千帆大模型沉浸式开箱之大模型训练完整历程
大模型开发/技术交流
- 社区上线
- 开箱评测
- 开源大模型
2023.10.082565看过
前言
金秋时节、叠翠流金, 秋风送爽、硕果盈枝,如果说当年百度提出All in AI只是播下了一颗种子,那今年文心一言和千帆大模型平台的发布就是当年播下的种子如今已经长成大树,开花并结出的累累硕果。从文心一言的的开花到千帆大模型平台的结果,这是百度多年努力奋斗,默默耕耘,静静沉淀的结果。或许文心一言刚发布的时候很多人并不太看好,而千帆大模型平台的发布正是很好的回应。现在外界一直说,当年百度抓住了搜索的风口,现在又抓住了人工智能这个风口。所以说,只管默默耕耘,时间会给出答案。相信百度最后会交上更多更好的答卷,会出开发出更多更好的产品。
以前我们需要在自己的业务场景或者应用中使用到人工智能相关的技术的时候,传统的做法是只能够自己从0到1去搭建一个相关的平台或者接口。传统的简单流程基本是,自己编写人工智能相关算法或者使用开源的人工智能算法或者框架进行二次开发,这只是开始,接着就是训练,大模型训练最重要的就是数据,外界一直说:数据是人工智能时代的石油。想要训练出来的模型足够优秀,就需要投喂大量的相关数据。所以这就到了关键的一步,数据收集,然后对收集到的数据进行数据处理,比如数据清洗,数据过滤,去重等等,接着进行数据标注,最后才是训练。