线上加速营课程学习——精调大模型实战
AI原生应用开发/技术交流
- AI加速器线上加速营
10月9日345看过
通过本期线上加速营课程的学习,学习到大模型精调过程中的一些细节方法,受益匪浅。其中,《第四章 结合模型精调的判题机器人Agent开发》是我非常喜欢的一节课程。这门课程讲解梳理大模型精调的过程,能够有效指导开发者投入到实际开发场景中。大家可以点击此链接报名参与学习:https://cloud.baidu.com/partner/training-camp/c9mmkvhy64i.html。
大模型的SFT(Supervised Fine-Tuning,监督微调)是指在机器学习和自然语言处理(NLP)领域中,对已经预训练的模型进行特定任务的训练,以提高其在该任务上的表现。具体来说,SFT的基本思想是利用特定任务的数据,对已经在大量通用数据上训练完成的预训练模型进行进一步调整,使其更适合该任务,并更好地适应最终任务和对齐用户偏好。
SFT的原理与步骤
SFT的过程大致可以分为以下几个步骤:
-
预训练模型:首先,在大规模的无监督数据集(如维基百科、书籍语料库等)上进行预训练。通过无监督学习,模型学习到丰富的语言表示,如词语之间的关系、句子结构等。
-
数据收集与标注:选择特定任务的数据集,对数据进行预处理和标注。这些数据集用于后续的有监督微调过程。
-
