送给儿子的生日礼物-微兔兔(基于千帆Appbuilder-智能硬件AIoT创意赛第一期)
大模型开发/技术交流
- 千帆杯挑战赛
1天前54看过
一、前言
参赛者需基于以下五类主题(任选其一),调用AppBuilder内置工具组件/自定义组件/知识库/数据库等,创建一个在智能硬件终端产品中能够产生实用价值的应用。
-
儿童陪伴类:为儿童提供趣味陪伴的AI agent,常见场景如绘本陪读、知识百科、人设陪伴等功能。
-
学习教育类:主要为学前和k12学生提供学习教育类AI agent,常见场景如专业英语口语陪练、AI体育老师、数学解题、单词记忆、汉字学习等。
-
娱乐互动类:为全年龄段用户提供娱乐互动类AI agent,常见场景如漫画头像生成、旅游规划、角色扮演、游戏攻略助手、宠物情绪识别等。
-
老年养生类:为老年人提供健康养生类AI agent,常见场景如健康问答、老年健康饮食助手、生活健康提醒等。
-
健康监测类:创作健康监测类AI agent,具体场景包括AI舌诊、家庭AI医生、AI陪伴减重等
二、背景
当前,物联网(IoT)与人工智能(AI)的融合发展正在以前所未有的速度推动智能家居和教育领域的革新。AIoT(AI + IoT),即人工智能物联网,不仅实现了设备之间的互联互通,还赋予了这些设备类似于人类的“思考”与决策能力,使其能够根据收集的数据做出智能化反应,从而提升了整体系统的效能与用户体验。
LLM(大语言模型)的迅猛发展推动了人工智能(AI)迈向通用人工智能(AGI)的新时代。伴随着新型模型的不断涌现,AI技术也在快速迭代,为各行业的应用带来了广泛而深刻的变革。在教育领域,AI通过自然语言对话简化了学习过程和门槛,能够为每位学生量身定制适合的学习路径,实现真正的因材施教。这种个性化的学习方式不仅提高了学习效率,还增强了学生的学习兴趣,推动了教育的创新与发展。此外,智能家居环境下的儿童教育系统,利用了物联网设备来创建沉浸式的教育体验,使学习不再局限于传统的课堂之内。例如,智能语音助手可以作为辅助教学工具,帮助孩子们解决作业中的难题,而智能穿戴设备则能监测孩子的健康状况,确保他们在健康的状态下学习。
总而言之,随着AI与IoT技术的不断进步及其在实际应用中的深度融合,无论是智能家居还是教育领域,都将迎来更加智能化、高效化的发展前景,为人们的生活带来前所未有的便利与可能性。
基于前述的参赛背景,我选择了儿童陪伴类的参赛主题,主要就是可以给我那三岁的小朋友讲一些好听的,具有普适性意义的儿童童话故事,取材基本限定格林童话,安徒生童话,一千零一夜的这样的经典。主打一个陪伴
三、开发板介绍
硬件方面其实有很多选择:树莓派,jetson,arduino不一而足,之前也曾经玩过一些时间的openwrt固件,也不算0基础。最近的AI火爆,想来想去只有基于x86架构的哪吒才是正当其时的
-
开发板资料:
哪吒哪吒顾名思义,很小很能打。1.8寸的小板上搭载了Intel® N97处理器(Alder Lake-N),最大睿频3.6GHz,Intel® UHD Graphics内核GPU,可实现高分辨率显示;板载LPDDR5内存、eMMC存储及TPM 2.0,配备GPIO接口,支持Windows和Linux操作系统,这些功能和无风扇散热方式相结合,为各种应用程序构建高效的解决方案,适用于如自动化、物联网网关、数字标牌和机器人等应用。
开发板详细资料如下,有图有真相:


-
开箱照片:

红色的就是主角哪吒了,接口有3个USB3.2和HDMI接口,网口(左侧),还有40针的GPIO和串口,官方还很贴心的放了一个绿联的无线双频网卡在里面。
四、项目介绍
-
整体构思:
-
产品介绍:微兔兔是一款拥有可爱造型的婴幼儿伴读功能的早教机器人,它具备音频互动和简单的图片识别功能。孩子可以通过与应用中的可爱角色对话,享受有趣的故事时间。该产品也能够识别特定位置的图片,能根据图片内容和小朋友互动进行场景式教学,同时通过内置的儿童语音互动鼓励孩子,让学习变得更加生动有趣。
-
