

 文心大模型ERNIE 5.0上线千帆!
文心大模型ERNIE 5.0上线千帆!构建企业级Agent
- 多智能体协同Agent
- 自主规划Agent
- 工作流Agent
- 知识库RAG
- 全链路可观测

多智能体协同Agent
复杂任务下多智能体协同
Multi-Agent编排引擎实现复杂场景下的任务智能分发和多Agent协同
突破单一Agent效率瓶颈
高并发 DAG 执行引擎提升效率,支持全链路流式输出,任务进度实时跟随
官方预置高质量子Agent
预置网页探索、代码编写、报告撰写等Agent,开箱即用
全面兼容A2A协议
全面兼容A2A协议,打造更开放的Agent生态




高效价比的模型服务
 ernie-5.0-thinking-preview
ernie-5.0-thinking-previewernie-5.0-thinking-preview
ERNIE X1.1 Preview
ERNIE 4.5 Turbo

DeepSeek-V3.1-Think
DeepSeek-V3.1
- 自研通用模型
- 垂类场景模型
- 第三方模型
百度蒸汽机2.0
音视一体,画质革命视频生成
通过多模态信息精准同步与自然交互,支持多人对话音视频一体化生成,音画同步,电影级质感画面、大师级运镜,中文语音细节高度还原。
模型接入点musesteamer-2.0-turbo-i2v-audio
上下文-
9月3日前¥1.4 / 5s、 ¥2.8 / 10s
9月3日后¥2.5 / 5s、 ¥4.2 / 10s
立即体验
ERNIE X1.1 Preview
全新升级,效果提升深度推理
问答、工具调用、智能体、指令遵循、逻辑推理、数学、代码任务的效果显著提升,事实性显著提升。支持64K上下文长度,兼顾响应速度与长链路推理连贯性。
模型接入点ernie-x1.1-preview
上下文64k,55K+64K
输入价格¥0.001/ 千tokens
输出价格¥0.004/ 千tokens
立即体验
ERNIE 4.5 Turbo VL
多模态图像理解
图片理解、创作、翻译、代码等能力显著提升,支持128K上下文长度,首Token时延显著降低。
模型接入点ernie-4.5-turbo-vl
上下文128K,123K+ 16K
输入价格¥0.003/ 千tokens
输出价格¥0.009/ 千tokens
立即体验
ERNIE 4.5 Turbo
文本生成
文心4.5 Turbo在去幻觉、逻辑推理和代码能力等方面也有着明显增强。对比文心4.5,速度更快、价格更低。
模型接入点ernie-4.5-turbo-128k
上下文128K,123K+ 12K
输入价格¥0.0008/ 千tokens
输出价格¥0.0032/ 千tokens
立即体验
ERNIE-5.0-Thinking-Preview
深度推理视觉理解
文心5.0是原生全模态大模型,基础能力全面升级,多模态理解、指令遵循、创意写作、事实性、智能体规划与工具应用等表现尤其出色
模型接入点ernie-5.0-thinking-preview
上下文119k,64k
输入价格¥0.006-0.01/ 千tokens
输出价格¥0.024-0.04/ 千tokens
立即体验
ERNIE-4.5-VL-28B-A3B
多模融合,全新升级多模态深度推理
文心4.5中的多模态开源模型,采用MoE架构,具备 280 亿总参数量,激活参数为 30 亿,支持切换思考和非思考两种模式。
模型接入点ernie-4.5-vl-28b-a3b
上下文32K,30K+8K
输入价格¥0.001/ 千tokens
输出价格¥0.01/ 千tokens
立即体验
独家优质组件与精选MCP服务



