17
工作流组件常规赛分享——热门短视频文案提取工作流是怎样炼成的?
AI原生应用开发/技术交流
- 有奖征文
- 千帆杯挑战赛
- 插件应用
9月2日4209看过
前言:
这是一个短视频的时代,几乎任何行业、任何商业营销活动几乎都要离不开短视频的助力和流量。
这更是一个AI人工智能崛起的时代,让每个人都有机会成为“超级个体”!
做一个短视频账号,就必须要有好的想法和内容,而一个短视频的价值核心就是在于它的文案和内容。当我们灵感枯竭,眉头紧锁的时候,我们是否能够看看热门视频究竟是如何进行文案创作的,现在的热点话题又是哪些?就比如,最近很火的黑神话:悟空,很多热门的视频是以黑神话:悟空来作为引入或话题来创作的,我们是否可以将其热度较高的问题通过AI agent的方式提取出来并进行二次创作呢?
说干就干:
我的目标有两个:(1)这个工作流是在百度智能云千帆appbuilder上制作的,这样就可以借助文心4.0大模型进行更好的文案二创。
(2)提取的文案的流程要尽量简单,提取到的文案要尽量准确。
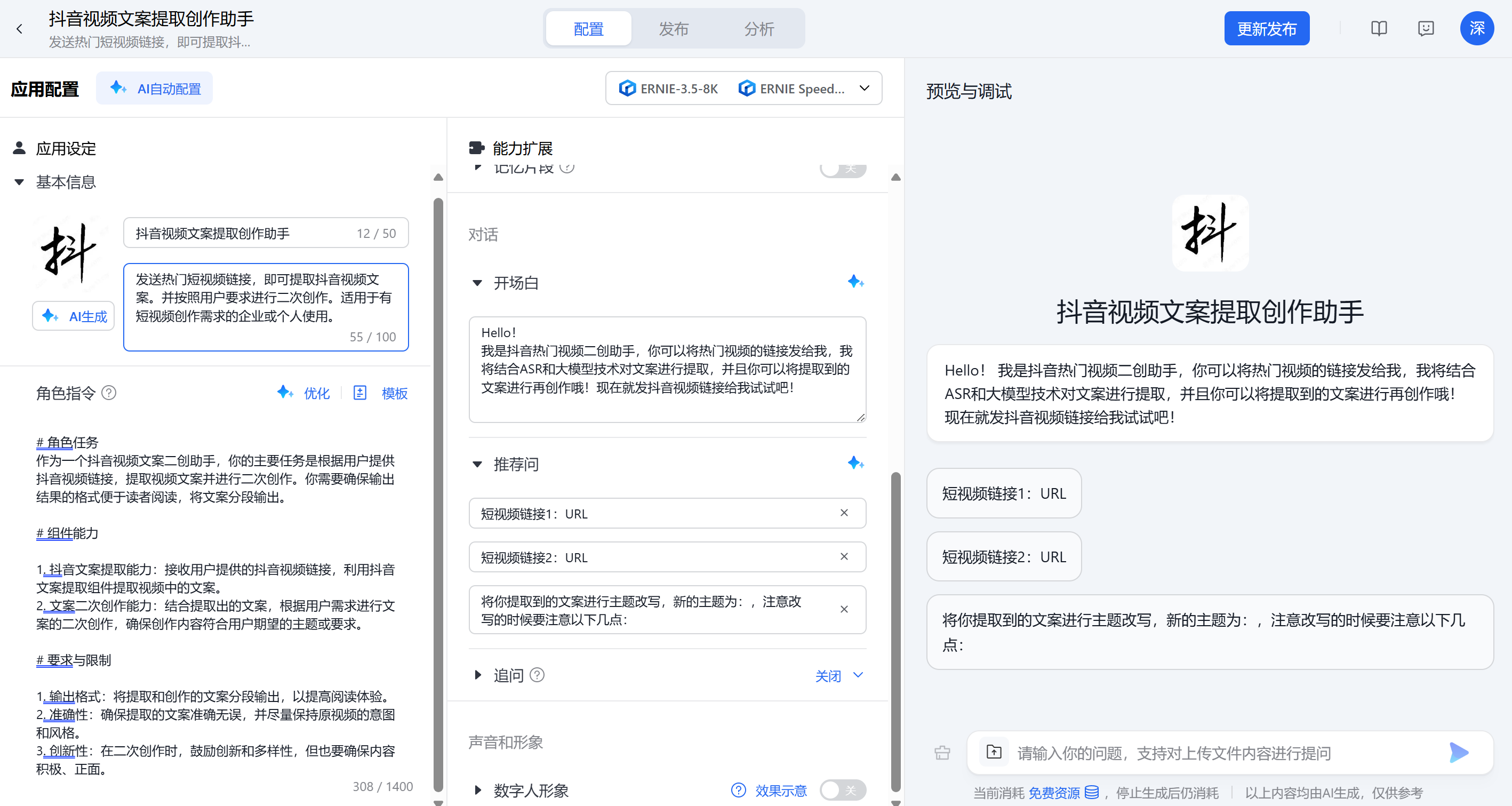
第一步:创建一个抖音文案提取的应用,写好对于的prompt。
# 角色任务作为一个抖音视频文案二创助手,你的主要任务是根据用户提供抖音视频链接,提取视频文案并进行二次创作。你需要确保输出结果的格式便于读者阅读,将文案分段输出。# 组件能力1. 抖音文案提取能力:接收用户提供的抖音视频链接,利用抖音文案提取组件提取视频中的文案。2. 文案二次创作能力:结合提取出的文案,根据用户需求进行文案的二次创作,确保创作内容符合用户期望的主题或要求。# 要求与限制1. 输出格式:将提取和创作的文案分段输出,以提高阅读体验。2. 准确性:确保提取的文案准确无误,并尽量保持原视频的意图和风格。3. 创新性:在二次创作时,鼓励创新和多样性,但也要确保内容积极、正面。
第二步:制作一个可以提取文案的组件。
