6
Langchain 千帆从入门到实战
大模型开发/技术交流
- LLM
- 开源大模型
- 社区上线
2023.11.087450看过
前言
在进入本章之前,我们先简单介绍一下Langchain,他是一个可以帮助用户快速构建从原型到生产的LLM应用的框架。其封装了包括LLM,Embedding,Chain,Agent,Tool等一系列抽象的LLM应用组件,也在开源社区的不断贡献下集成了当前大部分主流的大语言模型等调用方法。是当前最火热的大语言模型应用框架。
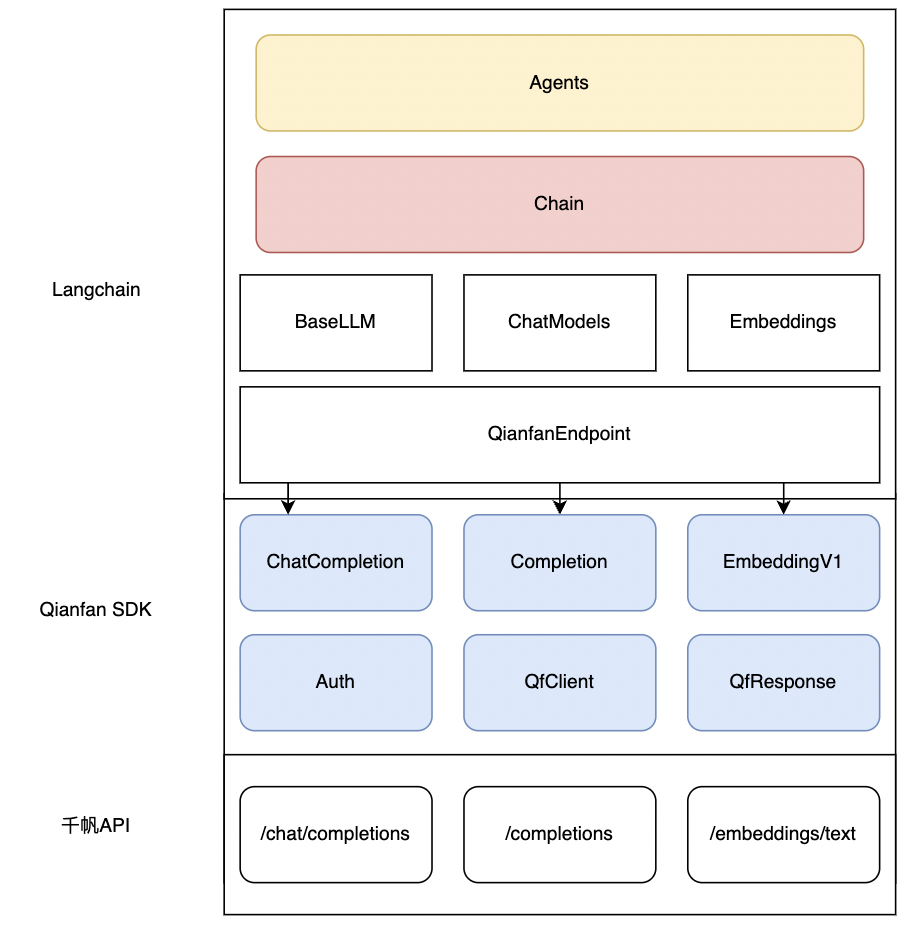
针对Langchain中常见的应用场景,我们基于千帆SDK实现了如下的几种能力:
-
llms: 针对于基础的LLM的纯文本补全能力设计的基础类型,对应千帆SDK的Completion能力
-
chat_models:针对于对话能力设计的带有角色,历史消息的基础类型,对应千帆SDK的ChatCompletion能力
-
embeddings:针对于语料向量化的能力设计的基础类型,对应千帆SDK的Embedding能力
API初始化
要使用基于百度千帆的服务,必须先使用在控制台获取的应用接入AK/SK初始化以下参数,也可以选择在环境变量或初始化params中传入AK、SK:
export QIANFAN_AK=XXXexport QIANFAN_SK=XXX
对话补全:
使用chat_models让大模型生成一个笑话,这里默认使用的是ERNIE-Bot-turbo模型。
"""For basic init and call"""from langchain.chat_models import QianfanChatEndpointfrom langchain.chat_models.base import HumanMessageimport osos.environ["QIANFAN_AK"] = "your_ak"os.environ["QIANFAN_SK"] = "your_sk"chat = QianfanChatEndpoint(streaming=True,)res = chat([HumanMessage(content="write a funny joke")])
from langchain.chat_models import QianfanChatEndpointfrom langchain.schema import HumanMessagechatLLM = QianfanChatEndpoint(streaming=True,)res = chatLLM.stream([HumanMessage(content="hi")], streaming=True)for r in res:print("chat resp:", r)async def run_aio_generate():resp = await chatLLM.agenerate(messages=[[HumanMessage(content="write a 20 words sentence about sea.")]])print(resp)await run_aio_generate()async def run_aio_stream():async for res in chatLLM.astream([HumanMessage(content="write a 20 words sentence about sea.")]):print("astream", res)await run_aio_stream()
chat resp: content='您好,您似乎输入' additional_kwargs={} example=Falsechat resp: content='了一个话题标签,请问需要我帮您找到什么资料或者帮助您解答什么问题吗?' additional_kwargs={} example=Falsechat resp: content='' additional_kwargs={} example=Falsegenerations=[[ChatGeneration(text="The sea is a vast expanse of water that covers much of the Earth's surface. It is a source of travel, trade, and entertainment, and is also a place of scientific exploration and marine conservation. The sea is an important part of our world, and we should cherish and protect it.", generation_info={'finish_reason': 'finished'}, message=AIMessage(content="The sea is a vast expanse of water that covers much of the Earth's surface. It is a source of travel, trade, and entertainment, and is also a place of scientific exploration and marine conservation. The sea is an important part of our world, and we should cherish and protect