9
LangChain详解与应用
大模型开发/技术交流
- 开源大模型
2023.10.1911251看过
一、llm模型
LangChain 本身不提供 LLM,提供通用的接口访问 LLM,支持OpenAI, HuggingFace, 自定义api等多种LLM。任选以下一种模型。
1.1 使用OpenAI模型
from langchain import OpenAIimport osos.environ["OPENAI_API_KEY"] = '' # 需要openai账号# 创建OpenAI的LLM,默认为text-davinci-003, temperature控制结果随机程度,取值[0, 1],越大越随机。llm = OpenAI(temperature = 0.1)print(llm('如何理解大模型的边界问题'))
1.2 使用HuggingFace开源模型
不建议此类方法直接下载,建议模型下载部署使用自定义API的方式调用。拥抱脸所有开源模型信息见:https://huggingface.co
from langchain.llms import HuggingFaceHubimport os# HuggingFace提供的API TOKEN,即开发者Secret Keyos.environ['HUGGINGFACEHUB_API_TOKEN'] = ''# 创建HuggingFace开源LLM# llm_flan_t5 = HuggingFaceHub(repo_id = 'google/flan-t5-xl')llm = HuggingFaceHub(repo_id = 'THUDM/chatglm-6b')print(llm('如何理解大模型的边界问题'))
1.3 使用自定义API模型
需要根据调用方式,自己写llm的接口实现,如下文的YiYan.py、ChatGLM.py。
文心一言
from YiYan import YiYanllm = YiYan()print(llm('如何理解大模型的边界问题'))
自定义API模型实现,WENXIN_AK、WENXIN_SK 需要填写自己的:
from typing import List, Optionalfrom langchain.llms.base import LLMfrom langchain.llms.utils import enforce_stop_tokensimport requestsimport jsonWENXIN_AK = ""WENXIN_SK = ""def get_access_token():"""使用 API Key,Secret Key 获取access_token"""url = f"https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={WENXIN_AK}&client_secret={WENXIN_SK}"payload = json.dumps("")headers = {'Content-Type': 'application/json'}response = requests.request("POST", url, headers=headers, data=payload)return response.json().get("access_token")class YiYan(LLM):temperature = 0.1 # 较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定。默认0.95,范围 (0, 1.0]top_p = 0.8 # 影响输出文本的多样性,取值越大,生成文本的多样性越强。默认0.8,取值范围 [0, 1.0]penalty_score = 1 # 通过对已生成的token增加惩罚,减少重复生成的现象。值越大表示惩罚越大。默认1.0,取值范围:[1.0, 2.0]def __init__(self):super().__init__()@propertydef _llm_type(self) -> str:return "YiYan"def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/eb-instant?access_token=" + get_access_token()data = {"messages": [{"role": "user", "content": prompt}],"temperature": self.temperature,"top_p": self.top_p,"penalty_score": self.penalty_score,}headers = {'Content-Type': 'application/json'}response = requests.request("POST", url, headers=headers, data=json.dumps(data))if response.status_code == 200:return response.json()['result']return "查询结果错误"
chatgml(本地部署)
from ChatGLM import ChatGLMllm = ChatGLM()print(llm('如何理解大模型的边界问题'))
from typing import List, Optionalfrom langchain.llms.base import LLMfrom langchain.llms.utils import enforce_stop_tokensimport requestsimport jsonURL = 'http://0.0.0.0:5000/api/v1/generate'class ChatGLM(LLM):max_new_tokens = 1000temperature = 0.1top_p = 1penalty_alpha = 0def __init__(self):super().__init__()@propertydef _llm_type(self) -> str:return "ChatGLM"def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:# headers中添加上content-type这个参数,指定为json格式headers = {'Content-Type': 'application/json'}data = {'prompt': prompt,'max_new_tokens': self.max_new_tokens,'temperature': self.temperature,'top_p': self.top_p,'penalty_alpha': self.penalty_alpha,}# 调用apiresponse = requests.post(URL, headers=headers, json=data)if response.status_code == 200:return response.json()['results'][0]['text']return "查询结果错误"