而可能由于数据不足,模型训练的参数较少,无法足够覆盖整个应用场景,导致最后训练出来的模型,效果不尽人意。然后就会进入漫长的算法调优-训练往复的阶段。而且众所周知,训练大模型,最重要的是算力的支持,需要硬件的支持。这些都是白花花的银子。特别是对于普通开发者或者中小型企业来说,根本无法承受,或者对于看不到收益的业务,或许最后会因为这个业务导致元气大伤。特别是对于普通人,学习门槛,开发成本更高,学习路径以及开发周期更长,且你需要对编程,对算法,对大模型开发的整个流程以及开发相关的工具足够熟悉。而千帆大模型平台的发布,就能够很好帮你规避了这些难题。千帆大模型平台本身就已经预置了几十个大模型,包括很多常用的开源模型,甚至预置了很多不同行业的数据集,包括金融,医疗,法律等等。。。。根本无需为数据收集而苦恼。对于普通的开发者,甚至普通人来说,简直是福音,如果你使用场景要求不是很高,根本就无需训练可以拿来即用,或者只需要进行微调就能够满足大多的应用场景,就算需要自己训练,千帆大模型平台也是可视化操作,这大大降低了学习成本和使用门槛,平台操作简便,文档详细,就算不看文档。直接照着提示流程操作,很快就能入手。根本就是有手就行,当然你得知道你要做什么。废话不多说,言归正传,下面进入沉浸式体验千帆大模型平台大模型训练的整个流程。
大模型训练的流程
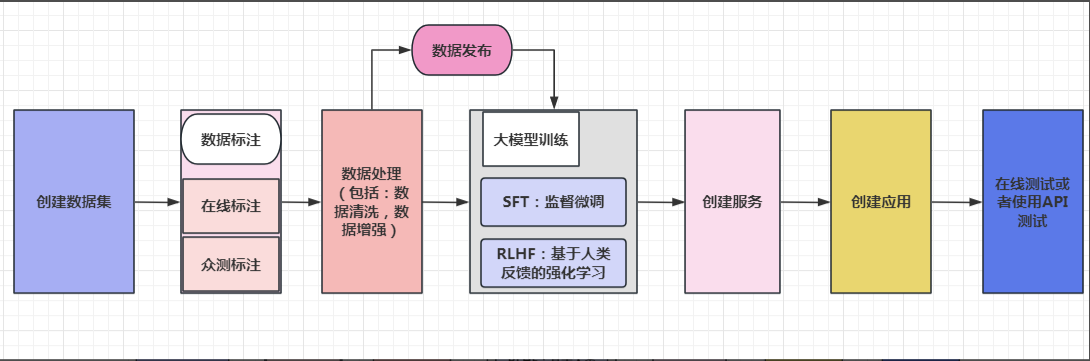