监督微调:将预训练的基础模型在标注好的数据集上进行进一步训练。这一过程通过有监督学习,使模型能够利用预训练阶段学到的通用知识,结合新数据的标签信息,提升在特定任务上的表现。
-
模型评估与优化:使用验证集对微调后的模型进行评估,计算模型在任务上的性能指标。根据评估结果,对模型进行进一步的优化和调整。
SFT的方式
大模型的SFT方式主要包括以下几种:
-
全参数微调(Full Parameter Fine Tuning):涉及对模型的所有权重进行调整,以使其完全适应特定领域或任务。这种方法适用于拥有大量与任务高度相关的高质量训练数据的情况。
-
部分参数微调(Sparse Fine Tuning / Selective Fine Tuning):
-
LoRA(Low-Rank Adaptation):通过向模型权重矩阵添加低秩矩阵来进行微调,既允许模型学习新的任务特定模式,又能够保留大部分预训练知识。
-
P-tuning v2:基于prompt tuning的方法,仅微调模型中与prompt相关的部分参数,而不是直接修改模型主体的权重。
-
QLoRA:可能是指Quantized Low-Rank Adaptation或其他类似技术,它可能结合了低秩调整与量化技术,以实现高效且资源友好的微调。
-
冻结(Freeze)监督微调:在这种微调方式中,部分或全部预训练模型的权重被冻结,仅对模型的部分层或新增的附加组件进行训练。这样可以防止预训练知识被过度覆盖,同时允许模型学习针对新任务的特定决策边界。
SFT的应用与优势
SFT在自然语言处理领域有广泛的应用,如文本分类、情感分析、机器翻译等。通过结合预训练和微调,SFT能够在较少的数据和计算资源下实现高效的模型性能提升。此外,由于预训练模型已经在大量数据上进行过训练,SFT通常只需要较少的标注数据即可达到良好的效果,这降低了数据标注的成本。
总的来说,大模型的SFT是一种有效的模型优化方法,能够提升模型在特定任务上的表现,并推动自然语言处理技术的进一步发展。
在百度智能云平台上,您可以选择对应的基础模型进行SFT训练,以进一步优化模型性能和适应特定任务需求。
本文采用LoRA微调
-
原理概述低秩矩阵:在线性代数中,矩阵的秩(Rank)是指矩阵中线性无关的行或列的最大数目。低秩矩阵意味着矩阵中存在较多的线性相关性,即矩阵的信息冗余度高。LoRA利用这一特性,通过引入低秩矩阵来近似表示权重矩阵在微调过程中的变化。微调过程:在LoRA中,原始预训练模型的权重矩阵保持不变,而是在其基础上添加两个低秩矩阵A和B。这两个矩阵的乘积BA可以近似表示权重矩阵在微调过程中的变化量。因此,微调后的权重矩阵可以表示为W' = W + BA,其中W是原始权重矩阵,W'是微调后的权重矩阵。
-