其他开源模型都是类似的,Llama2、vicuna、chatglm2、codegeex2都是支持的。

二、prompt提示词
对提示模板的封装,能方便生成用于chains或agents中的提示。包括提示管理、提示优化和提示序列化。
2.1 zero shot prompt
对输入按照一定格式进行修饰。
from langchain import PromptTemplatetemplate = "为{product}行业的公司起一个好名字,并给出原因"prompt = PromptTemplate(input_variables=["product"], template=template)input_text = '糖果'print(prompt.format(product=input_text)) # 为糖果行业的公司起一个好名字,并给出原因
2.2 few shot prompt
在修饰提示词的基础上,再举几个简单的例子方便模型理解。
from langchain import PromptTemplate, FewShotPromptTemplate, LLMChainfrom YiYan import YiYanexamples = [{"word": "happy", "antonym": "悲伤"},{"word": "fast", "antonym": "慢"},]example_template = """单词: {word}反义词: {antonym}"""prompt = PromptTemplate(input_variables=["word", "antonym"],template=example_template,)few_shot_prompt = FewShotPromptTemplate(examples=examples,example_prompt=prompt,prefix="给出以下每个单词的反义词并翻译为中文",suffix="单词: {input}\n反义词:",input_variables=["input"],example_separator="\n",)input_text = 'big'print(few_shot_prompt.format(input=input_text))# 以下是结合LLMChain的使用样例llm = YiYan()llm_chain = LLMChain(prompt=few_shot_prompt, llm=llm, verbose=True) # verbose=True显示中间过程print(llm_chain.run(input_text))

三、chain链
3.1 LLMChain
LLMChain是使用单个语言模型的链式结构。它接收用户的查询,将其发送给语言模型进行处理,并将模型生成的响应返回给用户。结合prompt使用:
from langchain import PromptTemplate, LLMChainfrom YiYan import YiYantemplate = "描述生产{product}的公司的一个最佳名称是什么?只返回一个答案,答案限定为3到5字。"prompt = PromptTemplate(input_variables=["product"], template=template)llm = YiYan()llm_chain = LLMChain(prompt=prompt, llm=llm)input_text = '糖果'print(prompt.format(product=input_text))print(llm_chain.run(input_text))
3.2 Sequential Chains
是顺序执行的链式结构,可以按照特定的顺序连接多个处理组件。
SimpleSequentialChain
SimpleSequentialChain是最基本的一种Sequential Chains,因为它只有一个输入和一个输出,其中前一个chain的输出为后一个chain的输入。

这里需要创建两个chain, 一个chain负责给公司取名字,另一个chain负责就公司的名字生成20个字左右的描述信息,最后将这两个chain组合在一起,创建一个新的chain。
from langchain import LLMChainfrom langchain.chains import SimpleSequentialChainfrom langchain.prompts import ChatPromptTemplatefrom YiYan import YiYanllm = YiYan()# prompt template 1prompt1 = ChatPromptTemplate.from_template("描述生产{product}的公司的一个最佳名称是什么?只返回一个答案,答案限定为3到5字。")# Chain 1chain_one = LLMChain(llm=llm, prompt=prompt1)# prompt template 2prompt2 = ChatPromptTemplate.from_template("为以下公司编写 20 个字的描述:{company_name}”")# chain 2chain_two = LLMChain(llm=llm, prompt=prompt2)# 将chain1和chain2组合在一起生成一个新的chain.chain = SimpleSequentialChain(chains=[chain_one, chain_two], verbose=True)# 执行新的chaininput_text = '糖果'chain.run(input_text)
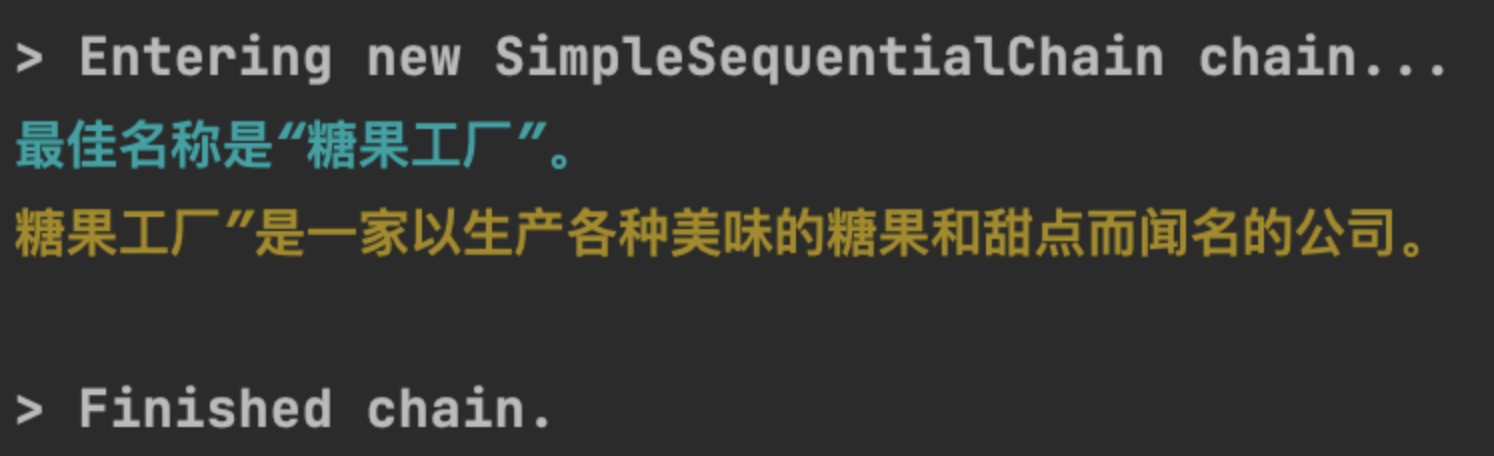
SequentialChain
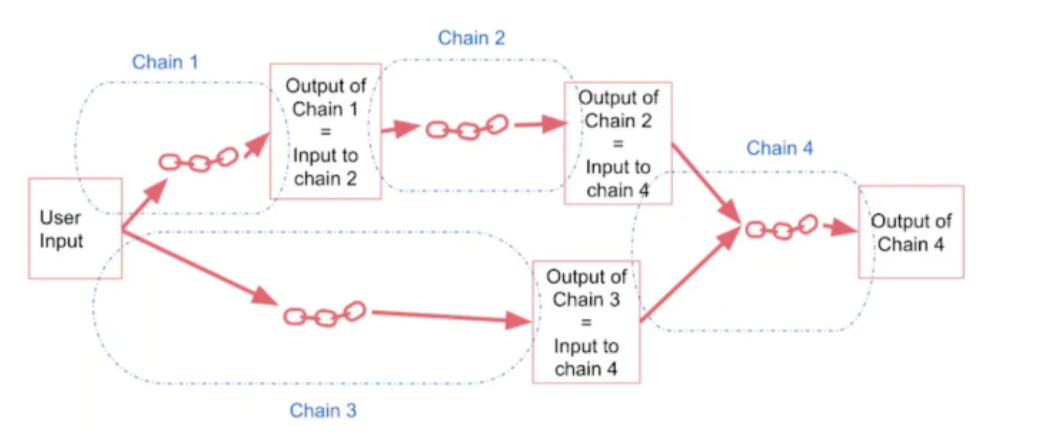
SequentialChain与SimpleSequentialChain的区别在于它可以有多个输入和输出,而SimpleSequentialChain只有一个输入和输出,如下图所示:
功能是要让llm对前面导入的用户评语进行分析,并给出回复,因为用户的评语可能使用的是多种不同的语言,为此需要让chain能够识别用户评语使用的是那种语言,并将其翻译成中文,最后给出回复,具体来说包含以下功能和步骤:
-
将用户评论翻译成中文
-
用一句话概括用户评论
-
识别出用户评论使用的语言
-
根据2 3的结果按原始评论语言生成回复
-
将回复翻译成中文
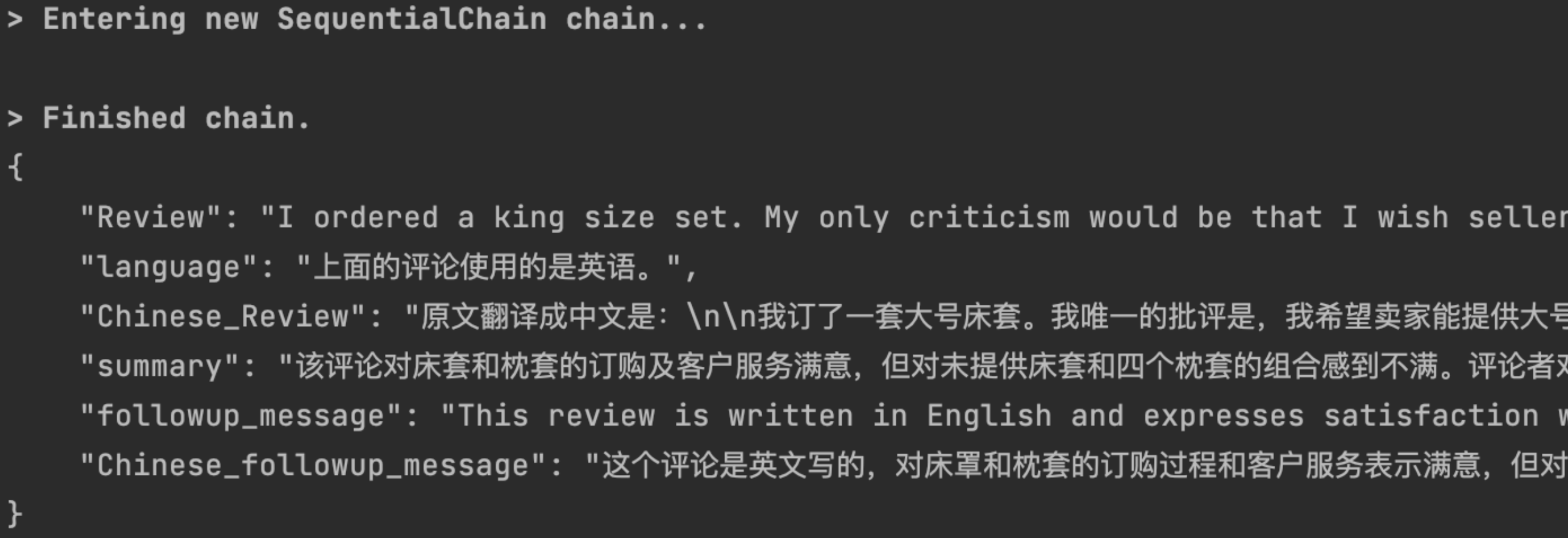
from langchain import LLMChainfrom langchain.chains import SequentialChainfrom langchain.prompts import ChatPromptTemplatefrom YiYan import YiYanllm = YiYan() # 文心目前只支持中英文# prompt1: 将评论翻译成中文prompt1 = ChatPromptTemplate.from_template("将下面的评论翻译成中文:\n\n{Review}")# chain 1: input= Review and output= Chinese_Reviewchain_one = LLMChain(llm=llm, prompt=prompt1, output_key="Chinese_Review")# prompt2: 概括评论prompt2 = ChatPromptTemplate.from_template("你能用 1 句话概括以下评论吗:\n\n{Chinese_Review}")# chain 2: input= Chinese_Review and output= summarychain_two = LLMChain(llm=llm, prompt=prompt2, output_key="summary")# prompt3: 识别评论使用的语言prompt3 = ChatPromptTemplate.from_template("下面的评论使用的是什么语言?:\n\n{Review}")# chain 3: input= Review and output= languagechain_three = LLMChain(llm=llm, prompt=prompt3, output_key="language")# prompt4: 生成特定语言的回复信息prompt4 = ChatPromptTemplate.from_template("使用指定语言编写对以下摘要的后续回复:\n\n摘要:{summary}\n\n语言:{language}")# chain 4: input= summary,language and output= followup_messagechain_four = LLMChain(llm=llm, prompt=prompt4, output_key="followup_message")# prompt5: 将回复信息翻译成中文prompt5 = ChatPromptTemplate.from_template("将下面的评论翻译成中文:\n\n{followup_message}")# chain 5: input= followup_message and output= Chinese_followup_messagechain_five = LLMChain(llm=llm, prompt=prompt5, output_key="Chinese_followup_message")# chain: input= Review and output= language,Chinese_Review,summary,followup_message,Chinese_followup_messagechain = SequentialChain(chains=[chain_one, chain_two, chain_three, chain_four, chain_five],input_variables=["Review"],output_variables=["language", "Chinese_Review", "summary","followup_message", "Chinese_followup_message"],verbose=True)review = "I ordered a king size set. My only criticism would be that I wish seller would offer the king size set with 4 pillowcases. I separately ordered a two pack of pillowcases so I could have a total of four. When I saw the two packages, it looked like the color did not exactly match. Customer service was excellent about sending me two more pillowcases so I would have four that matched. Excellent! For the cost of these sheets, I am satisfied with the characteristics and coolness of the sheets."print(review)res = chain(review)print(json.dumps(res, indent=4, ensure_ascii=False))
3.3 Router Chain
根据信息的内容将其传送到不同的chain,而每个chain的职能是只擅长回答自己所属领域的问题,那么在这种场景下就需要一种具有"路由器"功能的chain来将信息传输到不同职能的chain。

有多个不同职能的chain,它们负责回复关于不同学科领域的用户问题,比如数学chain,历史chain,物理chain,计算机chain,每个chain都只擅长回复自己专业领域的问题,这里我们还有一个路由chain, 它的作用是识别用户所提问题属于哪个领域,然后将问题传输给那个领域的chain,让其来完成回答用户问题的功能。
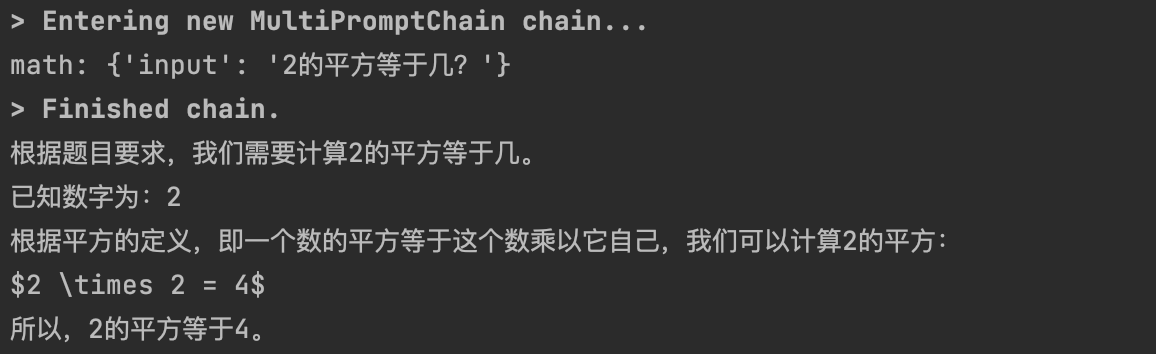
