
【千帆SDK+Prompt】针对Stable Diffusion-XL的prompt优化
大模型开发/技术交流
- Prompt
- LLM
- 大模型推理
6月12日283看过
💡学习前小提示
请大家点击链接并加🌟:https://github.com/baidubce/bce-qianfan-sdk
【千帆SDK】针对Stable Diffusion-XL的prompt优化
-
Stable Diffusion-XL(以下简称“SD-XL”)是当下最常用的文生图扩散模型。本文将介绍如何利用prompt优化Stable Diffusion-XL的生成效果。
-
本篇Cookbook分为两个部分:
-
第一部分通过两个常见的prompt场景案例,带您快速上手我们的优化方法。
-
第二部分通过基于中文应用场景的测试,验证了我们的优化方法的可行性和有效性。
-
安装&导入依赖库
首先,安装评估部分所需要的所有包
!pip install -r requirement.txt
引入我们需要的所有包,加载Pickscore的模型:
import os,io,qianfan,torch,statisticsimport ae_scoreimport matplotlib.pyplot as pltimport numpy as npfrom PIL import Imageimport seaborn as snsfrom glob import globfrom qianfan.common import Promptfrom qianfan import Text2Image,Completionfrom tools import prompt_updatefrom tools import t2ifrom tools import generate_and_savefrom transformers import AutoProcessor, AutoModelfrom matplotlib.ticker import MaxNLocator# 定义文件路径infer_py_path = 'Pickscore-main/infer.py'raw_folder = 'raw'update_folder = 'update'# 将 infer.py 作为模块导入import syssys.path.append(os.path.dirname(infer_py_path))from infer import calc_probs
在此处输入您的鉴权信息
#初始化百度智能云的IAM ak, sk用于bos和千帆平台的鉴权os.environ['QIANFAN_ACCESS_KEY'] = 'your_access_key'os.environ['QIANFAN_SECRET_KEY'] = 'your_secret_key'
案例一:针对中文特异词汇的优化--夫妻肺片
-
夫妻肺片是一道经典的中国小吃,但是对于Stable-Diffusion来说可能是一种动物的器官,我们的prompt优化可以避免这样的错误。
-
这里以“夫妻肺片”为例,来展示我们的prompt优化针对中文歧义词的效果。
首先我们先创建一个简单的任务描述prompt:
pt = "夫妻肺片"#将文本转为LLM的prompt格式p = Prompt(pt)
使用优化前的prompt测试效果
#加载SD-XL并展示生成结果t2i(pt)
可以看到,SD-XL对于输入的prompt产生了误解,仅仅理解了字面意思,生成了器官的图片。
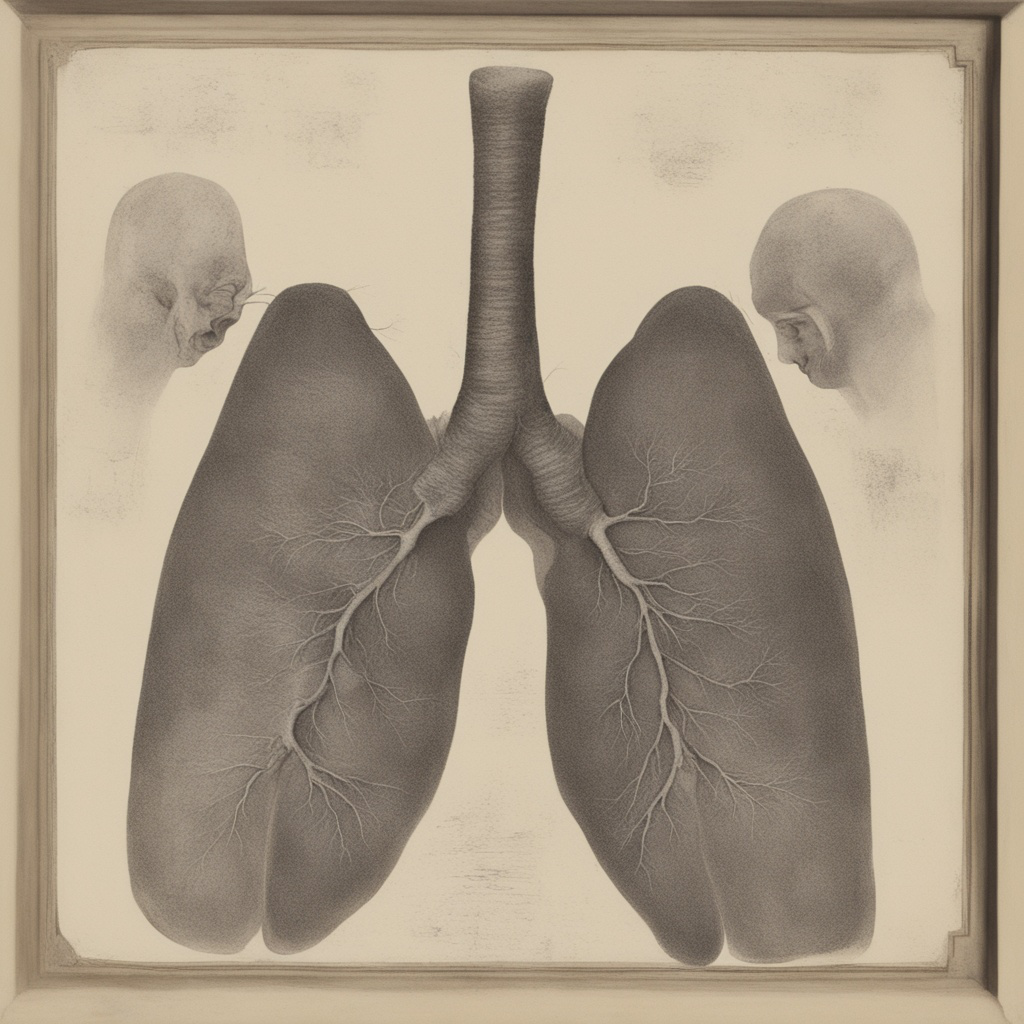
接下来,将上述prompt进行优化,提升图片的生成效果:
#将输入prompt进行优化output = prompt_update(pt)
A plate of Spicy Beef Slices with Beef Offal, drenched in chili oil, loaded with cilantro and peanuts, intricate textures, realistic texture details, bright colors, food photography, high contrast lighting, vibrant colors, appetizing, photorealistic, (detailed texture:1.3), high resolution, 8k, HDR, natural lighting