示例说明假设我们有一个预训练的神经网络层,其权重矩阵W的维度为1000×1000。在LoRA微调过程中,我们可以引入两个低秩矩阵A和B,它们的维度分别为50×1000和1000×50。这样,通过训练这两个较小的矩阵A和B,我们能够微调原始的1000×1000权重矩阵W,而不需要重新训练所有100万个参数。最终,微调后的权重矩阵W' = W + BA,其中BA的维度为50×50,仅包含2500个参数。
综上所述,LoRA(Low-Rank Adaptation)通过向模型权重矩阵添加低秩矩阵来进行微调,既允许模型学习新的任务特定模式,又能够保留大部分预训练知识。这一技术以其高效性、保留预训练知识和减少过拟合风险等优势,在自然语言处理领域得到了广泛应用。
SFT案例——劳动合同关键信息提取
在企业管理和法律事务中,大模型可以扮演合同审查专家的角色,自动识别劳动合同是否包含所有必备条款并提取合同中的关键信息。通过模型精调,可以解决直接调用大模型输出内容不够准确全面、不按格式输出等问题。精调模型的效果远远优于基础模型ERNIE Speed的效果。
对于劳动合同关键信息提取而言,需要大模型能够精准提取需要的关键信息,保证模型输出能够做到以下几点:
内容全面准确:按照以下顺序连续输出一段字符串:1、分析是否缺失必备条款;2、分析是否缺失期望提取的关键信息;3、提取的关键信息内容。