千帆大模型平台不但文档详细,就算不看文档只需直接按照控制台的提示流程,就能快速对大模型进行训练,大模型训练的基本流程如下图所示:

照着这个流程从左往右操作即可,其实就是左侧菜单从上往下操作。如图:

大模型训练实操
创建数据集
从上面的流程图来看,第一步我们需要先创建数据集,创建数据集最重要的当然是先收集数据,获取公开数据的平台常用的有好几个,比如:huggingface,和鲸,飞桨,kaggle,聚数力等等, 还有GitHub分享的一些开源数据集,或者一些博主网盘共享的数据集,这些都是日常开发常用数据获取的渠道,如果需要更加有针对性的数据,可以编写爬虫去获取或者氪金购买。获取到的数据集一定要注意数据集是否授权可商用。本文主要以开源的数据集进行演示。下面为飞桨的数据集截图:

获取到数据集之后,首先是创建数据集,即是将我们拿到的数据导入到千帆大模型平台:如下图
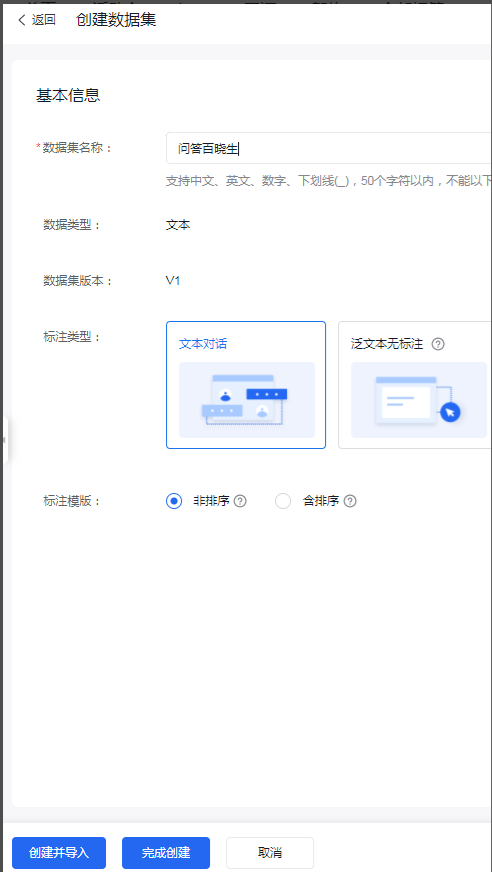
输入名称,然后点创建并导入,把我们从其他平台下载的数据集,导入千帆平台。比如我们想训练一个问答模型,我们下载的数据,如果是有问有答的两部分,说明我们的数据是有标注信息的,所以我们选择,有标注信息的选项。需要注意的是数据格式,千帆要求的导入数据格式是jsonL,所以我们需要将我们下载到数据集的格式转换为jsonL格式。
