一文读懂 RAG:它将如何重新定义 AI 的未来?
大模型开发/技术交流
- LLM
6月4日681看过
在上一篇有关于思维链提示的文章中,我在最后有一小段提到了有关于 RAG 的内容:
RAG 可以使 LLM 能够在实时请求提供事实信息时,访问外部来源的数据,比如经过审核的数据库或互联网上的信息。这样一来,RAG 就消除了大家对于 LLM 仅依赖其训练数据中获得的内部知识库的顾虑,毕竟,这些知识库可能存在缺陷或不完整。
如果你尝试使用过一些 LLM,那么,极有可能遇到的情况就是:当我们向 LLM 询问某个话题的最新情况的时候,得到的会是诸如「抱歉,我无法提供到2024年的实时数据」这样的回答。换句话说,这其实就是 LLM 的根本限制,也就是说,它们的知识本质上是在最后一次训练的时间点就被冻结了,并不能学习和记住新的信息,除非经过重新训练。
那么,这时候,就需要 RAG 技术来解决这个限制了。所以,RAG 究竟是什么?为什么如此重要?它又是如何工作的...
本文将针对以上种种问题,对 RAG 技术进行全面的探讨。
文章目录
-
简介
-
RAG 是什么
-
为什么需要 RAG
-
RAG 系统的组成
-
RAG 如何工作的
-
RAG 的优势
-
RAG 的挑战和局限性
-
RAG 的应用
-
总结
RAG 是什么?
RAG,全称为 Retrieval-Augmented Generation,即检索增强生成。从名字上我们就可以得出一些关于「RAG 是什么」信息:它可以通过信息检索从外部知识库来获取更多的信息和数据,它结合了传统的大语言模型(LLM)和信息检索的功能。
举个例子来理解就是,想象一下,作为一个记者,如果要报道某个事件的最新进展,你会怎么做?首先是调研事件,收集相关的文章或者报告,然后使用这些信息来撰写新闻故事。对于 LLM,RAG 采取了类似的方法。「检索」就是收集相关信息,而「生成」则是使用这些信息来撰写新闻稿。
为什么需要 RAG
我们可以用一个例子,来帮助我们理解 为什么需要 RAG。
假设你是一家做线上店铺的商家,你的商品销量都特别好,会经常性地需要上架新商品或者下架已售罄的商品。你现在需要一个智能客服机器人(比如 GPT-3 或者 GPT-4)来回答用户关于商品详情、库存、价格等各类问题的查询。
然而,现在的问题就是,LLM 有以下这些限制,有可能会为你的买家带来不好的体验:
