【千帆AppBuilder】院校录取分数线AI原生应用通过知识库实现问答精准信息输出的经验分享(1)
AI原生应用开发/技术交流
- LLM
- 文心大模型
- Prompt
2天前84看过
我在百度智能云千帆AppBuilder开发了一款AI原生应用,快来使用吧!「院校录取分数线」:https://appbuilder.baidu.com/s/XX1fSlOK
⭐背景
在上次线上会议里给大家分享过此款AI应用知识库的相关经验,
发现大家并没有什么反馈和意见,可能大家都会了吧,也可能大家没有Get点或者实战比较少。
线上有个小伙伴提出自己见解,这个应用并不是很实用,不能保证数据实时性?
在此分享知识库一些经验的同时,也是给有疑问的小伙伴解释下。
🎬直播回放已上线!
AppBuilder数据库/知识库高阶使用技巧:https://cloud.baidu.com/qianfandev/live/2649ee7261
⭐疑惑解释
线上有个小伙伴提到这个应用不是很好,没有保证到数据时效性,
他提到,大学的数据每次都要到对应大学抓取下来保存到一个表格里,
然后上传上去,实用上并不是很好。
非常感谢这位小伙伴的提出自己的见解和问题。
也非常感谢莫老师的反驳和解释,本次会议的目的是通过开发者分享的思路去开发自己应用,这个才是重点。
