37
Linux命令行机器人之---(4.)100行代码挑战开发一个完整的命令行机器人
大模型开发/技术交流
- 社区上线
- 开箱评测
- API
2023.10.032273看过
Linux命令行机器人系列文章导航
如果前三步骤都很熟悉了,请跳过直接第4步。否则强烈建议查看学习!!!
Linux命令行机器人之---1.初识百度智能云千帆大模型平台: https://cloud.baidu.com/qianfandev/topic/267409
Linux命令行机器人之---2.初学者快速入门千帆大模型平台: https://cloud.baidu.com/qianfandev/topic/267410
Linux命令行机器人之---3.千帆大模型平台HelloWorld实例: https://cloud.baidu.com/qianfandev/topic/267411
Linux命令行机器人之---(4.)100行代码挑战开发一个完整的命令行机器人: https://cloud.baidu.com/qianfandev/topic/267413
Linux命令行机器人之---5. 语音识别+千帆大模型实现个人专属语音助理: https://cloud.baidu.com/qianfandev/topic/267428
挑战成功,用了99行核心代码:

程序运行结果:
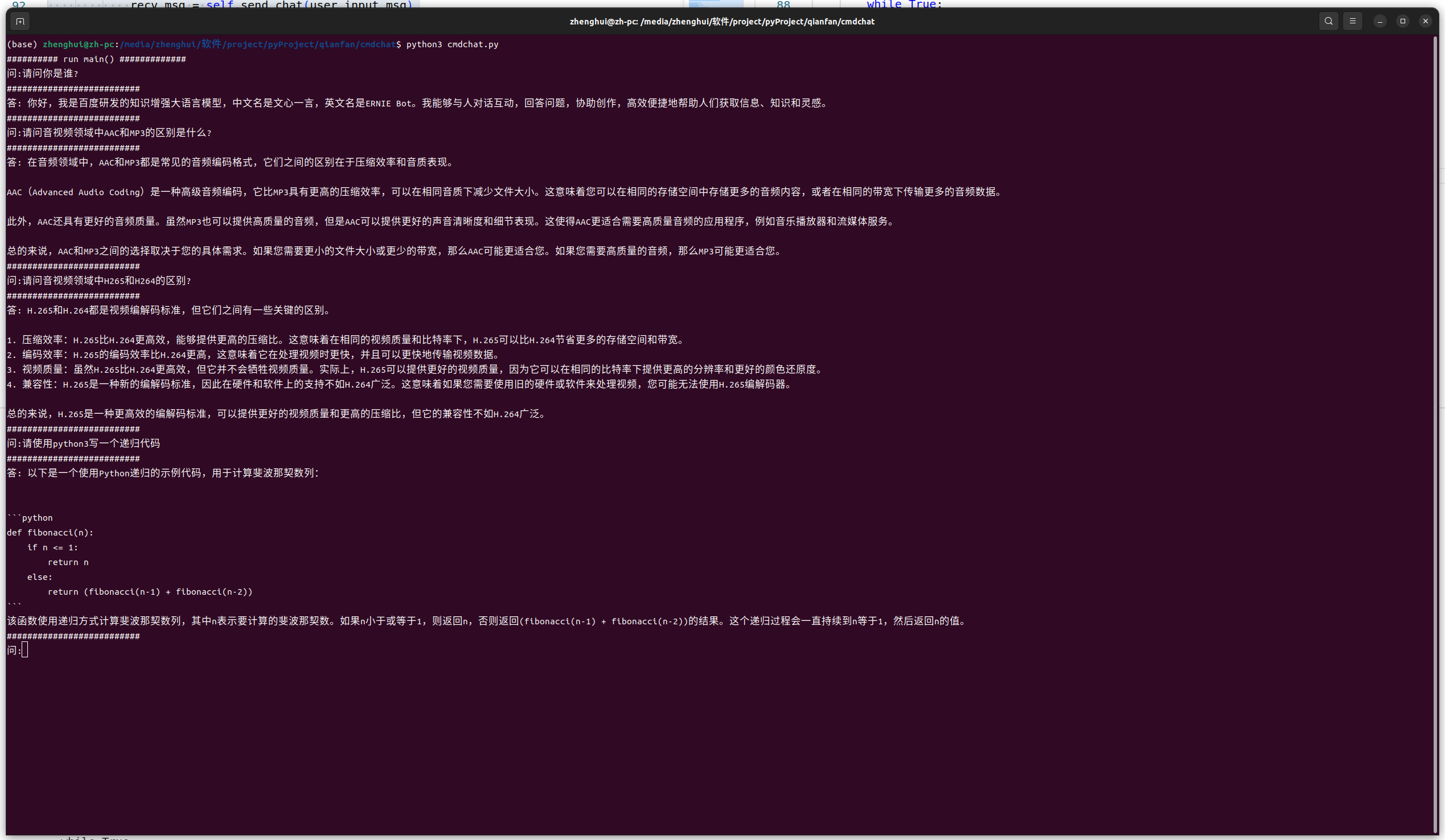
前言
本文就来点有意思的是,初步构想:
用户在命令行中输入问题,可以得到机器人的回答;
工具和具备的知识:
1、Python基础知识;
2、Linux基础使用;
3、千帆大模型平台的帐号,和已经创建过应用,拿到了Key等信息;
1、Python基础知识;
2、Linux基础使用;
3、千帆大模型平台的帐号,和已经创建过应用,拿到了Key等信息;
目前千帆大模型平台文档中给出了25个大项对话Chat的大模型。
我比较感兴趣的是千帆自研的2个大模型:
-
ERNIE-Bot
ERNIE-Bot是百度自行研发的大语言模型,覆盖海量中文数据,具有更强的对话问答、内容创作生成等能力。
-
ERNIE-Bot-turbo:
ERNIE-Bot-turbo是百度自行研发的大语言模型,覆盖海量中文数据,具有更强的对话问答、内容创作生成等能力,响应速度更快。
内置ERNIE-Bot-turbo系列最新版模型ERNIE-Bot-turbo-0725
可以看到介绍中说,ERNIE-Bot-turbo比ERNIE-Bot更快,所以本文决定使用ERNIE-Bot-turbo来做案例。
代码框架依然使用上篇文章已经写好的代码:
#!/usr/bin/python3import requestsimport jsonclass APIQianfan:def __init__(self):# 请求地址self.url = "https://aip.baidubce.com/oauth/2.0/token"self.APIKey = "VsysBQ2sY44B47Li712OGyna"self.SecretKey = "uMQX9PMyAMZdESQm0awlwbmitO868TGH"def get_token(self):params = {"grant_type" : "client_credentials","client_id" : self.APIKey,"client_secret" : self.SecretKey,}try:response = requests.post(self.url, timeout=10, params=params)if response.status_code == 200:# 转成JSONjsondata = json.loads(response.text)print(jsondata)return jsondata["access_token"]else:print("请求失败")except requests.exceptions.RequestException as e:# 处理请求异常的逻辑print("请求异常"except Exception as e:# 处理其他异常的逻辑print("其他异常:", e)return ""def main():print ("########## run main() #############")qf = APIQianfan()access_token = qf.get_token()print("##########################")print(access_token)print("##########################")if __name__ == "__main__":main()