功能设计:微兔兔的设计理念是将教育与娱乐完美融合,让孩子在玩耍中学习,在学习中玩耍。其内置的音频互动功能允许孩子们与虚拟角色进行自然流畅的对话,这种交互方式不仅能激发孩子的兴趣,还能锻炼他们的语言表达能力和社交技能。此外,微兔兔还能识别特定位置的图片,这意味着当孩子展示特定的卡片或书籍时,微兔兔会根据图片的内容进行相应的互动,从而引导孩子进入一个充满想象的情景教学环境中。 为了进一步提升学习效果,微兔兔还配备了儿童专用的语音识别系统,能够及时给予正面反馈和鼓励。当孩子参与互动时,微兔兔会用温馨的话语表扬他们,这种积极的强化机制有助于培养孩子的自信心和积极性。不仅如此,微兔兔还能根据孩子的反应调整教学策略,确保每个孩子都能获得最适合自己的学习体验。 微兔兔的设计充分考虑到了家长的需求,家长可以通过配套的应用程序来监控孩子的学习进度,甚至参与到孩子的学习过程中。这款应用程序提供了丰富的教育资源,包括各种故事书、儿歌和教育游戏,家长可以根据孩子的兴趣选择合适的内容。此外,应用程序还支持远程控制功能,即使家长不在孩子身边,也能通过手机远程指导孩子与微兔兔互动。
-
产品总结:总之,微兔兔不仅仅是一个简单的玩具,它是一款具有创新性的早教工具,旨在通过趣味横生的方式帮助孩子发展关键的认知技能和社会交往能力。无论是对于渴望陪伴孩子成长的父母,还是对于希望探索新奇世界的幼儿来说,微兔兔都是一款不可或缺的好伙伴。
-
方案架构
2.1 软件部分
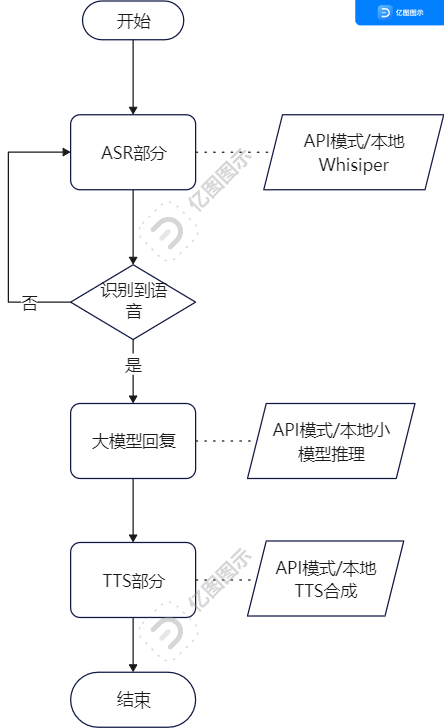
-
ASR部分,可以考虑本地whisper模型部署,也可以采用api的模式
-
大模型部分,可以进行本地模型部署,充分利用openvino的推理平台能力;也可以走api的模式
-
TTS部分,可以考虑本地TTS合成部署,也可以采用api模式
2.2 硬件部分
以前打游戏有个闲置usb麦克风,然后外加一个网上买的单线usb音箱(因为哪吒板上没有音频接口的):

后来发现其实有音箱麦克风一体的USB接口,可以省下一个USB扣,感觉这就很尴尬了。
五、MVP(最小化实现)
软件开发环境
哪吒三太子自然要配个大红的底座,进来以后就是熟悉的配方熟悉的味道。Win11.为了调试麦克风设备和音箱设置还被迫去下了个kms activator来激活。

说实话其实IoT更适合用linux系统,从我个人角度来说很喜欢wsl系统(我死了),那个可以很方便的在windows下操作docker。这个世界没有docker我觉得很多都玩不转。说实话这个系统还是不错的配置了8G内存和64G存储,比我想象的要好很多了。
自然这里是有vscode的,这对于python的用户还是蛮友好的。虽然没有pycharm啥的,也凑活
ASR部分
-
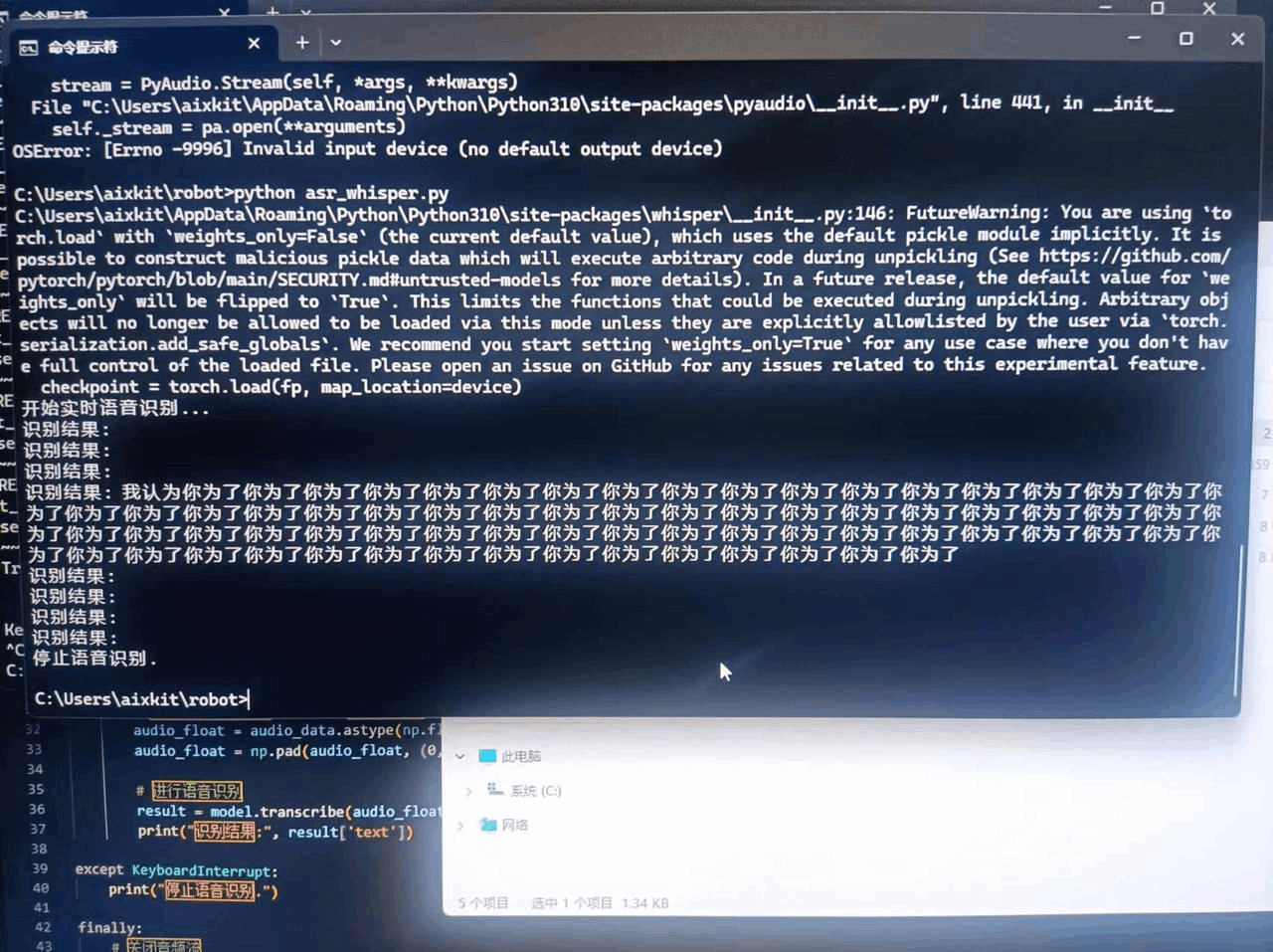
Whisper本地库
import pyaudioimport numpy as npimport whisper# 初始化 Whisper 模型model = whisper.load_model("base") # 可以选择 "tiny", "base", "small", "medium", "large"# PyAudio 设置chunk = 1024 # 每次读取的音频块大小format = pyaudio.paInt16 # 音频格式channels = 1 # 单声道rate = 16000 # 采样率p = pyaudio.PyAudio()# 打开音频流stream = p.open(format=format,channels=channels,rate=rate,input=True,frames_per_buffer=chunk)print("开始实时语音识别...")try:while True:# 读取音频数据data = stream.read(chunk)audio_data = np.frombuffer(data, dtype=np.int16)# 将音频数据转换为 Whisper 需要的格式audio_float = audio_data.astype(np.float32) / 32768.0 # 归一化到[-1, 1]audio_float = np.pad(audio_float, (0, 16000 - len(audio_float)), 'constant') # 填充到16秒长度# 进行语音识别result = model.transcribe(audio_float, fp16=False) # fp16=False是为了避免在某些硬件上出现问题print("识别结果:", result['text'])except KeyboardInterrupt:print("停止语音识别.")finally:# 关闭音频流stream.stop_stream()stream.close()p.terminate()
Whisper本地部署时可以的,这里用了base,一个很小的库但是效果。。。但感觉不太行,为了保证演示起见我们还是考虑采用API的方式;
-
ASR部分-Azure的API,当然你的订阅key和region自己选择;看了说明应该每个月只有5小时免费,不知道测试完是不是就给我哗哗的扣钱了。😭至于百度语音api考虑下次,本次比赛没有要求用百度tts
# This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION"speech_config = speechsdk.SpeechConfig(subscription='xxx', region='eastasia')speech_config.speech_recognition_language="zh-CN"audio_config = speechsdk.audio.AudioConfig(use_default_microphone=True)speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config)print("Speak into your microphone.")def stop_cb(evt):print('CLOSING on {}'.format(evt))speech_recognizer.stop_continuous_recognition()global donedone = Truedef sent_to_model(text):response = get_response(text)if response:print("model response:",response)text_to_speech(response)#speech_recognizer.recognizing.connect(lambda evt: print('RECOGNIZING: {}'.format(evt)))speech_recognizer.recognized.connect(lambda evt: print('RECOGNIZED: {}'.format(evt)) or sent_to_model(evt.result.text))speech_recognizer.session_started.connect(lambda evt: print('SESSION STARTED: {}'.format(evt)))speech_recognizer.session_stopped.connect(lambda evt: print('SESSION STOPPED {}'.format(evt)))speech_recognizer.canceled.connect(lambda evt: print('CANCELED {}'.format(evt)))speech_recognizer.session_stopped.connect(stop_cb)speech_recognizer.canceled.connect(stop_cb)speech_recognizer.start_continuous_recognition()while not done:time.sleep(.5)
其实还有很多api 的option,大家自己多试试。
LLM部分
-
比赛要求上appbuilder,冲!