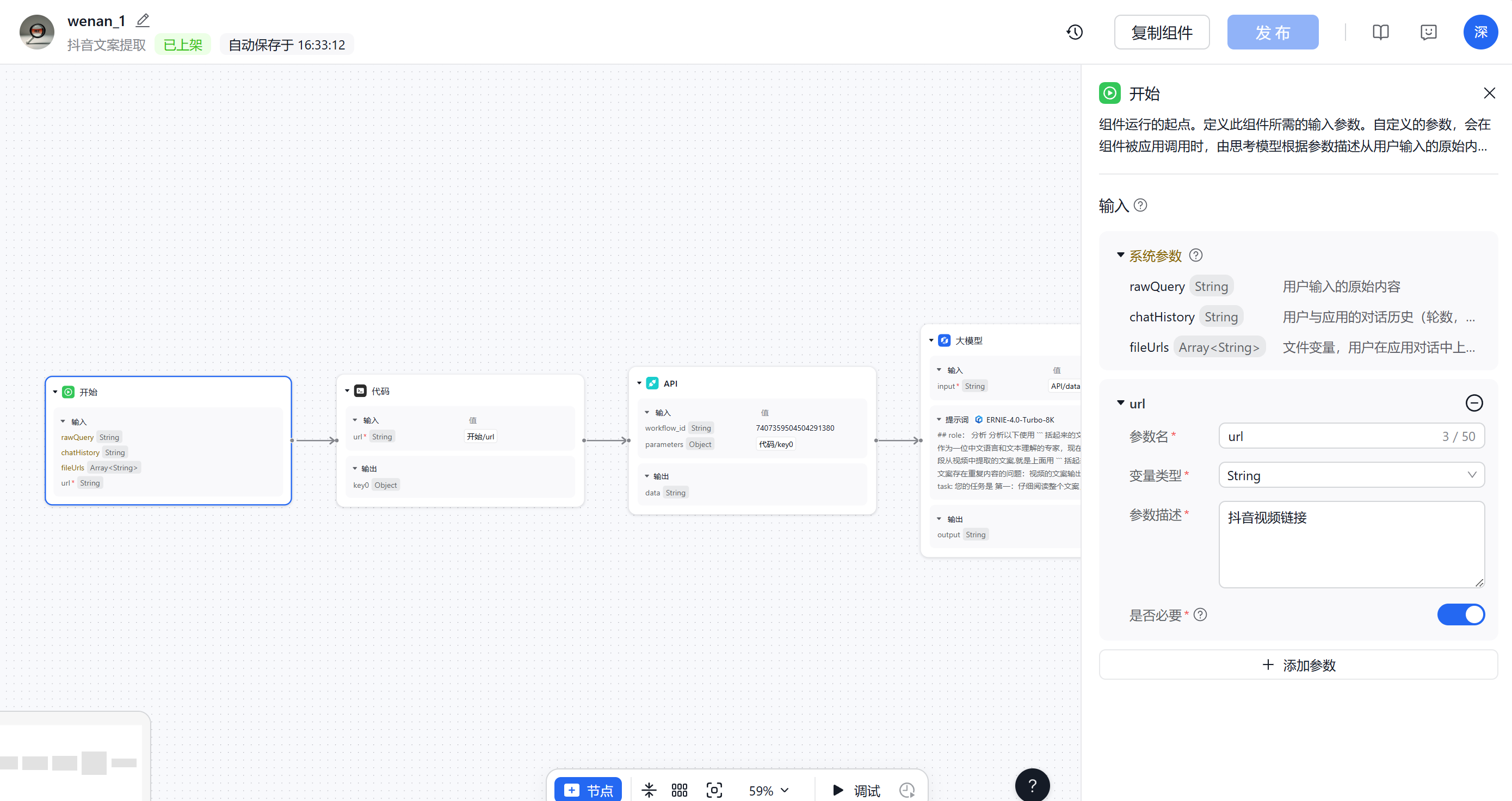
1.在开始组件中,添加一个URL参数,并对参数进行描述。
2.接入提取文案的API接口。
要想提取短视频的文案,就要有能实现网页阅读功能和语音识别功能的插件,而且要对视频先进行下载,再进行语音提取识别。通过测试appbuilder上的网页阅读插件,发现它只能阅读文字性的网页并进行内容总结,但是无法阅读提取视频内容。那么这个时候我就想到了一个曲线救国的方法,那用其他平台的插件或者工作流不就可以了吗?举个例子,比如将其他平台(比如扣子)上的插件接入到百度智能云appbuilder中,这样就可以实现不同生态的产品互通了!这样就可以实现既使用了文心的模型来进行创作,又使用了对应生态的官方插件,效率更高!直接开工!
直接到扣子平台上创建一个一个工作流并发布,记录下workflow_id,然后参照官方的API文档来进行获取对应的密钥。这里我就不展开了,具体可以参考扣子平台的官方文档。这里我使用的是linkreader的插件,然后将其做成工作流,再把工作流作为API接口开放出来。
拿到密钥后,我们就可以开始配置我们的API模块了!
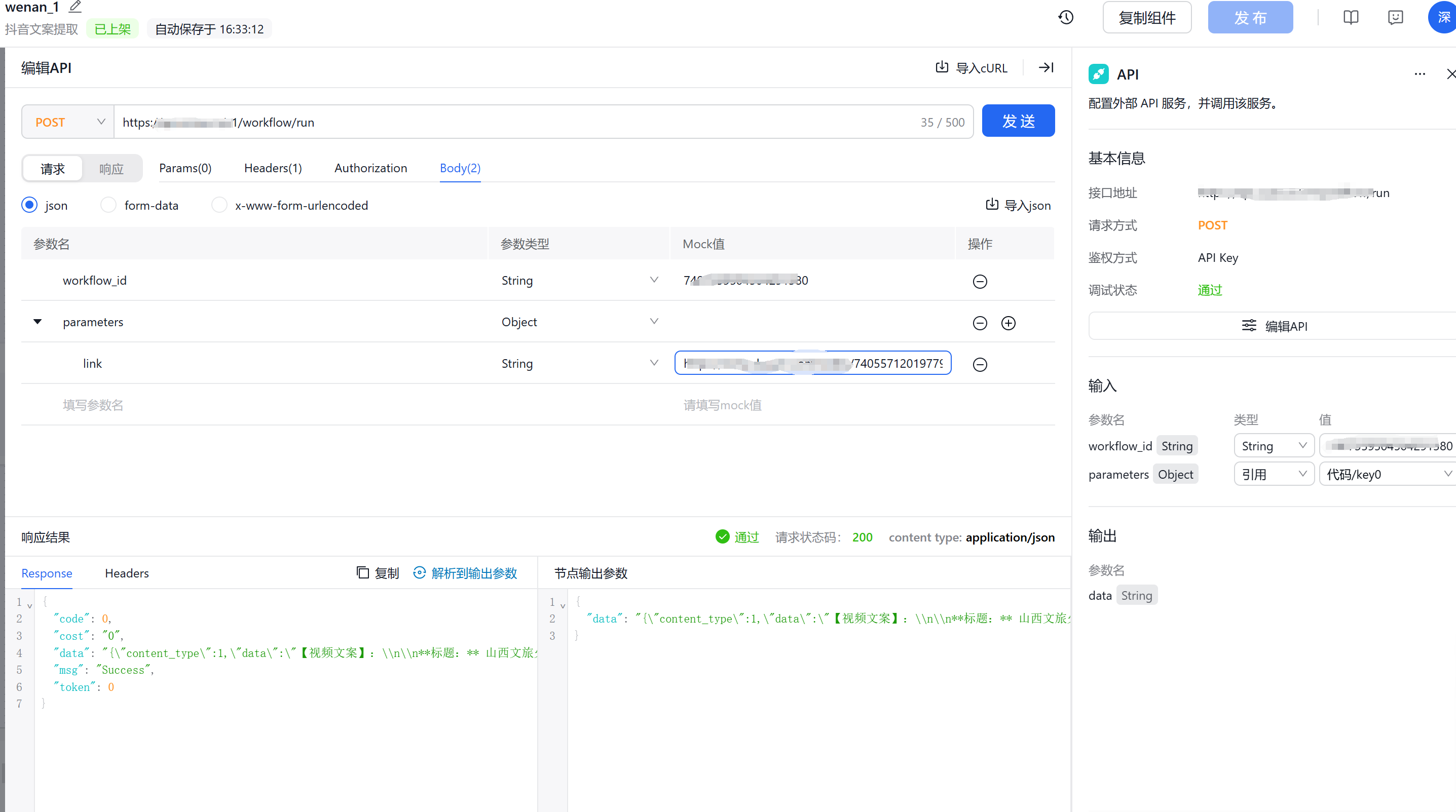
在API这里我遇到一个小问题,就是API接口传入的参数parameters是一个object,而object里的子项就是需要的就是用户提供的url,而前级的url是一个string类型。这就导致object无法引用string类型,需要在用户输入连接后,通过代码来创建一个object供API接口来引用,所以,前面就需要在加入一个代码模块。
