AIGC之图片生成——基于检索的图生成
大模型开发/技术交流
- LLM
2天前79看过
背景:
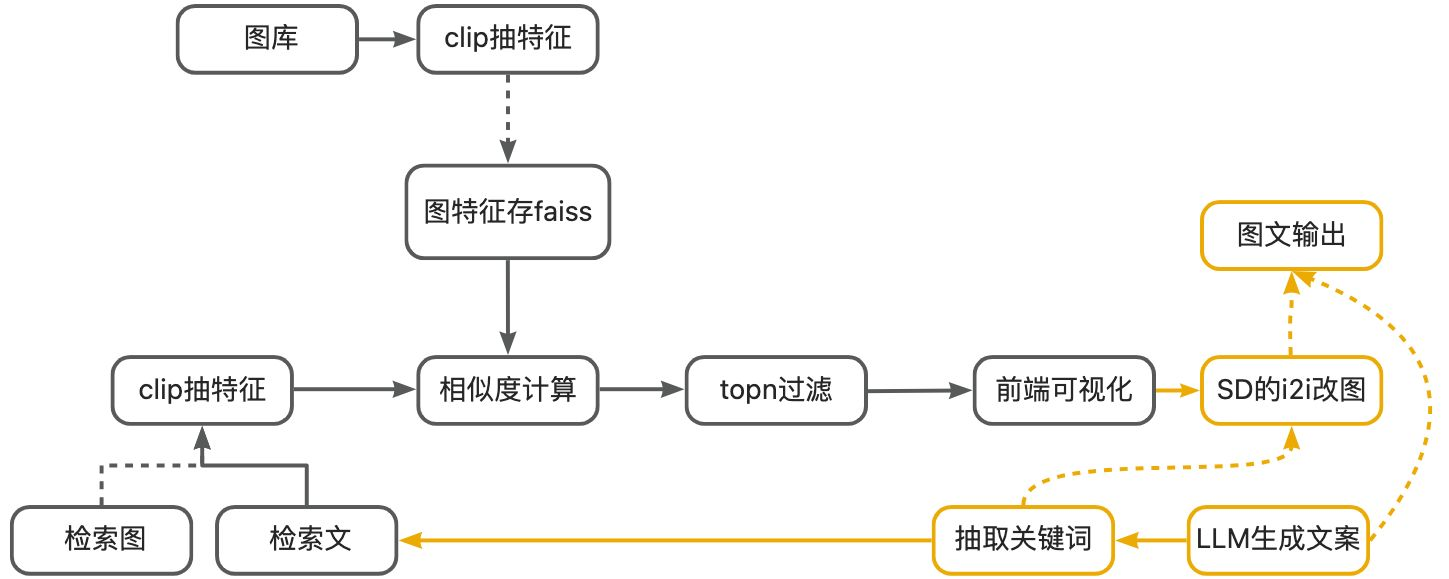
前面已经介绍了基于内容的图检索,今天我们来介绍基于检索的图生成。基于检索的图生成重点在于多模态的检索,生成图至少有两种应用:
1.大模型生成文案,抽取关键词,clip检索出合适的配图
2.基于文案检索出图,以检索图为基础继续加工
3.上面两部分的组合,做文案配图
在这部分不会详细介绍改图,只是给出了一个SD turbo的image to image的简单例子。理论上讲这部分的图加工可以很复杂,比如:分图层生成图、按物体修改、按色系修改、基于草图增删、组合合图......