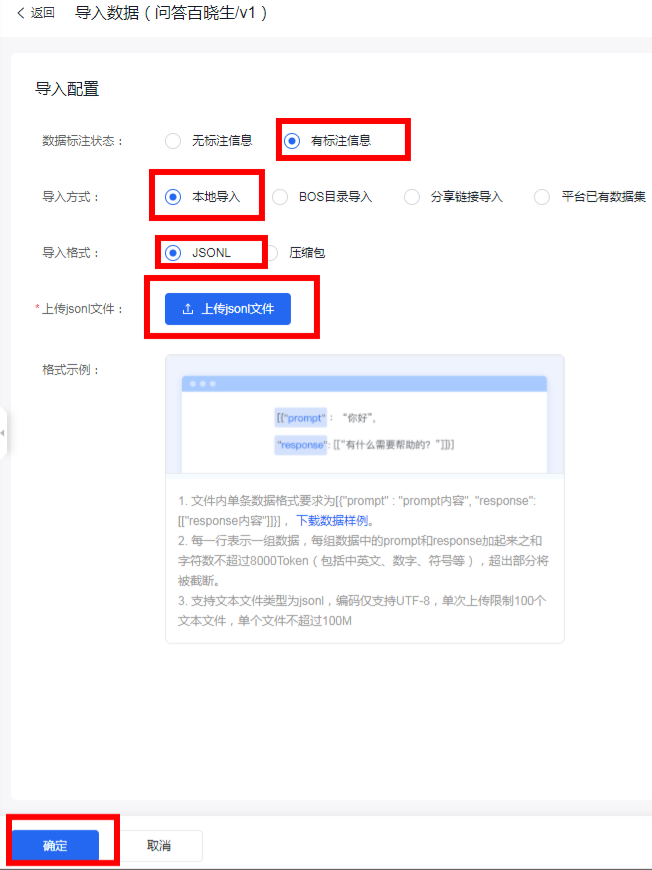
jsonL格式数据要求如下:
1. 文件内单条数据格式要求为[{"prompt" : "prompt内容", "response": [["response内容"]]}], 下载数据样例。2. 每一行表示一组数据,每组数据中的prompt和response加起来之和字符数不超过8000Token(包括中英文、数字、符号等),超出部分将被截断。3. 支持文本文件类型为jsonl,编码仅支持UTF-8,单次上传限制100个文本文件,单个文件不超过100M
数据导入可能需要一点时间,在数据集列表可以看到导入进度,完全无需任何干预,完全自动化。

导入完成会显示完成的状态

在数据集管理列表的操作栏可以看到以下操作项,如数据标注和数据处理相关选项,如下图:
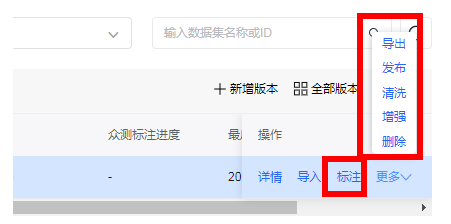
本文主要以我们常见的问答类应用场景为主.而且我们目前下载到的数据类型基本都是文本类数据。其实当前很多大模型都是以开始多模态技术,作为发展方向,多模态的大模型可以同时进行处理和分析不同模态的数据,如语音,图像,视频等等,从而使得应用程序在理解和响应用户时更加准确,全面和自然,也可以同时输出文字以外更多形式的内容。
预置数据集
我们在数据集管理的页面,还能看到一个“预置数据集”的选项。