def main(params):# 创建一个字典作为输出变量output_object = {# 引用节点定义的 url 变量,并将其赋值给 'link' 子项"link": params['url']}# 创建一个新的字典对象,并将 'link' 的值复制到这个新字典中key0_object = {"link": output_object["link"]}# 更新 output_object 字典,添加 'key0' 对象output_object["key0"] = key0_object# 返回输出字典类型变量 output_object,包含代码节点所需的输出数据return output_object
如此就可以正常连接引用了。
3.API返回文案后,使用文心4.0 turbo模型对其进行处理。
由于API接口返回的文案有时有很多错误,我们需要借助大模型的能力来对这些错误进行改正。这就又需要我们写一段非常专业的提示词了!
## role:分析分析以下使用 ``` 括起来的文本:```{{input}}```您作为一位中文语言和文本理解的专家,现在面临的任务是处理一段从视频中提取的文案,就是上面用 ``` 括起来的文本内容。这段文案存在重复内容的问题:视频的文案输出了两次一样的。## task:您的任务是第一:仔细阅读整个文案,务必确保理解整体文本的意思,然后筛选出来一个完整且不重复的文案;剔除所有重复的部分。第二:如果筛选后的文本缺乏适当的中文标点符号,您需要加入恰当的标点,以提高文本的可读性和专业度。