但这部分的目的在于介绍基于检索的方式来做图的生成,介绍基于图检索方式对图质量提升的好处。所以后面的一些修改组合技术可以另开章节介绍。
正文:
基于内容的检索系统在文本配图上应用
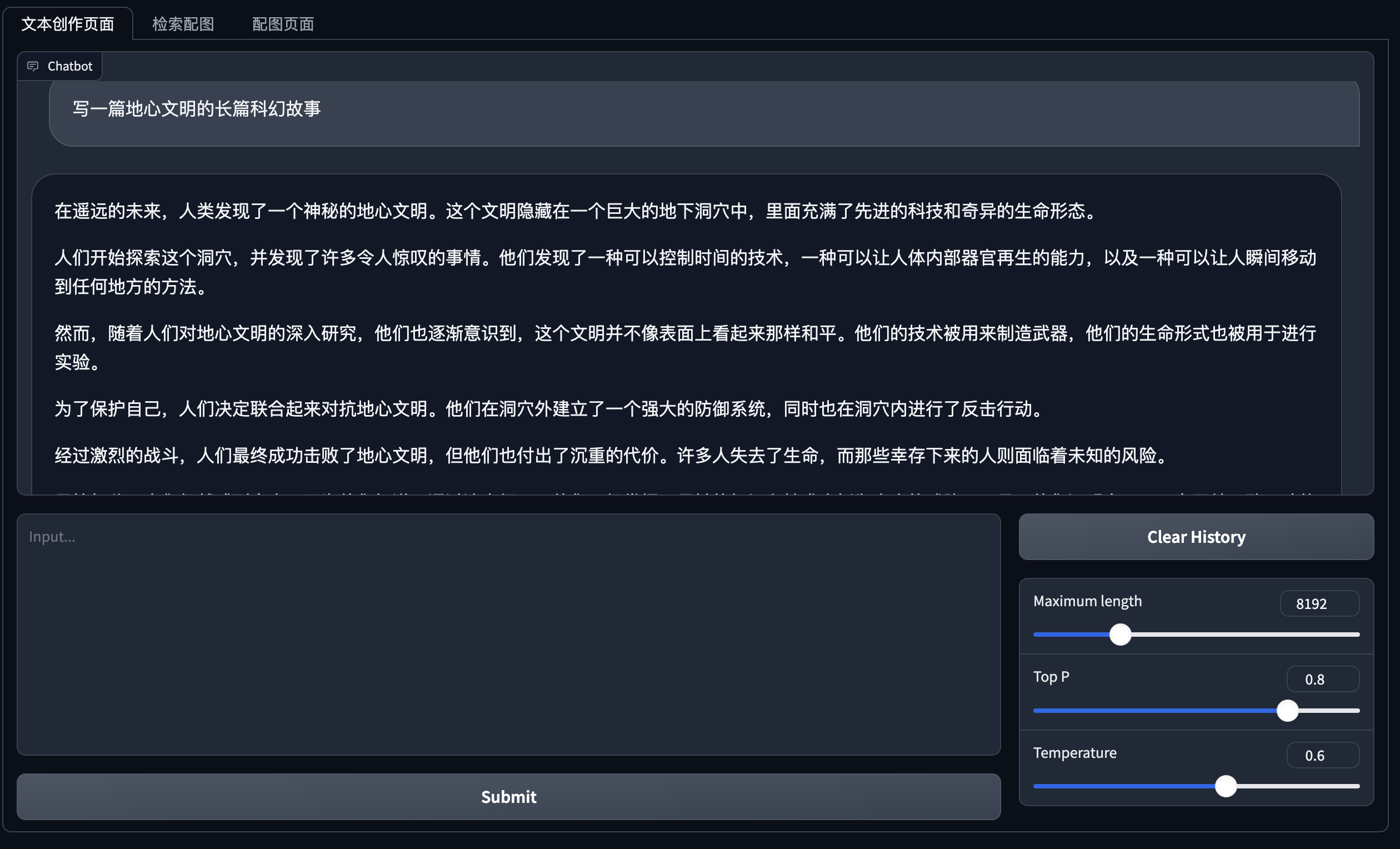
搭建qwen文本生成模型,代码如下:
# Initialize model and tokenizertokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B-Chat-int4", trust_remote_code=True,cache_dir="./")model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat-int4", device_map="auto", trust_remote_code=True,cache_dir="./").eval()model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat-int4", trust_remote_code=True,cache_dir="./")def predict(history, max_length, top_p, temperature):stop = StopOnTokens()messages = []for idx, (user_msg, model_msg) in enumerate(history):if idx == len(history) - 1 and not model_msg:messages.append({"role": "user", "content": user_msg})breakif user_msg:messages.append({"role": "user", "content": user_msg})if model_msg:messages.append({"role": "assistant", "content": model_msg})print("\n\n====conversation====\n", messages)model_inputs = tokenizer.apply_chat_template(messages,add_generation_prompt=True,tokenize=True,return_tensors="pt").to(next(model.parameters()).device)streamer = TextIteratorStreamer(tokenizer, timeout=60, skip_prompt=True, skip_special_tokens=True)generate_kwargs = {"input_ids": model_inputs,"streamer": streamer,"max_new_tokens": max_length,"do_sample": True,"top_p": top_p,"temperature": temperature,"stopping_criteria": StoppingCriteriaList([stop]),"repetition_penalty": 