扩展&改造
改造点1:引入配置文件管理功能
为了保存配置文件,这里我选择使用.json配置文件的方式来存储一些信息。
json的好处就是通用性强,结构化比较好,走到哪里都很适合。
json唯一不好的地方是不能注释。
肯定有不知道怎么操作json的,为了照顾到大多数人,可以运行这个实例:
1、请在同一目录下创建:config.json和test.py文件
config.json:
把你的这些基本信息都保存下来
{"qianfan_info": {"get_token_url": "https://aip.baidubce.com/oauth/2.0/token","api_key": "VsysBQ2sY44B47Li712OGyna","secret_key": "uMQX9PMyAMZdESQm0awlwbmitO868TGH","access_token": ""}}
test.py:
引入json库
import json# 打开 JSON 配置文件进行读取with open('config.json', 'r') as file:config_data = json.load(file)# 现在,config_data 包含了 JSON 配置文件中的数据,可以按需使用它print(config_data)# 保存access_token到json中config_data["qianfan_info"]["access_token"] = "abc"# 将配置数据写入 JSON 配置文件with open('config.json', 'w') as file:json.dump(config_data, file, indent=4)# 打开 JSON 配置文件进行读取with open('config.json', 'r') as file:config_data = json.load(file)# 现在,config_data 包含了 JSON 配置文件中的数据,可以按需使用它print(config_data)
运行结果:
可以很明显看到,我们读取成功了,也修改写入成功了。
(base) zhenghui@zh-pc:/media/zhenghui/软件/project/pyProject/qianfan/cmdchat$ python3 test.py{'qianfan_info': {'get_token_url': 'https://aip.baidubce.com/oauth/2.0/token', 'api_key': 'VsysBQ2sY44B47Li712OGyna', 'secret_key': 'uMQX9PMyAMZdESQm0awlwbmitO868TGH', 'access_token': ''}}{'qianfan_info': {'get_token_url': 'https://aip.baidubce.com/oauth/2.0/token', 'api_key': 'VsysBQ2sY44B47Li712OGyna', 'secret_key': 'uMQX9PMyAMZdESQm0awlwbmitO868TGH', 'access_token': 'abc'}}(base) zhenghui@zh-pc:/media/zhenghui/软件/project/pyProject/qianfan/cmdchat$
请理解了test.py的代码后,再继续下一步。
封装成一个config class:
config.py:
该代码,主要是保存和读取json数据。方便以后的调用
