检索、问答、情感分析场景前沿技术方案分享!
作者:番薯2021.12.31 11:04浏览量:2177简介:百度飞桨选取检索、问答、情感分析三大场景,推出面向真实应用场景的系统功能。
自然语言处理技术在各行业有着广泛的应用,然而长久以来,其落地并不是一帆风顺的。




针对这些棘手的问题,百度飞桨深耕产业界,选取NLP领域三大高频场景——检索、问答、情感分析,推出面向真实应用场景的系统功能,覆盖金融、电商零售、文娱、旅游、房地产、生活服务等多个行业,万方、荣耀、国美、驴妈妈旅游网、房天下、食行生鲜等均已基于相关方案成功完成业务上线。
语义检索系统
检索系统存在于人们日常使用的很多产品中,比如商品搜索、学术文献检索、通用搜索引擎等。传统方法匹配能力有限,只能捕捉字面匹配,而语义检索能够捕捉深层语义信息,达到更精准、更广泛地召回相似结果的目的。
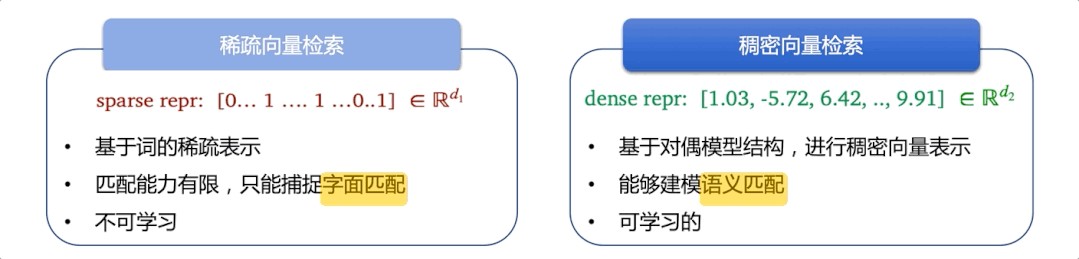
图:基于字面的稀疏向量检索 vs 基于语义的稠密向量检索
PaddleNLP本次推出语义检索系统,流程图如下,其中左侧为召回环节,核心是语义向量抽取模型;右侧是排序环节,核心是排序模型。
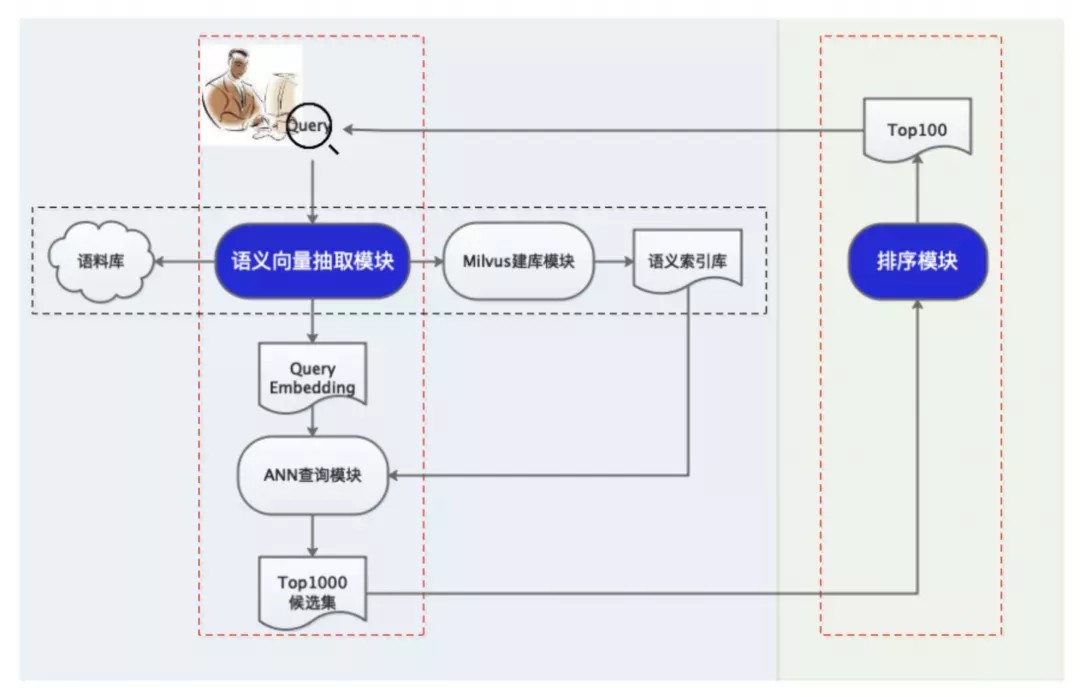
