RLHF强化学习详解与应用
大模型开发/实践案例
- 大模型训练
2023.10.095562看过
一、介绍
以chatGPT为代表的基于prompt范式的大型语言模型 (Large Language Model,LLM) 取得了巨大的成功。然而,对生成结果的评估是主观和依赖上下文的,这些结果难以用现有的基于规则的文本生成指标 (如 BLUE 和 ROUGE) 来衡量。除了评估指标,现有的模型通常以预测下一个单词的方式和简单的损失函数 (如交叉熵) 来建模,没有显式地引入人的偏好和主观意见。
因此,训练阶段,如果直接用人的偏好(或者说人的反馈)来对模型整体的输出结果计算reward或loss,显然是要比上面传统的“给定上下文,预测下一个词”的损失函数合理的多。基于这个思想,便引出了本文要讨论的对象——RLHF(Reinforcement Learning from Human Feedback):即使用强化学习的方法,利用人类反馈信号直接优化语言模型。
二、实现原理
RLHF的训练过程可以分解为三个核心步骤:
-
Language Model,LM:一个预训练语言模型 LM
-
Reward Model,RM:训练一个奖励模型RM
-
Reinforcement Learning,RL:用强化学习RL方式微调 LM
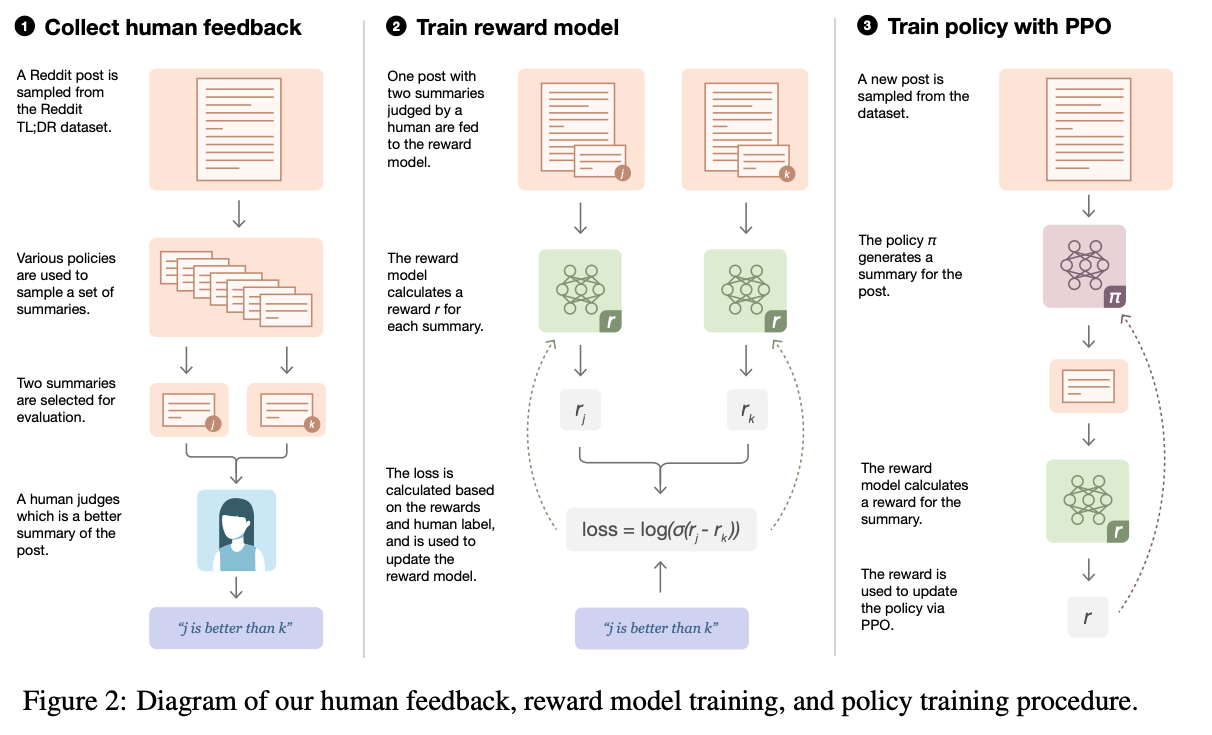
第一阶段:训练监督策略模型
以GPT 3.5为例,GPT 3.5本身很难理解人类不同类型指令中蕴含的不同意图,也很难判断生成内容是否是高质量的结果。为了让GPT 3.5初步具备理解指令的意图,首先会在数据集中随机抽取问题,由人类标注人员,给出高质量答案,然后用这些人工标注好的数据来微调 GPT-3.5模型(获得SFT模型, Supervised Fine-Tuning)。
此时的SFT模型在遵循指令/对话方面已经优于 GPT-3,但不一定符合人类偏好。
第二阶段:训练奖励模型(Reward Mode,RM)
这个阶段的主要是通过人工标注训练数据(约33K个数据),来训练回报模型。在数据集中随机抽取问题,使用第一阶段生成的模型,对于每个问题,生成多个不同的回答。人类标注者对这些结果综合考虑给出排名顺序。这一过程类似于教练或老师辅导。
接下来,使用这个排序结果数据来训练奖励模型。对多个排序结果,两两组合,形成多个训练数据对。RM模型接受一个输入,给出评价回答质量的分数。这样,对于一对训练数据,调节参数使得高质量回答的打分比低质量的打分要高。
第三阶段:采用PPO(Proximal Policy Optimization,近端策略优化)强化学习来优化策略
这一阶段利用第二阶段训练好的奖励模型,靠奖励打分来更新预训练模型参数。在数据集中随机抽取问题,使用PPO模型生成回答,并用上一阶段训练好的RM模型给出质量分数。把回报分数依次传递,由此产生策略梯度,通过强化学习的方式以更新PPO模型参数。
如果不断重复第二和第三阶段,通过迭代,会训练出更高质量的ChatGPT模型。
三、应用:微调GPT2生成正面电影评论
实现思路
给模型输入一个电影评论,然后生成一个正面较长的评论。使用DistilBERT分类器来评价生成评论的正面程度,强化学习算法是ChatGPT同款PPO(ClosedAI提出来的)。
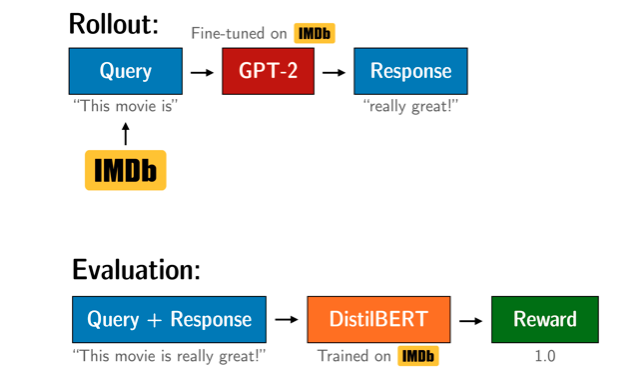
总共分3步:
-
Language Model,LM:一个在语料上微调的预训练语言模型,使用微调好的 gpt2-imdb
-
Reward Model,RM:BERT情感分类模型作为奖励模型,使用训练好的 distilbert-imdb
-
Reinforcement Learning,RL:使用PPO进行强化学习训练,引导模型生成
代码实现
import torchfrom tqdm import tqdmimport pandas as pdfrom datasets import load_datasetfrom transformers import pipeline, AutoTokenizer, AutoModelForCausalLMfrom peft import LoraConfig, PeftConfig, PeftModel, get_peft_model, prepare_model_for_kbit_trainingfrom trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHeadfrom trl.core import LengthSampler