#!/usr/bin/python3import jsonclass Config:def __init__(self):self.config_path = "./config.json"# 创建config_data,用于存储json数据self.config_data = Noneself.read()# 读取json配置文件def read(self):# 需要增加异常捕捉等代码with open(self.config_path, 'r') as file:self.config_data = json.load(file)return self.config_data# 写入json配置文件def write(self, config_data):with open(self.config_path, 'w') as file:json.dump(config_data, file, indent=4)
为了减小文章篇幅和文字个数,这里就不过多的处理异常问题,全默认是没问题的。
当然了,如果要工程话的话,还应该考虑很多问题,例如:
-
1、配置文件损坏时怎么办;
-
2、空的时候怎么办;
-
3、读取的数据异常时怎么办;
上面这几种是非常要命的,因为我在嵌入式环境下开发过应用,我深有体验。搞不好,整台设备就挂掉了,变砖也是有可能的。
在test1.py中测试:
import configcf = config.Config()config_data = cf.read()print(config_data)config_data["aaa"]="sss"cf.write(config_data)
打印:
(base) zhenghui@zh-pc:/media/zhenghui/软件/project/pyProject/qianfan/cmdchat$ python3 test.py{'aaa': 'sss'}(base) zhenghui@zh-pc:/media/zhenghui/软件/project/pyProject/qianfan/cmdchat$
前面的都没问题后,我们再cmdchat.py中新增配置文件的读取:
首先把这段内容添加到config.json中:
{"qianfan_conf":{"url": "https://aip.baidubce.com/oauth/2.0/token","APIKey": "VsysBQ2sY44B47Li712OGyna","SecretKey": "uMQX9PMyAMZdESQm0awlwbmitO868TGH"}}
1、引入配置文件操作工具:
# 引入配置文件操作工具import config
2、在init中创建一个Config对象:
def __init__(self):# 创建 Config 对象self.cf = config.Config()
3、把url,APIKey,SecretKey进行读取后赋值:
def __init__(self):# 创建 Config 对象self.cf = config.Config()# 配置文件赋值self.url = self.cf.config_data["qianfan_conf"]["url"]self.APIKey = self.cf.config_data["qianfan_conf"]["APIKey"]self.SecretKey = self.cf.config_data["qianfan_conf"]["SecretKey"]self.access_token = ""
4、执行测试:Success
(base) zhenghui@zh-pc:/media/zhenghui/软件/project/pyProject/qianfan/cmdchat$ python3 cmdchat.py########## run main() #######################################24.7ddcae5a16abec31d1d276bf3b651fd3.2592000.1698915654.282335-40406243##########################(base) zhenghui@zh-pc:/media/zhenghui/软件/project/pyProject/qianfan/cmdchat$
是不是非常的good.