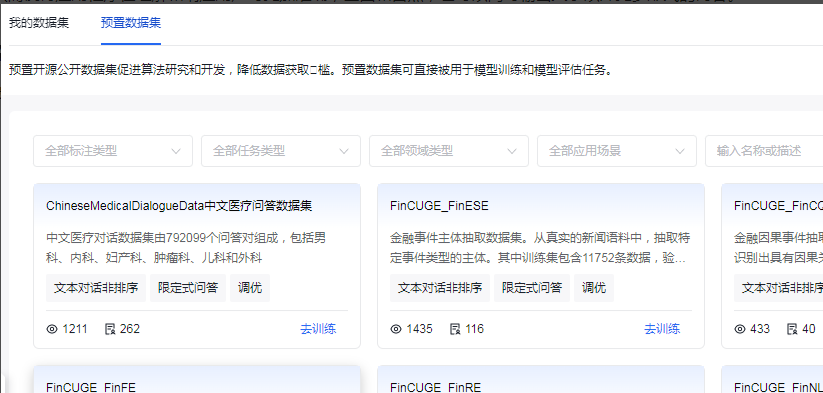
这里基本包含了不同行业所有的中文数据集,省去我们苦苦寻找数据的烦恼,如果我们要求不高,没有太多个性化的需求,完全可以使用预置的数据集进行训练自己的大模型,就算有自己个性化的需求,自己还可以对数据进行重新标注以及后续进行调优。
数据标注
数据创建完成之后就是,接下来就是数据标注了,因为我们获取到的数据集,有些问题答案时空的,没有回答,这时候我们就需要将数据补全,这就是数据标注的主要作用。数据标注分为在线标注和众测标注,在线标注你可以交给AI帮忙标注,如果你觉的AI标注的结果,你不够满意,你可以发布众测标注,交给专业的团队帮你标注。

进入在线标注,可以选择我们刚刚导入的数聚集

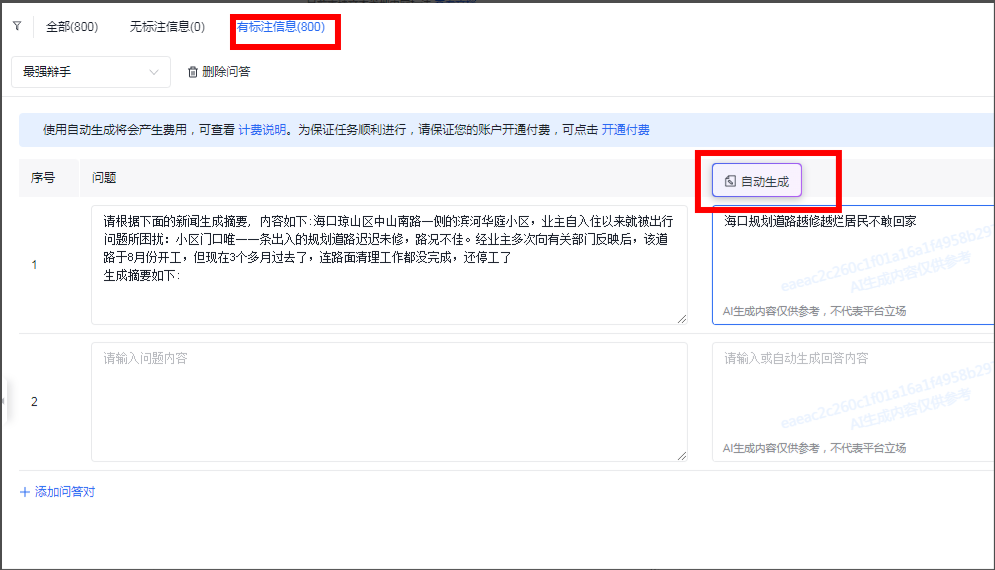
你可以选择自动生成,这个选项是由AI自动生成标注信息。不但可以对空的标注进行补全,你还可以在此页面新增问答标注。
众测标注流程
众测标注流程如下图:

数据处理
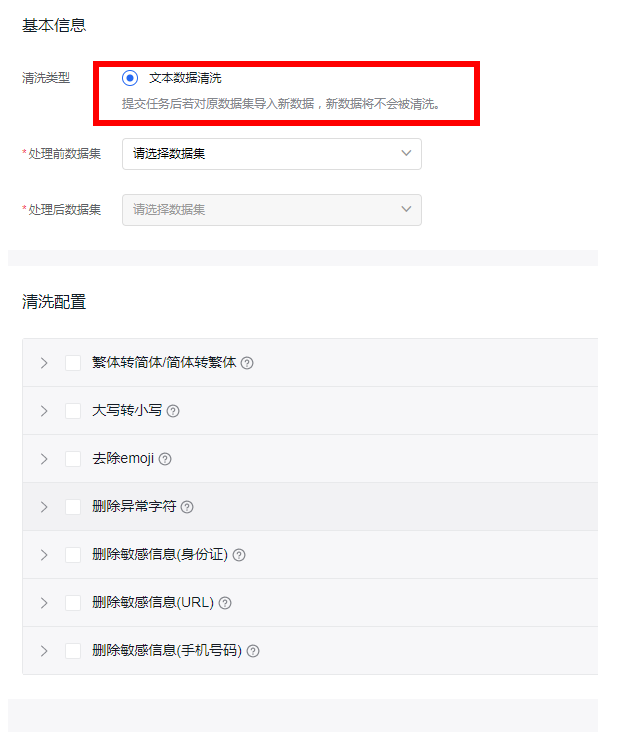
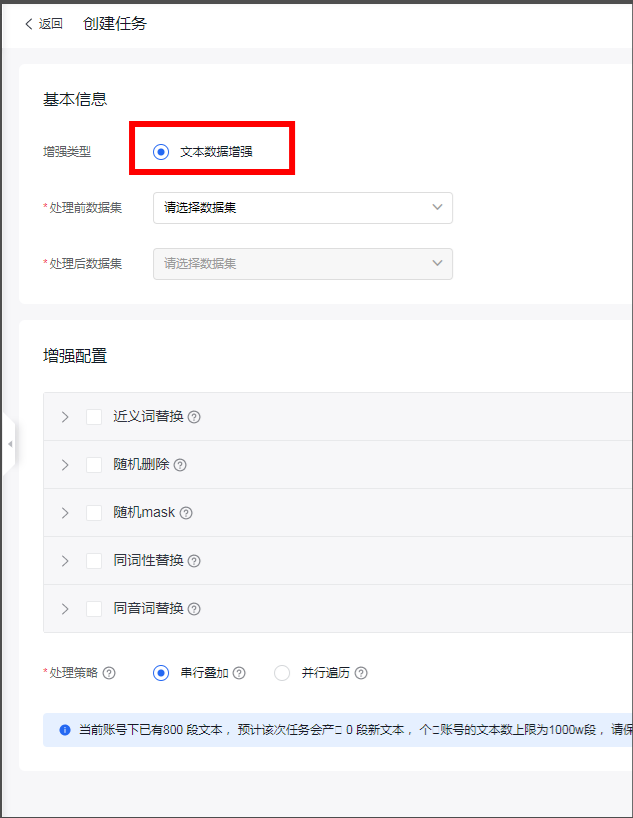