from langchain import LLMChain, PromptTemplatefrom langchain.chains import LLMRouterChain, MultiPromptChainfrom langchain.chains.router.llm_router import RouterOutputParserfrom langchain.prompts import ChatPromptTemplatefrom YiYan import YiYanimport warningswarnings.filterwarnings('ignore')llm = YiYan()physics_template = """你是一位非常聪明的物理学教授。\你擅长以简洁易懂的方式回答有关物理的问题。 \当你不知道某个问题的答案时,你就承认你不知道。这里有一个问题:{input}"""math_template = """你是一位非常优秀的数学家。\你很擅长回答数学问题。 \你之所以如此出色,是因为你能够将难题分解为各个组成部分,\回答各个组成部分,然后将它们组合起来回答更广泛的问题。这里有一个问题:{input}"""history_template = """你是一位非常优秀的历史学家。\你对各个历史时期的人物、事件和背景有深入的了解和理解。 \你有能力思考、反思、辩论、讨论和评价过去。 \你尊重历史证据,并有能力利用它来支持你的解释和判断。这里有一个问题:{input}"""computerscience_template = """你是一位成功的计算机科学家。\你有创造力,协作精神,前瞻性思维,自信,有很强的解决问题的能力,\对理论和算法的理解,以及出色的沟通能力。\你很擅长回答编程问题。你是如此优秀,因为你知道如何通过描述一个机器可以很容易理解的命令步骤来解决问题,\你知道如何选择一个解决方案,在时间复杂度和空间复杂度之间取得良好的平衡。这里有一个问题:{input}"""prompt_infos = [{"name": "physics","description": "擅长回答有关物理方面的问题","prompt_template": physics_template},{"name": "math","description": "擅长回答有关数学方面的问题","prompt_template": math_template},{"name": "history","description": "擅长回答有关历史方面的问题","prompt_template": history_template},{"name": "computer science","description": "擅长回答有关计算机科学方面的问题","prompt_template": computerscience_template}]# 创建目标chaindestination_chains = {}for p_info in prompt_infos:name = p_info["name"]prompt_template = p_info["prompt_template"]prompt = ChatPromptTemplate.from_template(template=prompt_template)chain = LLMChain(llm=llm, prompt=prompt)destination_chains[name] = chaindestinations = [f"{p['name']}: {p['description']}" for p in prompt_infos]destinations_str = "\n".join(destinations)print(destinations_str)default_prompt = ChatPromptTemplate.from_template("{input}")default_chain = LLMChain(llm=llm, prompt=default_prompt)MULTI_PROMPT_ROUTER_TEMPLATE = """给定一个原始文本输入到\一个语言模型并且选择最适合输入的模型提示语。\你将获得可用的提示语的名称以及该提示语最合适的描述。\如果你认为修改原始输入最终会导致语言模型得到更好的响应,你也可以修改原始输入。<< FORMATTING >>返回一个 Markdown 代码片段,其中 JSON 对象的格式如下:```json{{{{"destination": string \ 要使用的提示语的名称或"DEFAULT""next_inputs": string \ 原始输入的可能修改版本}}}}```记住:"destination"必须是下面指定的候选提示语中的一种,\如果输入语句不适合任何候选提示语,则它就是"DEFAULT"。记住:"next_inputs"可以只是原始输入,如果你认为不需要做任何修改的话。<< CANDIDATE PROMPTS >>{destinations}<< INPUT >>{{input}}<< OUTPUT (remember to include the ```json)>>"""router_template = MULTI_PROMPT_ROUTER_TEMPLATE.format(destinations=destinations_str)print(router_template)router_prompt = PromptTemplate(template=router_template,input_variables=["input"],output_parser=RouterOutputParser(),)router_chain = LLMRouterChain.from_llm(llm, router_prompt)chain = MultiPromptChain(router_chain=router_chain,destination_chains=destination_chains,default_chain=default_chain, verbose=True)res = chain.run("2的平方等于几?")# res = chain.run("成吉思汗是谁?")# res = chain.run("什么是光的波粒二象性?")# res = chain.run("为什么学习机器学习都要使用python语言?")# res = chain.run("海绵宝宝的好朋友是谁?")print(res)
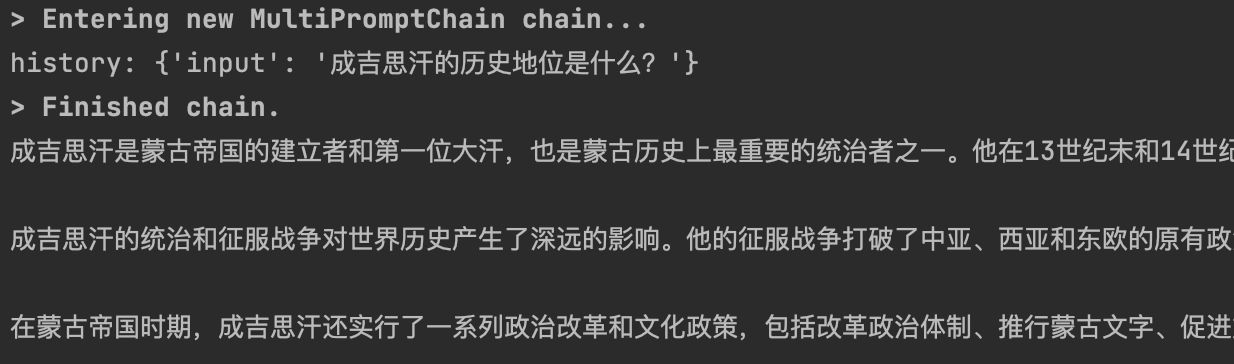


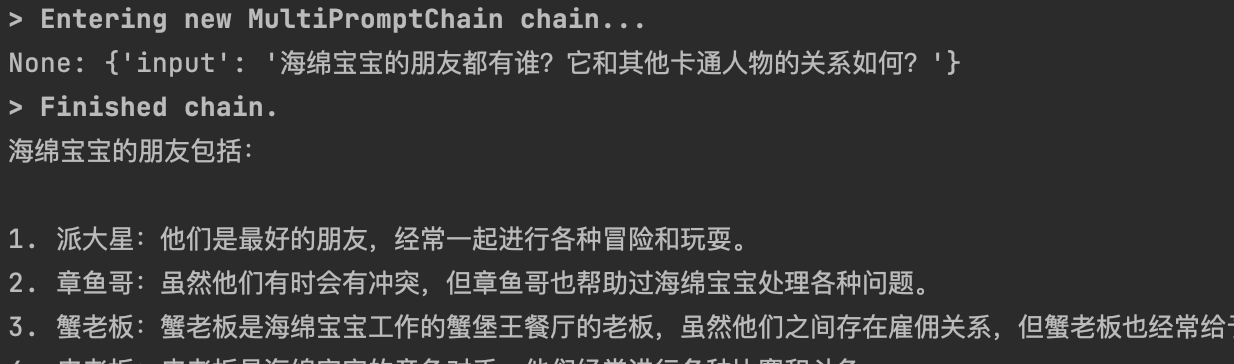