信息缺乏针对性
LLM 仅限于提供基于其训练数据的通用答案。如果买家要询问与你的店铺或者商品相关的问题,传统的 LLM 可能无法提供准确的答案。因为它们没有使用你店铺上的数据进行特别的训练。此外,LLM的训练数据往往都有一个截止日期,限制了它们提供最新信息的能力。
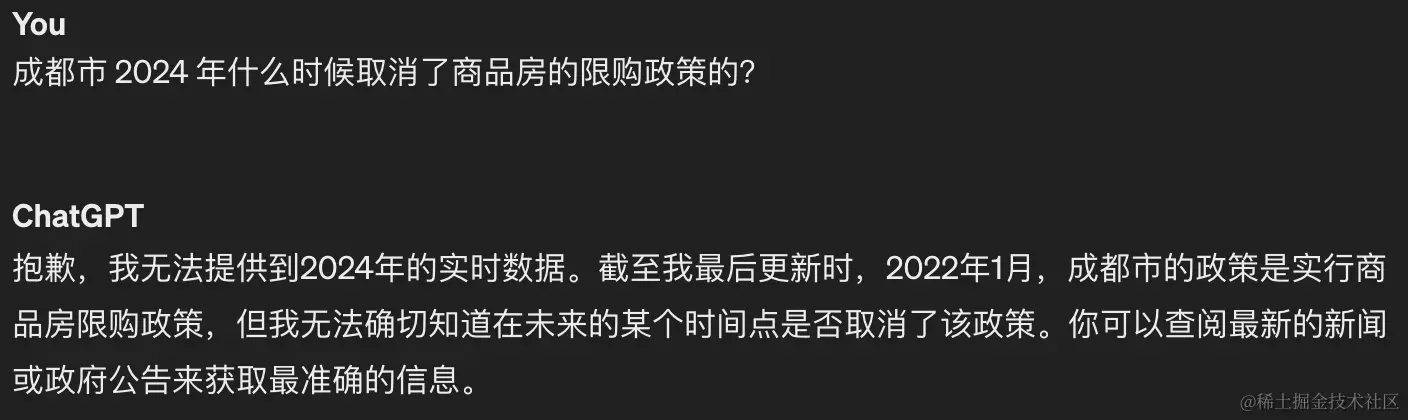
虚构回答
LLM 有可能会「虚构回答」,这是什么意思呢?就是说它们可能会基于不存在的事实来自信地生成错误的回答。同时,如果它们没有针对于用户的查询的准确回答,这样的算法就有可能提供完全不着边的答案,也就是我在之前的文章中所说的「胡说八道」,这会带来非常不好的用户体验。
通用回答
LLM 通常会提供不针对特定情境的通用回答。这在一些特定场景下,其实是属于比较大的缺陷了。所以现在市面上出现了更多的体量不那么大的,专门针对于特定领域的 LLM。
关于一些特定领域的开源 LLM,可以参考:github.com/HqWu-HITCS/…
RAG 系统的组成
RAG 不只是单一的一个组件或者一个程序,而是一个系统。RAG 系统是一个由多个组件组成的复杂系统,LLM 只是其中的一个组件。
RAG 系统的组件包括:
-
数据源:存储了要检索的信息,例如商品数据库、店铺信息等等。
-
数据处理模块:负责将数据转换为适合 RAG 系统使用的格式,例如进行数据切块(Chunking)和生成文档嵌入(Embedding)。
-
检索器(Retriever):负责根据用户查询从数据源中检索相关信息,使用基于关键词的搜索、文档检索或结构化数据库查询等检索技术来获取相关数据。
-
排序器(Ranker):通过评估检索信息的相关性和重要性来对其进行优化,确保最相关的信息呈现给 LLM 用于内容生成。
-
生成器(Generator):负责获取检索并排序的信息以及用户的原始查询,并通过 LLM 生成最终的响应或输出。生成器确保响应与用户的查询保持一致,并纳入从外部源检索到的事实性知识。
RAG 系统会根据用户查询从数据源中检索相关信息,然后将这些信息传递给 LLM 进行处理,LLM 会利用这些信息生成最终的回复。

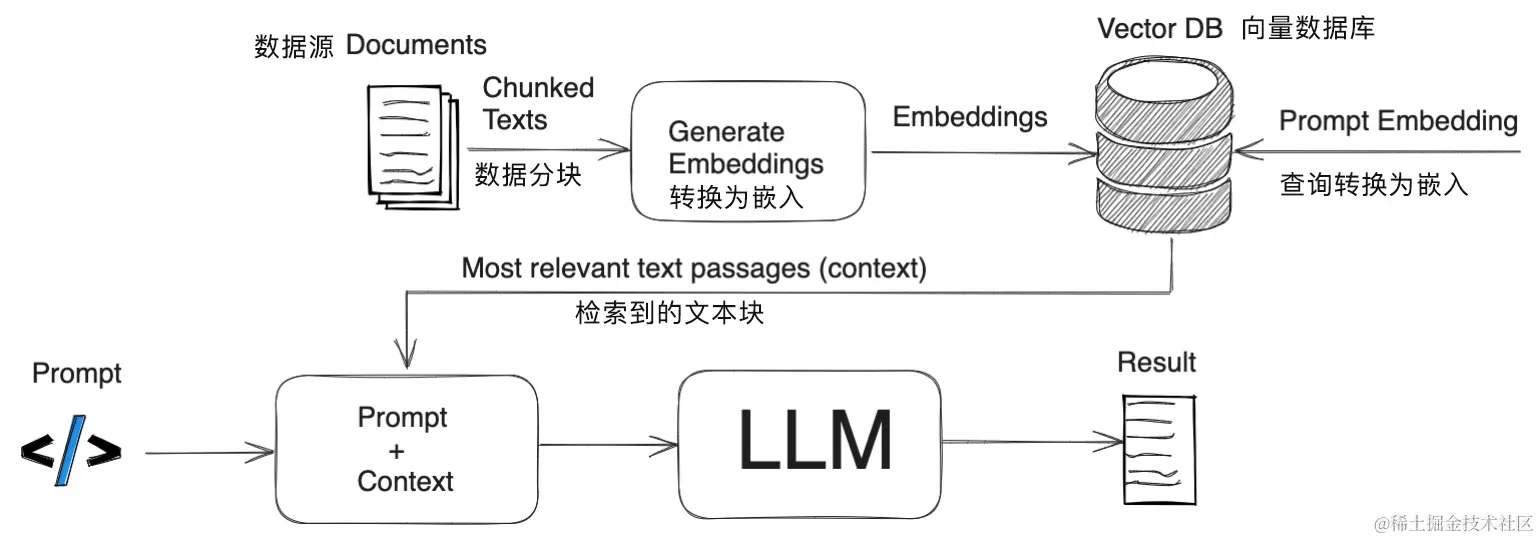
RAG 是如何工作的?