图:PaddleNLP Neural Search语义检索系统流程图
具备三大亮点:
低门槛:数据+代码+模型全部开源,无需标注数据也能够轻松构建起检索系统,并且提供训练、预测、近似最近邻(ANN)搜索一站式能力。
精度高:结合业界前沿模型和自有创新思路,推出适用多种数据情况、灵活的技术方案,精度超高。
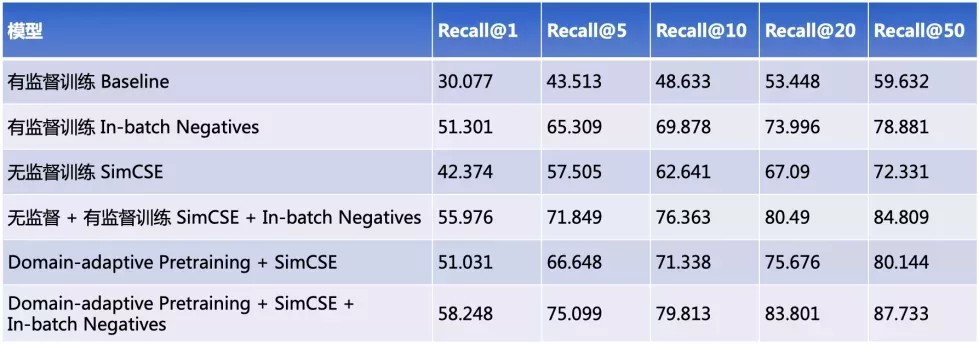
表:不同技术方案下的Recall@K指标
- 性能好:与开源向量数据库Milvus打通,结合Paddle Inference,实现高性能建库,并在千万级数据中做到毫秒级快速查询。

图:文献检索示例
前往GitHub获取开源代码和模型:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/neural_search
预训练时代的端到端问答 - RocketQA
问答系统是信息检索系统的一种高级形式,它能用准确、简洁的自然语言回答用户提出的问题,问答系统广泛应用于搜索引擎、智能设备、智能客服等产品中。
图:问答系统应用示例