1.2,}t = Thread(target=model.generate, kwargs=generate_kwargs)t.start()for new_token in streamer:if new_token != '':history[-1][1] += new_tokenyield historywith gr.Blocks() as demo:with gr.Tab("文本创作页面"):#gr.HTML("""<h1 align="center">ChatGLM3-6B Gradio Simple Demo</h1>""")chatbot = gr.Chatbot()with gr.Row():with gr.Column(scale=4):with gr.Column(scale=12):user_input = gr.Textbox(show_label=False, placeholder="Input...", lines=10, container=False)with gr.Column(min_width=32, scale=1):submitBtn = gr.Button("Submit")with gr.Column(scale=1):emptyBtn = gr.Button("Clear History")max_length = gr.Slider(0, 32768, value=8192, step=1.0, label="Maximum length", interactive=True)top_p = gr.Slider(0, 1, value=0.8, step=0.01, label="Top P", interactive=True)temperature = gr.Slider(0.01, 1, value=0.6, step=0.01, label="Temperature", interactive=True)def user(query, history):return "", history + [[parse_text(query), ""]]submitBtn.click(user, [user_input, chatbot], [user_input, chatbot], queue=False).then(predict, [chatbot, max_length, top_p, temperature], chatbot)emptyBtn.click(lambda: None, None, chatbot, queue=False)
类似openai API接口请求的前端代码如下,openai API服务端代码可以直接看我项目库代码。