恭喜你,到此为止,本阶段就结束了。
改造点2:新增一个token管理功能
token不必每次都获取,因为官方给出的token有效期时30天。所以我们为了节省资源和成本,也需要有效的设计代码架构。
上一步我们成功的读取到了数据,但是还没有把保获取到的access_token保存到config.json中。
该部分,有2个需要考虑到的:
-
1、获取到access_token后,应该保存到config.json中;
-
2、每次启动程序后,应该先检查access_token是否已存在,如果存在了就不需要继续获取token了,而是直接返回给用户即可。
好了,开动。
1、修改init函数:
这里要研判一下,因为这个字段可能不存在,就会报错了
if "access_token" in self.cf.config_data["qianfan_conf"]:self.access_token = self.cf.config_data["qianfan_conf"]["access_token"]else:self.access_token = ""
2、新增token校验是否过期功能:
这里就直接省略了
def token_is_valid(self):# 检查是否过期# .......return True
3、修改get_token函数:
def get_token(self):# 1、检查token是否存在if self.access_token != "":# 存在,检查是否过期if self.token_is_valid():# 存在token,并且没过期直接返回给用户return self.access_token# 2、否则重新获取一遍tokenparams = {"grant_type" : "client_credentials","client_id" : self.APIKey,"client_secret" : self.SecretKey,}response = requests.post(self.url, timeout=10, params=params)if response.status_code == 200:# 转成JSONjsondata = json.loads(response.text)# print(jsondata)self.access_token = jsondata["access_token"]# 保存到config.json中self.cf.config_data["qianfan_conf"]["access_token"] = self.access_tokenself.cf.write(self.cf.config_data)return self.access_tokenelse:print("请求失败")return ""
在开头心中呢个了校验token是否存在的功能,如果存在就继续校验是否过期,如果没过期就直接返回这个已保存的token即可。
否则就继续执行获取token的步骤。
获取到token,立马保存到config.json中。
可以看到,无论你执行多少遍,都不会重新获取token了。
恭喜你,这部分也完成了!!!!!
开发自己的专属小助手
这次使用的是ERNIE-Bot-turbo
一、接口介绍
请求说明
基本信息
Header参数
|
名称
|
值
|
|
Content-Type
|
application/json
|
Query参数
|
名称
|
类型
|
必填
|
描述
|
|
access_token
|
string
|
是
|
通过API Key和Secret Key获取的access_token,参考
|
Body参数
|
名称
|
类型
|
必填
|
描述
|
|
messages
|
List(message)
|
是
|
聊天上下文信息。说明:
|
|
(1)messages成员不能为空,1个成员表示单轮对话,多个成员表示多轮对话
|
|
|
|
|
(2)最后一个message为当前请求的信息,前面的message为历史对话信息
|
|
|
|
|
(3)必须为奇数个成员,成员中message的role必须依次为user、assistant
|
|
|
|
|