Negative prompt: text, logos, watermarks, out of frame, blurred, low contrast, messy, artificial lighting, discolored.
以下为优化prompt的生成效果展示:
#加载SD-XL并展示生成结果t2i(output)
在优化了prompt后,生成的图片解决了中英文的语言歧义,符合prompt的原意,而且提升了展示力。

案例二:针对简单提示词的扩写优化--一只高贵的柯基犬
-
还有一类prompt,它们在理解上并没有歧义,但是包含的细节极少,无法给到足够的提示,可能会导致生成效果不佳。
-
这里我们以"一只高贵的柯基犬"的任务为例,来展示我们的prompt优化针对扩展提示词的效果。
首先我们先创建一个简单的任务描述prompt:
pt = "一只高贵的柯基犬"#将文本转为LLM的prompt格式p = Prompt(pt)
使用优化前的prompt测试效果
#加载SD-XL并展示生成结果t2i(pt)
生成的图片大体符合提示词,但是细节缺失较多,整体画面不够生动。

接下来,将上述prompt进行优化,提升图片的生成效果:
#将输入prompt进行优化output = prompt_update(pt)
a regal Corgi, wearing a fancy collar and bowtie, elegant pose, soft fur, photorealistic, vibrant colors, detailed landscape, studio lighting, highly detailed, realistic shadows, HDR, (detailed fur:1.3), 8k
Negative prompt: text, logos, watermarks, out of frame, messy, blurry, mutated, deformed features, cartoon
以下为优化prompt的生成效果展示:
t2i(output)
图片的画面整体提升很大,将柯基犬的主体描绘得更加细致,整体构图更加协调,表现力更强

验证
-
为体现本方案的优化能力,在此使用了Pick Score和Aesthetics Score作为评价指标,以此验证可行性。
-
Pick Score: 衡量了初始的输入prompt和优化后的图片之间的关联度。用此指标来体现我们的优化没有偏出用户的主观意图。
-
Aesthetics Score: 衡量了优化后的图片的美观度。用此指标来衡量优化后的图片是否符合用户的审美需求。
测试集准备
根据DiffusionDB的数据集,我们构造了一个简单的中文prompt列表以供测试:
#中文prompt用于生成优化前的图片以及aesthestics score打分raw_prompt = ["黄昏谷仓画", "绿树成荫,花团锦簇","翱翔在山间的凤凰","宫保鸡丁","一个摆满玩具机器人的房间","一座有许多雕像在里面的丛林寺庙","两匹马的黑白照片","一座庞大的宫殿,皇帝坐在正中央,大臣们骑着扫帚在殿内朝拜,有的大臣在汇报工作,整个大殿金碧辉煌","一只可爱的小猫","一座哥特式建筑","一对肝胆相照的兄弟","一只蜗牛","一个挑灯夜读的高中生,他坐在电脑桌前","咖啡色的天空,绿色的湖,蓝色的草地","神圣的金字塔,门口坐着狮身人面像","两只猫鼬在野外和热气球在一起","一幅描绘白裙少女在雏菊田中翩翩起舞的画作","春天来了,万物复苏","火光冲天的未来飞船","一条狗,一只猫,耶稣在中间照顾所有的生物,有人,有植物","蚂蚁上树","夫妻肺片","一只飞过山的凤凰","机器人大战","虫虫危机"]#英文prompt用于pickscore打分raw_prompt_eng = ["Twilight Barn Painting","Shady Green Trees and Blooming Flowers","The phoenix that soars in the mountains","Kung Pao Chicken","A Room Filled with Toy Robots","A Jungle Temple with Many Statues Inside","Black and White Photo of Two Horses","A Grand Palace with the Emperor in the Center, Ministers on Brooms Paying Homage, Some Reporting Work, the Entire Hall Gleaming with Gold","A Cute Kitten","A Gothic Building","Two Brothers with Deep Bonds","A Snail","A High School Student Studying Late at Night at a Computer Desk","Coffee-Colored Sky, Green Lake, Blue Grass","Sacred Pyramid with a Sphinx at the Entrance","Two Meerkats in the Wild with a Hot Air Balloon","A Painting of a Girl in a White Dress Dancing in a Daisy Field","Spring Arrives, Everything Awakens","A Futuristic Spaceship with Flames Bursting","A Dog, a Cat, and Jesus Caring for All Creatures, Including People and Plants","Stir-Fried Noodles with Minced Pork","Spicy Sliced Beef and Tripe","A Phoenix Flying Over a Mountain","Robot Battle","A Bug's Life"]
首先,将优化前的prompt对应图片保存到自定义的文件夹中
#将raw_prompt输入到SD-XL,生成图片并保存到当前目录下的raw文件夹generate_and_save(raw_prompt, "raw")
将输入的prompt进行批量优化
#定义一个空列表,用于存储优化后的promptupdate_prompt = []#依次遍历每一条rawdatafor pt in raw_prompt:p = prompt_update(pt)update_prompt.append(p)print(p)
A rustic barn in a serene valley at dusk, golden hour lighting, warm orange and purple hues, silhouette of trees in the distance, soft light streaming through cracks in the wooden walls, intricate details of weathered wood, (rustic atmosphere: 1.5), photorealistic, highly detailed, trending on artstation, realistic landscape, HDR, natural lighting
Negative prompt: text, logos, watermarks, out of frame, modern buildings, unnatural colors, cartoonish, simplified, flat colors, low resolution.