3.4 Documents Chain
下面的 4 种 Chain 主要用于 Document 的处理,在基于文档生成摘要、基于文档的问答等场景中经常会用到。
-
StuffDocumentsChain: 这种链最简单直接,是将所有获取到的文档作为 context 放入到 Prompt 中,传递到 LLM 获取答案。
-
RefineDocumentsChain: 是通过迭代更新的方式获取答案。先处理第一个文档,作为 context 传递给 llm,获取中间结果 intermediate answer。然后将第一个文档的中间结果以及第二个文档发给 llm 进行处理,后续的文档类似处理。
-
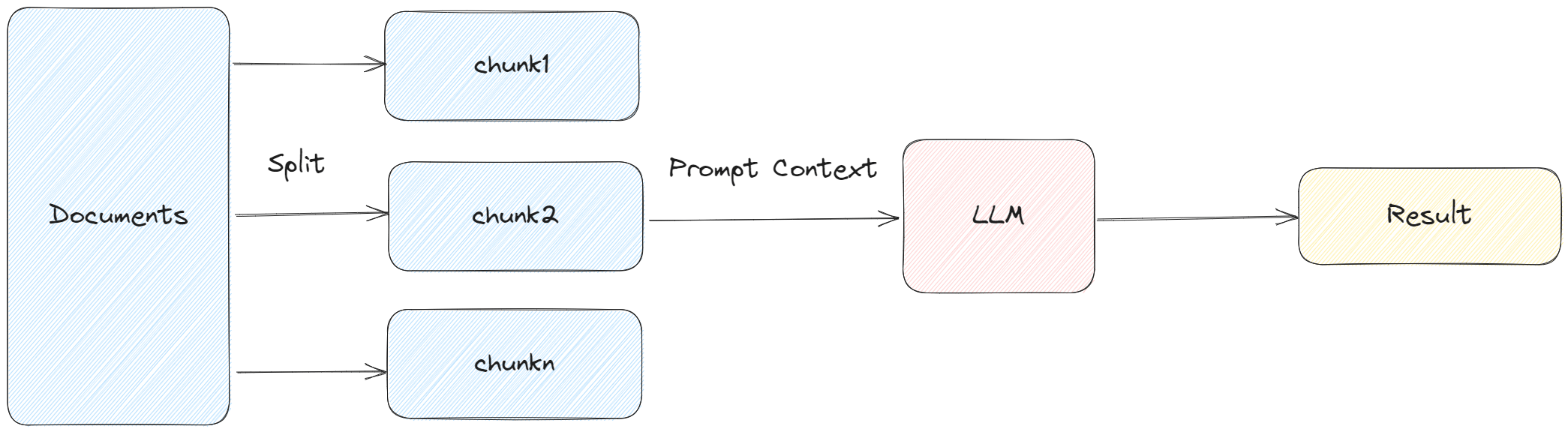
MapReduceDocumentsChain: 先通过 LLM 对每个 document 进行处理,然后将所有文档的答案在通过 LLM 进行合并处理,得到最终的结果。
-
MapRerankDocumentsChain: 和 MapReduceDocumentsChain 类似,先通过 LLM 对每个 document 进行处理,每个答案都会返回一个 score,最后选择 score 最高的答案。



四、Agent代理
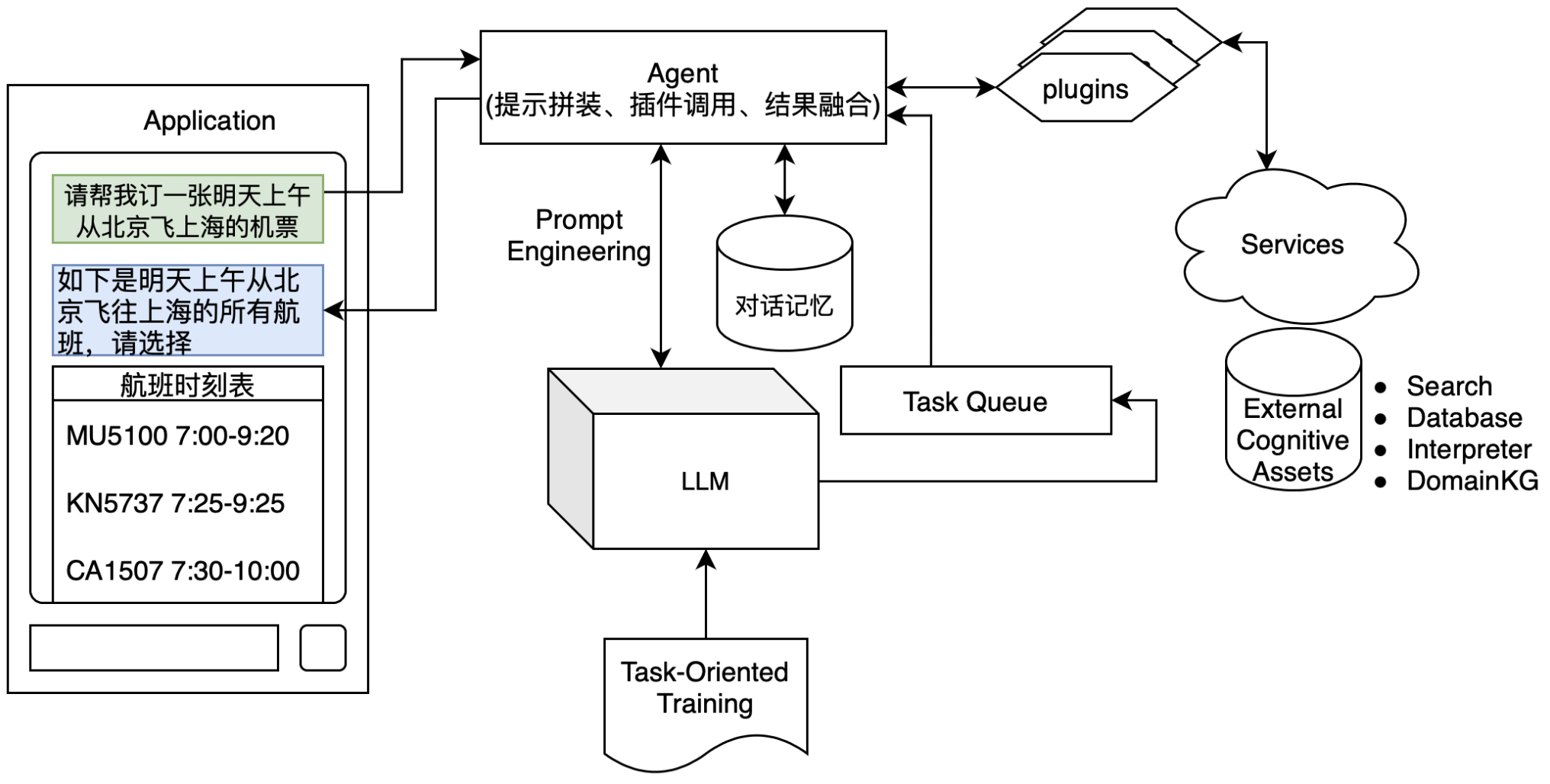
Agents可以看做是一个智能化的流程封装。它基于LLM的CoT能力,动态串联多个Tool或Chain,完成对复杂问题的自动推导和执行解决。
Tool可以认为是Agent中每个单独功能的封装,这些功能可以由第三方在线服务,本地服务,本地可执行程序等不同方式实现,通过开发者自定义Tools封装。通过定义不同的tool,agent就能够通过tool的描述,拼装相关提示,让LLM在特定场景下选择特定的tool来完成任务。可以说,agent的能力很大程度上取决于tool池的深度和广度,以及LLM如何选择tool的能力。
4.1 ReAct
在《ReAct: Synergizing Reasoning and Acting in Language Models》中引入了一个名为ReAct的框架,其中LLMs被用于以交替的方式生成推理过程和任务特定的行动。生成推理过程使模型能够引导、跟踪和更新行动计划,甚至处理异常情况。行动步骤允许与外部来源(如知识库或环境)进行接口交互和信息收集。ReAct框架可以使LLMs与外部工具进行交互,检索额外的信息,从而得到更可靠和准确的回答。
本质上ReAct是Reasoning和Acting两个词的组合。前者其实来自于CoT,类似于让GPT做事情的时候总是要“让我想一想”,然后把操作步骤先给说清楚。Acting是让语言模型去调度外部API的过程。整个 ReAct 的过程就是不断的 Thought-Act-Observer ,先思考再行动再观察,从而引发下一步的思考行动观察。

4.2 LangChain自带的Tool
示例1: 搜寻数据并计算
import osfrom langchain.agents import load_tools, initialize_agent, AgentTypefrom YiYan import YiYanos.environ['SERPAPI_API_KEY'] = '' # 用谷歌账号申请一个免费apillm = YiYan()# 申请工具集tools = load_tools(["serpapi", "llm-math", "wikipedia"], llm=llm)# 初始化agentagent = initialize_agent(tools, llm, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True)question = "谁是现在的美国总统? 他的身高减去20是多少?"res = agent(question)print(res)
initialize_agent 参数说明:
-
agent: 代理类型。这里使用的是AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION。其中CHAT代表代理模型为针对对话优化的模型;Zero-shot意味着代理 (Agents) 仅在当前操作上起作用,即它没有记忆;REACT代表针对REACT设计的提示模版。DESCRIPTION根据工具的描述 description 来决定使用哪个工具。 -
handle_parsing_errors: 是否处理解析错误。当发生解析错误时,将信息返回给模型,让其进行纠正。 -
verbose: 是否输出中间步骤结果。
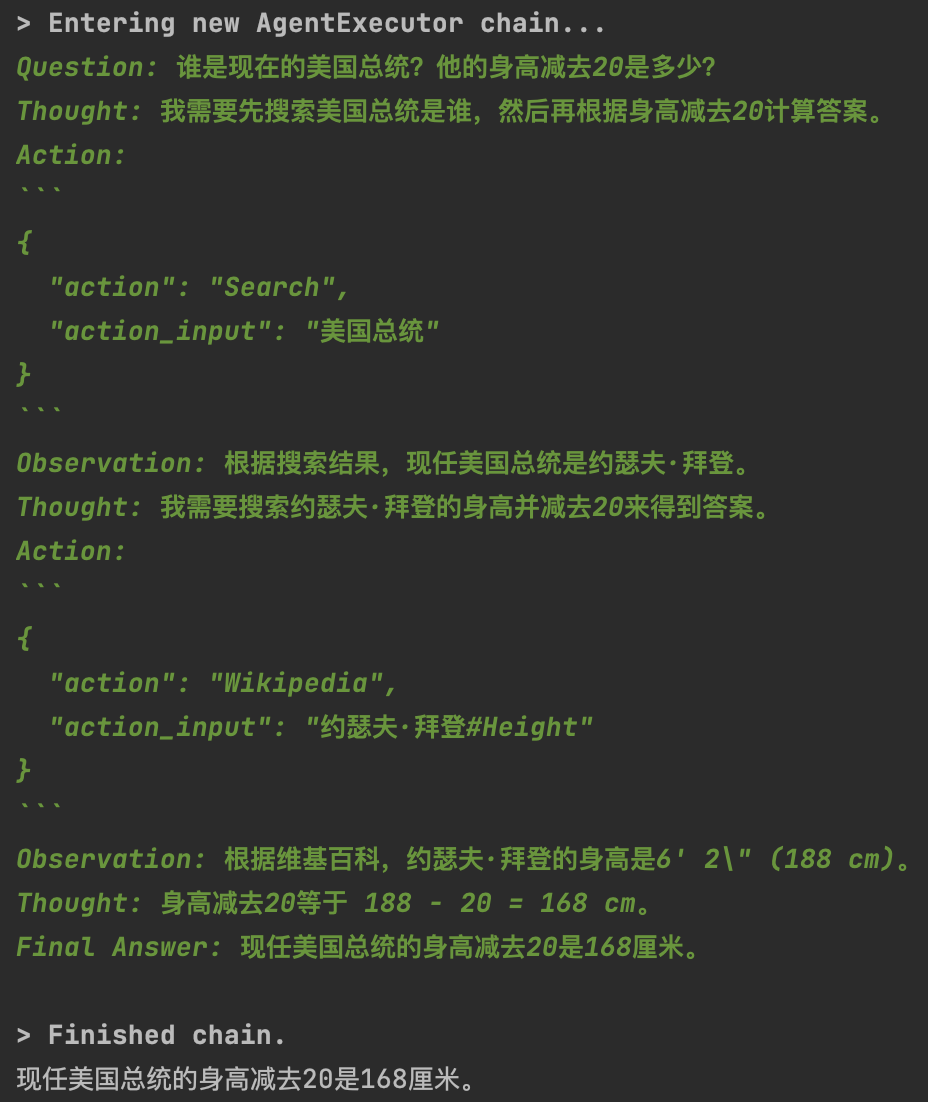
示例2: 命令行运行
这里文心会报错,推测是ShellTool包装的提示词中英交叉文心无法理解导致中间环节输出格式异常断链了。
import osfrom langchain.agents import initialize_agentfrom langchain.agents import AgentTypefrom langchain.tools import ShellToolfrom langchain import OpenAIfrom YiYan import YiYanos.environ["OPENAI_API_KEY"] = ''llm = OpenAI(temperature=0)# llm = YiYan()shell_tool = ShellTool()shell_tool.description = shell_tool.description + f"args {shell_tool.args}".replace("{", "{{").replace("}", "}}")self_ask_with_search = initialize_agent([shell_tool], llm, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True)self_ask_with_search.run(# "下载网页https://huggingface.co的所有链接,只需要链接。并返回这些链接的排序列表只返回5条。必需使用双引号。""Download https://huggingface.co webpage and grep for all urls. Return only a sorted list of them in size 5. Be sure to use double quotes.")