在此,小5老师也想和大家解释和分享下自己的理解,希望你能有所收获。
🌹探索为主
首先,不管应用是否好不好用,本次主要是以使用知识点进行经验探索为主。
🌹历史数据
其次,录取分数线对于历史数据来说是固化的,完全可以以文档形式作为知识库,
这个并不影响历史分数线的查询,并且可以使用这庞大分数线数据进行全域问答测试。
基本信息、历史录取分数线、相关事情信息等都可以固化下来,效果也是非常不错的。
🌹定时更新
最后,知识库现在也支持URL地址数据解析,并且能够根据频率发起URL调用更新数据。
目前测试,同一组数据会覆盖,新内容会增加到新切片等。
此方法也可以间接实现最新录取分数线知识库更新,基本能够实现会议上小伙伴提到的不能够保证实时性的情况。
目前此款AI应用主要以探索知识库使用的经验为主,在大批量数据情况下,探索问答知识库匹配命中正确率。
🌹数据整理
上面小伙伴提到确保实时性需要整理数据成表格然后再上传,感觉不太实用。
其实,有很多方式方法可以自动帮我们完成这些工作,加上支持了URL,基本上能够保证实时性。
因为分数线这些数据基本都是固化数据,不会有太大变动数据,使用文本文档方式保存成知识库也是非常合适的。
⭐知识库
🌹模型选择
大家可能已经发现,ERNIE-3.5、ERNIE-4.0、ERNIE-Speed-AppBuilder这几个大模型各自能力有所提升。