传统的问答系统通常由多个模块级联组成,而在预训练时代我们可以用一个端到端模型代替传统的复杂系统,实现更好的效果。然而,研发端到端问答模型需要大量的计算和数据资源,为了使更多开发者能方便地获取最先进的问答技术,我们推出了RocketQA开发工具,有三大亮点:
- 领先:提供国际领先的端到端问答技术-RocketQA,效果远超传统问答系统,与国际知名公司的技术方案相比也有一定优势。
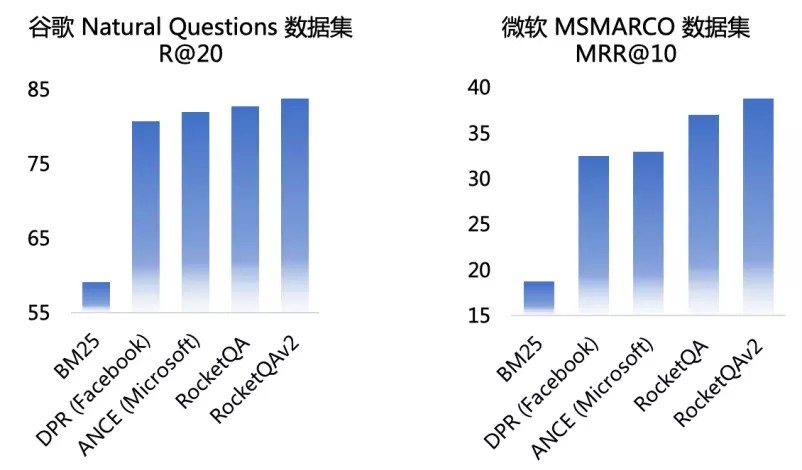
中文:开源首个中文端到端问答模型,该模型基于知识增强的预训练模型ERNIE和百万量级的人工标注数据集DuReader训练得到,效果优异。
易用:提供11种预置模型、2种安装方式和极简的开发接口,基于神经搜索框架JINA和近似近邻检索库FAISS,2行命令即可搭建自己的问答系统。

前往GitHub获取开源代码和模型:
https://github.com/PaddlePaddle/RocketQA
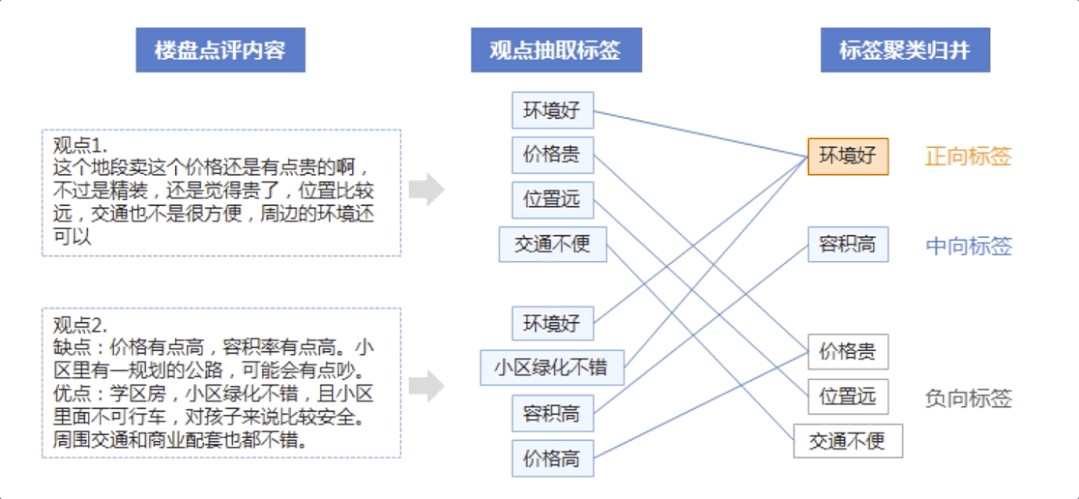
情感分析系统
情感分析旨在对带有情感色彩的主观性文本进行分析、处理、归纳和推理,其广泛应用于消费决策、舆情分析、个性化推荐等领域,具有很高的商业价值。
