拒绝 OpenClaw 成为「吞金龙虾」,百度百舸打造极致 KV Cache 调度与加速引擎
作者:xxinjiang2026.04.01 16:08浏览量:212简介:百度百舸构建了 KV Cache 分布式缓存管理体系 AttentionStore
2026 开年,OpenClaw 的现象级爆发使大模型迅速迈入「超长上下文」时代。在几乎人人手捧「龙虾」穿梭于代码、搜索、办公自动化的当下,Token(词元)消耗成本正在迅速累积。据 OpenRouter 平台数据,2026 年 3 月单周 OpenClaw Token 消耗量占平台总量的 20%。用户实测单个会话的上下文可膨胀至 23 万 Token;重度使用场景的月成本甚至高达 800-1500 美元。
这背后,是 Agent 架构的全量记忆策略——每一轮对话请求都必须携带历史上下文,导致 Token 消耗随轮次呈滚雪球式增长。
此时,KV Cache 的管理方式便成为影响推理效率与成本的关键变量。若无法有效复用历史 KV Cache,系统将重复执行 Prefill 计算——不仅带来了不必要的 Token 成本花销,也会显著拉长首 Token 时延(TTFT)。因此,通过提升上下文缓存命中率来降低用户使用成本以及通过减少重复 Prefill 计算来降低 TTFT,成为 KV Cache 优化的核心方向。
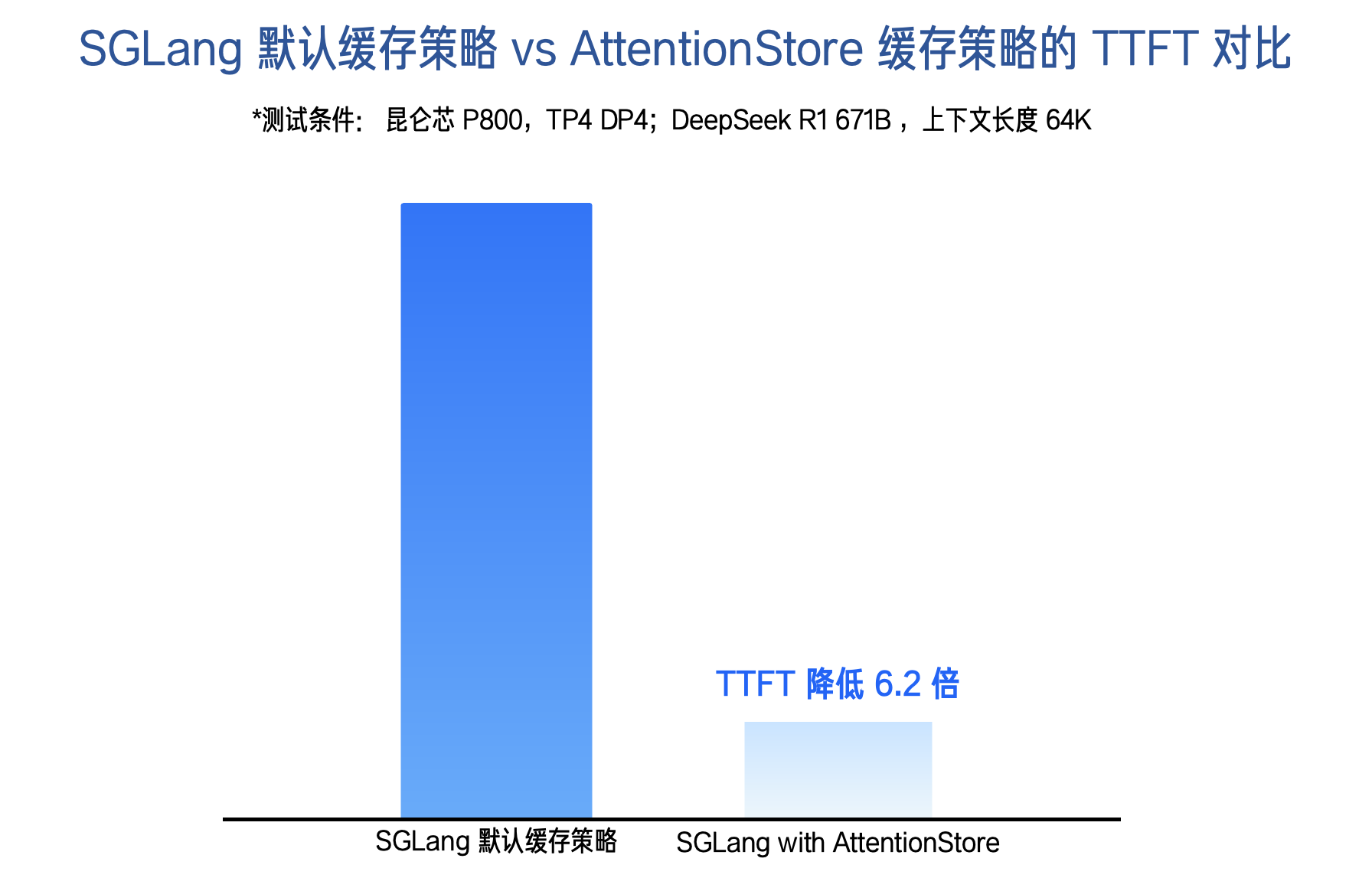
百度百舸推出了一套自主研发的 KV Cache 系统 —— AttentionStore,并基于昆仑芯 P800 在 DeepSeek 模型上完成系统验证:在 8K+ 长上下文场景中,TTFT 实现了 2 至 5 倍的性能提升;而在 64K 长上下文场景下,TTFT 性能提升至 6.2 倍,显著增强了大模型在长上下文历史条件下的首 Token 响应能力。