ERNIE-Speed-AppBuilder,速度上确实是快了。
如果追加思考和问答快速响应(性能),没什么复杂业务逻辑,单纯文本类,那么Speed模型是最佳选择,。
ERNIE-4.0,在思考和问答方面变得更加聪明了。
如果追加组件和Prompt、问答更加精准,场景具有一定复杂业务逻辑,那么4.0模型是最佳选择,但是速度上会慢一点,输出质量会高。
-
大模型广场地址:
🌹文本格式
文本内容的结构和关键知识点对精准匹配也是非常关键
🌹数据出错格式
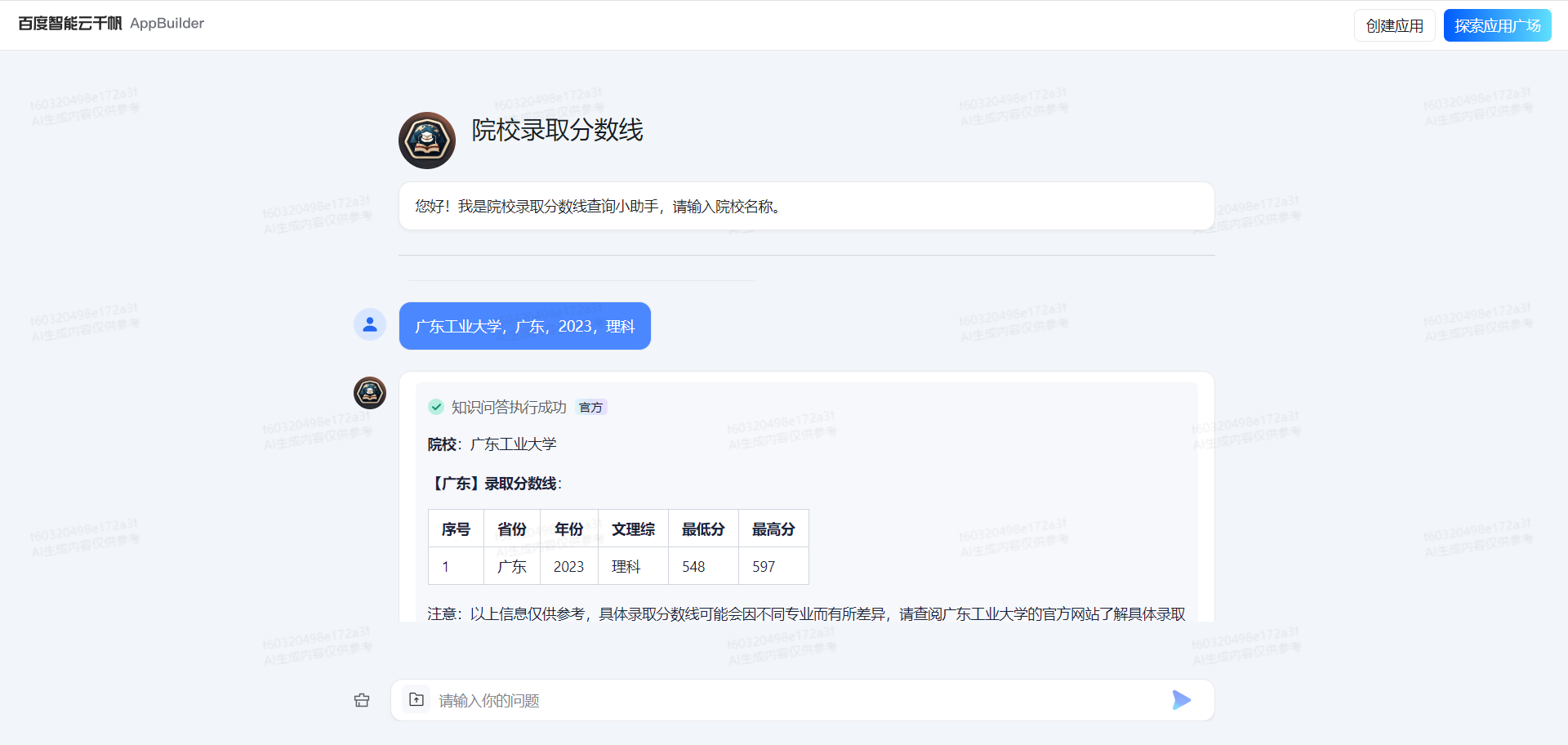
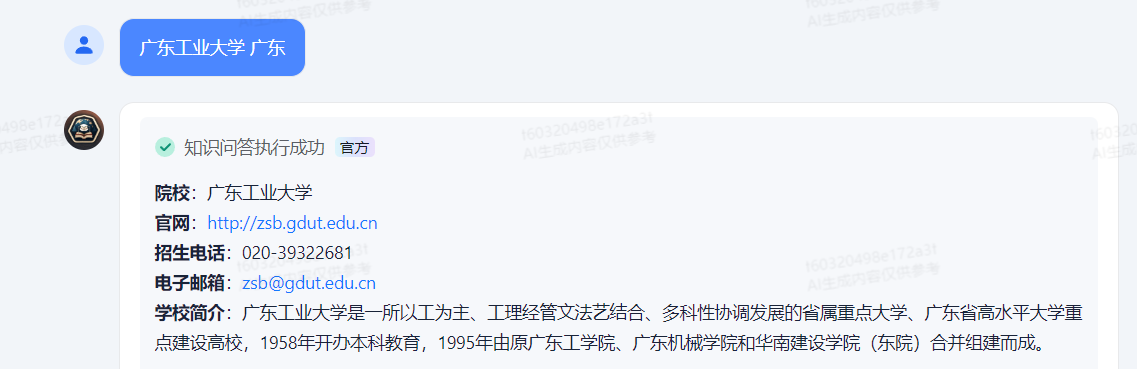
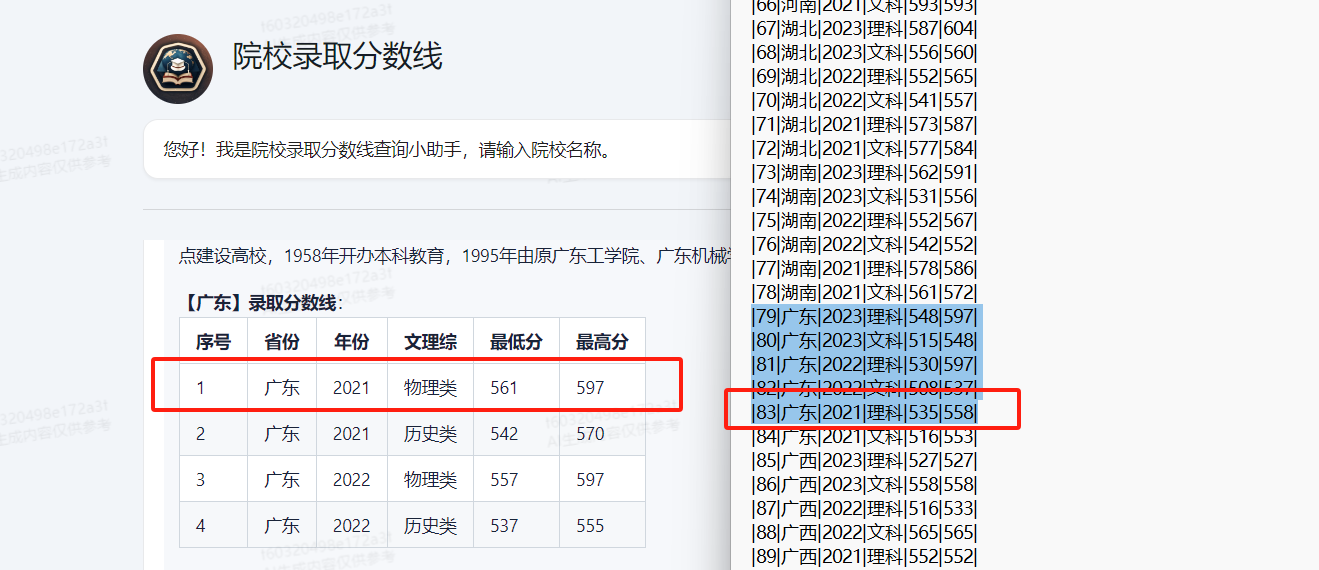
提问:广东工业大学 广东
目的是让AI应用输出广东工业大学在广东2021到2023年的录取分数线。
从下面查看到信息是不对的,因为这次模糊询问未能精准匹配到对的数据。
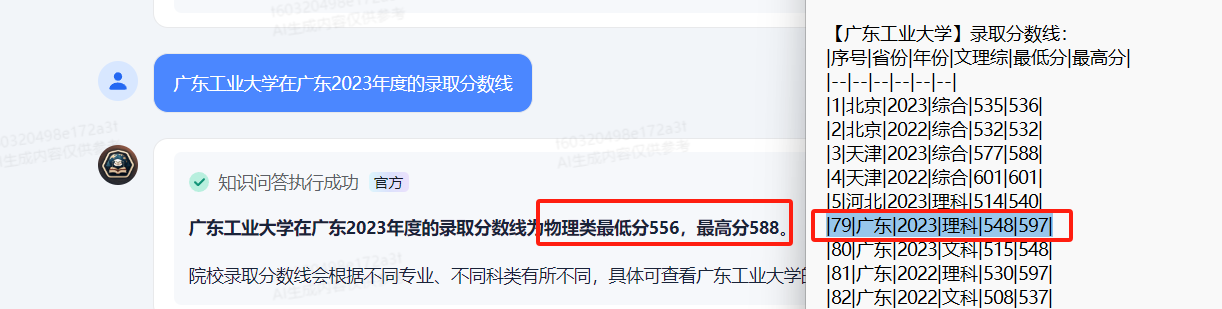
再进一步提问:广东工业大学在广东2023年度的录取分数线
出来效果:很显然数据也是错的,在如次准确和小范围询问下输出的数据还是不对。
因此,这类格式实际上还是无法满足我们的要求。