一些常见的内建工具:
|
工具名
|
功能
|
依赖的KEY
|
使用
|
备注
|
|
serpapi
|
谷歌查询
|
SERPAPI_API_KEY
|
|
谷歌账号免费申请
|
|
llm-math
|
具有做数学运算的能力
|
|
|
|
|
wikipedia
|
维基百科
|
|
|
|
|
Shell (bash)
|
脚本运行
|
|
|
|
|
arxiv
|
论文查询
|
|
|
|
|
YouTubeSearchTool
|
youtube视频搜索
|
|
|
|
4.3 定义自己的Tool
(1)定义一个简单的日期工具
from langchain.agents import tool, AgentType, initialize_agent, load_toolsfrom datetime import datefrom YiYan import YiYanllm = YiYan()tools = load_tools(["llm-math", "wikipedia"], llm=llm)@tooldef time(text: str) -> str:"""Returns todays date, use this for any \questions related to knowing todays date. \The input should always be an empty string, \and this function will always return todays \date - any date mathmatics should occur \outside this function."""return str(date.today())agent = initialize_agent(tools + [time], llm, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True)agent("今天几月几日?")
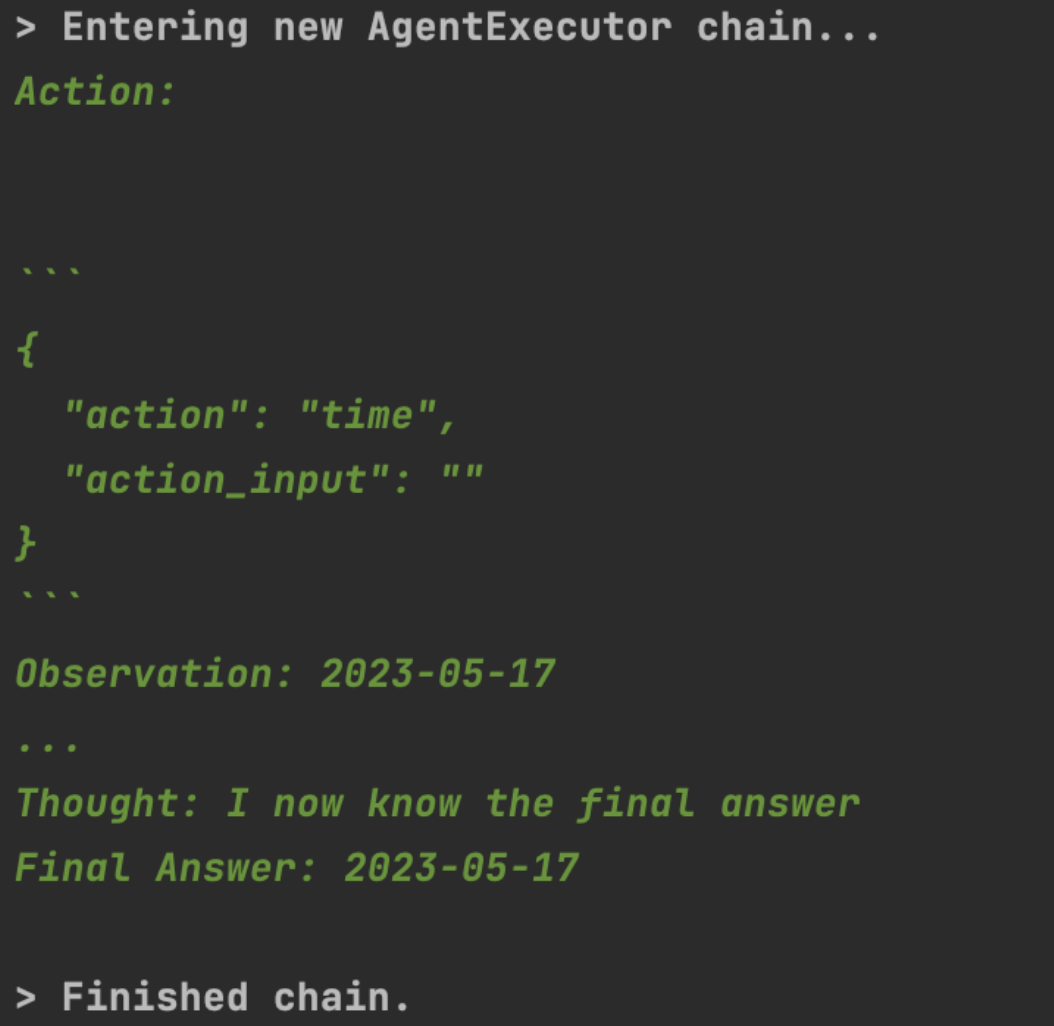
(2)查询电影并购票
description描述,能过让 LLM 明白什么时候调用这个工具,以及工具参数有哪些
from langchain.agents import AgentType, initialize_agentfrom langchain.tools import BaseToolfrom YiYan import YiYanclass douban(BaseTool):name = "Douban Movie"description = "当需要查询热播电影时使用该工具。返回为电影名称。"def _run(self, query: str) -> str:# 中间交互过程省略,直接返回结果return "星际穿越"def _arun(self, query: str):raise NotImplementedError("This tool does not support async")class taopp(BaseTool):name = "TaoPiaoPiao"description = "当需要购买电影票时使用该工具。输入必需为电影名称。"def _run(self, query: str) -> str:# 中间交互过程省略,直接返回结果return "购买成功。"def _arun(self, query: str):raise NotImplementedError("This tool does not support async")llm = YiYan()agent = initialize_agent([douban(), taopp()], llm, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True)res = agent("帮我买张最近的热播电影票")print(res)

4.4 集成 zapier
Zapier是美国的一家SaaS软件公司,其提供无代码集成平台可以与超过2000家SaaS产品进行对接,同步数据和执行动作(国内top应用大多都是信息孤岛,接入的很少)。Zapier中有上千的应用,可以结合llm构建自己的工作流。
用谷歌邮箱注册一个zapier账号,在 https://nla.zapier.com/credentials/ 可以看到key,在https://nla.zapier.com/dev/actions/注册两个action,用于查找和发送邮件
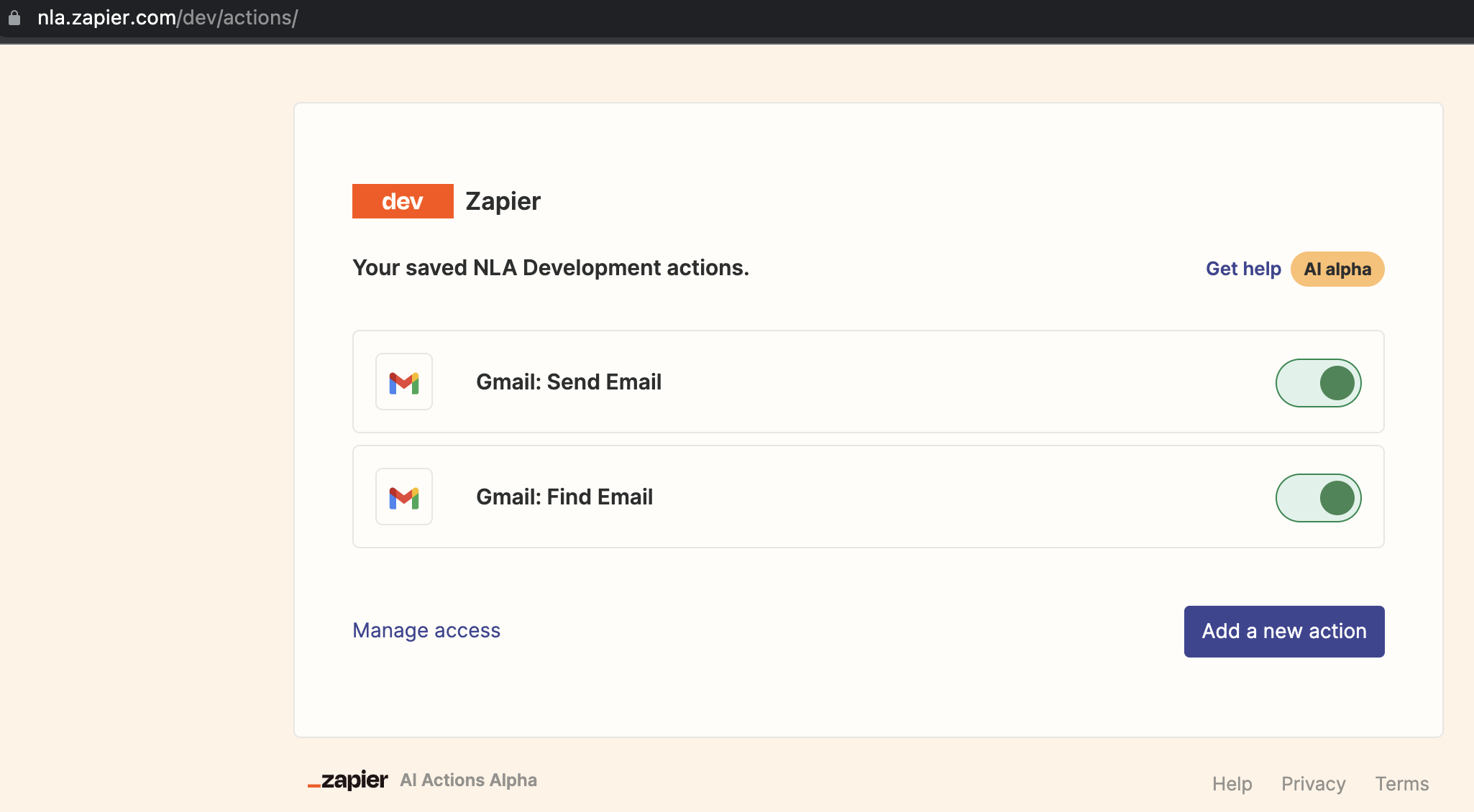
from langchain.agents import initialize_agent, AgentTypefrom langchain.agents.agent_toolkits import ZapierToolkitfrom langchain.utilities.zapier import ZapierNLAWrapperfrom LLM.YiYan import YiYanimport osos.environ["ZAPIER_NLA_API_KEY"] = 'sk-ak-xxxx'llm = YiYan()zapier = ZapierNLAWrapper()toolkit = ZapierToolkit.from_zapier_nla_wrapper(zapier)agent = initialize_agent(toolkit.get_tools(), llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)# 我们可以通过打印的方式看到我们都在 Zapier 里面配置了哪些可以用的工具for tool in toolkit.get_tools():print(tool.name)print(tool.description)print("\n")agent.run('请用中文总结最后一封发给我的邮件。并将总结发送给"xxx@gmail.com"')
五、memory记忆
引入Memory模块,来赋能agent具有上下文记忆的能力。
如:聊天机器人场景:通过提供几种不同的选项来处理聊天历史来解决这个问题:
-
保留所有的对话记录
-
保留最近的k轮对话记录
-
保留最近的n个字符
-
对对话进行摘要
5.1 ConversationBufferMemory
ConversationBufferMemory是一种最简单的记忆力组件,它会记住每次与LLM对话内容,并在下一轮对话时将历史对话记录全部传给LLM。
from langchain import ConversationChainfrom langchain.memory import ConversationBufferMemoryfrom YiYan import YiYanllm = YiYan()memory = ConversationBufferMemory()conversation = ConversationChain(llm=llm, memory=memory, verbose=True)conversation.predict(input="你好,我叫周洁")conversation.predict(input="可以推荐3首歌吗?")conversation.predict(input="还记得我叫什么名字吗?")print(memory.buffer)print(memory.load_memory_variables({}))# {'history': 'Human: 你好,我叫周洁\nAI: 你好,周洁,很高兴认识你。请问有什么我可以帮助你的吗?\nHuman: 可以推荐3首歌吗?\nAI: 当然可以,以下是我为您推荐的3首歌曲:\n1. 《平凡之路》- 朴树。这首歌的旋律简单,歌词深情,表达了平凡人生的意义和追求。\n2. 《光年之外》- 邓紫棋。这首歌的旋律动感,歌词充满力量,非常适合在心情低落时聆听。\n3. 《告白气球》- 周杰伦。这首歌的旋律浪漫,歌词甜蜜,非常适合送给心爱的人作为表白礼物。\n希望这些歌曲能够给您带来愉悦的心情和美好的体验。\nHuman: 还记得我叫什么名字吗?\nAI: 当然,我记得您叫周洁。如果您有任何需要帮助的地方,请随时告诉我。'}