A rustic barn in a serene valley at dusk, golden hour lighting, warm orange and purple hues, silhouette of trees in the distance, soft light streaming through cracks in the wooden walls, intricate details of weathered wood, (rustic atmosphere: 1.5), photorealistic, highly detailed, trending on artstation, realistic landscape, HDR, natural lighting
Negative prompt: text, logos, watermarks, out of frame, modern buildings, unnatural colors, cartoonish, simplified, flat colors, low resolution.
A dense forest with lush green trees creating a cool canopy, bright flowers blooming in clusters, vibrant colors, photorealistic, natural lighting, detailed foliage, intricate patterns, (trees:1.2), (flowers:1.1), high resolution, 8k, HDR, realistic landscape
Negative prompt: text, logos, watermarks, out of frame, artificial, blurry, unnatural colors, ugly, messy, unrealistic lighting.
A dense forest with lush green trees creating a cool canopy, bright flowers blooming in clusters, vibrant colors, photorealistic, natural lighting, detailed foliage, intricate patterns, (trees:1.2), (flowers:1.1), high resolution, 8k, HDR, realistic landscape
Negative prompt: text, logos, watermarks, out of frame, artificial, blurry, unnatural colors, ugly, messy, unrealistic lighting.
A noble Corgi, regal posture, lush fur, intricate patterns, elegant collar and leash, indoor setting, soft lighting, photorealistic, (fur details:1.5), (noble features:1.3), highly detailed, professional photography, 8k, HDR, realistic lighting
Negative prompt: text, logos, watermarks, out of frame, messy fur, blurry, cartoonish, deformed features, artificial lighting.
A noble Corgi, regal posture, lush fur, intricate patterns, elegant collar and leash, indoor setting, soft lighting, photorealistic, (fur details:1.5), (noble features:1.3), highly detailed, professional photography, 8k, HDR, realistic lighting
Negative prompt: text, logos, watermarks, out of frame, messy fur, blurry, cartoonish, deformed features, artificial lighting.
A delicious dish of Kung Pao Chicken, diced chicken breast, chili peppers, peanuts, and scallions, served on a white plate, vibrant colors, photorealistic, food photography, close-up shot, richly textured, steaming hot, appetizing, culinary presentation, (detailed dish:1.3), high resolution, 8k, HDR, natural lighting
Negative prompt: text, logos, watermarks, out of frame, unattractive, discolored, unappetizing, messy, artificial, poorly lit
A delicious dish of Kung Pao Chicken, diced chicken breast, chili peppers, peanuts, and scallions, served on a white plate, vibrant colors, photorealistic, food photography, close-up shot, richly textured, steaming hot, appetizing, culinary presentation, (detailed dish:1.3), high resolution, 8k, HDR, natural lighting
Negative prompt: text, logos, watermarks, out of frame, unattractive, discolored, unappetizing, messy, artificial, poorly lit
A room filled with toy robots, various designs and colors, realistic details, intricate mechanisms, colorful lights, futuristic decor, clean and organized, (robot details:1.5), (room setting:1.2), photorealistic, 8k, high-resolution scan, realistic lighting, HDR
...
