
【千帆SDK】如何使用千帆Python SDK搭配预置大模型服务进行批量推理
大模型开发/技术交流
- LLM
- 大模型推理
- API
1月12日2428看过
在 0.2.6 版本中,千帆Python SDK新增了对批量推理的支持,欢迎各位开发者使用体验!
使用该功能需要视情况开通千帆的模型服务,以确保您的账号可以调用您想进行批量推理的服务。
您是否有如下场景诉求?
场景1:我有测试数据,但是不想一条数据一条数据去测试,希望能够批量拿到测试结果
场景2:我有测试数据,希望对比不同大模型的返回结果,希望能够批量拿到结果
场景3:我有测试数据,希望能够自定义prompt,能够使用特定prompt,让大模型帮忙对这批数据进行分类。
场景4:我想测试一下千帆大模型的性能,发送100条数据,查看每一条数据返回延时
使用指南
使用千帆SDK实现批量推理相关场景需求,具体参数详见cookbook,此处介绍几个典型场景的应用。
场景1: 将多条测试数据保存成数据集,进行批量推理测试,拿到测试结果
测试数据集:
import authfrom qianfan.dataset import Datasetfrom qianfan.common import Promptdataset_file_path = "data_file/qa_pair.csv"dataset_input_column_list = ["prompt"]# 预期输出列列名,当数据集为对话类数据集时必填,为非对话数据集时选填。# 对应列的数据会在推理结果中出现reference_column = "response"ds = Dataset.load(data_file=dataset_file_path, input_columns=dataset_input_column_list, reference_column=reference_column)# 预览数据格式print(ds.list(0))result = ds.test_using_llm(service_model="ERNIE-Bot-turbo")print(result.list(0))dataset_save_file_path = "output_file.csv"result.save(data_file=dataset_save_file_path)## 将测试结果保存到本地
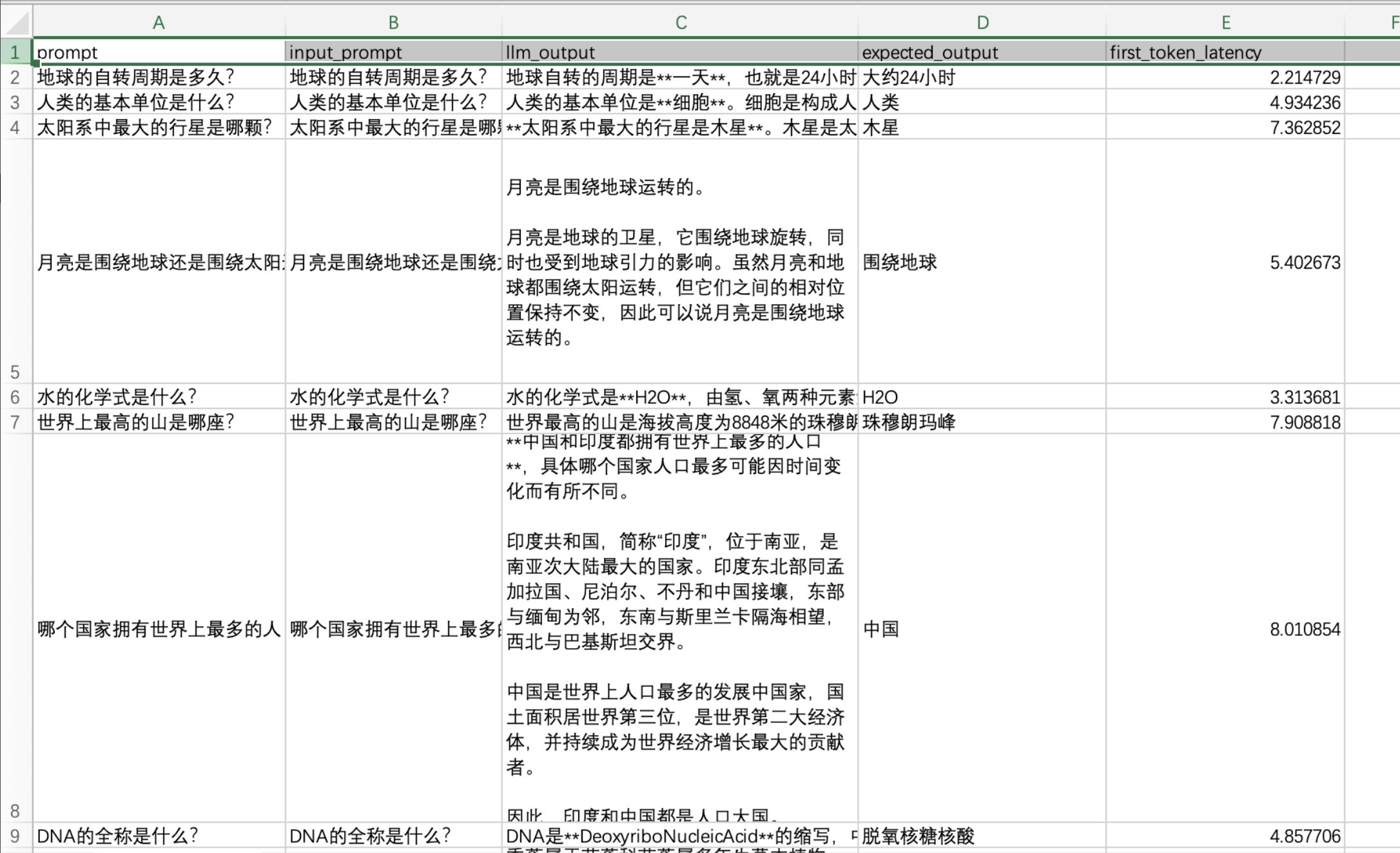
得到结果示例如下,其中llm_output为模型输出结果
场景2: 通过数据集来比较不同大模型的推理结果