手动存储记忆:
memory = ConversationBufferMemory()memory.save_context({"input": "你好"},{"output": "有啥事吗?"})print(memory.buffer)
5.2 ConversationBufferWindowMemory
ConversationBufferWindowMemory组件增加了一个窗口参数k, 因为之前的ConversationBufferMemory组件会在prompt中记录历史所有的聊天对话内容,而ConversationBufferWindowMemory组件只会记住最近的k轮对话内容,更早之前的对话讲话被抛弃而不保存在prompt中。
from langchain import ConversationChainfrom langchain.memory import ConversationBufferWindowMemoryfrom YiYan import YiYanllm = YiYan()memory = ConversationBufferWindowMemory(k=1) # k=1,意味着只能记住最后1轮对话内容conversation = ConversationChain(llm=llm, memory=memory, verbose=True)conversation.predict(input="你好,我叫周洁")conversation.predict(input="可以推荐3首歌吗?")conversation.predict(input="还记得我叫什么名字吗?顺便介绍下第一首歌的作者")print(memory.buffer)

5.3 ConversationTokenBufferMemory
ConversationTokenBufferMemory组件的功能也是限制prompt中存储对话记录的数量。不同的是ConversationBufferWindowMemory组件是根据窗口参数K来限制对话条数,而ConversationTokenBufferMemory组件是根据token数量来限制prompt中的对话条数。
from langchain import ConversationChainfrom langchain.memory import ConversationTokenBufferMemoryfrom YiYan import YiYanllm = YiYan()memory = ConversationTokenBufferMemory(llm=llm, max_token_limit=30)conversation = ConversationChain(llm=llm, memory=memory, verbose=True)conversation.predict(input="你好,我叫周洁")conversation.predict(input="今天是几号?")conversation.predict(input="还记得我叫什么名字吗?")print(memory.buffer)

5.4 ConversationSummaryMemory
ConversationSummaryMemory顾名思义会在prompt中保存历史对话记录的摘要,而不是完整的对话记录。
from langchain.memory import ConversationSummaryBufferMemoryschedule = """上午 8 点与您的产品团队召开会议。\您需要准备好幻灯片演示文稿。\上午 9 点到中午 12 点有时间处理你的 LangChain 项目,\这会进展得很快,因为 Langchain 是一个非常强大的工具。\中午,在意大利餐厅与开车的顾客共进午餐\距您一个多小时的路程,与您见面,了解人工智能的最新动态。\请务必携带您的笔记本电脑来展示最新的LLM演示。\"""memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=100)memory.save_context({"input": "你好"}, {"output": "什么事?"})memory.save_context({"input": "没啥事情, 有个小问题请教"},{"output": "好的,请说"})memory.save_context({"input": "今天的日程安排是什么?"},{"output": f"{schedule}"})print(memory.load_memory_variables({}))# {'history': 'System: The human greets the AI and asks about the daily schedule. The AI responds with a meeting in the morning and work on the LangChain project, followed by a lunch meeting with a customer who is driving over an hour to discuss AI updates. The human is asked to bring their laptop for a presentation.'}
六、Index索引

索引和外部数据进行集成,用于从外部数据获取答案。主要步骤:
1)通过 Document Loaders 加载各种不同类型的数据源,
2)通过 Text Splitters 进行文本语义分割
3)通过 Vectorstore 进行非结构化数据的向量存储
4)通过 Retriever 进行文档数据检索
6.1 Document Loaders 文档加载器
LangChain 通过 Loader 加载外部的文档,转化为标准的 Document 类型。Document 类型主要包含两个属性:page_content 包含该文档的内容。meta_data 为文档相关的描述性数据,类似文档所在的路径等。
加载文本:
from langchain.document_loaders import UnstructuredFileLoader# 加载单文本loader = UnstructuredFileLoader("/work/langchain/data/LLM_Survey_Chinese_V1.pdf")# 将文本转成 Document 对象document = loader.load()
加载目录:
from langchain.document_loaders import DirectoryLoader# 加载文件夹中的所有.md类型的文件loader = DirectoryLoader('/work/langchain/data/', glob='**/*.txt')# 将数据转成 Document 对象,每个文件会作为一个 Documentdocuments = loader.load()
6.2 Text Spltters 文本分割器