接下来,我们将进一步展开 AttentionStore 在 KV Cache 多级缓存管理体系上的关键设计与工程实践。
1. 显存瓶颈:长上下文推理的隐形天花板
在当前主流推理引擎(如 SGLang、vLLM 等)中,KV Cache 通常被视为一种仅存在于显存中的短生命周期数据结构。其设计目标很明确:在一次请求的解码阶段复用历史 Key / Value,避免重复计算;一旦请求结束或被调度器回收,KV Cache 便会被整体释放,以保证显存能够服务更多并发请求。
然而,随着多轮对话等长上下文场景的兴起,推理系统中所能容纳的 KV Cache 体量逐渐成为了决定系统性能的核心变量。此时,仅依靠显存承载的 KV Cache 体量远远不能满足长下文推理场景下的会话响应要求。
要准确评估 KV Cache 存储的瓶颈,就需要综合分析「单个 Token 所需的 KV 缓存开销」、「可存放 KV Cache 的显存容量」、以及「长上下文的会话长度」。
KV 缓存的计算公式如下:
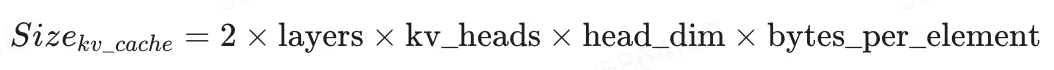
其与模型规模、模型层数、数据精度、以及所采用的注意力头结构相关。
- 以 Qwen3-32B 模型为例,其采用 GQA 结构,在 FP16 精度下,单 Token 所需的 KV 缓存开销约为 0.25MB,对于一个 80GB 显存的加速卡来说,除去模型权重需占用的 60GB 以及 runtime buffer、临时算子、并发数等占用的约 5GB~10GB 后,仅剩余的 10GB 显存最多容纳约 40K Tokens;
- 同理,我们再以 LLaMA-13B 模型为例,其采用 MHA 结构,在 FP16 精度下,单 Token 所需的 KV 缓存开销约为 0.8MB,在 80GB 显存的加速卡中,仅剩余的 40GB 显存最多容纳约 48K Tokens。