既然我们已经了解了 RAG 是什么以及 RAG 系统的组成,那么,现在就来看一下,RAG 系统具体的工作流程是怎么样的。
数据收集
首先,需要收集特定的应用程序所需要的所有数据。比如,针对于线上店铺,需要收集商品信息,库存信息,折扣信息等等。
数据分块(Chunking)
数据分块是指将数据源分解成更小、更易于管理的小块数据的过程。通过这种方式,每块数据都聚焦于一个特定的主题。当 RAG 系统从数据源检索信息时,它更可能直接找到针对于用户查询相关的数据,这样就避免了来自整个数据源的一些无用信息。同时,这种方式也提高了系统的效率,可以快速获取最相关部分的信息,而不是处理整个数据集。
文档嵌入(Embedding)
现在数据源已经被分解成更小的部分,需要将其转换为向量(Vector)表示,这就涉及将文本数据转换为嵌入(Embedding)。
可以简单地理解为:嵌入(Embedding)就像是将事物的特征压缩成一串数字,而向量(Vector)就是这串数字的有序排列,就像是一条线上的一串点。
处理用户查询并生成回答
当用户查询进入系统时,也必须将其转换为嵌入(Embedding)或向量(Vector)表示。为了确保文档和查询嵌入之间的一致性,必须使用相同的模型来处理。
当查询转换为嵌入之后,系统就会将查询嵌入与文档嵌入进行比较。它使用诸如余弦相似度(cosine similarity)和欧几里得距离(Euclidean distance)等算法来识别和检索与查询嵌入最相似的数据块。
通过 LLM 生成回答
检索到的文本块连同用户初始查询一起被输入 LLM 中,算法将利用这些信息通过聊天界面生成对用户问题的一致回复。
以下是一张简化的 RAG 系统的工作流程图。
RAG 的优势
RAG 的主要优势之一是能够提供更符合上下文语境的回答,同时,它还可以提高回答的准确性,尤其对于需要对话题进行深入理解的复杂问题。此外,RAG 可以针对特定行业进行微调,使其成为适用于各种应用的多功能工具。
与预训练模型不同,RAG 的内部知识可以很容易地被修改甚至实时补充。这使得研究人员和工程师能够控制 RAG 所知道和不知道的内容,而无需浪费时间或计算能力重新训练整个模型。
当然,RAG 还有更多的其他优势:
-
增强连贯性:外部语境的整合确保了 RAG 生成的内容保持逻辑流畅性和连贯性,尤其是在生成较长的文本或叙述的的情况下,显得极其重要。
-
通用性:RAG 用途广泛,可以适应各种任务和查询类型。它们不局限于特定领域,可以提供各种主题的相关信息。
-
效率:RAG 可以高效地访问和检索来自大型数据源的信息,与手动搜索相比节省了时间。这种效率对于一些需要快速响应的应用程序(例如聊天机器人)中就显得非常重要了。
-
内容摘要:RAG 适用于通过选择最相关的信息并生成简洁摘要来总结冗长文档或文章。
-
多语言能力:RAG 可以访问和生成多种语言的内容,使其适用于国际应用程序、翻译任务和跨文化交流。
-
决策支持:RAG 可以通过提供经过充分研究的、基于事实的信息来支持决策过程,帮助医疗、金融、法律等领域的各种决策做出明智的选择。
-
减少人工工作量:RAG 减少了手动研究和信息检索的需求,从而节省了人力和资源。这在需要处理大量数据的情况下尤其有价值。
-