接下来就是数据处理,数据处理包括数据清洗,数据增强,如敏感数据的过滤,去重等等,特别是爬取的数据,一定要注意敏感数据的去除,如身份证,手机号以及其他个人隐私信息,以免触犯别人的隐私,还有一些个性化比较强的数据也需要按实际情况处理,避免影响模型训练的效果。
数据清理和数据增强都是可视化:如下图:

大模型训练
当我们数据处理完成后,接着就是进入重头戏--大模型训练,我们前面所做的一些都是为训练这步做铺垫,千帆大模型平台提供两种训练方式。一种是大模型微调SFT(监督微调)和RLHF(基于人类反馈的强化学习)
名词解析
什么是SFT
监督微调(SFT)是指采用预先训练好的神经网络模型,并针对你自己的专门任务在少量的监督数据上对其进行重新训练的技术。在千帆平台上已经预置了ERNIE-Bot系列大模型和BLOOM系列大模型。
SFT在大语言模型中的应用的作用
关于SFT的调优,官方已经提供了详细的文档,这里就不再赘述https://cloud.baidu.com/qianfandev/topic/267277
什么是RLHF
Reinforcement Learning from Human Feedback翻译过来即是基于人类反馈的强化学习,这也是未来几年发展极快的AI领域,他是一种强化的学习算法,通过真实的人类反馈,大幅加速语言模型的训练速度,让他更好地理解人类的真实意图,并给出更合适的响应,这可以提高模型的准确性和自然度,同时提升用户体验。关于RLHF更多介绍可以访问官方介绍:https://cloud.baidu.com/qianfandev/topic/267161