import qianfanqianfan.Completion.models():{'AquilaChat-7B','BLOOMZ-7B','ChatGLM2-6B-32K','ChatLaw','CodeLlama-7b-Instruct','EB-turbo-AppBuilder','ERNIE-Bot','ERNIE-Bot-4','ERNIE-Bot-8k','ERNIE-Bot-turbo','ERNIE-Speed','Llama-2-13b-chat','Llama-2-70b-chat','Llama-2-7b-chat','Qianfan-BLOOMZ-7B-compressed','Qianfan-Chinese-Llama-2-13B','Qianfan-Chinese-Llama-2-7B','SQLCoder-7B','XuanYuan-70B-Chat-4bit','Yi-34B-Chat'}
使用预置服务
-
以上服务都可以service_model传参,进行推理调用。修改 result = ds.test_using_llm(service_model="ERNIE-Bot-turbo") 中的service_model参数来选择需要进行推理的大模型。
然后针对自定义服务,可以使用下面的方案
-
修改service_endpoint参数,例如 result = ds.test_using_llm(service_endpoint="completions_pro")
如果需要比较不同大模型的推理效果,可以使用同一个数据集,修改service_endpoint/service_model参数,跑批生成两个文件,然后对比llm_output的输出结果。
场景3:使用自定义人设进行批量推理
请将qianfan sdk版本更新至0.2.6
pip install -U "qianfan>=0.2.6"
可以通过system_prompt参数来传递大模型需要遵循的人设,demo如下:
测试数据集:
你是文心千帆大模型平台的一个客服问题分类员 需要针对用户问题进行分类 主要问题分类包含数据问题、微调问题、评估问题、API问题、计费管理、产品文档问题、QPS问题、错误码问题
