一文讲清楚人工智能深度学习Dropout正则化
大模型开发/技术交流
- LLM
3小时前18看过
前言
在前文中,笔者为大家讲解了机器学习中常用的两种基本的正则化技术-- L1 和 L2 正则化技术,这篇文章笔者就带大家了解学习一下深度学习中最常见的正则化技术--Dropout正则化。
一、定义和原理
1. 定义 :
Dropout正则化是一种在深度学习中广泛使用的正则化技术,由Hinton等人于2012年提出。它的核心思想是在模型训练过程中随机地关闭(即设置为0)网络中的一部分神经元,使它们在当前训练迭代中不参与前向传播和反向传播。这样做可以减少神经元之间复杂的共适应性,增强模型的泛化能力。
2. 原理 :
Dropout正则化的原理(集合下文原理图像理解) :
-
随机失活神经元--减少共适应性:在神经网络的训练过程中,Dropout通过随机将一部分神经元的激活输出设置为0(即“关闭”或“丢弃”这些神经元),从而防止它们在前向传播和反向传播中起作用。这种方法减少了神经元之间复杂的共适应性,即防止模型过度依赖于某些特定的神经元或神经元组合。
-
增强泛化能力:由于每次训练迭代都可能使用不同的神经元子集,这相当于训练了多个不同的模型,从而增强了模型的泛化能力。
-
模拟集成学习:Dropout可以看作是一种模型平均的集成学习方法,因为它在每次训练迭代中创建了一个不同的“瘦”模型,而在测试时则使用了所有可能的模型的平均效果。
Dropout的神经网络图像:
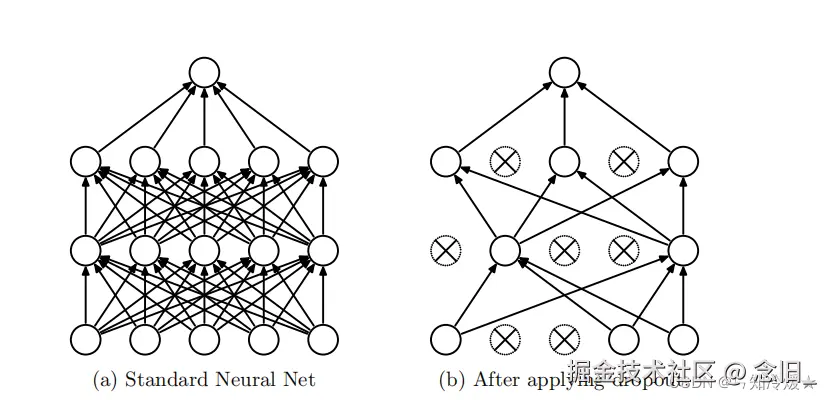
还是看不懂 ? OK 上例子!
3. 实例讲解Dropout正则化原理过程 :
想象一下,你是一个篮球队的教练,你的队伍有12名球员,但你只有10个上场名额。你的目标是组建一个不仅在训练赛中表现出色,而且在正式比赛中也能赢得胜利的球队。
在没有Dropout的情况下,你可能会依赖于固定的10名球员参加每一场比赛,这样会导致几个问题:
-
如果某个关键球员受伤或状态不佳,整个队伍的表现可能会大幅下降。
-
你的球队可能会过度依赖某些球星,而其他球员没有足够的机会来提升自己的技能。
这就像是没有正则化的神经网络,它可能会过度依赖某些特征(球员)来做出预测。
现在,让我们引入Dropout的概念。在每场比赛前,你决定随机选择2名球员让他们坐在替补席上,这样只有10名球员可以参加比赛。这个决定是随机的,每个球员都有被选中坐在替补席上的可能性。这个策略带来了以下好处:
-
所有球员都知道他们可能在任何一场比赛中被选中上场,所以他们都必须保持状态和准备。
-
球队不能依赖于任何特定的球员,必须发展出一种即使在失去某些球员时也能继续比赛的策略。
-
这种策略迫使球队找到一种更加灵活和多样化的打法,这有助于提高球队在不可预测的正式比赛中的表现。
这就与我们Dropout正则化的作用非常相似:
-
Dropout通过在每次训练迭代中随机“丢弃”一些神经元,迫使网络中的所有神经元保持活跃和准备状态。
-
它减少了网络对任何特定神经元的依赖,因为任何神经元都可能在训练的任何时候被丢弃。
-
这迫使网络学习到更加鲁棒的特征表示,这些特征表示不依赖于任何特定的神经元子集。
在测试时(相当于正式比赛),虽然所有球员都可以参加,但你会让每个球员以较低的强度(例如,减少他们的上场时间)来比赛,以保持与训练时相同的整体强度水平。在神经网络中,这相当于在测试时不使用Dropout,但保持网络权重的缩放,以确保网络输出的期望值与训练时相同。通过这种方式,Dropout正则化帮助神经网络提高了泛化能力,使其在面对新的、未见过的数据时也能表现良好。



为什么保持期望输出不变很重要?