依托百度领先的情感分析技术,食行生鲜自动生成菜品评论标签辅助用户购买,并指导运营采购部门调整选品和促销策略;房天下向购房者和开发商直观展示楼盘的用户口碑情况,并对好评楼盘置顶推荐;国美搭建服务智能化评分系统,客服运营成本减少40%,负面反馈处理率100%。
为了降低技术门槛,方便开发者共享效果领先的情感分析技术,PaddleNLP本次开源的情感分析系统,具备三大亮点:
- 覆盖任务全:集成句子级情感分类、评论观点抽取、属性级情感分类等多种情感分析能力,并开源模型,且打通模型训练、评估、预测部署全流程。
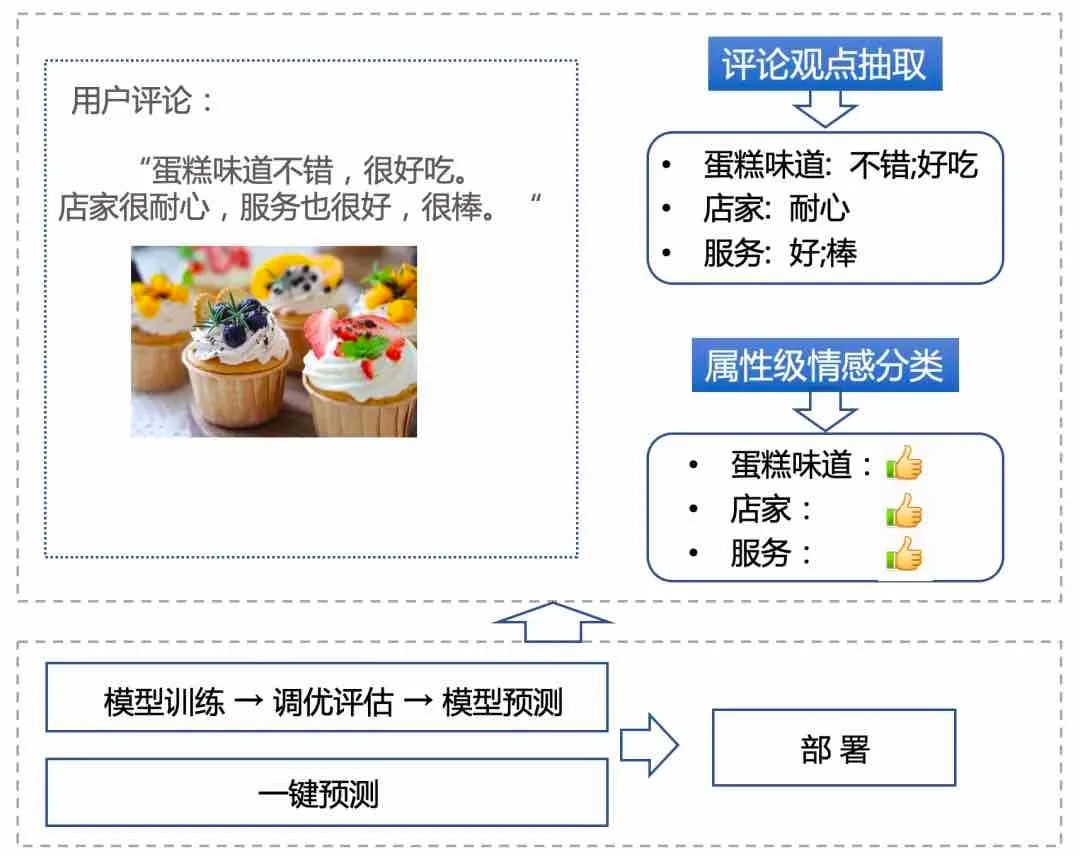
图:PaddleNLP Sentiment Analysis核心能力展示
- 效果领先:集成百度研发的基于情感知识增强的预训练模型SKEP,为各类情感分析任务提供统一且强大的情感语义表示能力。
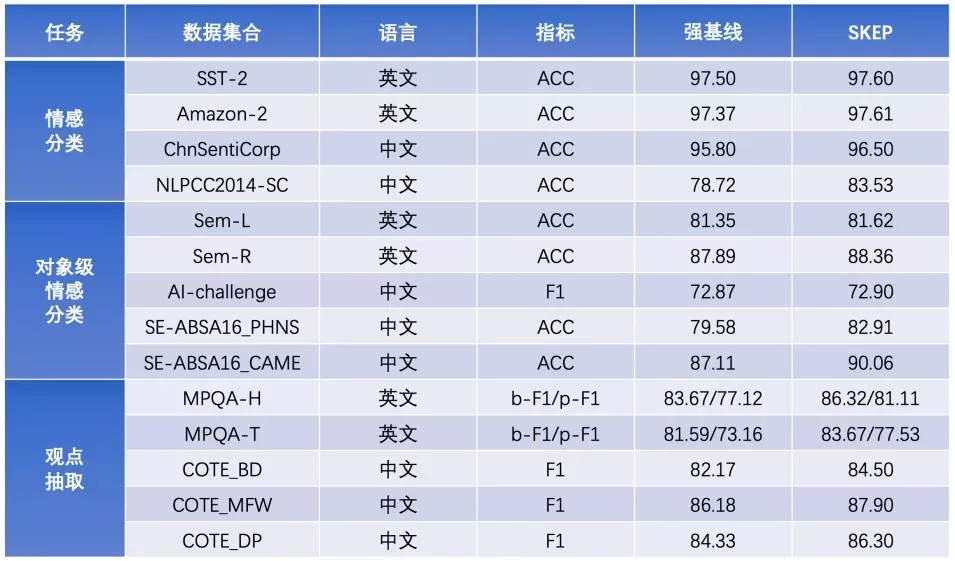
- 预测性能强:针对预训练模型预测效率低的问题,开源小模型PP-MiniLM,配套裁剪、量化优化策略,预测性能提速900%!
前往GitHub获取开源代码和模型:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/sentiment_analysis