让专有云 VPC 网络承载跨区 RDMA 存储通信,企业级智算中心 VPC 3.0 实践
作者:xxinjiang2026.05.12 14:46浏览量:97简介:VPC 3.0 将 RDMA 能力贯通到了私有化智算中心的跨区通信场景中。
从 VPC 1.0 到 VPC 3.0,百度智能云的每一次技术迭代,都不是为了技术而技术,更不是照搬默认的标准方案,而是基于业务真实场景进行设计。
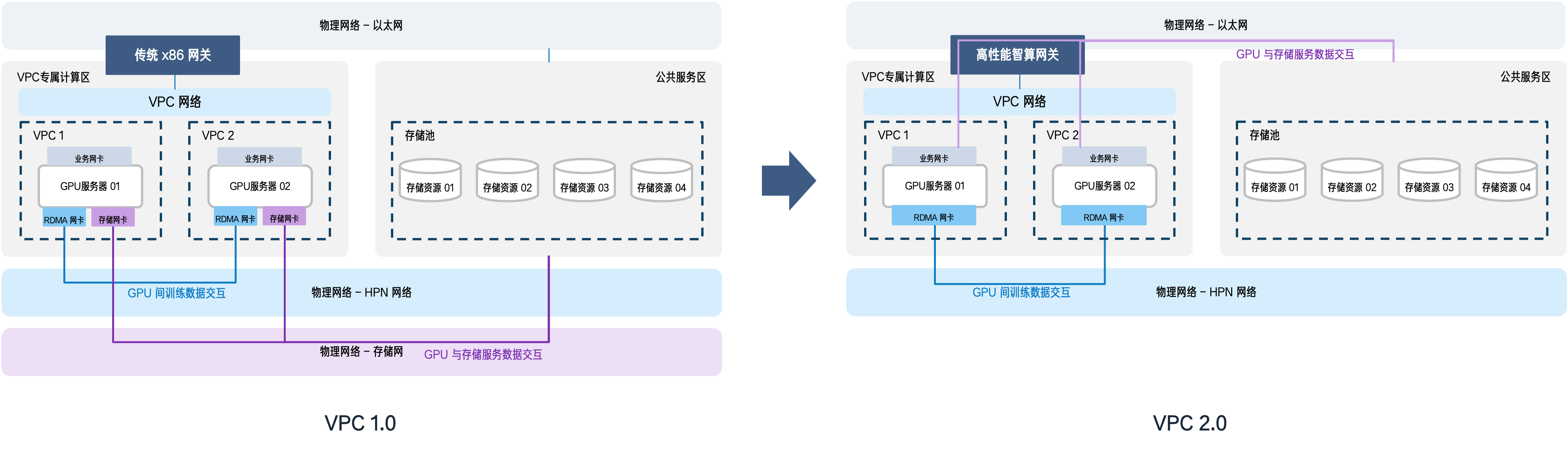
在高性能 AI 基础设施建设中,「计算与存储分区部署、独立扩展」并配套专用 RDMA 存储网络,已经成为默认方案。
然而在面向政企客户的私有化交付中,我们却反复看到一个值得深思的「资源错位」现象:很多客户对投入的成本效率高度敏感,一方面,承载通用业务的 VPC 网络长期处于低负载状态,大量带宽资源被闲置;另一方面,要搭建专用 RDMA 存储网络,又需要额外采购高性能网卡、专用交换机、低延时光纤等昂贵硬件——两边一算,总觉得这笔投入「亏得慌」。
于是,一个自然的问题浮出水面:能不能直接把现有 VPC 网络利用起来,承担存算之间的跨区通信?