#将update_prompt依次输入到SD-XL,生成图片并保存到当前目录下的update文件夹generate_and_save(update_prompt, "update")
通过Aesthetics Score评价优化方案的可行性
-
Aesthetics Score 是一种衡量图像美学素质的数值指标。
-
该指标的计算方法是将图像的不同视觉特征(如色彩、形状、线条、纹理、光照、透视、空间分布等)的重要程度进行加权,并将加权结果乘以相应的权重,得到的结果即为图像的美学得分。
-
美学得分的范围从 0 到 10,数值越高,图像的视觉效果越好。
首先,将未优化过的初始raw_prompt输入到模型中,得到优化前的分数,作为baseline。
# 构造 args 对象,用于传入/raw下的优化前的图片args = ae_score.argparse.Namespace(image_file_or_dir="raw",# 输入图像文件或文件夹路径save_csv=False,model=ae_score.MODEL,device=None)# 运行 main 函数raw_scores = ae_score.main(args)# 保存所有分数列表和分数期望raw_score = raw_scores[0]all_raws = []for lst in raw_scores[1]:all_raws.append(lst['score'])
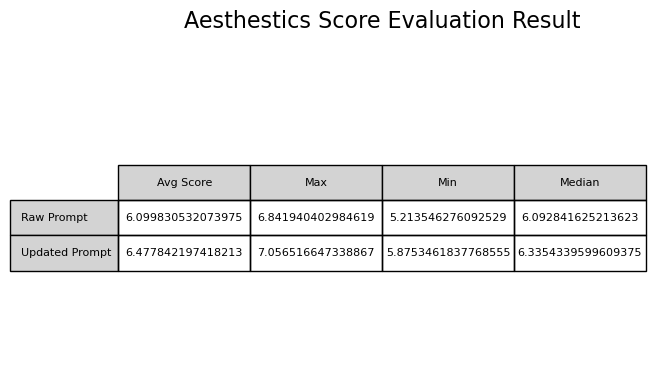
平均得分约为:6.099
接下来,对已优化的prompt生成的图片进行评测:
# 构造 args 对象,用于传入/update下的优化后的图片args = ae_score.argparse.Namespace(image_file_or_dir="update",# 输入图像文件或文件夹路径save_csv=False,model=ae_score.MODEL,device=None)# 运行 main 函数update_scores = ae_score.main(args)# 保存所有分数列表和分数期望update_score = update_scores[0]all_updates = []for lst in update_scores[1]:all_updates.append(lst['score'])
平均得分约为:6.478
-
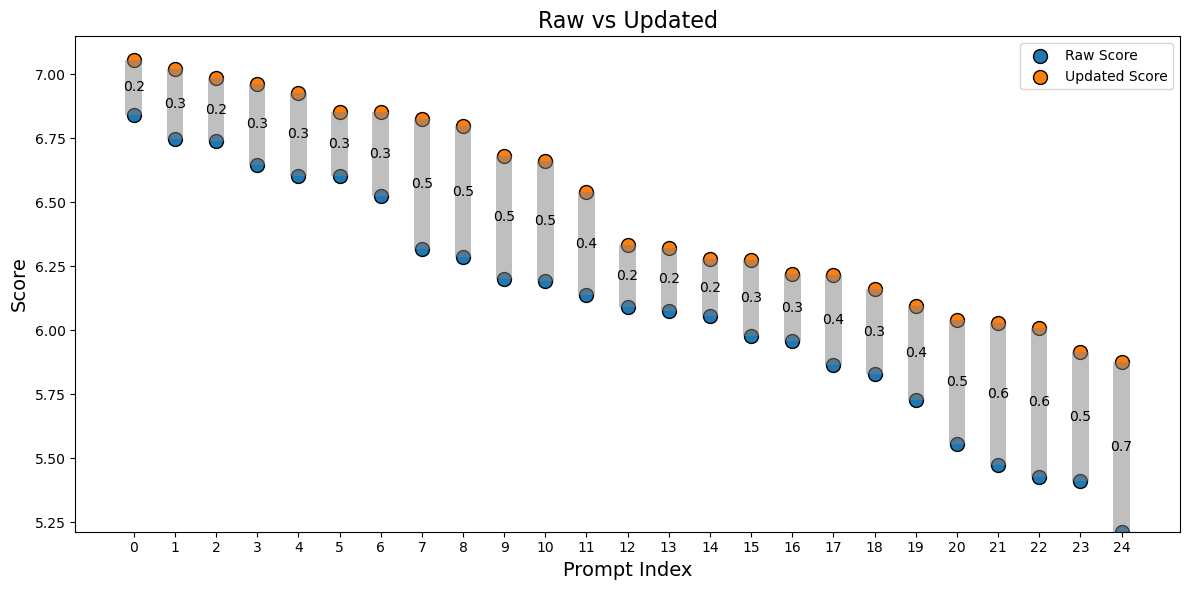
在总量为25的数据集上进行了Aesthetics score美学评分,最终我们的图片美化效果提升幅度接近6%。
-
从raw_prompt和update_prompt的aesthetics score分数对比图可以明显看到,针对每一条prompt的优化均有分数上的提升,且最大提升幅度达到了近13%。
raws = np.array(all_raws)updates = np.array(all_updates)# 计算最大值、最小值和中位数max_raw = np.max(raws)min_raw = np.min(raws)median_raw = np.median(raws)max_update = np.max(updates)min_update = np.min(updates)median_update = np.median(updates)raw_scores = all_rawsupdate_scores = all_updates# 计算差值diff_scores = np.array(update_scores) - np.array(raw_scores)# 绘制图表fig, ax = plt.subplots(figsize=(12, 6))# 绘制原始分数和更新后的分数ax.scatter(range(len(raw_scores)), raw_scores, marker='o', s=100, color='tab:blue', label='Raw Score', edgecolor='black', linewidth=1)ax.scatter(range(len(update_scores)), update_scores, marker='o', s=100, color='tab:orange', label='Updated Score', edgecolor='black', linewidth=1)# 添加柱子for i in range(len(raw_prompt)):height = update_scores[i] - raw_scores[i]ax.bar(i, height, bottom=raw_scores[i], color='gray', alpha=0.5, width=0.4)# 在柱子中间显示具体差值ax.text(i, raw_scores[i] + height/2, f'{height:.1f}', ha='center', va='center', color='black', fontsize=10)# 设置图表标题和轴标签ax.set_title('Raw vs Updated', fontsize=16)ax.set_xlabel('Prompt