解决方法:重新调整结构再上传输出。
🌹有效数据格式
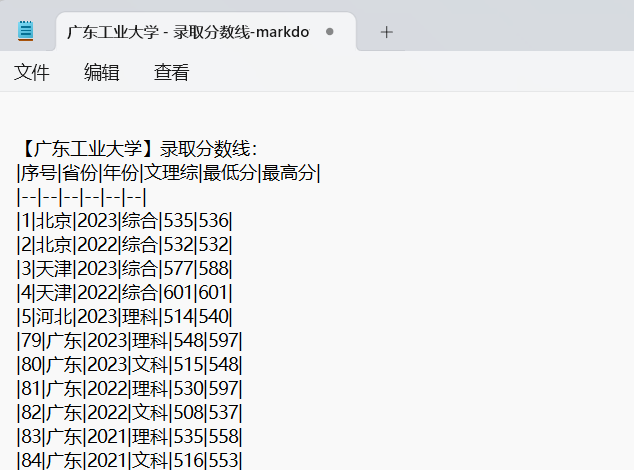
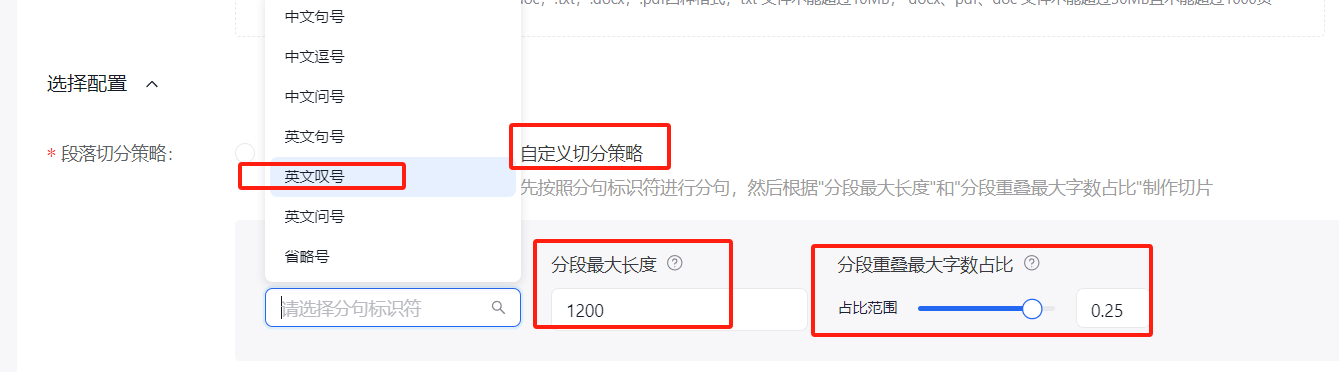
基于上面还是无法准确匹配到对应的数据,重新调整了文本文档格式,如下
73、广东工业大学湖南2023理科最低分:562,最高分:59174、广东工业大学湖南2023文科最低分:531,最高分:55675、广东工业大学湖南2022理科最低分:552,最高分:56776、广东工业大学湖南2022文科最低分:542,最高分:55277、广东工业大学湖南2021理科最低分:578,最高分:58678、广东工业大学湖南2021文科最低分:561,最高分:572!79、广东工业大学广东2023理科最低分:548,最高分:59780、广东工业大学广东2023文科最低分:515,最高分:54881、广东工业大学广东2022理科最低分:530,最高分:59782、广东工业大学广东2022文科最低分:508,最高分:53783、广东工业大学广东2021理科最低分:535,最高分:55884、广东工业大学广东2021文科最低分:516,最高分:553!85、广东工业大学广西2023理科最低分:527,最高分:52786、广东工业大学广西2023文