3
"三板斧"解决大模型推理"慢"问题
大模型开发/技术交流
- 文心大模型
- LLM
- 大模型推理
4月8日5490看过
☞ 如果您在大模型落地过程中遇到任何问题,可以提交工单咨询:https://console.bce.baidu.com/ticket/#/ticket/create?productId=279
☞ 同时大模型技术专家可为您提供效果调优、应用定制和技术培训等付费专属服务:https://cloud.baidu.com/product/llmservice.html
一、前言
要想理解和解决大模型服务推理“慢”的问题,首先要知道大模型的推理结果是怎么产生的。
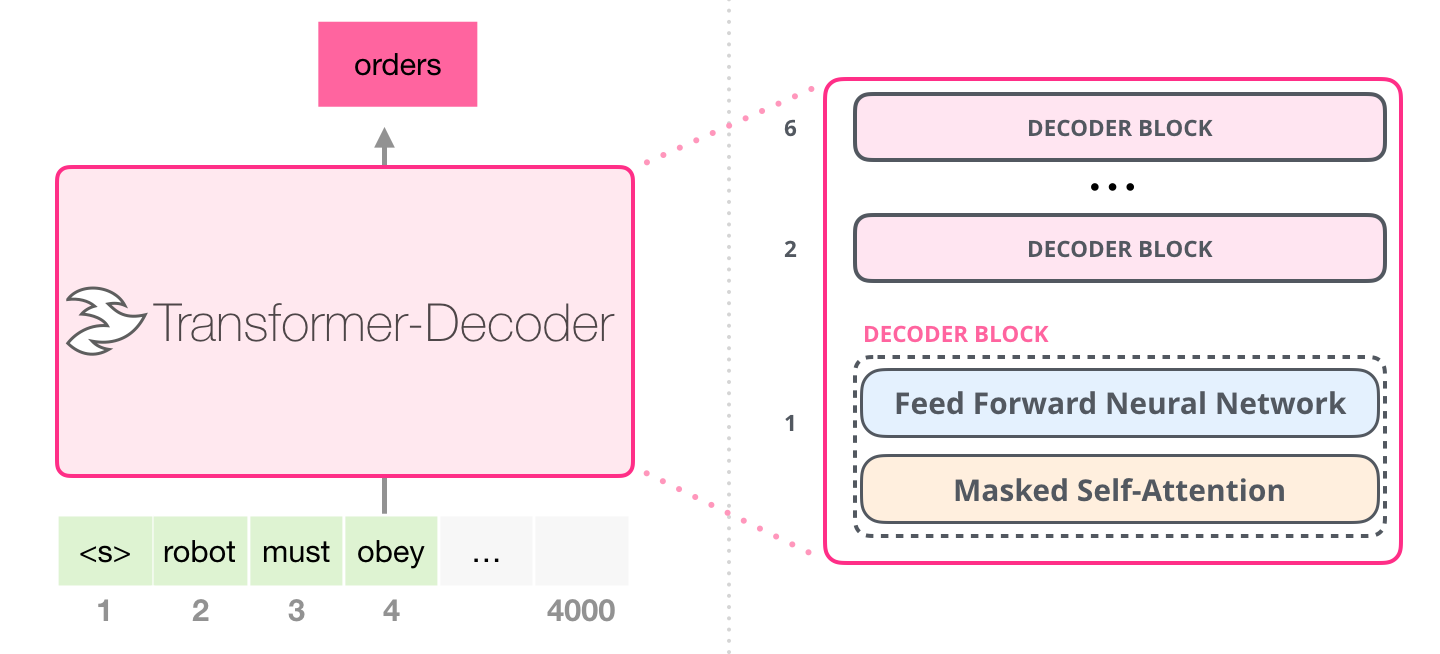
由上图可知,推理过程是不断地根据上文(robot must obey)来猜测下文最可能出现的token(orders),最后拼接而成。如果需要输出更长的结果,那么就需要不断地去根据上文推理下一个token,直到结束。所以影响大模型推理“慢”的主要原因是不同模型推理速度和输出长度。
总体来说,解决大模型推理“慢”大致有三种常见方案,您可以根据实际业务场景和工程需要来选择:
-
流式请求 (快速获得结果的头部部分tokens,尽快使用/展示,缓解长时间等待的焦虑)
-
切换模型 (不同模型推理速度不同,可以合理选择不同效果、速度的模型)
-
约束输出内容长度 (输出长度和推理时间成正比,合理有效的减少输出长度可以减少等待时间)
二、解决方案
流式请求
非流式请求与流式请求的差异
-
非流式请求
-
阻塞式等待服务端返回数据
-
所有推理结果一次性返回
-
适用场景:需要对结果进行固定格式解析、其他对完整性结果有要求
-
入参:stream: false(默认)
-
出参:
-