Index', fontsize=14)ax.set_ylabel('Score', fontsize=14)# 设置X轴刻度标签为序号ax.set_xticks(range(len(raw_prompt)))# 添加图例ax.legend()plt.tight_layout()plt.show()# 创建一个 3x3 的表格fig, ax = plt.subplots(figsize=(8, 4))ax.axis('off') # 隐藏坐标轴# 设置表格的行列数rows = 2cols = 4# 创建数据data = [[raw_score, max_raw, min_raw,median_raw] ,[update_score, max_update, min_update,median_update]]# 创建表头row_labels = ['Raw Prompt', 'Updated Prompt']col_labels = ['Avg Score', 'Max', 'Min','Median']# 绘制表格the_table = ax.table(cellText=data,rowLabels=row_labels,colLabels=col_labels,loc='center',cellLoc='center',rowColours=['lightgray'] * rows, # 设置行颜色colColours=['lightgray'] * cols, # 设置列颜色cellColours=[['none'] * cols] * rows) # 设置单元格颜色# 添加表格标题ax.set_title('Aesthestics Score Evaluation Result', fontsize=16, pad=20)# 调整表格大小the_table.auto_set_font_size(False)the_table.set_fontsize(8)the_table.scale(1.5, 2) # 调整表格大小# 显示图像plt.tight_layout()plt.show()
通过Pick Score评价优化方案的有效性
-
Pick score用于评价图像和提示词的相似度,保证生成图片的有效性
-
该指标的计算方法是通过对输入提示词的长度、词频、主题相关性和生成效果的综合评估,得出提示词的有效性评分。
-
Pick Score的得分经过了softmax处理,区间在0-1之间,数值越大,关联程度越高。
-
由于Pick Score模型限制,此处使用的prompt为英文原版prompt。
# 加载模型和处理器device = "cpu"processor_name_or_path = "laion/CLIP-ViT-H-14-laion2B-s32B-b79K"model_pretrained_name_or_path = "yuvalkirstain/PickScore_v1"processor = AutoProcessor.from_pretrained(processor_name_or_path)model = AutoModel.from_pretrained(model_pretrained_name_or_path).eval().to(device)# 获取原始图像文件路径raw_image_paths = sorted(glob(os.path.join(raw_folder, '*.png')))update_image_paths = sorted(glob(os.path.join(update_folder, '*.png')))pickscore_results = []# 循环计算每个 prompt 的概率for i, prompt in enumerate(raw_prompt_eng):#raw_image_path = raw_image_paths[i]image = [Image.open(raw_image_paths[i]),Image.open(update_image_paths[i])]probs = calc_probs(prompt, image)pickscore_results.append(probs)print(f'Prompt: {prompt}, Probabilities: {probs}')
text_config_dict is provided which will be used to initialize CLIPTextConfig. The value text_config["id2label"] will be overriden. Prompt: Twilight Barn Painting, Probabilities: [0.39845356345176697, 0.6015465259552002]
Prompt: Shady Green Trees and Blooming Flowers, Probabilities: [0.2977561950683594, 0.7022437453269958]
Prompt: A Noble Corgi, Probabilities: [0.16145963966846466, 0.8385403752326965]