格式准确无误:只需输出以上三点内容,不用输出顺序号和多余信息,尤其是第3点需要以{"要求提取的关键信息":"你提取的关键信息内容"}的json格式输出。
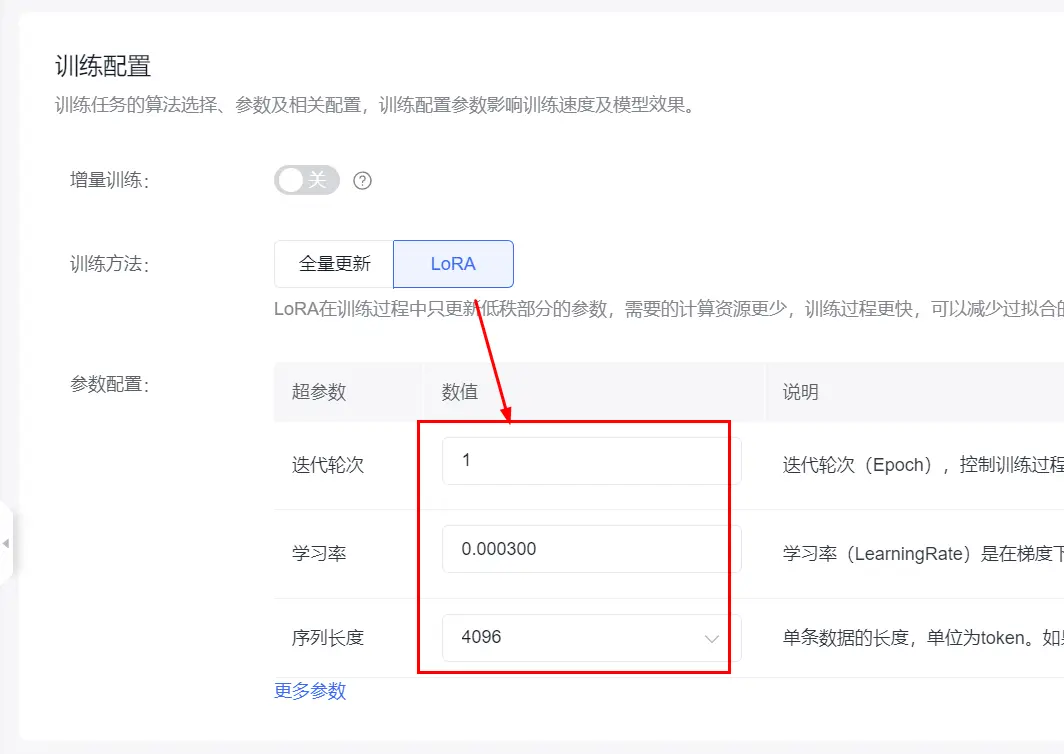
模型与参数
ERNIE-Speed-8K查看
|
训练方式
|
迭代轮次Epoch
|
学习率Learning Rate
|
序列长度Seq Length
|
|
SFT
|
1
|
0.00003
|
4096
|
数据格式示例
|
Prompt
|
Response
|
|
你是一个从合同中提取关键信息的智能助手。你的任务是分析【合同文本】并提取【关键信息】。\n你需要向我汇报的内容是:\n1.汇报合同是否缺失劳动合同必备条款;\n2.汇报【关键信息】有没有在合同中缺失;\n3.汇报你提取的关键信息,以{"要求提取的关键信息":"你提取的关键信息内容"}的json格式汇报。\n4.按照上述顺序连续汇报一段字符串,并且不用输出顺序号和任何多余信息。\n下面是你要分析的【合同文本】和要提取的【关键信息】:\n【合同文本】\n 甲方(用人单位)\n名称:明达科技有限公司\n统一社会信用代码:91310105MA1FW7U934\n地址:上海市静安区延安西路666号\n联系人:张明\n联系方式:13800138000\n乙方(劳动者)\n姓名:李华\n身份证号码:340824199001010012\n住所:上海市浦东新区