(4)最后一个message的content长度(即此轮对话的问题)不能超过7000 token;如果messages中content总长度大于7000 token,系统会依次遗忘最早的历史会话,直到content的总长度不超过7000 token
|
|
|
|
|
stream
|
bool
|
否
|
是否以流式接口的形式返回数据,默认false
|
|
temperature
|
float
|
否
|
说明:
|
|
(1)较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定
|
|
|
|
|
(2)默认0.95,范围 (0, 1.0],不能为0
|
|
|
|
|
(3)建议该参数和top_p只设置1个
|
|
|
|
|
(4)建议top_p和temperature不要同时更改
|
|
|
|
|
top_p
|
float
|
否
|
说明:
|
|
(1)影响输出文本的多样性,取值越大,生成文本的多样性越强
|
|
|
|
|
(2)默认0.8,取值范围 [0, 1.0]
|
|
|
|
|
(3)建议该参数和temperature只设置1个
|
|
|
|
|
(4)建议top_p和temperature不要同时更改
|
|
|
|
|
penalty_score
|
float
|
否
|
通过对已生成的token增加惩罚,减少重复生成的现象。说明:
|
|
(1)值越大表示惩罚越大
|
|
|
|
|
(2)默认1.0,取值范围:[1.0, 2.0]
|
|
|
|
|
user_id
|
string
|
否
|
表示最终用户的唯一标识符,可以监视和检测滥用行为,防止接口恶意调用
|
message说明
|
名称
|
类型
|
描述
|
|
role
|
string
|
当前支持以下:
|
|
user: 表示用户
|
|
|
|
assistant: 表示对话助手
|
|
|
|
content
|
string
|
对话内容,不能为空
|
响应说明
|
名称
|
类型
|
描述
|
|
id
|
string
|
本轮对话的id
|
|
object
|
string
|
回包类型
|
|
chat.completion:多轮对话返回
|
|
|
|
created
|
int
|
时间戳
|
|
sentence_id
|
int
|
表示当前子句的序号。只有在流式接口模式下会返回该字段
|
|
is_end
|
bool
|
表示当前子句是否是最后一句。只有在流式接口模式下会返回该字段
|
|
is_truncated
|
bool
|
当前生成的结果是否被截断
|
|
result
|
string
|
对话返回结果
|
|
need_clear_history
|
bool
|
表示用户输入是否存在安全,是否关闭当前会话,清理历史会话信息。
|
|
true:是,表示用户输入存在安全风险,建议关闭当前会话,清理历史会话信息。
|
|
|
|
false:否,表示用户输入无安全风险
|
|
|
|
ban_round
|
int
|
当need_clear_history为true时,此字段会告知第几轮对话有敏感信息,如果是当前问题,ban_round=-1
|
|
usage
|
usage
|
token统计信息,token数 = 汉字数+单词数*1.3 (仅为估算逻辑)
|
usage说明
|
名称
|
类型
|
描述
|
|
prompt_tokens
|
int
|
问题tokens数
|
|
completion_tokens
|
int
|
回答tokens数
|
|
total_tokens
|
int
|
tokens总数
|
注意 :同步模式和流式模式,响应参数返回不同,详细内容参考示例描述。
-
同步模式下,响应参数为以上字段的完整json包。
-
流式模式下,各字段的响应参数为 data: {响应参数}。
二、ApiFox模拟请求
我有一个习惯就是能用api工具来测一下的,就尽量测一下,因为有很多因素可能在代码阶段出现问题,这个阶段就是先排除官方的API是完全没问题的。那么再出现问题,就是自己代码的问题了。
使用APIFox心中呢个一个POST请求:
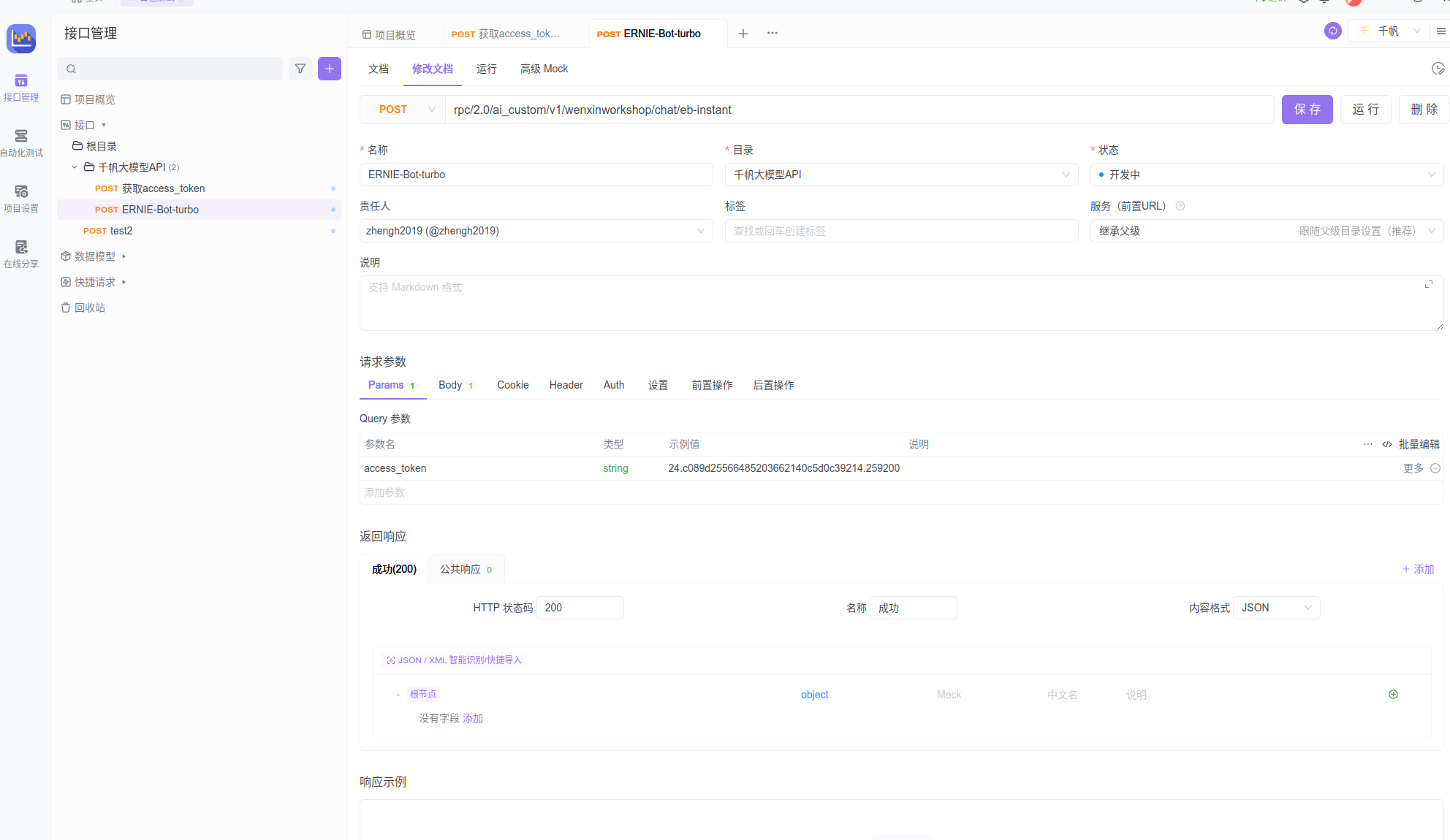
在Params参数中填入参数名为access_token,值为自己获取到的key.