import authimport asyncioimport nest_asynciofrom qianfan.dataset import Datasetfrom qianfan.common import Promptdataset_file_path = "data_file/qa_classification.csv"dataset_input_column_list = ["prompt"]# 预期输出列列名,当数据集为对话类数据集时必填,为非对话数据集时选填。# 对应列的数据会在推理结果中出现reference_column = "response"ds = Dataset.load(data_file=dataset_file_path, input_columns=dataset_input_column_list, reference_column=reference_column)# 预览数据格式# print(ds.list(0))# 添加系统人设result = ds.test_using_llm(service_model="ERNIE-Bot-4",system_prompt="你是文心千帆大模型平台的一个客服问题分类员 需要针对用户问题进行分类 主要问题分类包含数据问题、微调问题、评估问题、API问题、计费管理、产品文档问题、QPS问题、错误码问题")# print(result.list(0))dataset_save_file_path = "output1.csv"result.save(data_file=dataset_save_file_path)
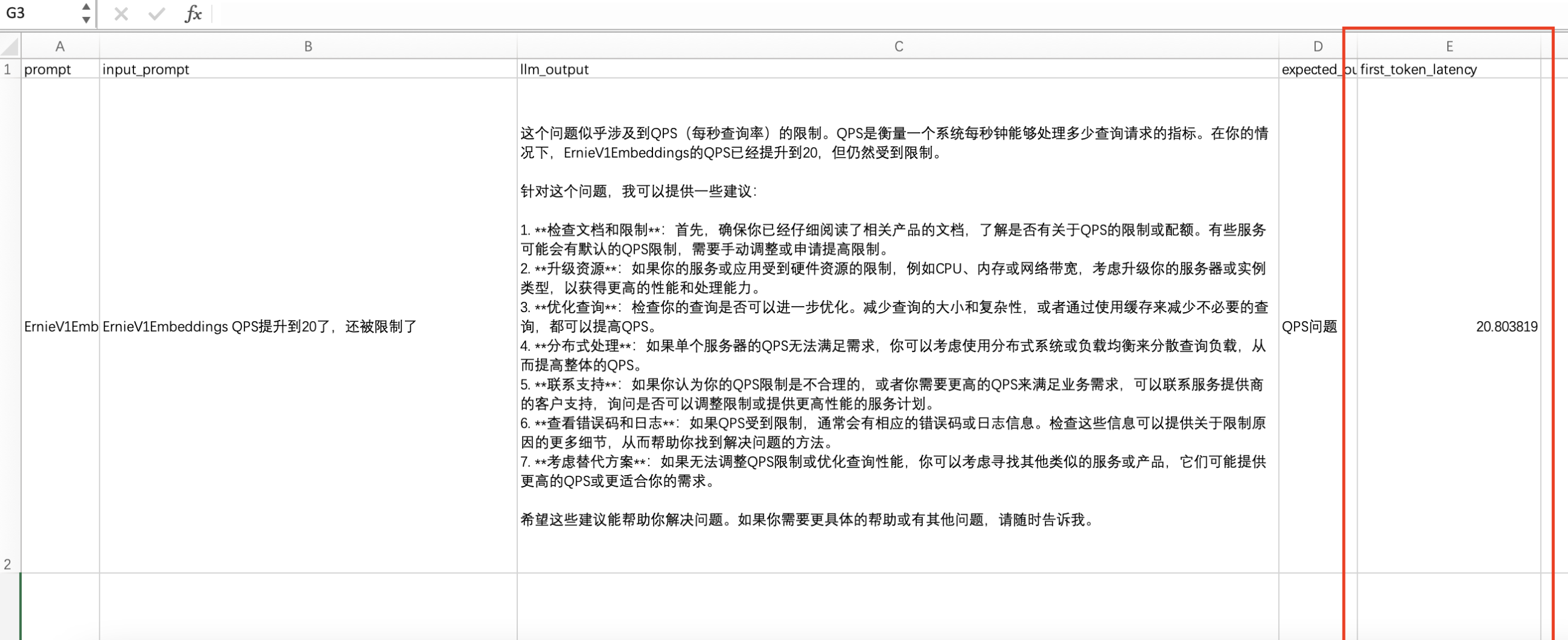
测试结果参考:

注意:测试结果准确度受模型效果影响,建议使用eb-4
场景4: 测试大模型性能
请将qianfan sdk版本更新至0.2.6
pip install -U "qianfan>=0.2.6"
first token latency:指从输入文本到生成第一个单词的延迟。即用户在提问后等待出第一个结果的时间。也是实际应用中业务比较关注的另一个延迟指标。
-
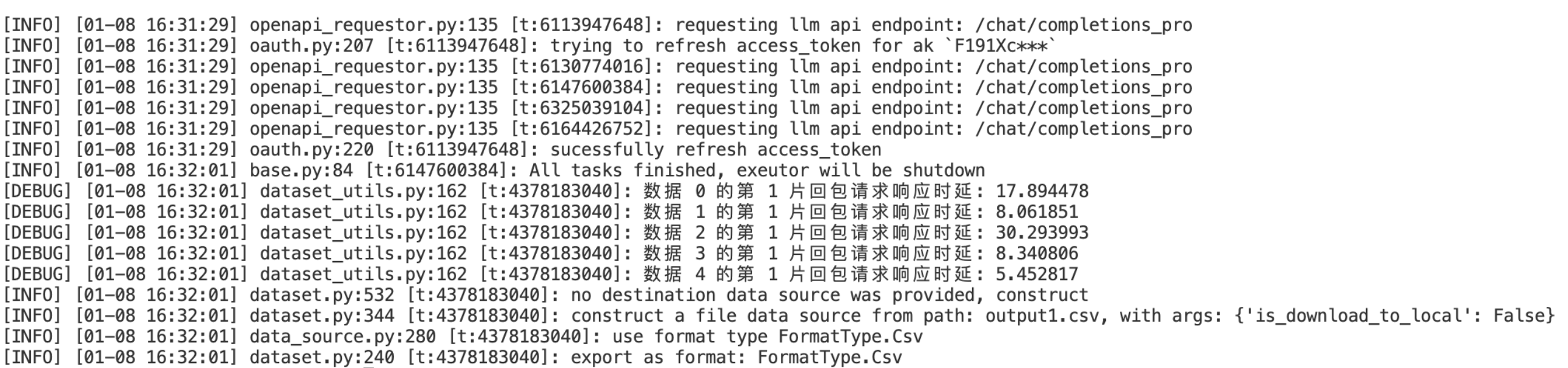
在最终生成文件中,关注first_token_latency列
-
将日志等级修改为DEBUG,在返回请求中,查看每条消息时延
场景5: 自定义 Prompt Template
请将qianfan sdk版本更新至0.2.6
pip install -U "qianfan>=0.2.6"
用户可以使用 SDK 的 Prompt 对象,在批量推理中使用提示词模板,设置好的 Prompt 会在批量推理时使用输入数据进行渲染,并且作为实际的输入内容给到大模型