SFT训练流程如下:

我们直接创建训练任务即可


我们训练的模型一般针对国内用户,所以训练配置我们直接选择文心大模型并选择最新版本即可,如果不需要将全部参数进行更新,我们选择LoRA即可。
关于数据集的选择,我们可以选择平台已有数据集也可以选择我们自己刚创建的数据集,如下图:
当然你想要在此选择自己创建的数据集,创建好的数据集一定要记得发布,发布之后才可以使用,只有发布了才可以在选择数据集的时候看到我们自己创建的数据集。
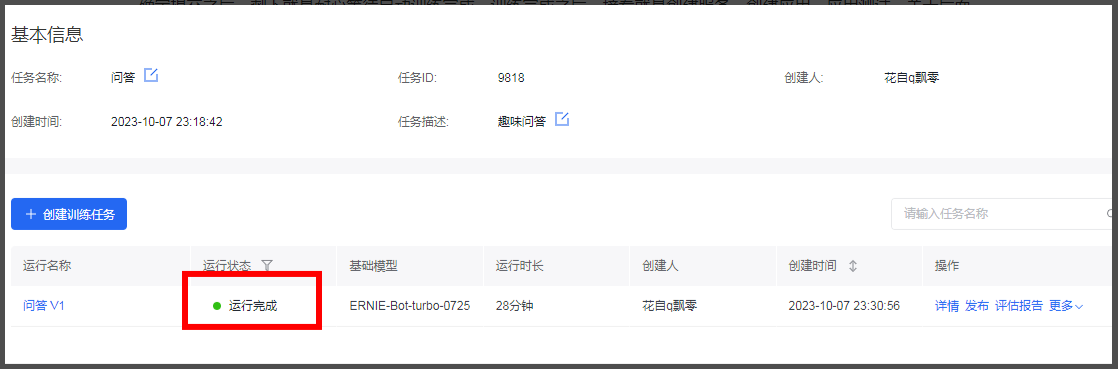
确定提交之后,剩下就是耐心等待自动训练完成,训练完成之后,接着就是创建服务,创建应用,应用测试。关于后面这三步,上一篇文章已经介绍过,这里不再赘述。训练过程中可以在详情页查看训练的进度以及其他详情,还可以将训练过程可视化展示,下图是训练完成的状态
下图为训练过程可视化图表:

以下为训练的评估报告:
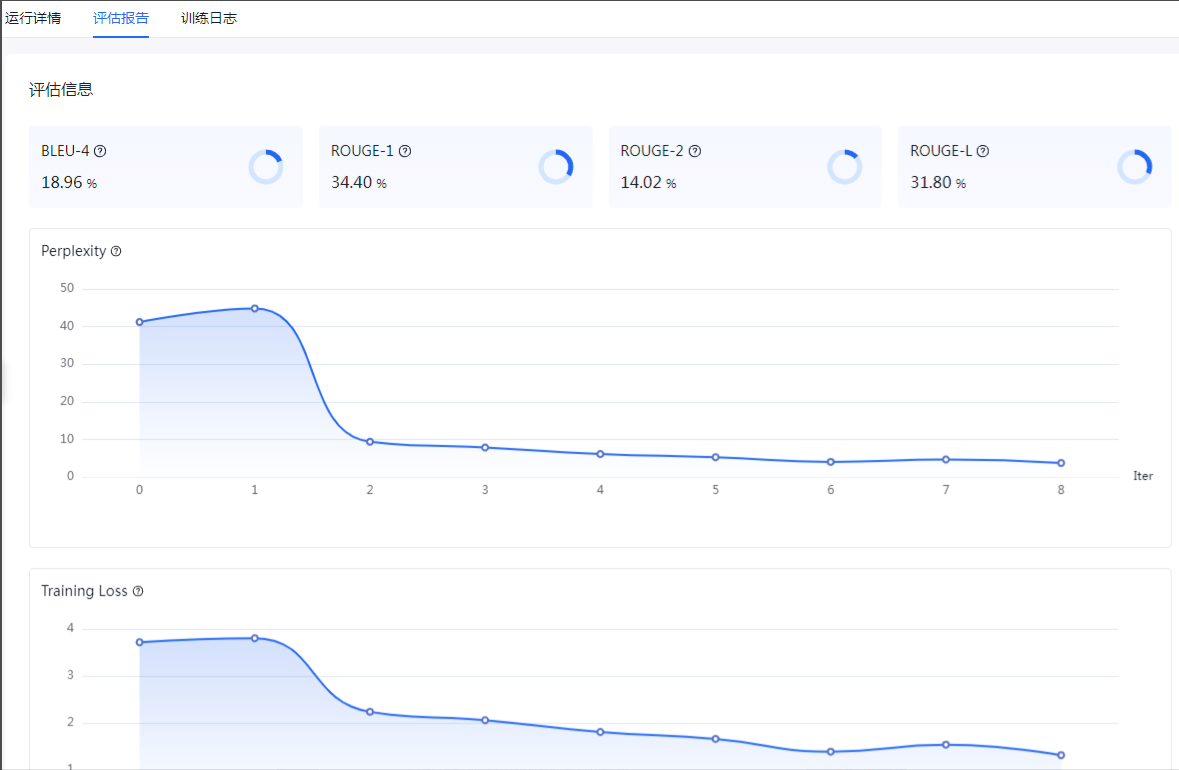
全部是可视化,极其方便,训练完成之后,接着发布训练好的模型,只有发布了才能在后续操作中使用
发布大模型
因为我们是首次发布大模型,所以我们“发布为新模型”,然后给模型起个响亮的名字,然后确定提交即可,如下图