Body中填入如下参数:

{"messages": [{"role": "user","content": "Java和Python的区别是什么"}]}
运行测试:

这就说明是OK的,那么可以继续往下了。
三、问答功能模块开发
问答,问答,肯定是有问又有答,所以需要传入参数和返回参数。
函数模型如下:
def send_chat(self, msg):recv_msg = ""# 1、发送消息# 2、接受&处理 消息return recv_msg
初步代码:
def send_chat(self, msg):recv_msg = ""_url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/eb-instant"# 1、发送消息# 封装query消息params = {"access_token" : self.get_token()}# 封装body参数body = {"messages": [{"role": "user","content": msg}]}headers = {"Content-Type": "application/json"}# 使用 json.dumps() 方法将字典转换为 JSON 格式字符串json_data = json.dumps(body, indent=4) # indent 参数可选,用于格式化输出print("封装body参数=", body)print("封装json_data参数=", json_data)response = requests.post(_url, timeout=10, params=params, data=json_data ,headers=headers)if response.status_code == 200:# 转成JSONjsondata = json.loads(response.text)print(jsondata)else:print("请求失败")# 2、接受&处理 消息return recv_msg
调用:
def main():print ("########## run main() #############")qf = APIQianfan()access_token = qf.get_token()print("##########################")print(access_token)print("##########################")qf.send_chat("1+1=?")print("##########################")
打印:
(base) zhenghui@zh-pc:/media/zhenghui/软件/project/pyProject/qianfan/cmdchat$ python3 cmdchat.py########## run main() #######################################24.5fcc16d4e36d66078f695f3cc59bef2a.2592000.1698916759.282335-40406243##########################封装body参数= {'messages': [{'role': 'user', 'content': '1+1=?'}]}封装json_data参数= {"messages": [{"role": "user","content": "1+1=?"}]}{'id': 'as-tbcaisp56b', 'object': 'chat.completion', 'created': 1696327773, 'result': '1+1等于2。', 'is_truncated': False, 'need_clear_history': False, 'usage': {'prompt_tokens': 1, 'completion_tokens': 4, 'total_tokens': 5}}##########################(base) zhenghui@zh-pc:/media/zhenghui/软件/project/pyProject/qianfan/cmdchat$
可以看到结果已经返回了,那么就可以拿到结果json中的result进行返回即可。
再次改造:
def send_chat(self, msg):print("问:", msg)recv_msg = ""_url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/eb-instant"# 1、发送消息# 封装query消息params = {"access_token" : self.get_token()}# 封装body参数body = {"messages": [{"role": "user","content": msg}]}headers = {"Content-Type": "application/json"}# 使用 json.dumps() 方法将字典转换为 JSON 格式字符串json_data = json.dumps(body, indent=4) # indent 参数可选,用于格式化输出# print("封装body参数=", body)# print("封装json_data参数=", json_data)response = requests.post(_url, timeout=10, params=params, data=json_data ,headers=headers)if response.status_code == 200:# 转成JSONjsondata = json.loads(response.text)# print(jsondata)recv_msg = jsondata["result"]else:print("请求失败")# 2、接受&处理 消息return recv_msgdef main():print ("########## run main() #############")qf = APIQianfan()access_token = qf.get_token()print("##########################")print(access_token)print("##########################")recv_msg = qf.send_chat("1+1=?")print("答:", recv_msg)print("##########################")