from qianfan.dataset import Datasetfrom qianfan.common import Promptdataset_file_path = "data_file/qa_classification.csv"dataset_input_column_list = ["prompt"]# 预期输出列列名,当数据集为对话类数据集时必填,为非对话数据集时选填。# 对应列的数据会在推理结果中出现reference_column = "response"ds = Dataset.load(data_file=dataset_file_path, input_columns=dataset_input_column_list, reference_column=reference_column)# 预览数据格式# print(ds.list(0))# 使用 Prompt 对象。请自定义 template 的内容,使用 {} 来在模板中引用输入列的数据prompt_template = Prompt(template='请回答下列问题: {prompt}')result = ds.test_using_llm(service_model="ERNIE-Bot-4", prompt_template=prompt_template)# print(result.list(0))dataset_save_file_path = "output1.csv"result.save(data_file=dataset_save_file_path)
cookbook地址
https://github.com/baidubce/bce-qianfan-sdk/blob/main/cookbook/dataset/batch_inference_using_dataset.ipynb
重要参数介绍
-
os.environ["QIANFAN_QPS_LIMIT"] = "1" : 调用qps限制,值可以是任意大于0的正数
-
os.environ['QIANFAN_LLM_API_RETRY_COUNT'] = "3"
-
enable_log(logging.INFO):表示日志等级,视情况设置为INFO或DEBUG
同步调用和异步调用的说明
同步调用和异步调用在最终得到的结果层面上来讲是一致的,区别在于内部运行代码时使用的方式不一样
同步调用底层是线程池实现,多个线程同时竞争一把 GIL 来处理任务和网络请求
异步调用底层使用 asyncio 与异步函数实现,在运行时可以利用 Python 的协程优势,可以更好的加入到客户的异步代码中(在异步代码中进行同步调用会直接堵死整个事件循环,使得协程机制失效)
评论