import appbuilderimport osos.environ['APPBUILDER_TOKEN'] = "xxxxxxxxxxxxxxxxxxxxxxxxxxx"app_id = "acf19b27-1019-45fb-b163-a454d31ef014"def agent_query( query: str):# 初始化Agent实例agent = appbuilder.AppBuilderClient(app_id)# 创建会话IDconversation_id = agent.create_conversation()print("您的AppBuilder App ID为:{}".format(app_id))print("processing")response_message = agent.run(conversation_id=conversation_id, query=query)description = response_message.content.answerreturn descriptionif __name__ == '__main__':prompt = '讲一个灰姑娘的故事'print(agent_query(prompt))
2.喜欢折腾的可以参考openvino的本地qwen2.5-7b部署
TTS部分
-
API方式,我们这里还是用的Azure,我喜欢微软,别问我为什么
async def text_to_speech(text):speech_config2 = speechsdk.SpeechConfig(subscription='xxx', region='eastasia')audio_config2 = speechsdk.audio.AudioOutputConfig(use_default_speaker=True)# The neural multilingual voice can speak different languages based on the input text.speech_config2.speech_synthesis_voice_name='zh-CN-XiaoyiNeural'speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config2, audio_config=audio_config2)# Get text from the console and synthesize to the default speaker.print("tts=>>>",text)speech_synthesis_result = speech_synthesizer.speak_text_async(text).get()if speech_synthesis_result.reason == speechsdk.ResultReason.SynthesizingAudioCompleted:print("Speech synthesized for text [{}]".format(text))elif speech_synthesis_result.reason == speechsdk.ResultReason.Canceled:cancellation_details = speech_synthesis_result.cancellation_detailsprint("Speech synthesis canceled: {}".format(cancellation_details.reason))if cancellation_details.reason == speechsdk.CancellationReason.Error:if cancellation_details.error_details:print("Error details: {}".format(cancellation_details.error_details))print("Did you set the speech resource key and region values?")
这里其实 一直有个小bug和问题,有时候会发现有合成的语音直接被ASR捕捉了,然后试了很多方式,设置asr_active和tts_active的开关量来控制希望在TTS过程中不会有声音被ASR捕捉,但是一直不怎么成功。后续引入线程机制,初步测试感觉引入线程机制是比较有效的,但是真正的串音好像还没有彻底解决。
我甚至提了一个issue给微软的ASR团队。
估计解决起来应该需要研究下回音消除或者这种串扰具体发生的机理,还请懂得大侠不吝赐教。
-
本地TTS的部署:
六、演示
如下简单的录了一段演示视频,贴在B站上了。录得不一定好,儿子还不太熟悉,程序设定的也不太好,大家多多包含。
视频号我也放上去了,各位关注微信视频号:AI-Researcher即可以查看。

七、总结和后记
首先感谢百度的智能硬件第一场赛事,也感谢千帆平台的各种资源和api,再呢就感谢我的家人尤其是我的老婆和儿子,最近调试的有点冒火,是不是受了三太子的影响,哈哈。
这个算是给儿子的生日礼物吧。希望他能真正成长起来。
后续其实这块板子还是可以做很多事情的,接上摄像头和多模态大模型做一些图像或者视频识别,甚至视频分析Yolo都应该都可以,接上轮子和伺服电机就可以跑了。
所以想想空间还是蛮大的。这次的确也是第一次能够结合硬件和大模型做点好玩的东西,感觉AI的领域空间无限大,再次感谢家人的陪伴和支持,也感谢大家看到最后。
评论