{"id": "as-fg4g836x8n","object": "chat.completion","created": 1709716601,"result": "北京,简称“京”,古称燕京、北平,中华民族的发祥地之一,是中华人民共和国首都、直辖市、国家中心城市、超大城市,也是国务院批复确定的中国政治中心、文化中心、国际交往中心、科技创新中心,中国历史文化名城和古都之一,世界一线城市。\n\n北京被世界城市研究机构评为世界一线城市,联合国报告指出北京市人类发展指数居中国城市第二位。北京市成功举办夏奥会与冬奥会,成为全世界第一个“双奥之城”。北京有着3000余年的建城史和850余年的建都史,是全球拥有世界遗产(7处)最多的城市。\n\n北京是一个充满活力和创新精神的城市,也是中国传统文化与现代文明的交汇点。在这里,你可以看到古老的四合院、传统的胡同、雄伟的长城和现代化的高楼大厦交相辉映。此外,北京还拥有丰富的美食文化,如烤鸭、炸酱面等,以及各种传统艺术表演,如京剧、相声等。\n\n总的来说,北京是一个充满魅力和活力的城市,无论你是历史爱好者、美食家还是现代都市人,都能在这里找到属于自己的乐趣和归属感。","is_truncated": false,"need_clear_history": false,"finish_reason": "normal","usage": {"prompt_tokens": 2,"completion_tokens": 221,"total_tokens": 223}}
-
流式请求
-
服务端生成一段推理内容(非语义连贯)后即输出,调用方无需等待所有数据返回后再处理;
-
提升了首个token的响应时间,减少用户等待;
-
适用场景:对话、检索类,无需对结果进行特殊格式解析等
-
入参:stream: true
-
出参:
-
