千帆大模型平台增加RLHF训练功能
大模型开发/互助问答
- 文心大模型
- API
2023.08.251527看过
千帆平台增加了RLHF训练,包含奖励模型训练和强化学习训练。
本篇文章主要回答社区用户的这个提问:https://cloud.baidu.com/qianfandev/topic/267167
为了更好理解这个问题,可以借鉴学习一下ChatGPT的训练过程。
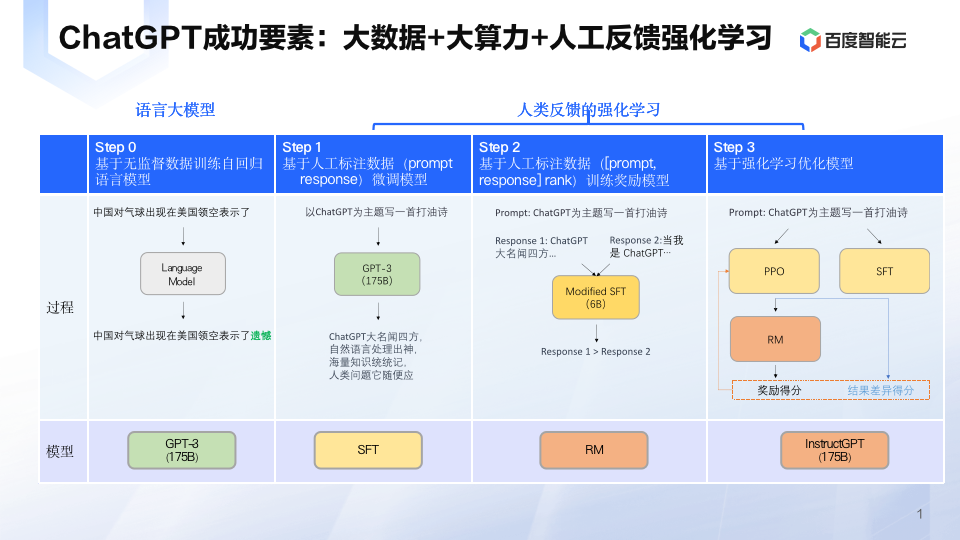
在“人工标注数据+强化学习”框架下,训练 ChatGPT 主要分为三个阶段。
-
第一阶段使用标准数据(prompt 和对应的回答)进行微调,也就是有监督微调 SFT(Supervised fine-tuning)
-
第二个阶段,训练回报模型(Reward Model, RM)。给定 prompt(大约3万左右),使用微调后的模型生成多个回答,人工对多个答案进行排序,然后使用 pair-wise learning 来训练 RM,也就是学习人工标注的顺序(人工对模型输出的多个答案按优劣进行排序)。
-
最后一个阶段就是使用强化学习,微调预训练语言模型。
那么为什么不直接使用 SFT,而是又要引入强化学习?
强化学习的目的是让模型的答案更接近人类意图,本阶段无需人工标注数据,而是利用上一阶段学好的 RM 模型,靠 RM 打分结果来更新预训练模型参数。
既然目标是让模型能更好拟合<prompt, answer>,那为什么不直接使用 SFT,这样不是更直接吗?或者为了拟合<prompt, answer1, answer2,...>这个序,再做一次 Fine-tuning。
之所以没有这样做,主要原因还是标注数据太少了,一共才3万条标注数据。理想情况下,如果标注数据足够多,可能 SFT 就足够了,这时候也不需要再做强化学习。现实中数据量达不到足够多,这时候就要借助强化学习。
再回顾一下千帆大模型:PPO是强化学习的一种算法,经过了PPO以后的1.3B的模型效果好于未经过PPO的175B模型,可见强化学习对大模型效果提升非常明显。
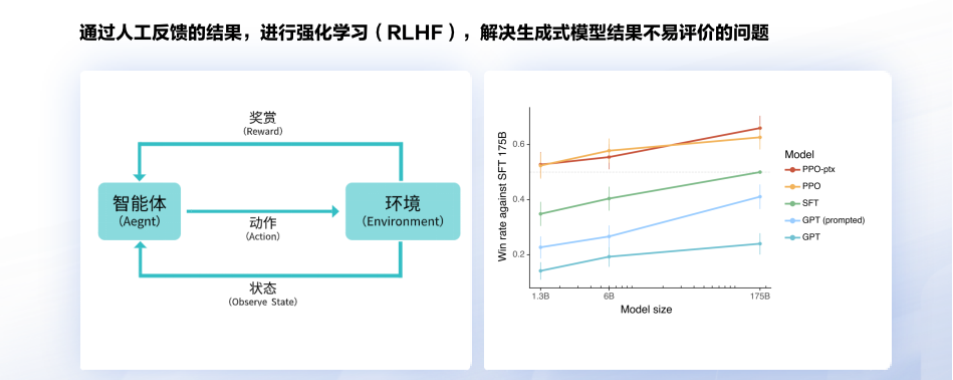
可以看到,只做SFT,模型效果是不能完全发挥出来的,必须得做强化学习,而要做强化学习, 又要先训练奖励模型。因此千帆大模型平台增加RLHF训练功能。
评论