创新应用:RAG 为创新的 NLP 应用打开了大门,包括智能聊天机器人、虚拟助手、自动内容生成等等,增强了用户体验和工作效率。
RAG 的挑战和局限性
尽管 RAG 有那么多的优势,但并不意味着这项技术就没有挑战和局限性。
主要挑战之一在于模型的复杂性管理。将 RAG 系统的检索器和生成器集成到单个模型中会导致模型复杂度很高。当存在来自不同格式的多个外部数据源时,这种复杂性会增加。不过,我们可以通过分别训练检索器和生成器来缓解这一问题,这可以简化训练过程并降低所需的计算资源。
另一个挑战是确保 LLM 能够有效利用检索到的信息。LLM 存在忽略检索到的文档而仅仅依赖其内部知识的风险,从而导致生成的响应准确性或相关性降低。我们可以通过根据检索器输出结果对 LLM 进行微调来解决这个问题,确保它能够充分利用检索到的文档。
然而,即使采用了这些解决方案,在使用 RAG 时依然有一些限制需要考虑:
-
搜索工具和数据的质量:RAG 生成回答的质量在很大程度上取决于搜索工具和数据的质量。如果搜索工具无法检索到相关和准确的文档或者检索到的数据质量不够好,那么回答的质量也将会下降。
-
可扩展性:随着数据量的增加,维护 RAG 系统将会变得更具挑战性。有许多复杂的操作和任务需要执行,例如生成嵌入、比较不同文本片段之间的含义以及实时检索数据,由于这些操作和任务都是计算密集型,所以,随着源数据大小的增加,可能会使系统变慢。
-
有限的内部知识:完全忽略语言模型的内部知识会限制可回答问题的数量。虽然检索到的文档可以提供额外的信息,但模型的内部知识对于生成准确和相关的响应仍然至关重要。
虽然有这些挑战的局限性,RAG 仍然具有巨大的潜力。随着持续的研究和开发,这些问题可能会得到解决,让 RAG 技术成为人工智能领域更加强大的工具。
RAG 的应用
问答系统
这也许是 RAG 技术最突出的应用,这些系统能够从大型知识库中检索相关信息,然后生成流畅的答案。
文本摘要生成
RAG 可以利用来自外部来源的内容来生成准确的摘要,从而节省大量时间。借助支持 RAG 的应用程序,他们可以快速提取文本数据中最关键的发现,并做出更有效的决策,而无需阅读冗长的文档。
个性化推荐
RAG 系统可以用于分析客户数据来生成产品推荐。RAG 应用程序可以根据用户观看历史记录和评分来推荐一些流媒体平台上更好看的电影,还可以用于分析电商平台上的商品评论。
由于 LLM 擅长理解文本数据背后的语义,因此 RAG 系统可以为用户提供比传统推荐系统更加细致的个性化建议。
以上是一些通用案例,我将在以后的文章中,带领你一起利用相关的框架来构建属于你自己的 RAG 应用。
总结
RAG 技术是一种强大的工具,可以增强 LLM 的能力。通过结合预训练语言模型的强大功能以及检索和利用外部信息的能力,提供更准确和与上下文更相关的回答。尽管存在一些挑战和局限性,RAG 的未来依然有着强大的可能性。随着 AI 领域的不断进步,RAG 这样的工具一定会更加完善,这些工具将在塑造我们的数字未来方面发挥至关重要的作用。
References
————————————————
版权声明:本文为稀土掘金博主「黄家润研究院」的原创文章
原文链接:https://juejin.cn/post/7364409188074946611
如有侵权,请联系千帆社区进行删除
评论