if prompt := st.chat_input():st.session_state.messages.append({"role": "user", "content": prompt})st.chat_message("user").write(prompt)print(st.session_state.messages)messages =[]messages.append({"role": "user", "content": prompt})history_mssg.append({"role": "user", "content":str(st.session_state.messages)+ prompt})#print(history_mssg)response = openai.ChatCompletion.create(model="Qwen", messages=history_mssg,#st.session_state.messages,stream=False,stop=[])msg = response.choices[0].message.contentassistant_mssg = {"role": "assistant", "content": msg}st.session_state.messages.append({"role": "assistant", "content": msg})history_mssg.append(assistant_mssg)st.chat_message("assistant").write(msg)
在LLM的交互界面让模型生成你要的文本,生成完在你需要配图的地方,
1.输入:“抽取上面文字的关键词”得到LLM的回答就是你的检索图的query词(这部分后面可以做到按钮方式点击直接传到query地方检索);
2.然后输入“把上面的关键词翻译成英文,英文输出到一行”,这部分就可以作为你后面image2image的prompt
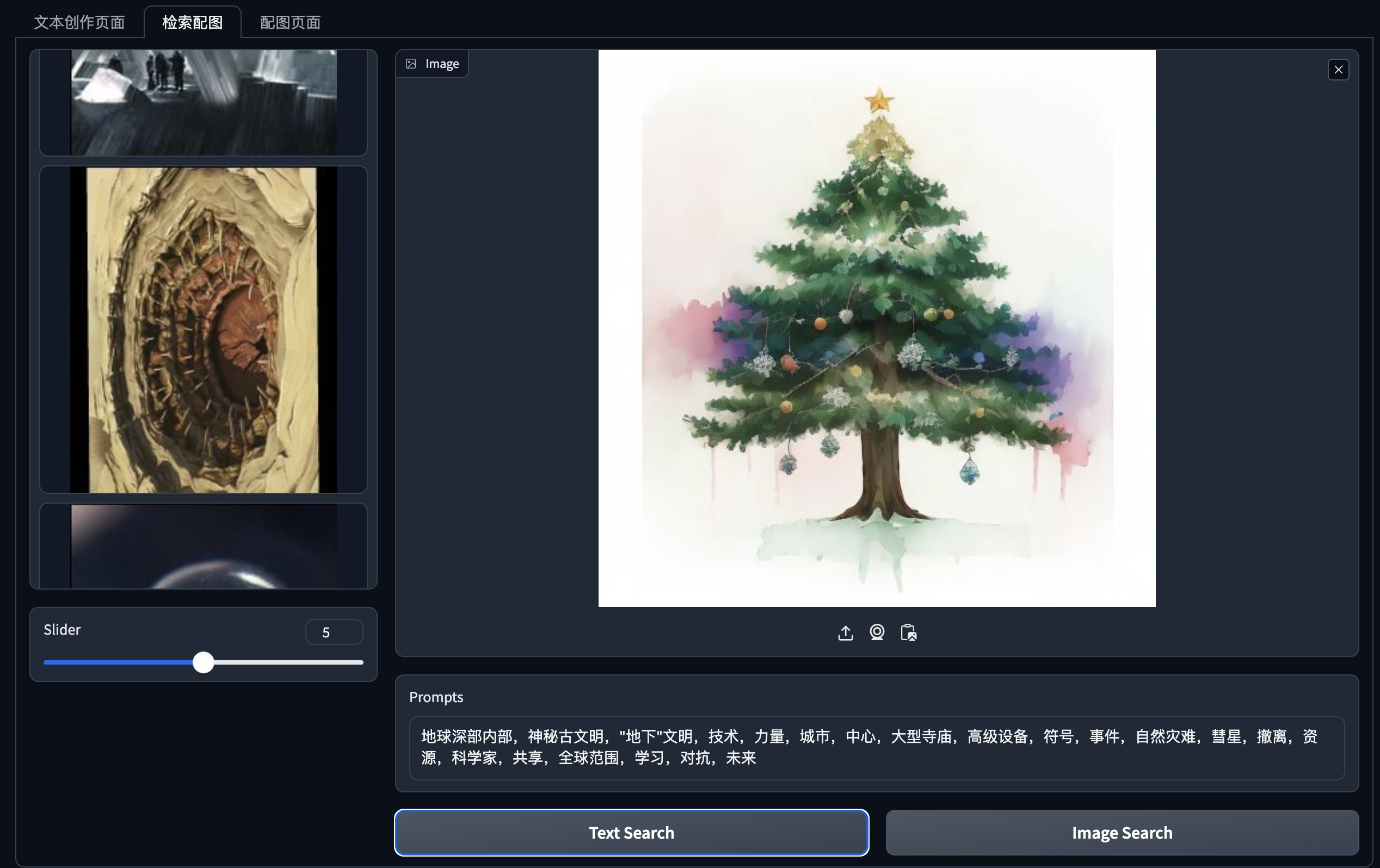
基于内容的检索系统在图生成上的应用
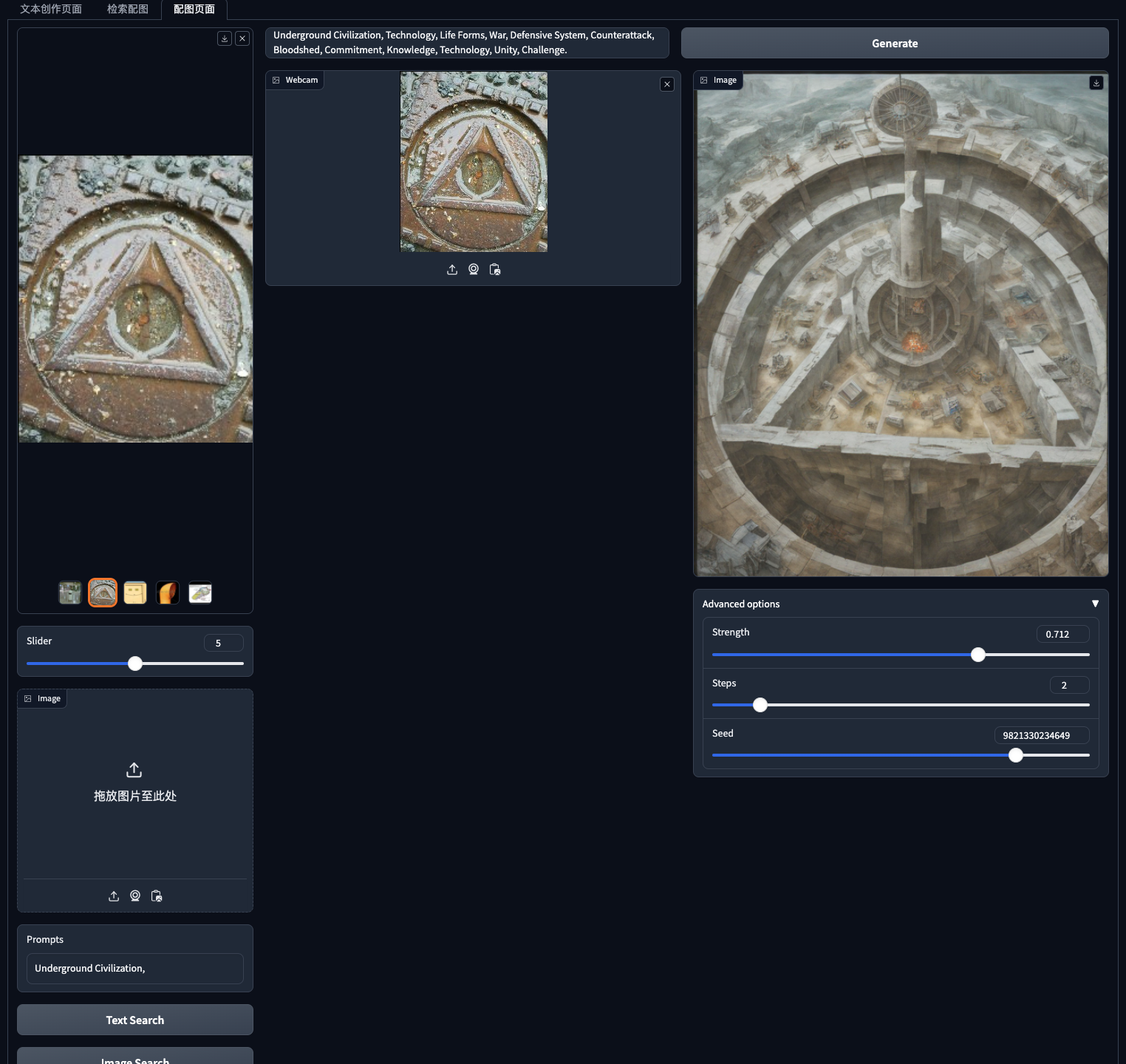
这部分会用到stable turbo用来对检索出来的图,通过prompt方式来修改。
1.通过对生成文本抽取关键词,检索到图
2.从检索中图中选择一张复制到参考图位置
3.把抽取的关键词翻译成英文promt,用stable turbo改图
stable turbo具体代码如下:
if SAFETY_CHECKER == "True":i2i_pipe = AutoPipelineForImage2Image.from_pretrained("stabilityai/sdxl-turbo",cache_dir = "./",torch_dtype=torch_dtype,variant="fp16" if torch_dtype == torch.float16 else "fp32",)t2i_pipe = AutoPipelineForText2Image.from_pretrained("stabilityai/sdxl-turbo",cache_dir = "./",torch_dtype=torch_dtype,variant="fp16" if torch_dtype == torch.float16 else "fp32",)else:i2i_pipe = AutoPipelineForImage2Image.from_pretrained("stabilityai/sdxl-turbo",safety_checker=None,cache_dir = "./",torch_dtype=torch_dtype,variant="fp16" if torch_dtype == torch.float16 else "fp32",)t2i_pipe = AutoPipelineForText2Image.from_pretrained("stabilityai/sdxl-turbo",safety_checker=None,cache_dir = "./",torch_dtype=torch_dtype,variant="fp16" if torch_dtype == torch.float16 else "fp32",)t2i_pipe.to(device=torch_device, dtype=torch_dtype).to(device)t2i_pipe.set_progress_bar_config(disable=True)i2i_pipe.to(device=torch_device, dtype=torch_dtype).to(device)i2i_pipe.set_progress_bar_config(disable=True)def resize_crop(image, size=512):image = image.convert("RGB")w, h = image.sizeimage = image.resize((size, int(size * (h / w))), Image.BICUBIC)return imageasync def predict_image(init_image, prompt, strength, steps, seed=1231231):if init_image is not None:init_image = resize_crop(init_image)generator = torch.manual_seed(seed)last_time = time.time()if int(steps * strength) < 1:steps = math.ceil(1 / max(0.10, strength))results = i2i_pipe(prompt=prompt,image=init_image,generator=generator,num_inference_steps=steps,guidance_scale=0.0,strength=strength,width=512,height=512,output_type="pil",)else:generator = torch.manual_seed(seed)last_time = time.time()results = t2i_pipe(prompt=prompt,generator=generator,num_inference_steps=steps,guidance_scale=0.0,width=512,height=512,output_type="pil",)print(f"Pipe took {time.time() - last_time} seconds")nsfw_content_detected = (results.nsfw_content_detected[0]if "nsfw_content_detected" in resultselse False)if nsfw_content_detected:gr.Warning("NSFW content detected.")return Image.new("RGB", (512, 512))return results.images[0]
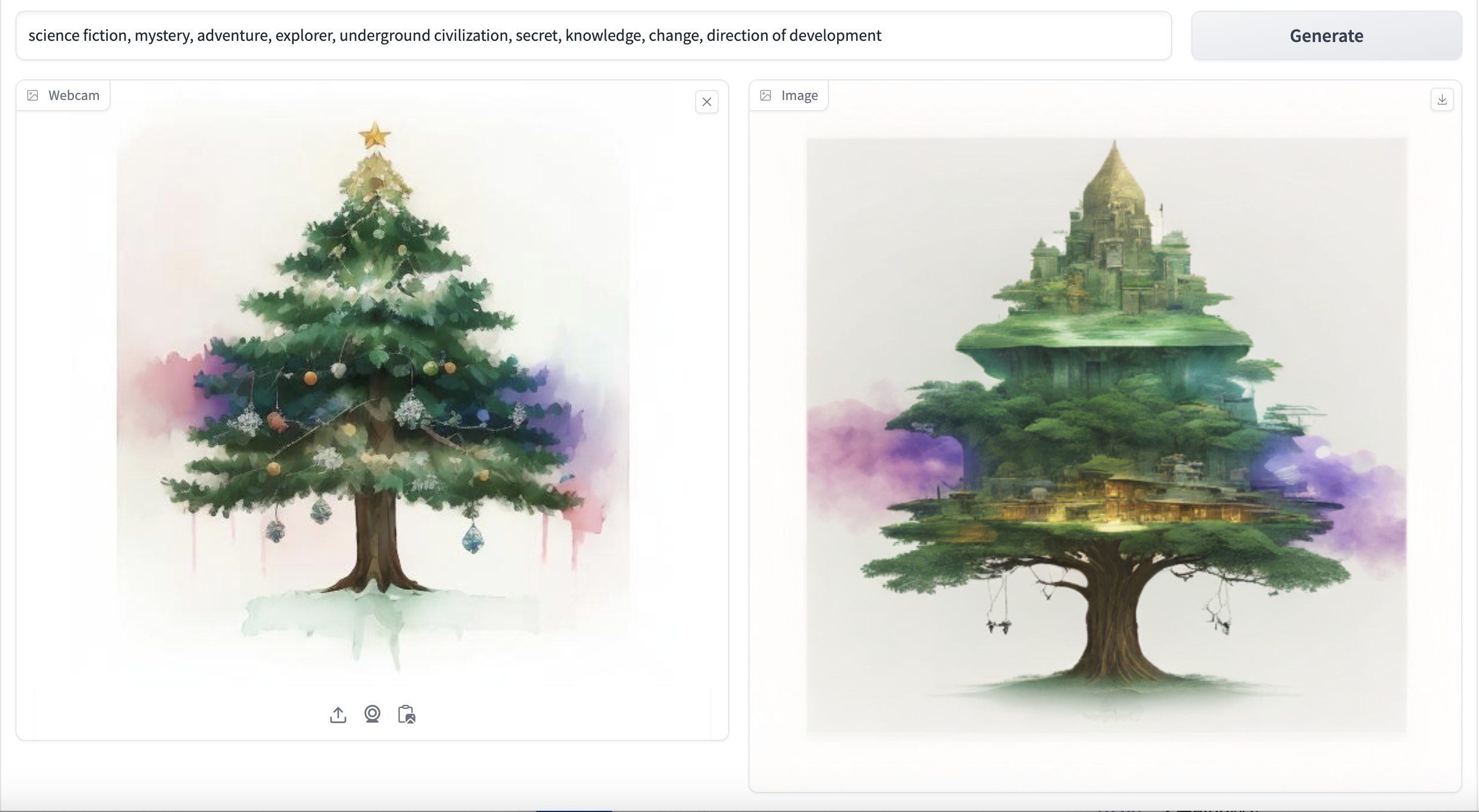
界面可视化部分代码如下:
with gr.Tab("配图页面"):init_image_state = gr.State()with gr.Row():with gr.Column(scale=1):gallery = gr.Gallery(label="Generated images", show_label=False,elem_id="gallery",show_share_button=True,columns=[1], rows=[5], object_fit="contain", height="auto")slider = gr.Slider(0, 10, step=1)input_image = gr.Image( type="pil")text_prompt = gr.Textbox(label="Search Word")with gr.Row():text_button = gr.Button(value="Text Search")image_button = gr.Button(value="Image Search")with gr.Column(elem_id="container",scale=4):with gr.Row():prompt = gr.Textbox(placeholder="Insert your prompt here:",#scale=5,lines=10,container=False,)generate_bt = gr.Button("Generate")#, scale=1)with gr.Row():with gr.Column():image_input = gr.Image(sources=["upload", "webcam", "clipboard"],label="Webcam",type="pil",)with