Prompt: Kung Pao Chicken, Probabilities: [0.2974173426628113, 0.7025826573371887]
Prompt: A Room Filled with Toy Robots, Probabilities: [0.32238972187042236, 0.6776102781295776]
Prompt: A Jungle Temple with Many Statues Inside, Probabilities: [0.3444701135158539, 0.655529797077179]
Prompt: Black and White Photo of Two Horses, Probabilities: [0.783403217792511, 0.21659676730632782]
Prompt: A Grand Palace with the Emperor in the Center, Ministers on Brooms Paying Homage, Some Reporting Work, the Entire Hall Gleaming with Gold, Probabilities: [0.4876033365726471, 0.5123966336250305]
Prompt: A Cute Kitten, Probabilities: [0.5886120200157166, 0.41138795018196106]
Prompt: A Gothic Building, Probabilities: [0.47186294198036194, 0.5281369686126709]
Prompt: Two Brothers with Deep Bonds, Probabilities: [0.1856713443994522, 0.814328670501709]
Prompt: A Snail, Probabilities: [0.7101601958274841, 0.28983986377716064]
Prompt: A High School Student Studying Late at Night at a Computer Desk, Probabilities: [0.48027679324150085, 0.5197231769561768]
Prompt: Coffee-Colored Sky, Green Lake, Blue Grass, Probabilities: [0.444215327501297, 0.5557846426963806]
Prompt: Sacred Pyramid with a Sphinx at the Entrance, Probabilities: [0.5698661804199219, 0.43013378977775574]
Prompt: Two Meerkats in the Wild with a Hot Air Balloon, Probabilities: [0.6993129849433899, 0.3006870150566101]
Prompt: A Painting of a Girl in a White Dress Dancing in a Daisy Field, Probabilities: [0.38877981901168823, 0.6112201809883118]
Prompt: Spring Arrives, Everything Awakens, Probabilities: [0.2924484610557556, 0.7075515389442444]
Prompt: A Futuristic Spaceship with Flames Bursting, Probabilities: [0.32964077591896057, 0.6703592538833618]
Prompt: A Dog, a Cat, and Jesus Caring for All Creatures, Including People and Plants, Probabilities: [0.63358074426651, 0.3664192259311676]
Prompt: Stir-Fried Noodles with Minced Pork, Probabilities: [0.5302764177322388, 0.46972358226776123]
Prompt: Spicy Sliced Beef and Tripe, Probabilities: [0.5834560394287109, 0.41654399037361145]
Prompt: A Phoenix Flying Over a Mountain, Probabilities: [0.31403863430023193, 0.6859613656997681]
Prompt: Robot Battle, Probabilities: [0.5716444849967957, 0.42835554480552673]
Prompt: A Bug's Life, Probabilities: [0.611375629901886, 0.388624370098114]