基于上述思路,百度智能云在 25 年推出了企业级智算中心 VPC 2.0 方案,并在多个项目中落地。VPC 2.0 方案通过在网络中引入基于 Tofino 的高性能智算网关,将原有 VPC 的转发能力从百 Gbps 提升至 Tbps 级别,时延压缩至微秒级。
更重要的是,运维人员无需再像管理专用 RDMA 网络那样编写大量 ACL 规则,直接利用 VPC 原生的产品化能力,即可完成租户访问控制、资源隔离与灵活组网。
1. 企业级智算中心 VPC 2.0 面临的新挑战
然而 VPC 2.0 落地后、随着业务的持续运营,新的挑战随之而来。
在 AI Agent、Coding 这类推理业务中,为了支撑更快的响应,KV Cache 需要外溢至存储集群进行高频读写,这种以 IOPS 为核心的密集数据访问,对跨区网络的低延迟和传输稳定性提出了苛刻要求。
而在高强度训练场景中,业务突发流量往往会在瞬间打满存储系统(如并行文件存储 PFS),导致写 IOPS 出现明显的性能下降与毛刺。
这些问题让我们意识到:VPC 2.0 的「性能达标」已经不够了,我们需要完成一次从「能用」到「对齐专用 RDMA 存储网络」的能力跨越。
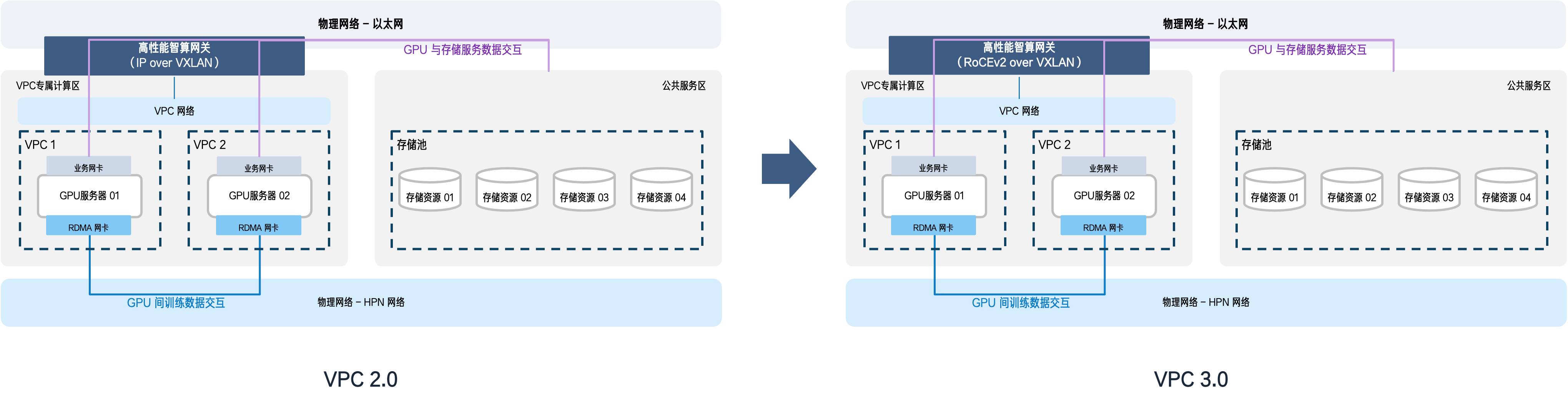
2. 企业级智算中心 VPC 3.0:让云网络也具备专用 RDMA 存储网络的性能表现
为了抹平 VPC 与专用 RDMA 存储网络之间的最后一段性能差距,我们推出了企业级智算中心 VPC 3.0 解决方案。
VPC 3.0 将 RDMA 能力贯通到了私有化智算中心的跨区通信场景中,并基于私有化业务特征优化了数据转发机制,充分降低数据传输时延,实现网关资源的极致利用。
VPC 3.0 这一方案的核心,源于我们对私有化客户的真实痛点的梳理和精准应对:
2.1 打通跨区通信的全链路 RDMA 能力
在 VPC 网络上使能 RDMA 能力,早已有弹性 RDMA 等成熟技术方案。只是,主流面向公有云的弹性 RDMA(eRDMA)解决的是 VPC 内部的通信逻辑。
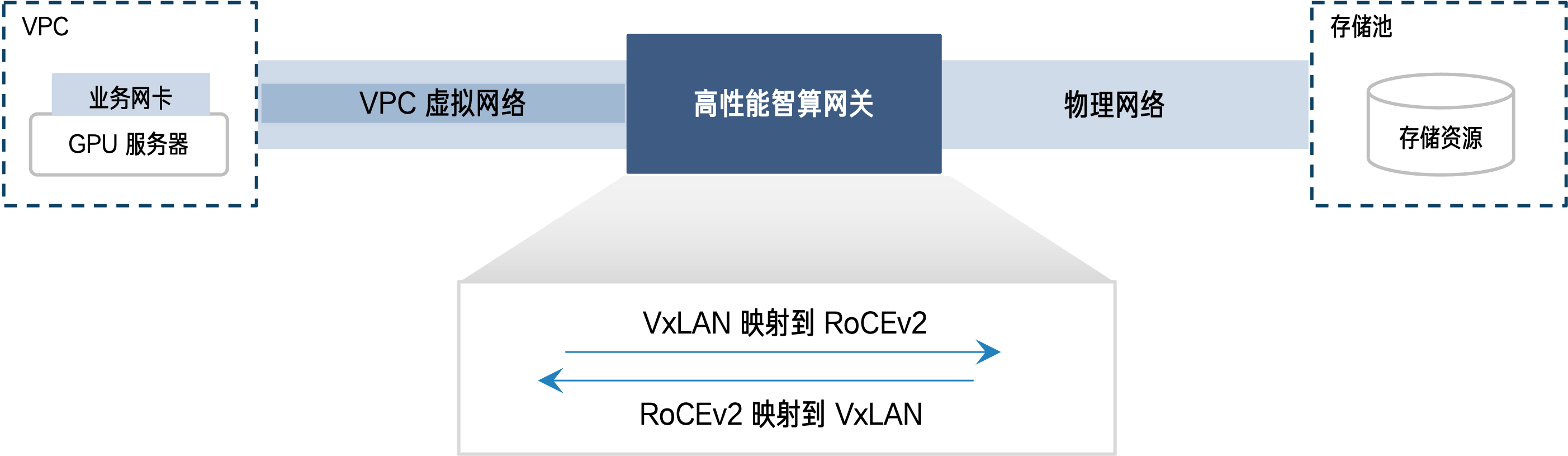
但在私有化智算中心,RDMA 流量需要穿越租户区 VPC 云网络与公共服务区物理网络——两套异构网络之间的「缝隙」,恰恰是性能损耗的高发地带。高性能智算网关不仅要打通这两张网络,还要确保流量优先级、路径选择等关键控制信息在全链路中完整、无损地传递。