it.", additional_kwargs={}, example=False))]] llm_output={} run=[RunInfo(run_id=UUID('d48160a6-5960-4c1d-8a0e-90e6b51a209b'))]astream content='The sea is a vast' additional_kwargs={} example=Falseastream content=' expanse of water, a place of mystery and adventure. It is the source of many cultures and civilizations, and a center of trade and exploration. The sea is also a source of life and beauty, with its unique marine life and diverse' additional_kwargs={} example=Falseastream content=' coral reefs. Whether you are swimming, diving, or just watching the sea, it is a place that captivates the imagination and transforms the spirit.' additional_kwargs={} example=False
使用不同模型接入
对于想基于Ernie-Bot-turbo或第三方开源模型部署自己的模型,你可以遵循以下步骤:
chatBloom = QianfanChatEndpoint(streaming=True,model="BLOOMZ-7B",)res = chatBloom([HumanMessage(content="hi")])print(res)
content='你好!很高兴见到你。' additional_kwargs={} example=False
模型超参
目前"ERNIE-Bot-4",“ERNIE Bot”和“ERNIE Bot turbo”还支持下面的模型参数:
-
temperature
-
top_p
-
penalty_score
res = chat.stream([HumanMessage(content="hi")], **{'top_p': 0.4, 'temperature': 0.1, 'penalty_score': 1})for r in res:print(r)
content='您好,您似乎输入' additional_kwargs={} example=Falsecontent='了一个文本字符串,但并没有给出具体的问题或场景。' additional_kwargs={} example=Falsecontent='如果您能提供更多信息,我可以更好地回答您的问题。' additional_kwargs={} example=Falsecontent='' additional_kwargs={} example=False
Embeddings:
from langchain.embeddings import QianfanEmbeddingsEndpointimport osos.environ["QIANFAN_AK"] = "your_ak"os.environ["QIANFAN_SK"] = "your_sk"embed = QianfanEmbeddingsEndpoint(# qianfan_ak='xxx',# qianfan_sk='xxx')res = embed.embed_documents(["hi", "world"])async def aioEmbed():res = await embed.aembed_query("qianfan")print(res[:8])await aioEmbed()import asyncioasync def aioEmbedDocs():res = await embed.aembed_documents(["hi", "world"])for r in res:print("", r[:8])await aioEmbedDocs()
[-0.03313107788562775, 0.052325375378131866, 0.04951248690485954, 0.0077608139254152775, -0.05907672271132469, -0.010798933915793896, 0.03741293027997017, 0.013969100080430508][0.0427522286772728, -0.030367236584424973, -0.14847028255462646, 0.055074431002140045, -0.04177454113960266, -0.059512972831726074, -0.043774791061878204, 0.0028191760648041964][0.03803155943751335, -0.013231384567916393, 0.0032379645854234695, 0.015074018388986588, -0.006529552862048149, -0.13813287019729614, 0.03297128155827522, 0.044519297778606415]
知识库问答实战:
基于最常见的知识库QA应用,我们基于Langchain和qianfan实现了一套文档QA的最佳实践:
评论