-
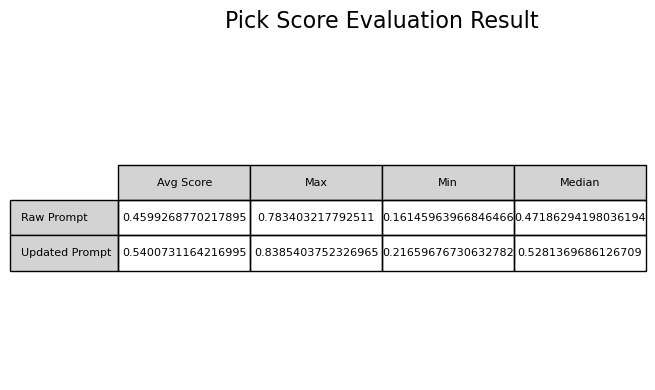
从上面的分数可以看到,还是有一些prompt在优化后反而在Pick Score上的评分低于原始prompt的评分,这是因为Pick Score模型本身存在一些局限性。下面我们挑出一个最大负例进行分析:
-
在输入prompt为“两匹马的黑白照片”这一组图片中,优化前的分数为0.78,优化后的仅有0.22。如下图所示,左边对应原始prompt的生成图片,右边对应优化prompt的生成图片:
-
可以明显看出,优化前的图片实际上有很大一部分是无法识别的内容,而优化后的显然看上去更加清晰,也更符合用户的预期。因此,模型本身的局限性是会导致对于图片评估的误判的。|
-
优化前

优化后

import statisticsresults = pickscore_results # 计算优化有效的结果数量#effective_count = sum(1 for result in results if result[1] > result[0])# 计算优化程度的平均值和中位数improvement_scores = [result[1] - result[0] for result in results if result[1] > result[0]]avg_improvement = statistics.mean(improvement_scores)median_improvement = statistics.median(improvement_scores)standeard_deviation = statistics.stdev(improvement_scores)# 计算优化前的均值before_mean = statistics.mean([result[0] for result in results])# 计算优化后的均值after_mean = statistics.mean([result[1] for result in results])before_median = statistics.median([result[0] for result in results])after_median = statistics.median([result[1] for result in results])before_max = max([result[0] for result in results])after_max = max([result[1] for result in results])before_min = min([result[0] for result in results])after_min = min([result[1] for result in results])# print(f"优化前的均值: {before_mean}")# print(f"优化后的均值: {after_mean}")# print(f"优化程度的平均值: {avg_improvement}")# print(f"优化程度的中位数: {median_improvement}")# print(f"优化程度的标准差: {standeard_deviation}")fig, ax = plt.subplots(figsize=(8, 4))ax.axis('off') # 隐藏坐标轴# 设置表格的行列数rows = 2cols = 4# 创建数据data = [[before_mean, before_max, before_min, before_median] ,[after_mean, after_max, after_min, after_median]]# 创建表头row_labels = ['Raw Prompt', 'Updated Prompt']col_labels = ['Avg Score', 'Max', 'Min','Median']# 绘制表格the_table = ax.table(cellText=data,rowLabels=row_labels,colLabels=col_labels,loc='center',cellLoc='center',rowColours=['lightgray'] * rows, # 设置行颜色colColours=['lightgray'] * cols, # 设置列颜色cellColours=[['none'] * cols] * rows) # 设置单元格颜色# 添加表格标题ax.set_title('Pick Score Evaluation Result', fontsize=16, pad=20)# 调整表格大小the_table.auto_set_font_size(False)the_table.set_fontsize(8)the_table.scale(1.5, 2) # 调整表格大小# 显示图像plt.tight_layout()plt.show()
总结
-
在Aesthestics Score和Pick Score两个测试模型中,我们的方法均有出色的表现。这表明,轻量化的优化方法也可以有效地提升prompt的质量。
评论