对此,我们首先选择了零成本开销的 RoCEv2 协议,兼容客户现有网络体系;再利用高性能智算网关打通 VPC 虚拟网络和物理网络,借助 Tofino 硬件处理能力,完成 RoCEv2 控制标签与 VXLAN 标签的「性能零损耗」映射,让 RDMA 能力在全链路得以充分发挥。这套机制不仅保障了推理、训练等关键业务流量的优先转发,更让网络具备了准确的拥塞感知能力,有效规避网络堵塞导致的性能抖动。
此外,考虑到 RoCEv2 封装会增加报文头部开销,我们在网关层面引入了巨帧能力,支持更大 MTU 的报文传输,避免数据分片与重组带来的性能消耗。
凭借这套完整的技术方案与性能优化, AI 服务器访问存储集群的写 IOPS 提升约 40%,数据传输时延降低约 80%。至此,VPC 3.0 具备了支撑超大规模数据读写的极致性能,以及在高强度流量压力下的极致性能稳定性。
2.2 面向私有化场景的转发机制优化
私有化场景中业务虚拟机规模远小于公有云,许多为超大规模设计的默认转发机制,在私有化场景中反而会引入额外开销。
以 Tofino 芯片为例,其默认实现中数据包从接收到完成转发需要经过 4 次流水线处理——这原本是为公有云超大规模租户的复杂通信需求设计的:要么将各种功能分散在不同流水线进行串行处理,要么集合 4 条流水线来承载更大的表容量。但在政企智算中心,这套「重武装」不仅没有带来收益,反而造成了不必要的处理延迟和资源占用。
我们对高性能智算网关的转发逻辑进行了针对性优化。通过对表项空间进行精细化规划、削减不必要的容量占用,我们将原本的 4 次流水线收敛为 2 次。
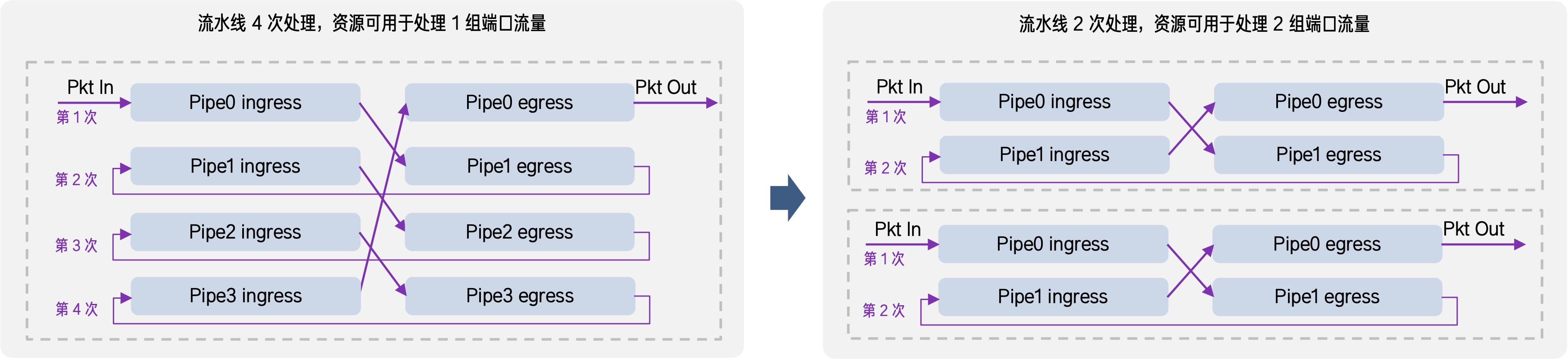
在确保各项功能完整无损的前提下,单台高性能智算网关的通信带宽再提升 1 倍,帮助政企客户削减 50% 的跨区通信组网硬件成本。
3. 结语
从企业级智算中心 VPC 1.0 到 VPC 3.0,百度智能云的每一次迭代,都不是为了技术而技术,更不是照搬默认的标准方案,而是基于业务真实场景进行设计。
VPC 2.0 时代,面对政企客户在成本与性能之间的两难抉择,我们深入分析客户业务的实际负载特征,在有限预算下将通用 VPC 网络带入了 Tbps 转发与微秒级时延的新阶段。
如今的 VPC 3.0,面对 Agentic 推理与突发流量对网络性能的极致要求,我们再次针对私有化场景的特殊性做了因地制宜的微创手术,精准对齐了政企客户对性能的极致期待。