gr.Column():image = gr.Image(type="filepath")with gr.Accordion("Advanced options", open=False):strength = gr.Slider(label="Strength",value=0.7,minimum=0.0,maximum=1.0,step=0.001,)steps = gr.Slider(label="Steps", value=2, minimum=1, maximum=10, step=1)seed = gr.Slider(randomize=True,minimum=0,maximum=12013012031030,label="Seed",step=1,)image_button.click(image_search_image, inputs = [input_image,slider], outputs =[gallery])text_button.click(text_search_image, inputs = [text_prompt,slider], outputs =[gallery])inputs = [image_input, prompt, strength, steps, seed]generate_bt.click(fn=predict_image, inputs=inputs, outputs=image, show_progress=False)prompt.change(fn=predict_image, inputs=inputs, outputs=image, show_progress=False)steps.change(fn=predict_image, inputs=inputs, outputs=image, show_progress=False)seed.change(fn=predict_image, inputs=inputs, outputs=image, show_progress=False)strength.change(fn=predict_image, inputs=inputs, outputs=image, show_progress=False)
小结:
这篇文章介绍了如何基于clip检索到的图给文章配图,进一步介绍了如何基于检索到的图做图的生成修改。文章虽然只是简单的介绍了基于image2image用关键词prompt方式来改图的方法,但这个只是给大家一个思路。实际上还有很多的基于检索到的图改图方法大家可以基于自己需要去尝试。这篇文章的目的在于强调合启发大家基于检索生成图的思考。到此你就拥有一个基于检索的配图、改图的简单工具。其实大家也看到了图库的重要性、以及检索准确性的重要性。如果图库质量好、检索质量好后面的创作任务事半功倍。所以真正的功夫还在数据,这里面可以搞的东西很多,后面会再用几篇文章简单介绍。
————————————————
版权声明:本文为稀土掘金博主「liangsh01」的原创文章
如有侵权,请联系千帆社区进行删除
评论