 免费调用:100次/天
免费调用:100次/天











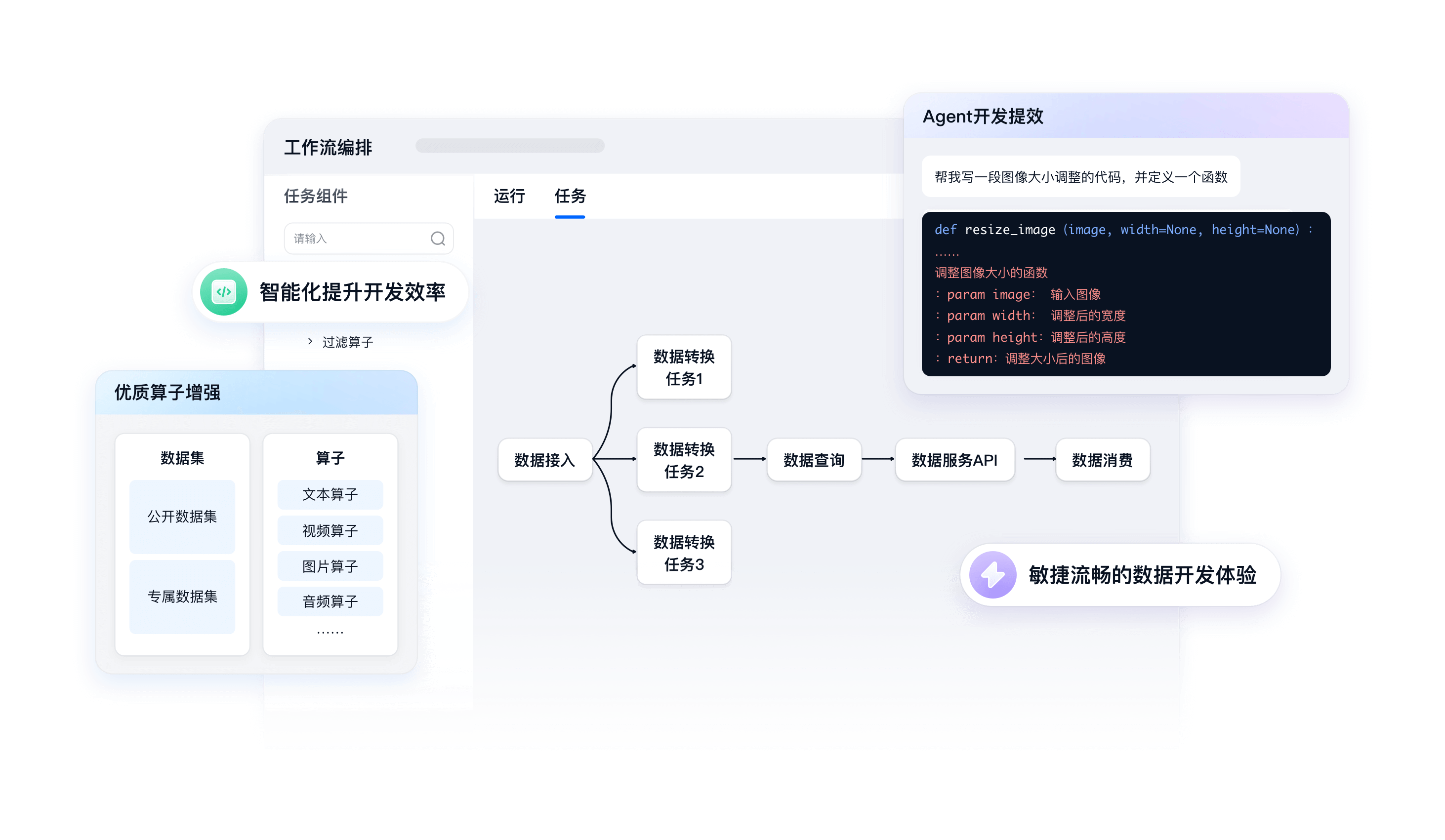
一站式数据智能平台DataBuilder
- 高效数据迭代
- 多模态数据管理
- 一站式高性能计算
- 智能数据分析
高效数据迭代
在线开发平台
同个工作空间多角色协作,支持在线文件系统等能力,提供统一的开发体验
灵活任务编排
支持多任务可视化调度和分布式并行,便于用户完成复杂的数据开发工作
优质算子增强
内置增强算子和高质量数据集,有助于提升开发效率和效果
Agent开发提效
自研AI智能引擎,支持通过自然语言指令生成开发代码,帮助用户高效完成代码任务
企业级云原生高可用
 安全、稳定高可用
安全、稳定高可用
多维监控
为企业稳定使用保驾护航提供全局调用/异常分析/ Agent 资源统计等 20+ 丰富监控指标

日志持久化
满足企业日志管理诉求可投递至云BLS日志服务,持久化管理与存储,并支持回流、脱敏与挖掘

实时告警
为企业提供及时告警推送无缝接入云监控BCM,可配置自定义告警规则及通知渠道

审计合规
满足企业合规性需求控制台与管控API核心事件接入云审计BCT,对操作进行详细的审计记录

安全能力
避免企业业务风险针对模型输入输出提供独家安全策略,并支持自定义干预,满足合规要求

权限管控
提升企业操作安全性支持多用户访问控制与自定义细粒度权限策略,支持主账户对子用户管控
客户成功落地案例
- 政务企服
- 教育
- 招聘
- 金融
- 能源
- 手机助手

智能 “居民助理” 带来政务服务新变革
基于RAG 框架构建本地政务知识库,并运用文心大模型能力开发“居民助理”,可通过语音或文本方式响应居民医保缴费、户籍办理等咨询,并将居民诉求转换为工单并进入后台流转。
20万户+
居民触达
70%
服务满意度
7*24小时
便民服务
助力中华全国总工会系统服务效率跃迁式提升
千帆通过建设一套 1+4+N 的人工智能应用支撑体系,实现了全国一盘棋,服务全国亿万职工会员,提供更人性、高效、准确的法律和维权服务,得到有效信息支撑从周级到小时级。
亿万职工
获得援助服务
小时级
获取有效信息
1个月内
系统完成交付
与全球伙伴携手,深入产业共创价值


















全面的AI开发资源









更多大模型生态服务