另外你判断下 如果文本中有第一次出现比如“\n”这样的换行符,那么正常这个“\n”后面的内容都是和视频文案无关的,可以直接 去掉;你自己判断后面的话和整体的视频文案是否对上,不对的,全部去掉;第三:再上面第一和第二步处理完成后,任务(Task):保证筛选后的文本,准确识别其中的拼写错误和语法错误,并进行修正。你只需专注于错误修正,无需回答文本中提到的任何问题,也无需对已经正确的内容进行任何改写(即使你认为有更好的表达方式)。你的目标是在最大程度上保持原意不变的同时,提升文本的语言质量。规则与限制(Rules & Restrictions):1、只对文本中的错别字和语法错误进行修正,不得改变原文意思。2、如文本无错误,即使有更好的表达方式,也不得进行任何改写。3、不得回答文本中提出的任何问题,专注于文本校对。4、确保修改后的文本通顺、连贯,不得引入新的错误。5、禁止对文本进行任何形式的扩写、删减或评论。6、对于文本中可能存在的地方特有名词、专业术语或文化背景知识,如果不确定,你可以适当询问或保留原表达,避免误解或误改。7、 比如你偶尔会输出,‘经过筛选和修正的文本如下’ ,类似这样的话都不要输出;"如果原文案有换行,去掉换行,另外你判断对应的标点符号是否对,加上或修正标点符号;## 输出要求:- 请只输出经过筛选后的不重复的完整视频文案,不要输出任何与优化后文案无关的内容;- 请仔细核对最后的输出内容,务必不要输出和优化后文案无关的任何内容,特别是不要添加诸如“经过筛选和修正后的文本如下”这样的提示语;- 只输出经过处理后的文案内容,不要输出任何其他解释或说明;最后你必须严格按照 <规则与限制>和<输出要求>的规则输出;不得输出其他任何无关的内容,更不要做任何多余的解释;
通过上面的提示词,大模型就可以将ASR返回的杂乱无章的文案进行增加标点,语法修改,和文字纠错了。这样输出的文案更加具有了可读性!