然而,在诸如 OpenClaw 等长上下文的真实业务场景中,受到多轮对话、多并发用户因素的影响,会话长度可达 64K,甚至 128K。此时,显存容量的有限空间就使得系统经常需要重新计算历史 Token 的 KV 值,引起极大的推理时延。
为了解决显存无法容纳长上下文业务场景所需存放的 KV Cache 问题,业内普遍采用了 KV Cache Offload 方案 —— 它提供了一种兼具性能与成本效益的技术路径:将历史 KV Cache 从昂贵的显存中迁移至更具性价比的存储介质(如内存、SSD 等),在会话延续时按需加载实现数据复用。然而,在将这一方案大规模落地到生产业务过程中,还需要解决三个关键问题:
- 调度系统要如何匹配到最优节点,避免昂贵的重复计算开销:传统调度系统无法感知缓存的全景分布与介质状态,存在严重的调度盲区。这导致请求往往被分发至无缓存节点,触发大规模重复计算与存储冗余,难以发挥分布式缓存的集群效应;
- 如何提升多级缓存间的数据搬运效率,加快响应速度:传统方案难以针对异构芯片的底层访存特性进行深度优化,在多级存储介质(HBM - DRAM - SSD)之间搬运动态数据时,数据通路效率低下,极易引入额外的传输时延,抵消掉复用缓存带来的性能增益;
- 会话中断后,如何避免 KV Cache 丢失:传统方案中,缓存管理与推理进程强耦合:一旦推理引擎进程退出或异常重启,缓存数据即刻失效。
2. AttentionStore —— KV Cache 全局调度与高效流转系统
正是由于上述问题的存在,KV Cache Offload 并不能仅停留在「存储迁移」层面,而必须在调度、数据通路与缓存管理机制上进行系统性升级。
在这一背景下,百度百舸构建了 KV Cache 分布式缓存管理体系 AttentionStore,并基于昆仑芯硬件平台进行了深度适配与调优。
AttentionStore 通过在推理集群层面实现多维感知与精准调度,以及在执行节点中加快缓存数据的传输效率,AttentionStore 可实现高达 80% ~ 90% 的 KV Cache 缓存命中率,大幅降低推理成本;并系统性减少重复 Prefill 计算开销,显著降低 TTFT。
