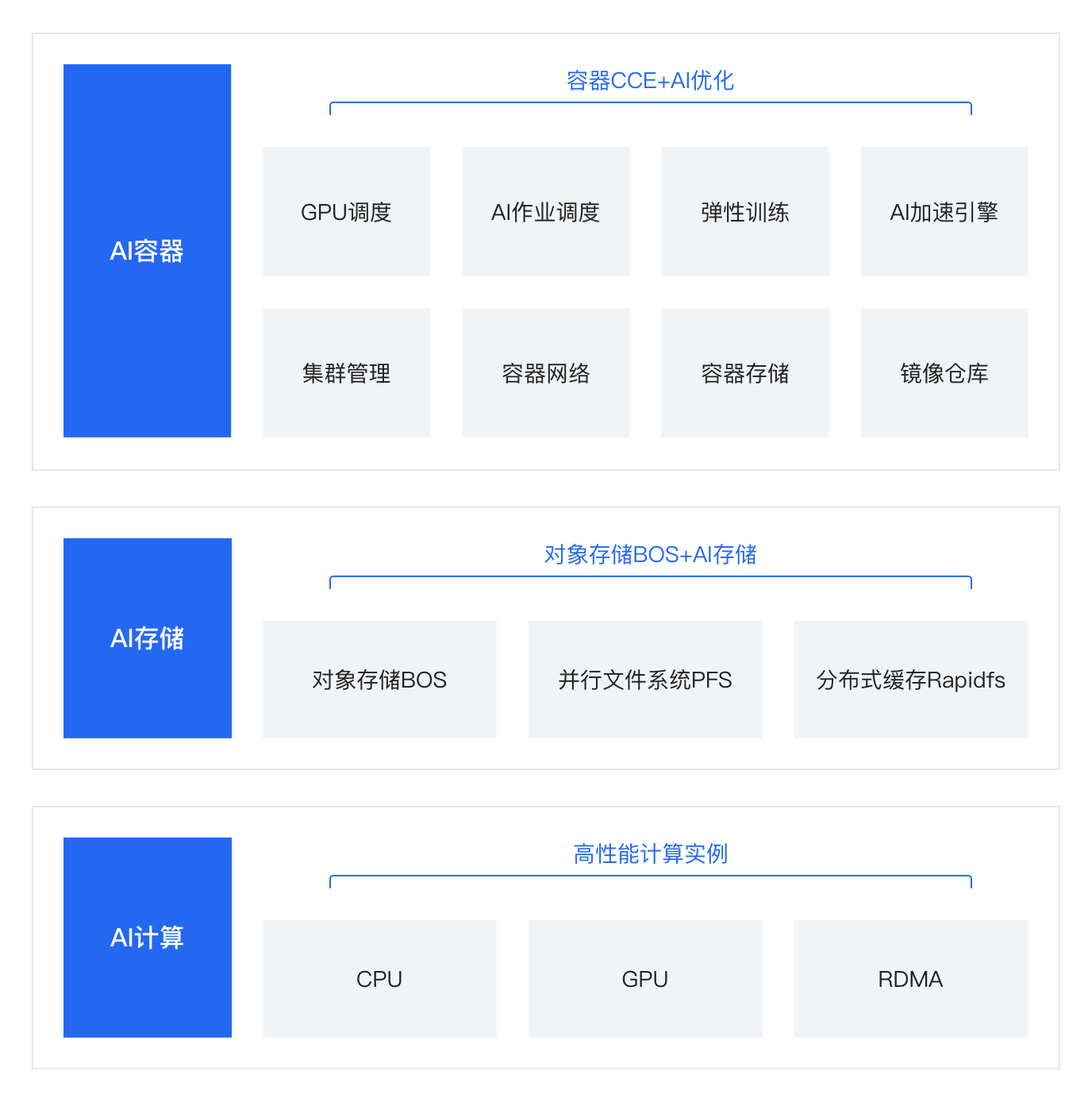
云原生AI能力全景图
云原生AI在资源弹性、跨节点架构感知,训练推理效率等多方面的能力显著提升,可最大化地帮助企业实现AI应用的快速交付与落地。
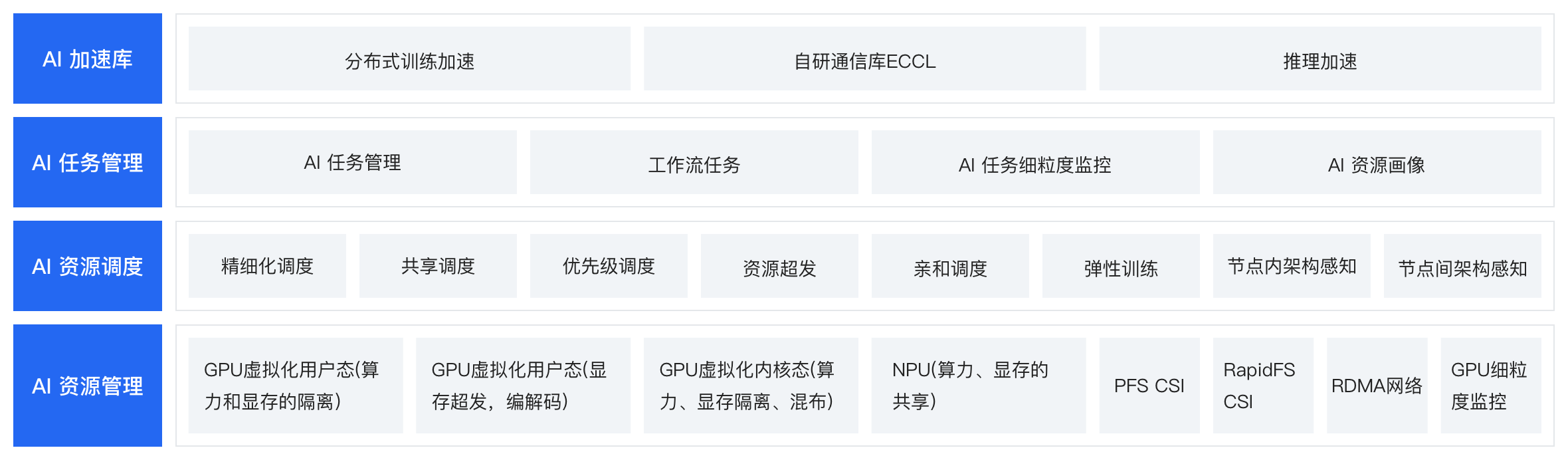
解决方案优势
双引擎虚拟化
提供了用户态和内核态双引擎:用户态性能最优,内核态隔离性强。用户可以根据自己的需求灵活选择。
01AI调度
调度支持共享混部、独立调度,用户可根据需求灵活选择;支持拓扑感知以及亲和调度。
02AIAK-Training 分布式训练加速
通过通信加速和算子融合等技术,提升分布式训练的性能,在典型模型场景下吞吐提升50%以上。
03推理加速
通过图优化跟算子融合等技术,提升推理的性能,在典型模型场景下时延降低50%。
04数据加速
支持Fluid Operator与PFS/RapidFS等,能实现分布式缓存引擎加速与协同调度,训练效果提升5倍以上。
05