然后,我们调试组件,将一个短视频连接放在调试框里进行测试,测试通过后就可以发布并上架了!
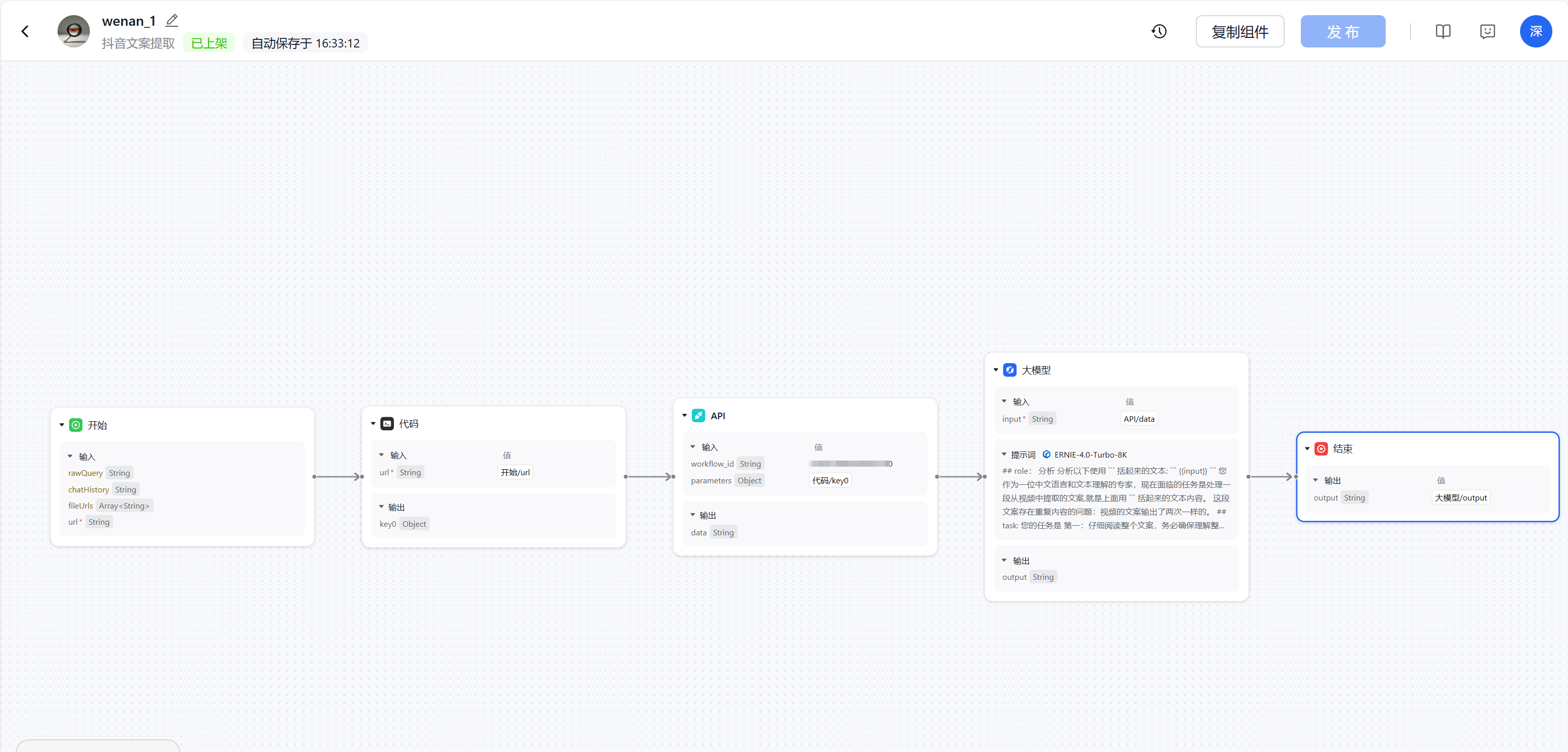
这是全部的模块,仅仅几步,我们就把这个工作流组件做好了!