为了保障 KV Cache 服务连续性,我们将 AttentionStore 与推理引擎解耦,以独立进程的形式运行在每个推理节点上,当推理进程重启、故障恢复或版本升级时,KV Cache 依旧可以稳定保存在 AttentionStore 管理的存储空间中,可在后续推理中重新加载使用。同时,AttentionStore 采用共享内存和 SSD 作为主机缓存介质,其自身重启后可通过本地索引表快速实现数据恢复,实现服务升级与维护期间业务无感切换。
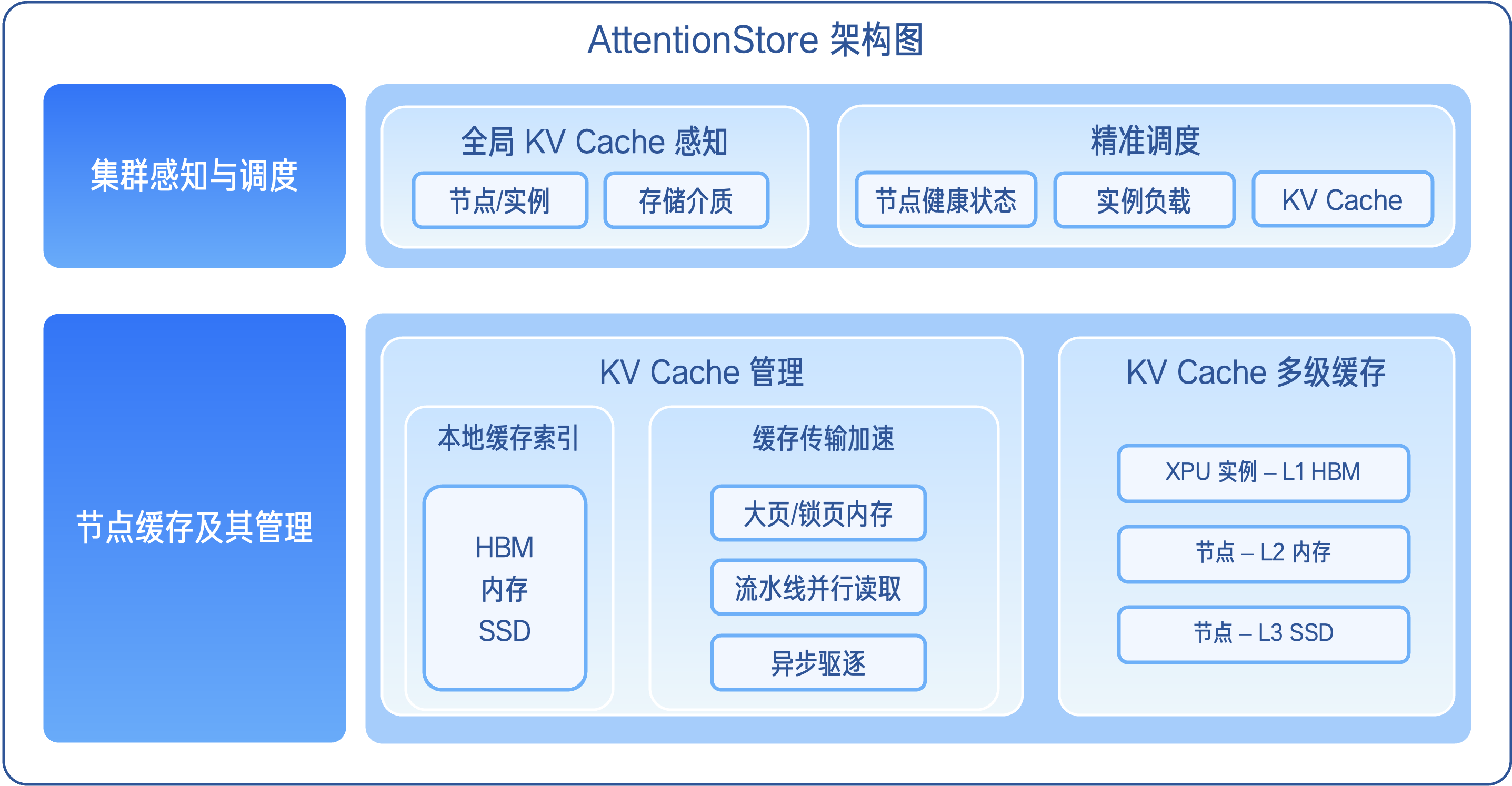
2.1. KV Cache 全局感知,优化推理调度决策链
在实际生产环境中,推理请求往往运行在多节点、多实例的分布式架构之上。若推理调度器对缓存分布无感知,仅依据不同实例的状态及负载等因素进行调度决策,极易出现「请求被调度至无缓存节点」的情况,从而触发完整的 Prefill 重算,使得 Offload 带来的性能收益被完全抵消。
为此,凭借行业领先的 KV Cache 多维感知,我们在推理集群内构建了实时 KV Cache 全局索引视图;并将 KV Cache 纳入调度决策,使调度从「只看资源」升级为「资源与缓存协同决策」。
- 全局 KV Cache 索引:我们在全局层面汇聚了各推理节点的 KV Block 信息,包括 BlockHash、所在存储介质(HBM / DRAM / SSD)等元数据,并实时捕捉 KV Cache 的创建与销毁事件,从而精准掌握最新的全局 KV Cache 索引,形成 Host → Blocks 映射关系;