世纪公园路100号\n联系人:李华\n联系方式:13900139000\n本合同各方经平等自愿协商,根据《中华人民共和国民法典》《中华人民共和国劳动合同法》及相关法规,签订本合同以共同遵守。\n# 劳动合同期限 #\n劳动合同期限:自2023年 03月 01日起(含当日)至 2026年 03月 01日(含当日)止。\n# 工作岗位和工作地点 #\n工作岗位:软件工程师。具体工作内容以甲方要求为准。\n工作地点: 上海市静安区延安西路666号明达科技有限公司办公楼。\n# 劳动报酬 #\n月工资标准:人民币(大写)玖仟元(¥9000元)。\n# 工作时间、休息休假 #\n乙方所在岗位执行标准工时制;甲方保障乙方的休息权利,并确保乙方每周至少休息一日。\n# 社会保险和福利待遇 #\n甲方依法为乙方缴纳社会保险。\n# 附则 #\n本合同一式两份,甲、乙双方各执一份,具有同等法律效力。\n\n甲方(盖章):明达科技有限公司\n乙方(签字):李华\n签订日期:2023年03月01日\n【关键信息】\n劳动合同期限,注意要提取年月日-年月日 的纯数字格式
|
分析:该合同包含了用人单位和劳动者的基本信息、劳动合同期限、工作岗位和地点、劳动报酬、工作时间和休息制度以及社会保险等关键信息,但缺失了试用期、劳动纪律、劳动保护和职业危害防护等条款。分析:有劳动合同期限。{"劳动合同期限": "20230301-20260301"}"