返回结果:
(base) zhenghui@zh-pc:/media/zhenghui/软件/project/pyProject/qianfan/cmdchat$ python3 cmdchat.py########## run main() #######################################24.5fcc16d4e36d66078f695f3cc59bef2a.2592000.1698916759.282335-40406243##########################问: 1+1=?答: 1+1等于2。##########################(base) zhenghui@zh-pc:/media/zhenghui/软件/project/pyProject/qianfan/cmdchat$
怎么样,爽吧。
恭喜你,本阶段完成,可以继续进阶了。
四、无间断问答功能开发
说直白点,就是无需退出,那么就while(true)即可,然后接收用户实时输入的数据。
新增代码如下:
def run_loop(self):while True:print("##########################")# 使用 input() 函数接收用户输入user_input_msg = input("问:")recv_msg = self.send_chat(user_input_msg)print("答:", recv_msg)print("##########################")
修改main函数如下:
def main():print ("########## run main() #############")qf = APIQianfan()qf.run_loop();if __name__ == "__main__":main()
最终运行结果:
文字:
(base) zhenghui@zh-pc:/media/zhenghui/软件/project/pyProject/qianfan/cmdchat$ python3 cmdchat.py########## run main() #############问:请问你是谁?##########################答: 你好,我是百度研发的知识增强大语言模型,中文名是文心一言,英文名是ERNIE Bot。我能够与人对话互动,回答问题,协助创作,高效便捷地帮助人们获取信息、知识和灵感。##########################问:请问音视频领域中AAC和MP3的区别是什么?##########################答: 在音频领域中,AAC和MP3都是常见的音频编码格式,它们之间的区别在于压缩效率和音质表现。AAC(Advanced Audio Coding)是一种高级音频编码,它比MP3具有更高的压缩效率,可以在相同音质下减少文件大小。这意味着您可以在相同的存储空间中存储更多的音频内容,或者在相同的带宽下传输更多的音频数据。此外,AAC还具有更好的音频质量。虽然MP3也可以提供高质量的音频,但是AAC可以提供更好的声音清晰度和细节表现。这使得AAC更适合需要高质量音频的应用程序,例如音乐播放器和流媒体服务。总的来说,AAC和MP3之间的选择取决于您的具体需求。如果您需要更小的文件大小或更少的带宽,那么AAC可能更适合您。如果您需要高质量的音频,那么MP3可能更适合您。##########################问:请问音视频领域中H265和H264的区别?##########################答: H.265和H.264都是视频编解码标准,但它们之间有一些关键的区别。1. 压缩效率:H.265比H.264更高效,能够提供更高的压缩比。这意味着在相同的视频质量和比特率下,H.265可以比H.264节省更多的存储空间和带宽。2. 编码效率:H.265的编码效率比H.264更高,这意味着它在处理视频时更快,并且可以更快地传输视频数据。3. 视频质量:虽然H.265比H.264更高效,但它并不会牺牲视频质量。实际上,H.265可以提供更好的视频质量,因为它可以在相同的比特率下提供更高的分辨率和更好的颜色还原度。4. 兼容性:H.265是一种新的编解码标准,因此在硬件和软件上的支持不如H.264广泛。这意味着如果您需要使用旧的硬件或软件来处理视频,您可能无法使用H.265编解码器。总的来说,H.265是一种更高效的编解码标准,可以提供更好的视频质量和更高的压缩比,但它的兼容性不如H.264广泛。##########################问:请使用python3写一个递归代码##########################答: 以下是一个使用Python递归的示例代码,用于计算斐波那契数列:```pythondef fibonacci(n):if n <= 1:return nelse:return (fibonacci(n-1) + fibonacci(n-2))该函数使用递归方式计算斐波那契数列,其中n表示要计算的斐波那契数。如果n小于或等于1,则返回n,否则返回(fibonacci(n-1) + fibonacci(n-2))的结果。这个递归过程会一直持续到n等于1,然后返回n的值。
##########################
最终整理代码如下:
cmdchat.py:
#!/usr/bin/python3import requestsimport jsonimport config # 引入配置文件操作工具class APIQianfan:def __init__(self):# 创建 Config 对象self.cf = config.Config()# 配置文件赋值self.url = self.cf.config_data["qianfan_conf"]["url"]self.APIKey = self.cf.config_data["qianfan_conf"]["APIKey"]self.SecretKey = self.cf.config_data["qianfan_conf"]["SecretKey"]if "access_token" in self.cf.config_data["qianfan_conf"]:self.access_token = self.cf.config_data["qianfan_conf"]["access_token"]else:self.access_token = ""# 检查是否过期def token_is_valid(self):# .......return