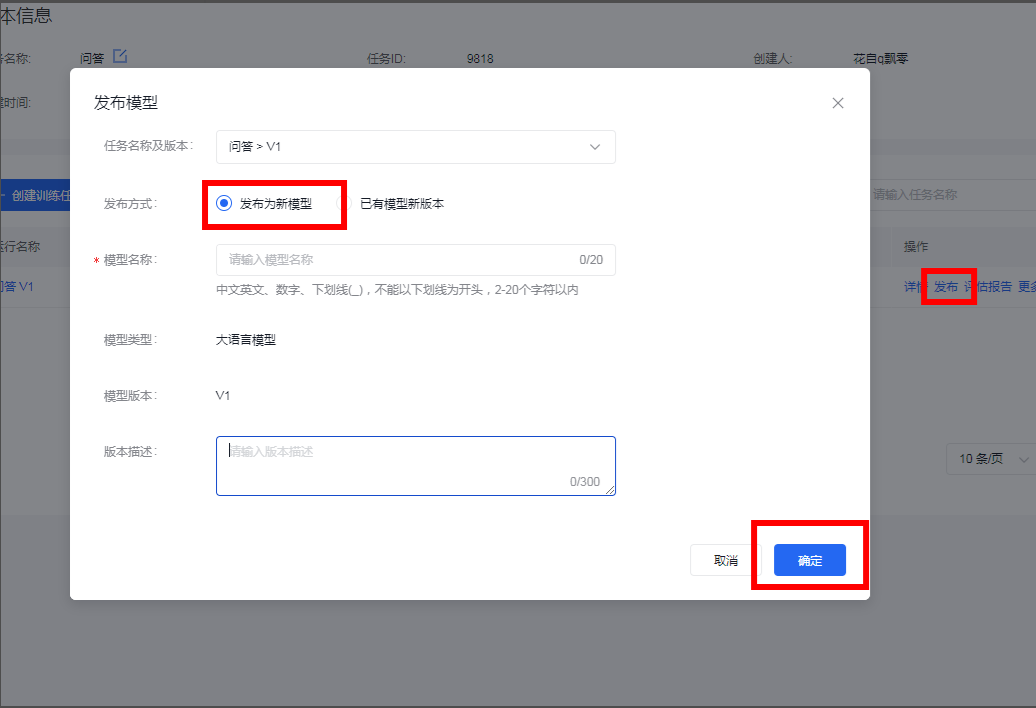
这时候我们在大模型管理界面就可以看到我们已经发布的大模型,模型开始创建,模型创建需要一定的时间,趁这间隙可以去干点别的事
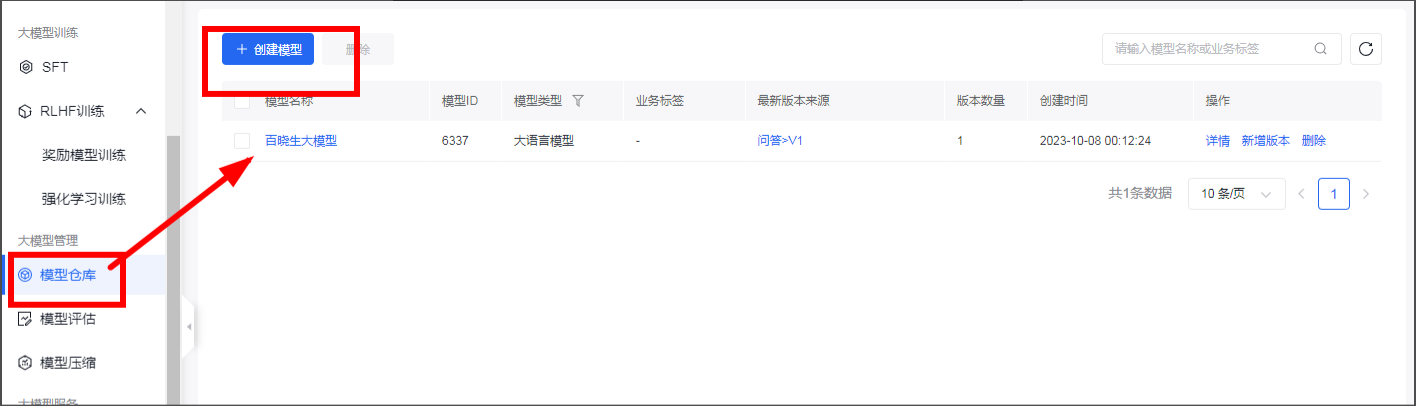
模型创建好后,状态就会从创建中变为就绪状态,这时候就可以部署我们训练好的大模型
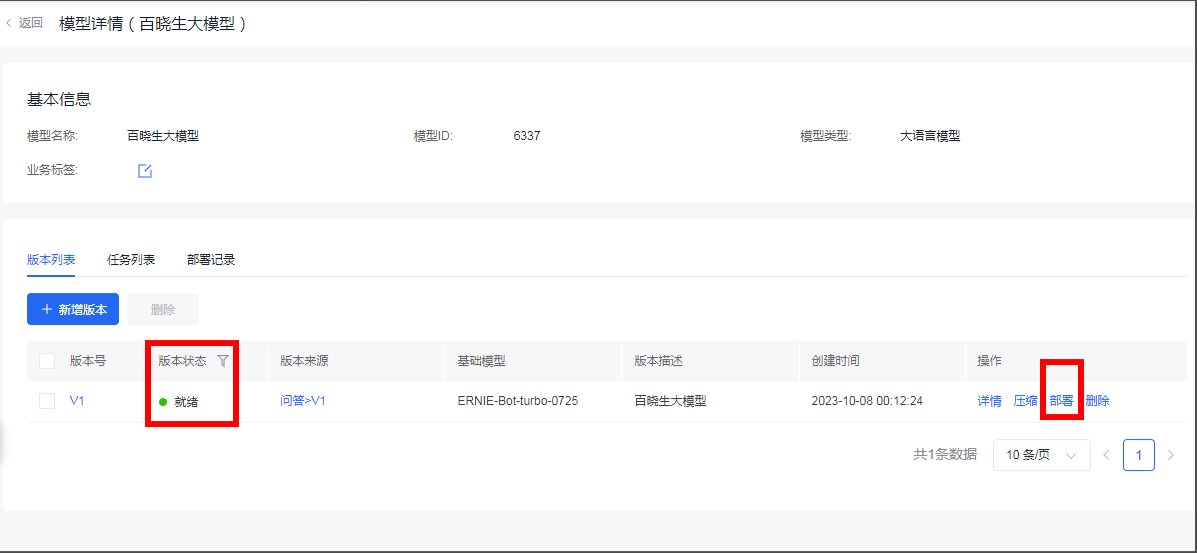
接着点击部署,就自动进入服务创建页面
大模型应用
服务创建
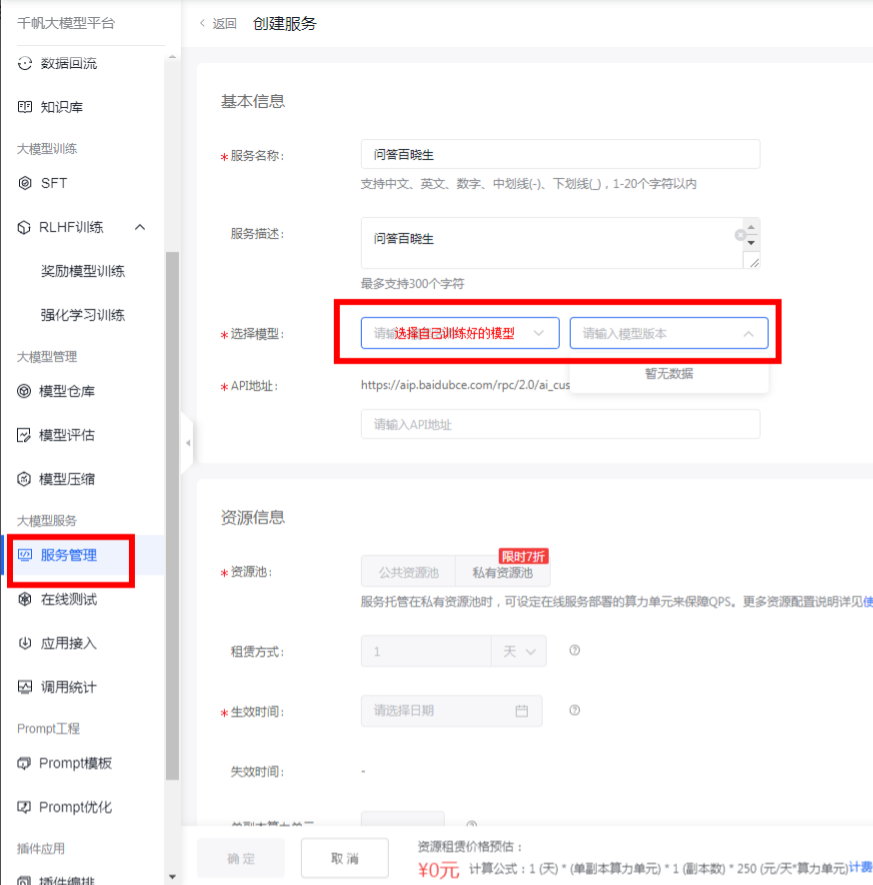
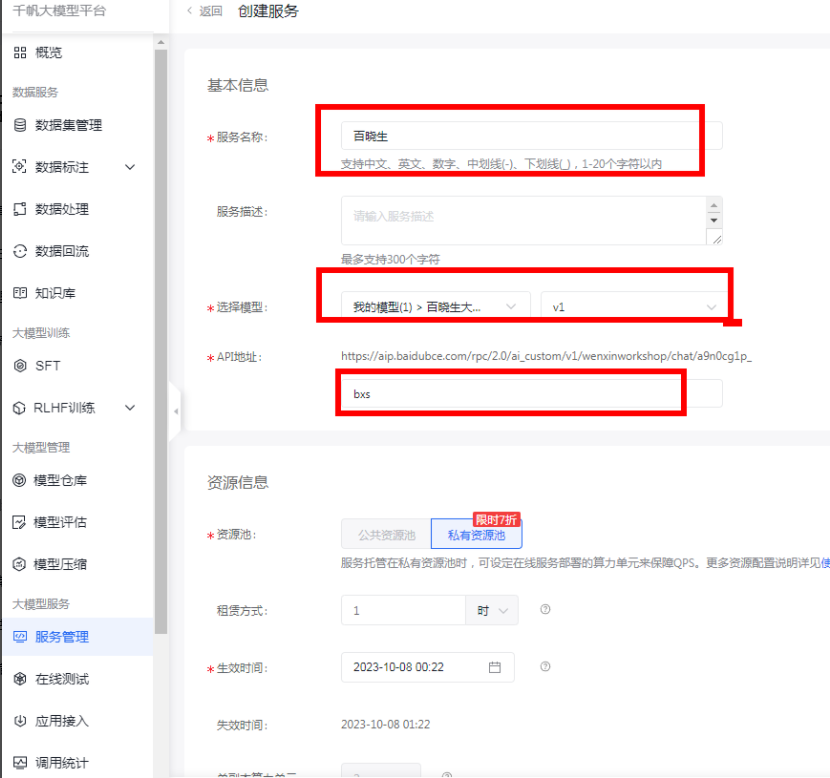
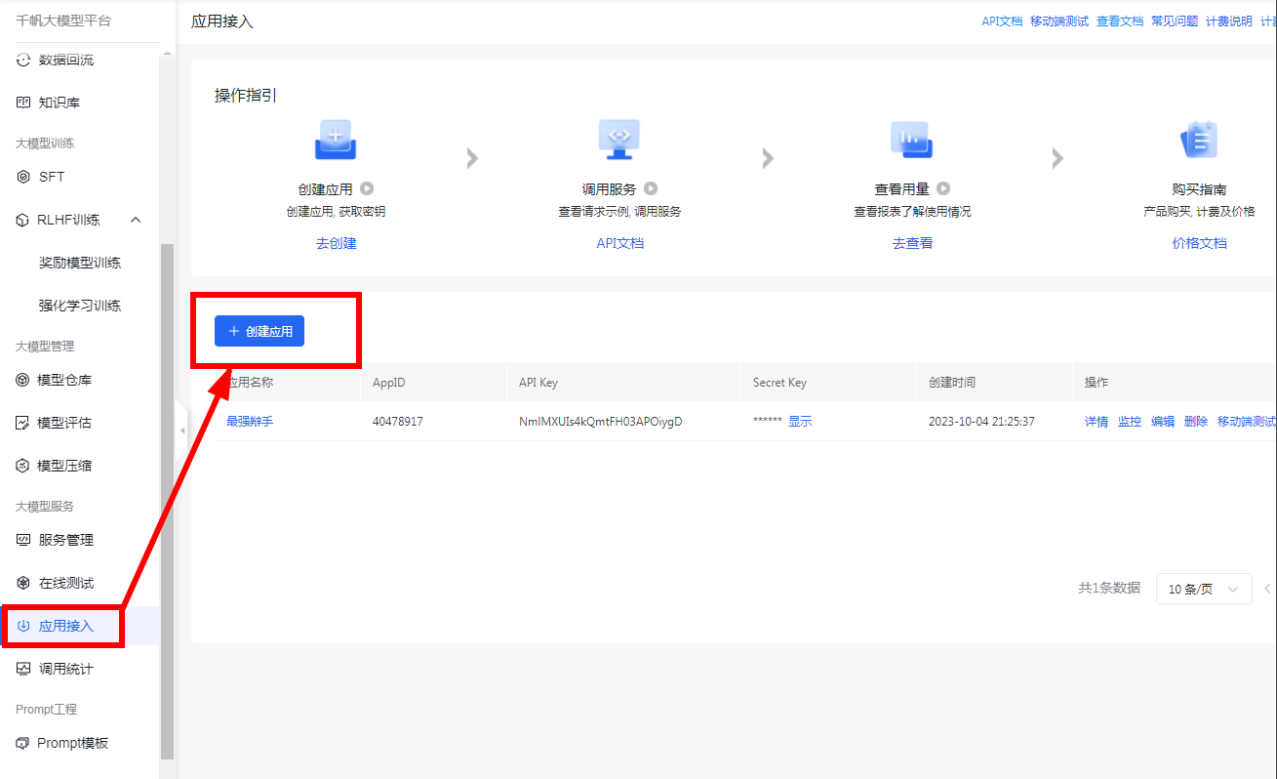
应用创建
只有创建应用才能获取到调用模型的权限
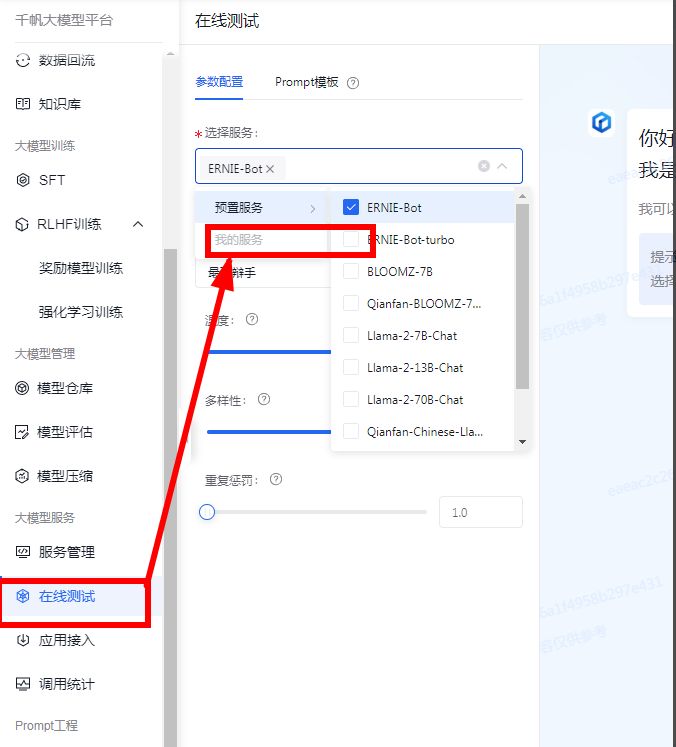
应用测试
服务和应用创建好之后,直接可以在线测试,可以选择自己创建的服务或者选择千帆预置的服务进行大模型的测试和体验。
到这里,一个完整的大模型训练就结束了,从头到尾无需编写一句代码,即可完成大模型的训练,全部可视化,自动化操作,这也体现了千帆大模型使用上快捷方便,完全是一款很好的符合大众化产品。
评论