|
数据集是SFT的关键也是工作量最大的部分,数据的质量关系训练的效果!!一般在1000条数据左右,最少100条。
模型训练
进入千帆modelbuilder平台:
点击左侧SFT菜单。
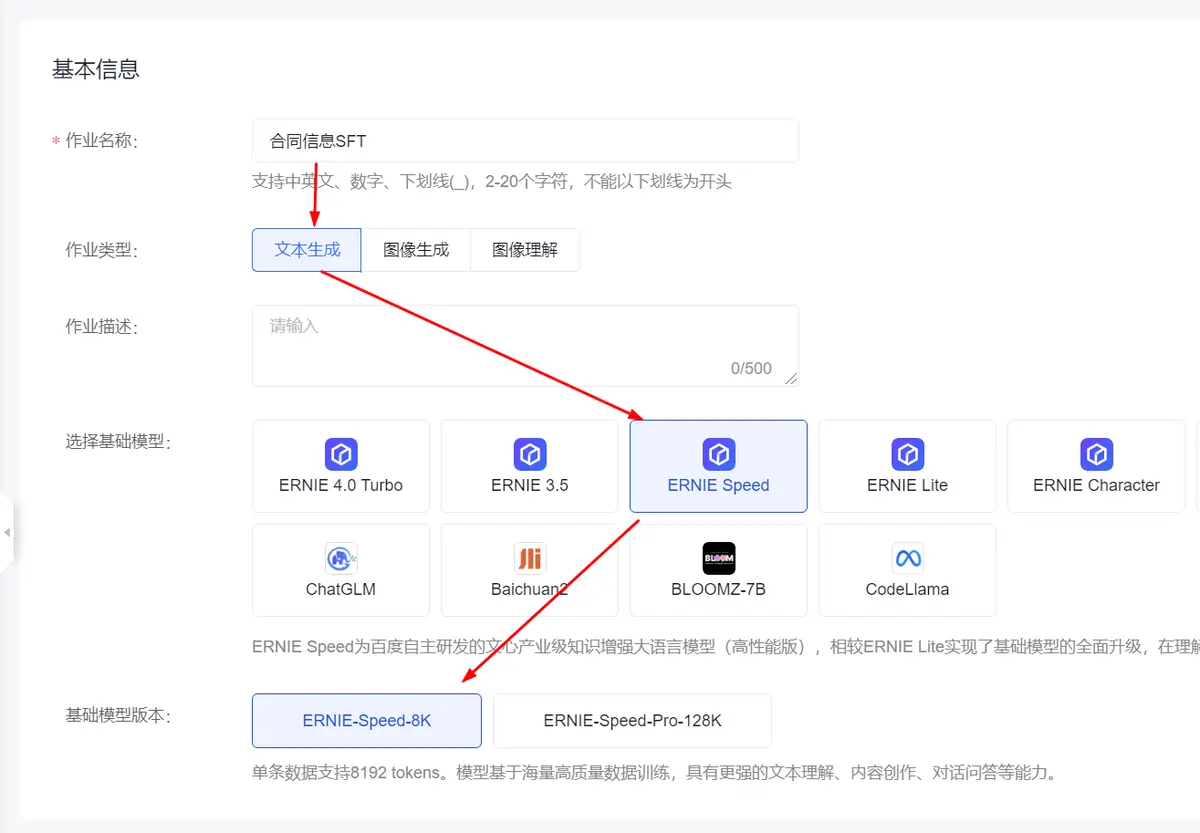
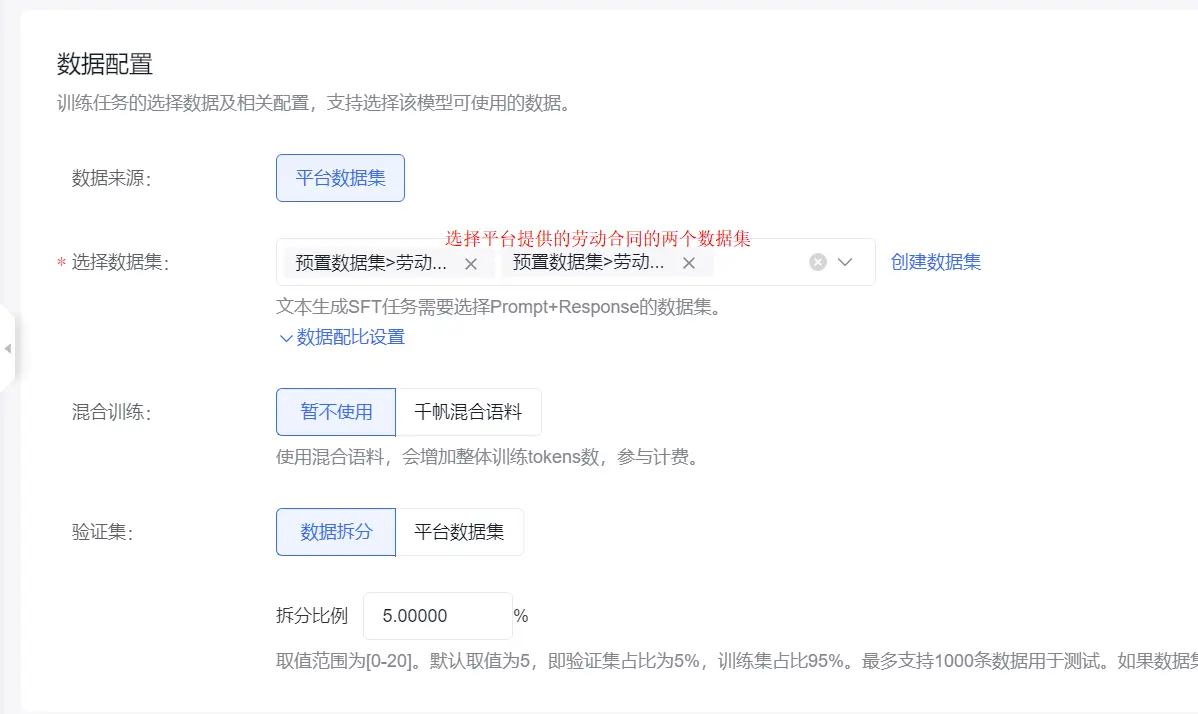
开始精调点击“确定”按钮,会自动调整到SFT详情页面。
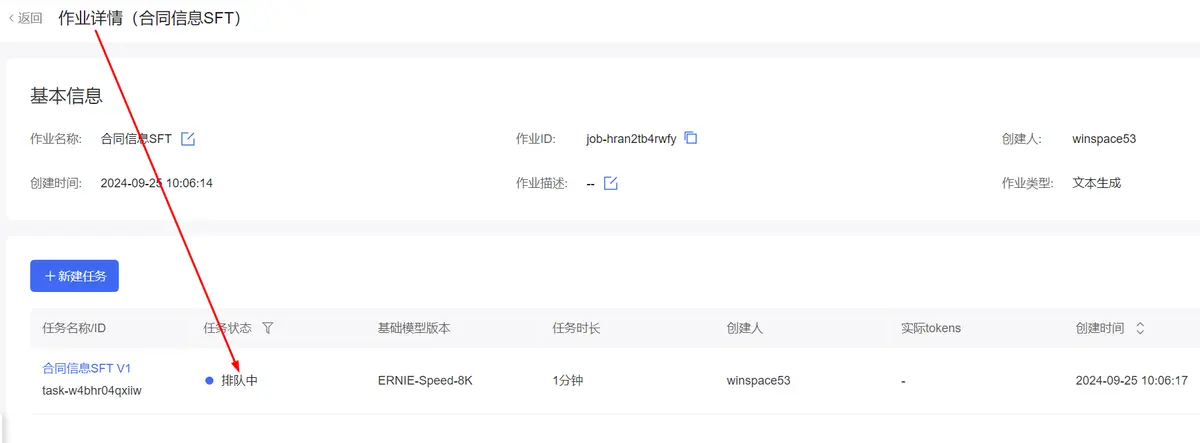
预计精调40分钟后完成。
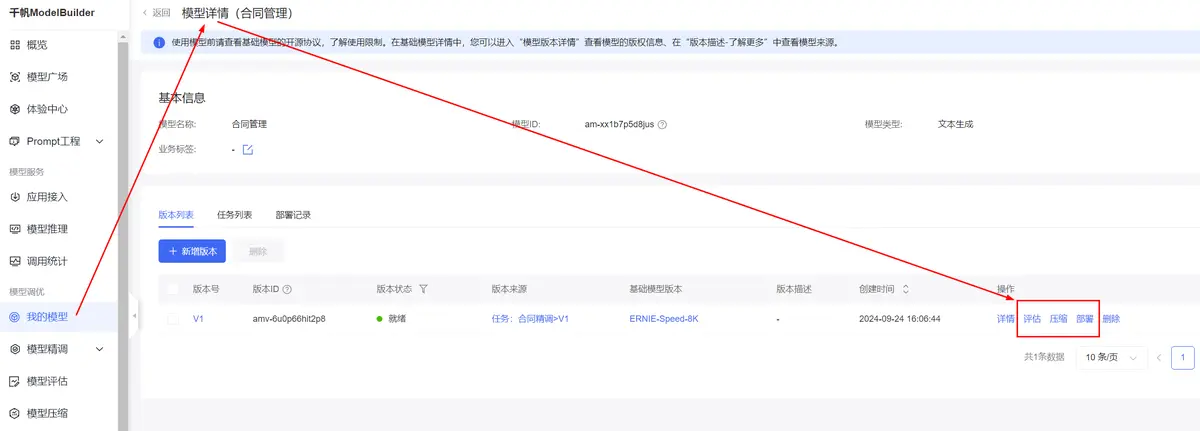
发布模型为我的模型。

发布后,可以在左侧我的模型菜单查看到发布后的模型。可以接下来评估、压缩等操作,最后部署模型为服务,即可被调用进行推理。
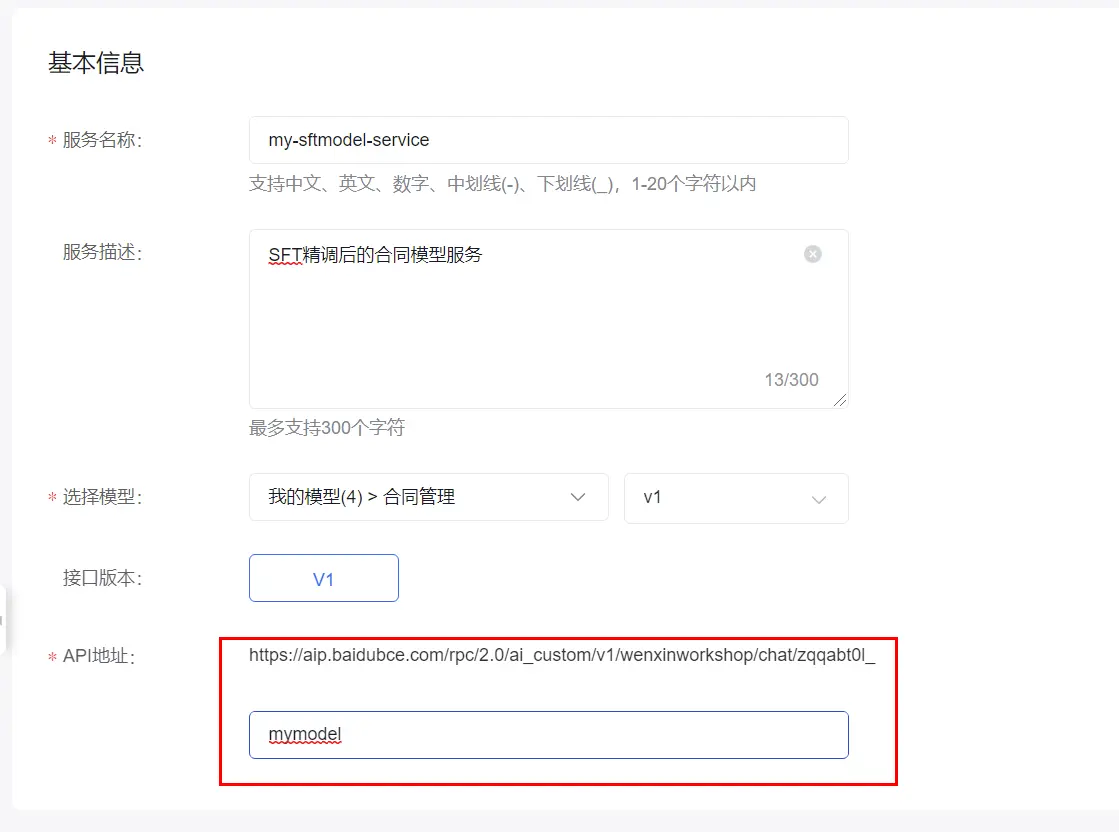
点击部署链接,开始申请资源进行模型部署,会生成模型的调用URL,注意图中的API地址是固定地址加上自定义的内容才是完整API地址,再参考百度提供的API或者SDK进行模型推理。
可以查看评估报告。
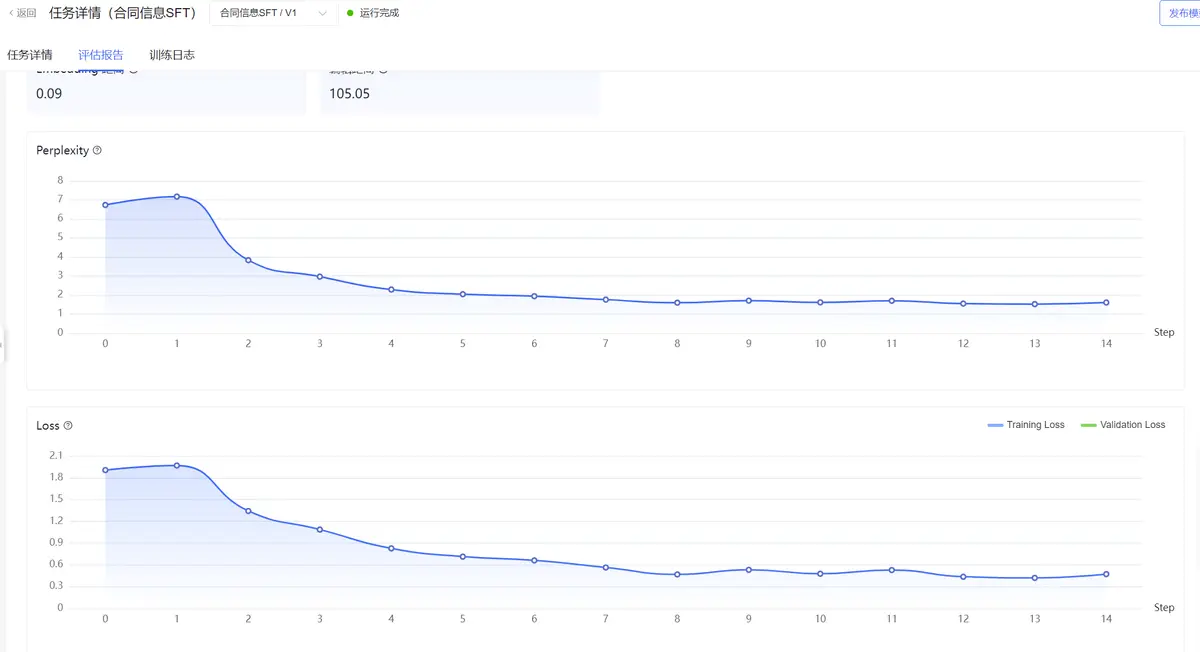
至此一个完成了模型SFT精调并发布为服务的过程。
评论