config = PPOConfig(model_name="/shareData/gpt2-imdb", # 这个是Huggingface上要训练的gpt2-imdb的名称,在transformer中可以用from_pretrained直接下载和缓存learning_rate=1.41e-5, # 学习率)sent_kwargs = {"return_all_scores": True, # 文本生成的参数,这里设置为True,表示生成文本时返回得分"function_to_apply": "none","batch_size": 16}# 使用transformers库加载模型pretrained_model = AutoModelForCausalLM.from_pretrained(config.model_name)# 设置lora配置参数lora_config = LoraConfig(r=16,lora_alpha=32,target_modules=["c_attn"] ,lora_dropout=0.05,bias="none",task_type="CAUSAL_LM")# 设置8bit训练pretrained_model = prepare_model_for_kbit_training(pretrained_model)# 设置lora模型。做instruction learning,到这里就好了。如果要做RLHF,还要做第四步。pretrained_model = get_peft_model(pretrained_model, lora_config)# 将lora模型加载入trl模型model = AutoModelForCausalLMWithValueHead.from_pretrained(pretrained_model)# 做必要的设置,梯度检查。model.gradient_checkpointing_disable = model.pretrained_model.gradient_checkpointing_disablemodel.gradient_checkpointing_enable = model.pretrained_model.gradient_checkpointing_enable
def print_trainable_parameters(model):"""Prints the number of trainable parameters in the model."""trainable_params = 0all_param = 0for _, param in model.named_parameters():all_param += param.numel()if param.requires_grad:trainable_params += param.numel()print(f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}")print_trainable_parameters(model)
trainable params: 590593 || all params: 125030401 || trainable%: 0.47235951838625234
下载数据集:
def build_dataset(config, dataset_name="imdb", input_min_text_length=2, input_max_text_length=8):"""构建训练用的数据集"""tokenizer = AutoTokenizer.from_pretrained(config.model_name)tokenizer.pad_token = tokenizer.eos_token # pad_token和eos_token是同一个,也可以用其它的token进行替换。# 加载IMDB数据集,直接从huggingface的hub上下载数据,当然也可以下载其他数据# 每次做DL或ML时,大量时间用在了做ds = load_dataset(dataset_name, split='train') # 加载后是DataFrame格式!?ds = ds.rename_columns({'text': 'review'})ds = ds.filter(lambda x: len(x["review"])>200, batched=False) # 这里filter是指len(x["review"])>200都过滤掉# 对batch_size进行裁剪,缩小到2到8之间。(2和8是函数中的默认参数)# 即query的token长度控制在2到8之间,有点小呀input_size = LengthSampler(input_min_text_length, input_max_text_length)def tokenize(sample):sample["input_ids"] = tokenizer.encode(sample["review"])[:input_size()] # 后面设置batched=False,每次input_size都不同sample["query"] = tokenizer.decode(sample["input_ids"])return sampleds = ds.map(tokenize, batched=False)# 将数值型变量设置为torch的tensor格式,并且输出所有的列数据,在RL截断需要使用!一定要注意设置output_all_columns=Trueds.set_format(type='torch', columns=["input_ids", "label"], output_all_columns=True)return dsdataset = build_dataset(config)def collator(data):return dict((key, [d[key] for d in data]) for key in data[0])