Truedef get_token(self):# 1、检查token是否存在if self.access_token != "":# 存在,检查是否过期if self.token_is_valid():# 存在token,并且没过期直接返回给用户return self.access_token# 2、否则重新获取一遍tokenparams = {"grant_type" : "client_credentials","client_id" : self.APIKey,"client_secret" : self.SecretKey,}response = requests.post(self.url, timeout=10, params=params)if response.status_code == 200:# 转成JSONjsondata = json.loads(response.text)# print(jsondata)self.access_token = jsondata["access_token"]# 保存到config.json中self.cf.config_data["qianfan_conf"]["access_token"] = self.access_tokenself.cf.write(self.cf.config_data)return self.access_tokenelse:print("请求失败")return ""def send_chat(self, msg):recv_msg = ""_url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/eb-instant"# 1、发送消息# 封装query消息params = { "access_token" : self.get_token() }# 封装body参数body = {"messages": [{"role": "user","content": msg}]}headers = { "Content-Type": "application/json" }# 使用 json.dumps() 方法将字典转换为 JSON 格式字符串json_data = json.dumps(body, indent=4) # indent 参数可选,用于格式化输出# print("封装body参数=", body)# print("封装json_data参数=", json_data)response = requests.post(_url, timeout=10, params=params, data=json_data ,headers=headers)if response.status_code == 200:# 转成JSONjsondata = json.loads(response.text)# print(jsondata)recv_msg = jsondata["result"]else:print("请求失败")# 2、接受&处理 消息return recv_msgdef run_loop(self):while True:print("##########################")# 使用 input() 函数接收用户输入user_input_msg = input("问:")recv_msg = self.send_chat(user_input_msg)print("答:", recv_msg)print("##########################")if __name__ == "__main__":print ("########## run main() #############")qf = APIQianfan()qf.run_loop()
config.json:
{"qianfan_conf": {"url": "https://aip.baidubce.com/oauth/2.0/token","APIKey": "VsysBQ2sY44B47Li712OGyna","SecretKey": "uMQX9PMyAMZdESQm0awlwbmitO868TGH","access_token": "24.5fcc16d4e36d66078f695f3cc59bef2a.2592000.1698916759.282335-40406243"}}
config.py:
#!/usr/bin/python3import jsonclass Config:def __init__(self):self.config_path = "./config.json"# 创建config_data,用于存储json数据self.config_data = Noneself.read()# 读取json配置文件def read(self):# 需要增加异常捕捉等代码with open(self.config_path, 'r') as file:self.config_data = json.load(file)return self.config_data# 写入json配置文件def write(self, config_data):with open(self.config_path, 'w') as file:json.dump(config_data, file, indent=4)
恭喜你,实现了自己的机器人!!!!
恭喜你,实现了自己的机器人!!!!
恭喜你,实现了自己的机器人!!!!
代码完全可以:复制--粘贴---运行!!!!
代码完全可以:复制--粘贴---运行!!!!
代码完全可以:复制--粘贴---运行!!!!
Linux命令行机器人系列文章导航
如果前三步骤都很熟悉了,请跳过直接第4步。否则强烈建议查看学习!!!
Linux命令行机器人之---1.初识百度智能云千帆大模型平台: https://cloud.baidu.com/qianfandev/topic/267409
Linux命令行机器人之---2.初学者快速入门千帆大模型平台: https://cloud.baidu.com/qianfandev/topic/267410
Linux命令行机器人之---3.千帆大模型平台HelloWorld实例: https://cloud.baidu.com/qianfandev/topic/267411
Linux命令行机器人之---(4.)100行代码挑战开发一个完整的命令行机器人: https://cloud.baidu.com/qianfandev/topic/267413
评论