保持期望输出的不变是为了确保我们训练过程中的信号传递不受Dropout的随机性影响。如果期望输出降低了,那么学习信号可能会被削弱,导致网络学习速度变慢。通过缩放,我们确保了即使有神经元被丢弃,网络的总体学习动态仍然保持一致。
四、实战代码演示
以下是一个我使用 Dropout 正则化的简单神经网络示例,使用了 TensorFlow 和 Keras 构建:
import tensorflow as tffrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Dense, Dropout# 定义一个简单的顺序模型model = Sequential()# 添加输入层和第一个隐藏层model.add(Dense(64, activation='relu', input_shape=(input_dim,)))model.add(Dropout(0.5)) # 添加Dropout层,丢弃率50%# 添加第二个隐藏层model.add(Dense(64, activation='relu'))model.add(Dropout(0.5)) # 再次添加Dropout层# 添加输出层model.add(Dense(num_classes, activation='softmax'))# 编译模型model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])# 模型摘要model.summary()# 假设 X_train 和 y_train 是训练数据和标签# X_train, y_train = ...# 训练模型# history = model.fit(X_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
在我这个例子中:
-
模型构建:使用
Sequential模型堆叠层。 -
Dropout 层:在两个隐藏层后面分别添加了 Dropout 层,丢弃率设置为 50%,这意味着在每次训练迭代中,每个神经元有 50% 的概率不会参与到前向和后向传播中。
-
编译模型:使用
adam优化器和categorical_crossentropy损失函数编译模型,评估指标为accuracy。 -
模型训练:使用
fit方法训练模型,其中validation_split参数用于划分一部分训练数据用于验证。
在你实际的使用中,请注意,
input_dim 应该设置为你的数据的特征数量,num_classes 应该设置为你的目标类别数量。此外,你需要替换 X_train 和 y_train 为你的实际训练数据和标签。
五、其他
-
Dropout在全连接层中应用最为广泛,通常在隐藏层之后设置Dropout层,以减少层与层之间神经元的共适应性。一些实验表明,Dropout比率设置在0.3到0.5之间时,往往能取得较好的效果。当然,归根到底还是因模型而异,最好还是做个实验寻找出最优值。
-
在实际应用中,Dropout可以与其他正则化方法(如L1/L2正则化、数据增强等)结合使用,以取得更好的正则化效果。在测试阶段,所有神经元都被保留,但需要对权重进行缩放以恢复原始的网络结构。
-
Dropout虽然简单,但也有一些潜在的局限性。例如,如果Dropout比率设置得过高,则可能导致模型损失过多信息,从而影响性能。此外,Dropout并不能完全解决过拟合问题,可能需要结合其他技术一起使用。
-
总的来说,Dropout是一种有效的正则化方法,通过随机丢弃网络中的神经元,减少了过拟合现象,提高了模型的泛化能力。在设计深度学习模型时,合理地使用Dropout可以显著提升我们模型的性能和鲁棒性。
六、Reference
以上就是笔者关于人工智能深度学习Dropout正则化技术的讲解,欢迎大家点赞,收藏,交流和关注,O(∩_∩)O谢谢!
————————————————
版权声明:本文为稀土掘金博主「念旧_」的原创文章
原文链接:https://juejin.cn/post/7416903220591525926
如有侵权,请联系千帆社区进行删除
评论