ref_model = AutoModelForCausalLMWithValueHead.from_pretrained(config.model_name)tokenizer = AutoTokenizer.from_pretrained(config.model_name)tokenizer.pad_token = tokenizer.eos_token
ppo_trainer = PPOTrainer(config, model, ref_model=ref_model,tokenizer=tokenizer, dataset=dataset,data_collator=collator)
device = ppo_trainer.accelerator.deviceif ppo_trainer.accelerator.num_processes == 1:device = 0 if torch.cuda.is_available() else "cpu" # to avoid a `pipeline` bugsentiment_pipe = pipeline("sentiment-analysis", model="/shareData/distilbert-imdb", device=device)
gen_kwargs = {"min_length":-1,"top_k": 0.0,"top_p": 1.0,"do_sample": True,"pad_token_id": tokenizer.eos_token_id}
output_min_length = 4output_max_length = 16output_length_sampler = LengthSampler(output_min_length, output_max_length)generation_kwargs = {"min_length":-1,"top_k": 0.0,"top_p": 1.0,"do_sample": True,"pad_token_id": tokenizer.eos_token_id}for epoch, batch in tqdm(enumerate(ppo_trainer.dataloader)):query_tensors = batch['input_ids']model.gradient_checkpointing_disable()model.pretrained_model.config.use_cache = True#### Get response from gpt2response_tensors = []for query in query_tensors:gen_len = output_length_sampler()generation_kwargs["max_new_tokens"] = gen_lenresponse = ppo_trainer.generate(query, **generation_kwargs)response_tensors.append(response.squeeze()[-gen_len:])batch['response'] = [tokenizer.decode(r.squeeze()) for r in response_tensors]#### Compute sentiment scoretexts = [q + r for q,r in zip(batch['query'], batch['response'])]pipe_outputs = sentiment_pipe(texts, **sent_kwargs)rewards = [torch.tensor(output[1]["score"]) for output in pipe_outputs]# Run PPO stepmodel.gradient_checkpointing_enable()model.pretrained_model.config.use_cache = False#### Run PPO stepstats = ppo_trainer.step(query_tensors, response_tensors, rewards)ppo_trainer.log_stats(stats, batch, rewards)

时间很漫长,a100大概两个多小时。
训练完看看效果:
bs = 16game_data = dict()dataset.set_format("pandas")df_batch = dataset[:].sample(bs)game_data['query'] = df_batch['query'].tolist()query_tensors = df_batch['input_ids'].tolist()response_tensors_ref, response_tensors = [], []#### get response from gpt2 and gpt2_reffor i in range(bs):gen_len = output_length_sampler()output = ref_model.generate(torch.tensor(query_tensors[i]).unsqueeze(dim=0).to(device),max_new_tokens=gen_len, **gen_kwargs).squeeze()[-gen_len:]response_tensors_ref.append(output) ## output = model.generate(torch.tensor(query_tensors[i]).unsqueeze(dim=0).to(device),# max_new_tokens=gen_len, **gen_kwargs).squeeze()[-gen_len:]output = ppo_trainer.generate(torch.tensor(query_tensors[i]).to(device),max_new_tokens=gen_len, **gen_kwargs).squeeze()[-gen_len:]response_tensors.append(output)#### decode responsesgame_data['response (before)'] = [tokenizer.decode(response_tensors_ref[i]) for i in range(bs)]game_data['response (after)'] = [tokenizer.decode(response_tensors[i]) for i in range(bs)]#### sentiment analysis of query/response pairs before/aftertexts = [q + r for q,r in zip(game_data['query'], game_data['response (before)'])]game_data['rewards (before)'] = [output[1]["score"] for output in sentiment_pipe(texts, **sent_kwargs)]texts = [q + r for q,r in zip(game_data['query'], game_data['response (after)'])]game_data['rewards (after)'] = [output[1]["score"] for output in sentiment_pipe(texts, **sent_kwargs)]# store results in a dataframedf_results = pd.DataFrame(game_data)df_results

print('mean:')display(df_results[["rewards (before)", "rewards (after)"]].mean())print()print('median:')display(df_results[["rewards (before)", "rewards (after)"]].median())

项目文件
一些可能的报错或警告
1、UserWarning: The installed version of bitsandbytes was compiled without GPU support
使用pip install bitsandbytes正常安装库,切换到bitsandbytes所在lib目录(pip show bitsandbytes可以看到),打开site-packages/bitsandbytes/cuda_setup。使用vim指令或其他方式编辑main.py文件,定位到if not torch.cuda.is_available(): return 'libsbitsandbytes_cpu.so', None, None, None, None,将其替换为if torch.cuda.is_available(): return 'libbitsandbytes_cuda118.so', None, None, None, None 。(并非一定要使用cuda118,只需大于等于自身显卡cuda版本即可),定位到self.lib = ct.cdll.LoadLibrary(binary_path),会找到两处,把两处都替换为self.lib = ct.cdll.LoadLibrary(str(binary_path))
2、TqdmWarning: IProgress not found. Please update jupyter and ipywidgets.
出现该问题的原因是未安装ipywidgets,所以 安装ipywidgets包即可。命令如下:pip install ipywidgets
附录
本文作者周洁,已获作者授权发布,如需转载请联系
评论