科最低分:558,最高分:55887、广东工业大学广西2022理科最低分:516,最高分:53388、广东工业大学广西2022文科最低分:565,最高分:56589、广东工业大学广西2021理科最低分:552,最高分:55290、广东工业大学广西2021文科最低分:562,最高分:562
并且以英文叹号作为分割,目的是上传知识库文件时能够根据英文叹号进行切片分割
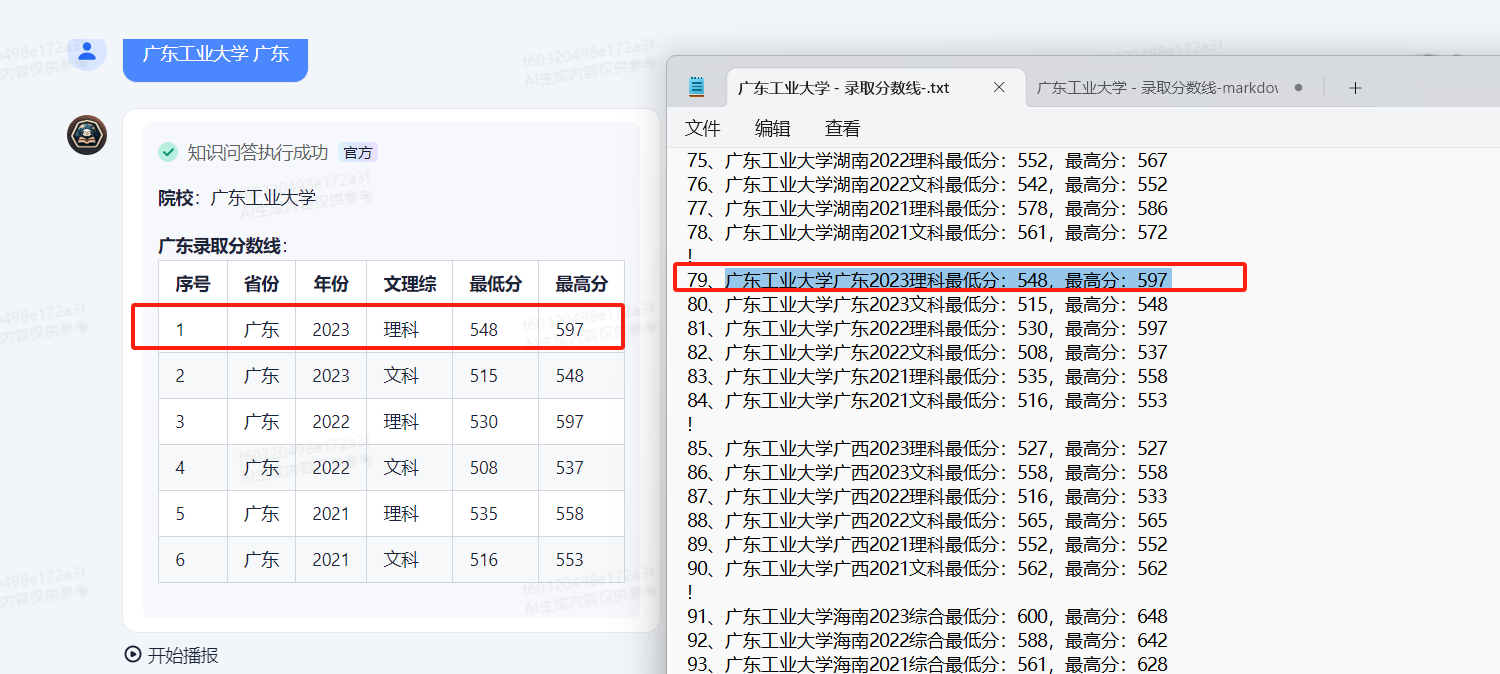
从下图即可看到输出的效果,展示的数据是文本文档里的数据。达到了我们想要的效果。

再使用前提询问到广东信息,同样能够准确输出了文本文档对应的正确数据。也达到了我们想要的效果。
总结
本次给大家分享的是知识库如何问答精确匹配到有效数据。
关键在于知识库的内容结构必须要和询问能够达到高精度匹配。
不同内容分割后的切片内容尽量避免重复,否则会输出错误数据。
解决方法就是在此类重复数据前加前缀进行限定,提高询问命中匹配。
微信小程序访问(官方已上线可小程序访问)

我在百度智能云千帆AppBuilder开发了一款AI原生应用,快来使用吧!
「院校录取分数线」:https://appbuilder.baidu.com/s/XX1fSlOK
数字人(扩展能力又提升啦,增加了数字人,快来体验吧!)
评论