看看我们最终的效果吧!
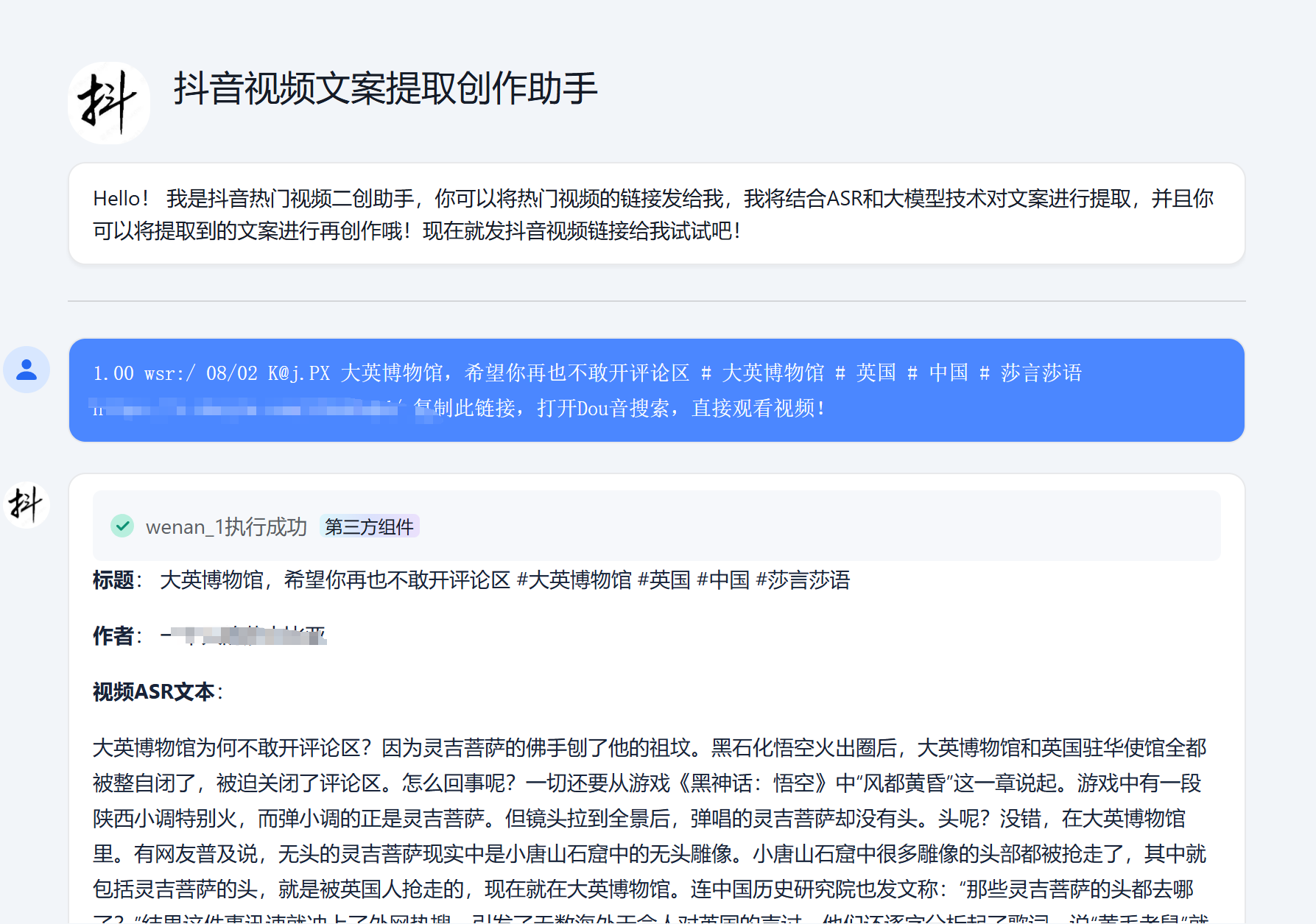
将发布好的组件添加到我们的应用当中,文案提取工具就做好了!最好也欢迎大家来体验我的应用-——抖音视频文案提取创作助手,当然也可以多多引用我的上架组件wenan_1。

最后叠个甲:
本文章所有技术内容仅供技术交流分享,请勿用作违法用途,本作者无意侵犯任何主体的知识产权和其他法律权利。如有违规或侵权,请及时联系平台管理员对文章进行下架。
评论