- 调度决策优化:在具备全局感知能力之后,KV Cache 的命中情况被正式纳入调度决策路径。在原有基于负载与健康状态筛选候选节点的基础上,调度器会根据请求上下文,将调度目标先收敛到具备高缓存命中率的节点集合,并结合命中长度以及缓存所在存储介质(HBM / DRAM / SSD)的读取效率,对候选节点进行综合打分。
最终,推理集群调度不再仅以「是否可用」为标准,而是以「是否最优」为目标——将请求优先分配至缓存命中率更高、数据加载速度更快的节点,在保障负载均衡的前提下,最大化 KV Cache 复用价值,系统性降低重复 Prefill 开销,并显著优化 TTFT 表现。
2.2. KV Cache 多级缓存优化,加速数据传输效率
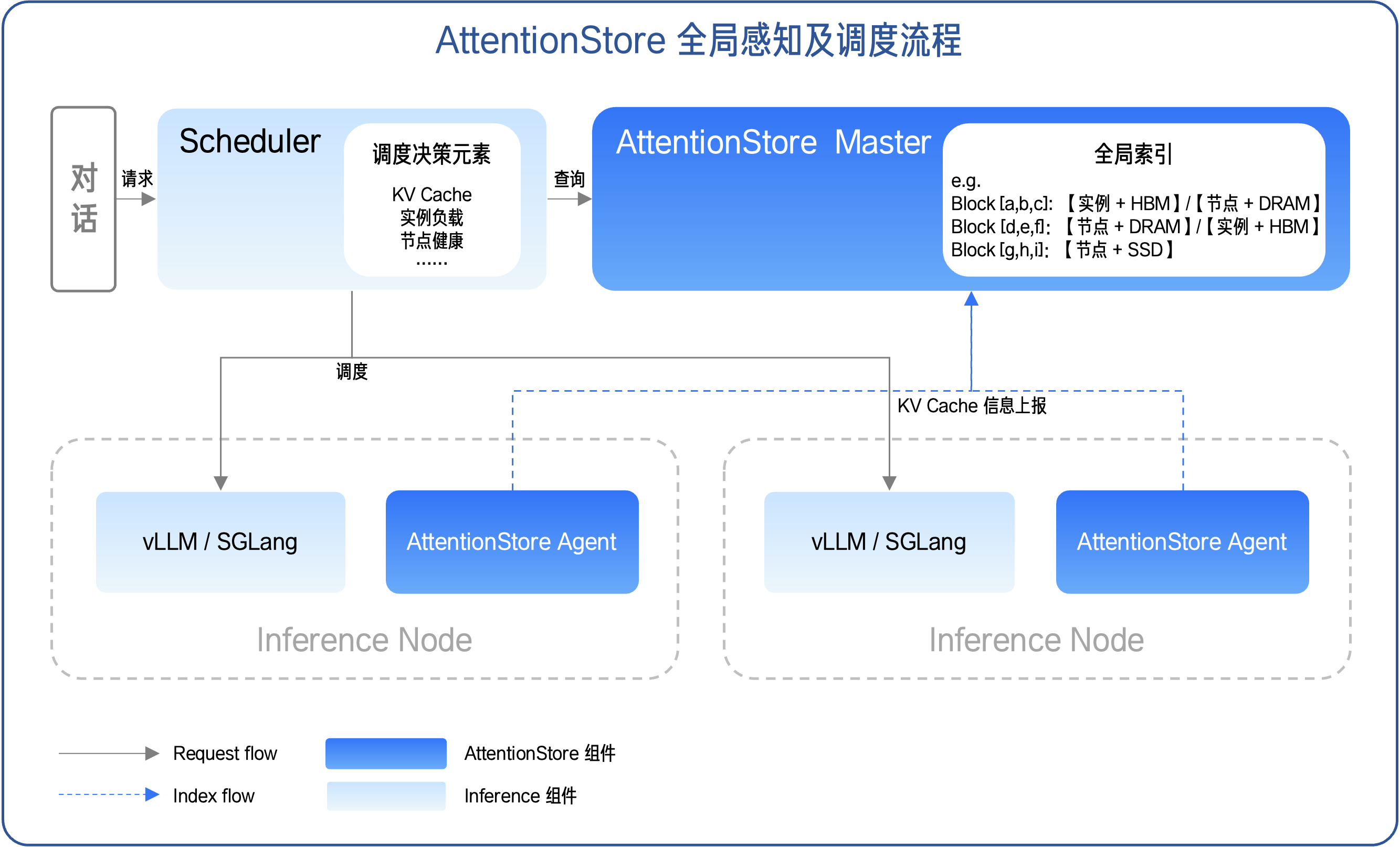
实现 KV Cache 的全局感知与精准调度,解决了长上下文推理中缓存「调度匹配」的核心问题;而在多级缓存体系中,跨介质的数据传输效率与多数据传输的并行能力,是决定 KV Cache 复用性能的另一关键因素。为此,我们通过 AttentionStore 对 KV Cache 的全生命周期数据通路进行了深度优化,构建了高效的多级缓存体系,实现跨介质数据传输的全面加速。
在典型的长文本推理场景下,KV Cache 在 HBM、DRAM、SSD 多级缓存体系中的数据流转遵循以下逻辑:
- 请求到达时,Prefill 节点优先尝试从显存 KV Cache 中匹配;
- 若显存未命中,将借助节点间的 KV Cache 池化能力快速将缓存数据迁移至目标 Prefill 节点的主机内存;仍未命中的部分则由 Prefill 节点即时计算生成;
- Prefill 节点生成的 KV 传输至 Decode 节点,并异步回写至主机内存 / SSD;
- Decode 节点在推理过程中新生成的 KV 增量,异步回写至 Prefill 节点的主机内存 / SSD。
针对上述链路中的读取、写入及传输环节,我们实施了如下针对性优化:
- 昆仑芯底层原生适配:面向昆仑芯 XPU 架构,我们进行了 AttentionStore 方案的深度适配 —— 针对 KV Cache 在显存、内存与 SSD 之间高频流转的特征,通过调用 XPU 原生 API,对数据搬运、缓存访问及执行调度等关键路径进行专项优化,从而充分发挥昆仑芯在带宽与访存效率上的硬件能力。同时,借助统一的硬件抽象与适配层,确保了底层指令集的无缝切换,由此,上层业务无需关注具体运行在何种硬件架构之上,即可获得一致的缓存复用能力与性能表现,实现了跨硬件环境的平滑运行;
- KV Cache 读取加速:在 HBM、DRAM 与 SSD 混合命中的场景下,传统的 KV Cache 读取采用串行逻辑(如下图左侧「AttentionStore 优化前」所示),这种方式的读取耗时较长。对此,我们通过将 KV Cache 的读取过程拆分为并行任务 —— 让高速介质与低速介质同步发起传输(如下图右侧「AttentionStore 优化后」所示),最大程度缩短全部 KV Cache 的读取耗时。此外,我们将 AttentionStore 管理的共享内存标记为大页内存,显著减少页表项数量,降低地址转换开销,提高内存访问效率;同时,通过全生命周期锁页操作,避免 KV Cache 数据在传输过程中被换出,减少额外的内存拷贝与页错误开销,使数据能够以更稳定、更高带宽的方式直达显存。实测显示,DRAM 到 HBM 的通信效率较基线提升了 4 倍,让 DRAM 与 SSD 中的缓存数据能够更快进入显存参与计算;
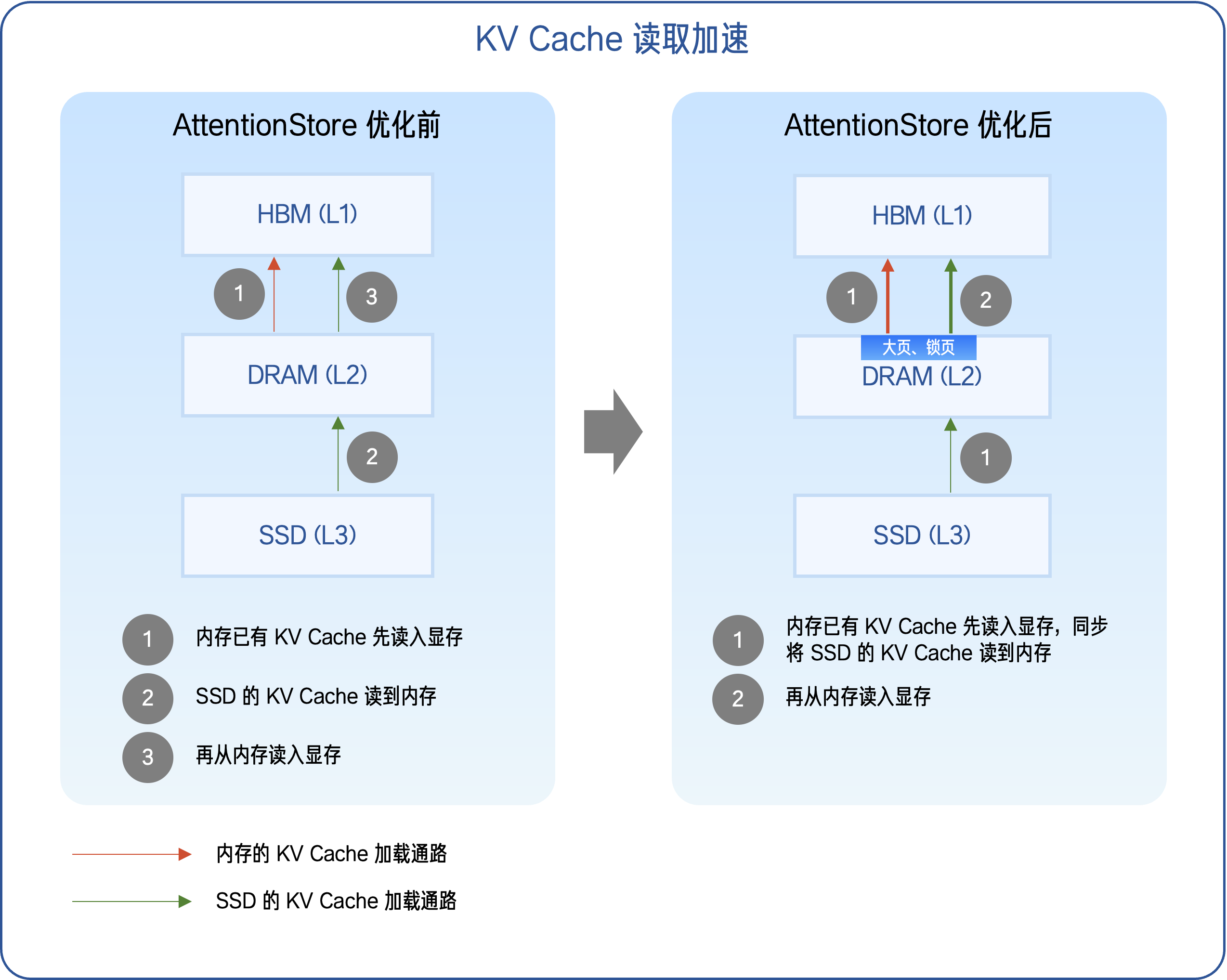
- KV 传输加速:为了提高 KV 在 Prefill-Decode 节点间的传输效率,我们首先在推理引擎之外,引入基于 C++ SDK 的高性能数据通路,对 KV Cache 的传输过程进行独立管理与优化。具体而言,通过 C++ SDK 扩展,我们将 KV 数据的序列化、打包与跨节点传输等操作从推理主进程中解耦出来,并交由独立的异步线程池负责执行,使 KV 传输与模型计算形成并行流水线,避免二者的相互阻塞。