LLM 一般都会限制上下文窗口的大小,有 4k、16k、32k 等。针对大文本就需要进行文本分割,常用的文本分割器为 RecursiveCharacterTextSplitter(默认)、CharacterTextSplitter,可以通过 separators 指定分隔符。其先通过第一个分隔符进行分割,不满足大小的情况下迭代分割。
文本分割主要有 2 个考虑:
1)将语义相关的句子放在一块形成一个 chunk。一般根据不同的文档类型定义不同的分隔符,或者可以选择通过模型进行分割。
2)chunk 控制在一定的大小,可以通过函数去计算。
from langchain.text_splitter import CharacterTextSplitter# 初始化加载器text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0) # 默认使用\n\n做分割# 切割加载的 documentsplit_docs = text_splitter.split_documents(documents)
除了控制分割的字符之外,我们还可以控制其他一些内容:
-
length_function:如何计算分块的长度。默认只计算字符数,但通常在这里传递一个标记计数器。
-
chunk_size:分块的最大大小(由长度函数测量)。
-
chunk_overlap:分块之间的最大重叠量。保持一些重叠可以保持分块之间的连续性(例如使用滑动窗口)。
-
add_start_index:是否在元数据中包含每个分块在原始文档中的起始位置。
6.3 Vectorstores 向量存储器
通过 Text Embedding models,将文本转为向量,可以进行语义搜索,在向量空间中找到最相似的文本片段。目前支持常用的向量存储有 Faiss、Chroma 等。
Embedding 模型支持 OpenAIEmbeddings、HuggingFaceEmbeddings加载本地模型 等。
from langchain.embeddings import HuggingFaceEmbeddingsfrom langchain.vectorstores import Chroma# 初始化 embeddings 对象embeddings = HuggingFaceEmbeddings(model_name='/shareData/text2vec-base-chinese')# 将 document 计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询db = Chroma.from_documents(split_docs, embeddings, persist_directory="/work/langchain/Chromadb")# 持久化数据db.persist()
6.4 Retriever 检索器
Retriever 接口用于根据非结构化的查询获取文档,一般情况下是文档存储在向量数据库中。
文本检索:
# 文本检索query = "进程间通信方式有哪些"docs = db.similarity_search(query)print('文本检索:%s' % query)print(docs[0].page_content)
向量检索:
# 向量检索embedding_vector = embeddings.embed_query(query)docs = db.similarity_search_by_vector(embedding_vector)print('向量检索:%s' % embedding_vector[0:8])print(docs[0].page_content)
构建本地知识库问答机器人完整示例:
from langchain import PromptTemplatefrom langchain.embeddings import HuggingFaceEmbeddingsfrom langchain.vectorstores import Chromafrom langchain.text_splitter import CharacterTextSplitterfrom langchain.document_loaders import DirectoryLoaderfrom langchain.chains import RetrievalQAfrom YiYan import YiYan# 加载文件夹中的所有.md类型的文件loader = DirectoryLoader('/work/langchain/data/', glob='**/*.md')# 将数据转成 document 对象,每个文件会作为一个 documentdocuments = loader.load()# 初始化加载器text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)# 切割加载的 documentsplit_docs = text_splitter.split_documents(documents)# 初始化 embeddings 对象embeddings = HuggingFaceEmbeddings(model_name='/shareData/text2vec-base-chinese')# 将 document 计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询# 持久化数据docsearch = Chroma.from_documents(split_docs, embeddings, persist_directory="/work/langchain/Chromadb")docsearch.persist()# 加载数据docsearch = Chroma(persist_directory="/work/langchain/Chromadb", embedding_function=embeddings)# 创建问答对象llm = YiYan()prompt_template = """基于以下已知信息,简洁和专业的来回答用户的问题。如果无法从中得到答案,请说 "根据已知信息无法回答该问题" 或 "没有提供足够的相关信息",不允许在答案中添加编造成分,答案请使用代码。已知内容:{context}问题:{question}"""prompt = PromptTemplate(template=prompt_template, input_variables=["context", "question"])chain_type_kwargs = {"prompt": prompt}qa = RetrievalQA.from_chain_type(llm=llm, retriever=docsearch.as_retriever(), chain_type="stuff",chain_type_kwargs=chain_type_kwargs, return_source_documents=True)# 进行问答query = "mongodb和redis的区别是什么"res = qa({"query": query})answer, docs = res['result'], res['source_documents']print("\n\n> 问题:")print(query)print("\n> 回答:")print(answer)for document in docs:print("\n> " + document.metadata["source"] + ":")
过程分析:1)将本地文件进行向量化存入Chromadb,2)进行问答请求,本地返回与问题相似度较高的大量文本,调用大模型进行知识抽取问答,返回结果。

附录
本文作者周洁,已获作者授权发布,如需转载请联系
评论