其次,在数据流传路径上,我们进一步对 KV 的回写与 P、D节点间传输流程进行了重构:传统模式下,P 节点会先将 KV Cache 完整回写至内存 / SSD,再将其传输至 D 节点;在 AttentionStore 中,我们将这一过程拆分为多个细粒度任务,通过异步机制实现「写回与传输同步进行」。借此,在保障推理任务连续执行的同时,显著提升 KV Cache 的跨节点传输效率。
3. 实践效果:超长上下文场景下的性能飞跃
在 PD 分离推理架构中,我们基于 DeepSeek R1 671B 模型,在昆仑芯 P800 集群环境中对 AttentionStore 的 KV Cache Offload 方案进行了系统验证。
环境及配置:2 台 Prefill 节点,TP4 / DP4 并行配置。
验证效果:
- 当上下文长度达到 8K 以上时,AttentionStore 的 TTFT 指标具有 50%~80% 的稳定优化收益;
- 多轮对话场景中,通过避免重复 Prefill 并提升 Prefill 节点的可复用性,系统整体吞吐量提升了 5.4 倍;
- 在 64K 长上下文场景中,相较于推理引擎默认 Chunk-Prefill 缓存策略,基于 AttentionStore 的 KV Cache Offload 方案显著减少了历史上下文的 Prefill 重算开销,使 TTFT(首 Token 时延)降低 6.2 倍;
4. 结语
Agent 将大模型推理全面带入长上下文与多轮交互时代,百度百舸的 AttentionStore 让 KV Cache 从「短暂的显存数据结构」演进为「可持久、可调度、可规模化复用的系统资源」,通过对昆仑芯底层算力的深度调优与推理框架的无缝集成,我们成功实现了更优的 TTFT 响应与更低的成本开销,为大规模国产化算力落地构筑了坚实底座。