data: {"id":"as-vb0m37ti8y","object":"chat.completion","created":1709089502,"sentence_id":0,"is_end":false,"is_truncated":false,"result":"当然可以,","need_clear_history":false,"finish_reason":"normal","usage":{"prompt_tokens":5,"completion_tokens":2,"total_tokens":7}}... ...data: {"id":"as-vb0m37ti8y","object":"chat.completion","created":1709089508,"sentence_id":3,"is_end":false,"is_truncated":false,"result":"您可以参观西安的兵马俑、大雁塔,体验兰州的黄河风情,以及在敦煌欣赏壮丽的莫高窟。","need_clear_history":false,"finish_reason":"normal","usage":{"prompt_tokens":5,"completion_tokens":2,"total_tokens":7}}
从上述返回结果数据结构上可以看出,调用方需要针对不同的请求方式分别处理。
更多请求示例和细节,您可以参考官方文档:https://cloud.baidu.com/doc/WENXINWORKSHOP/s/clntwmv7t(此处以ERNIE-4.0-8K模型为例)
首token响应时间对比
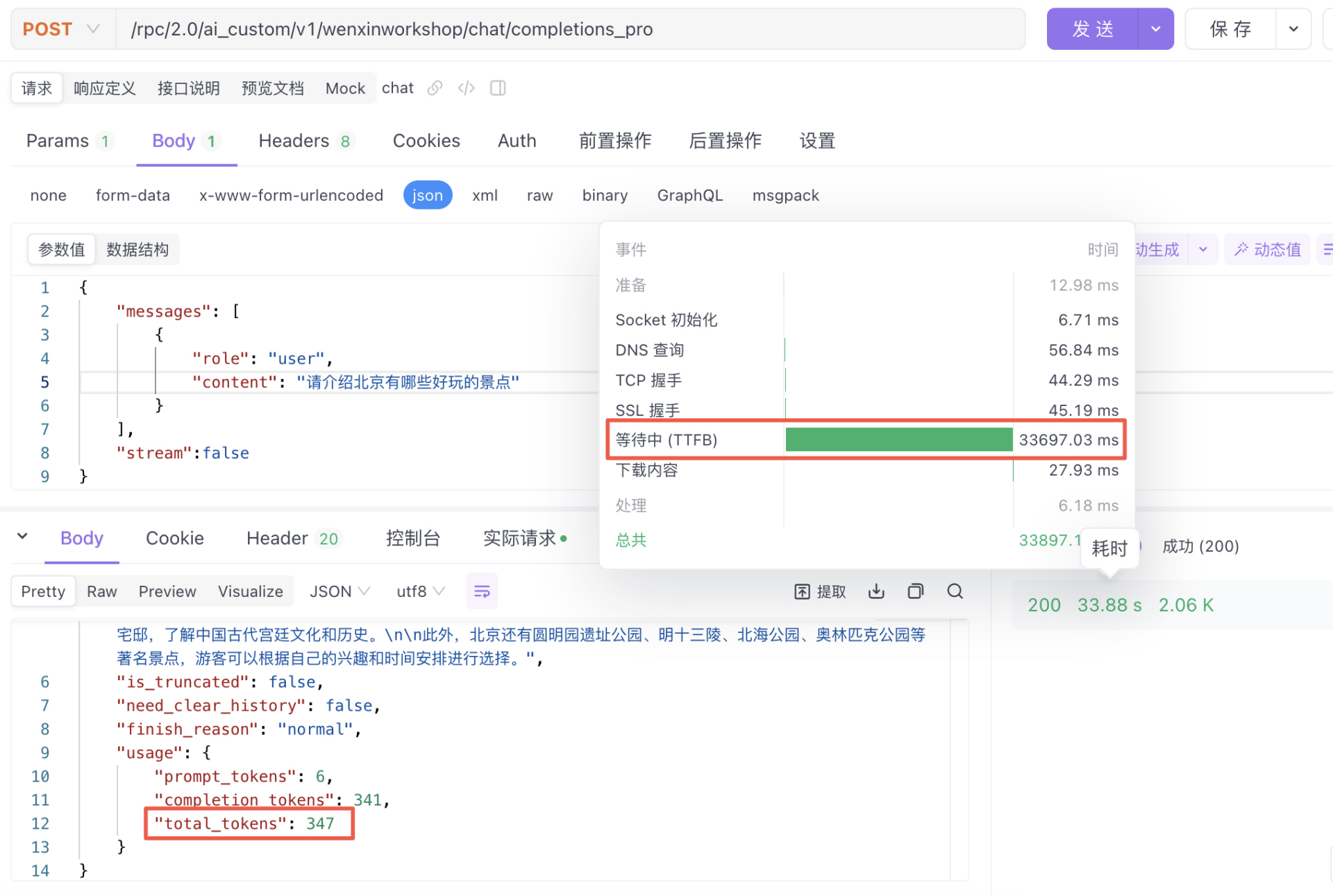
{"messages": [{"role": "user","content": "请介绍北京有哪些好玩的景点"}],"stream":false}
stream:false 时的响应时间:等待所有所有结果都返回的时间是33秒
stream:true时的首包响应时间:3秒
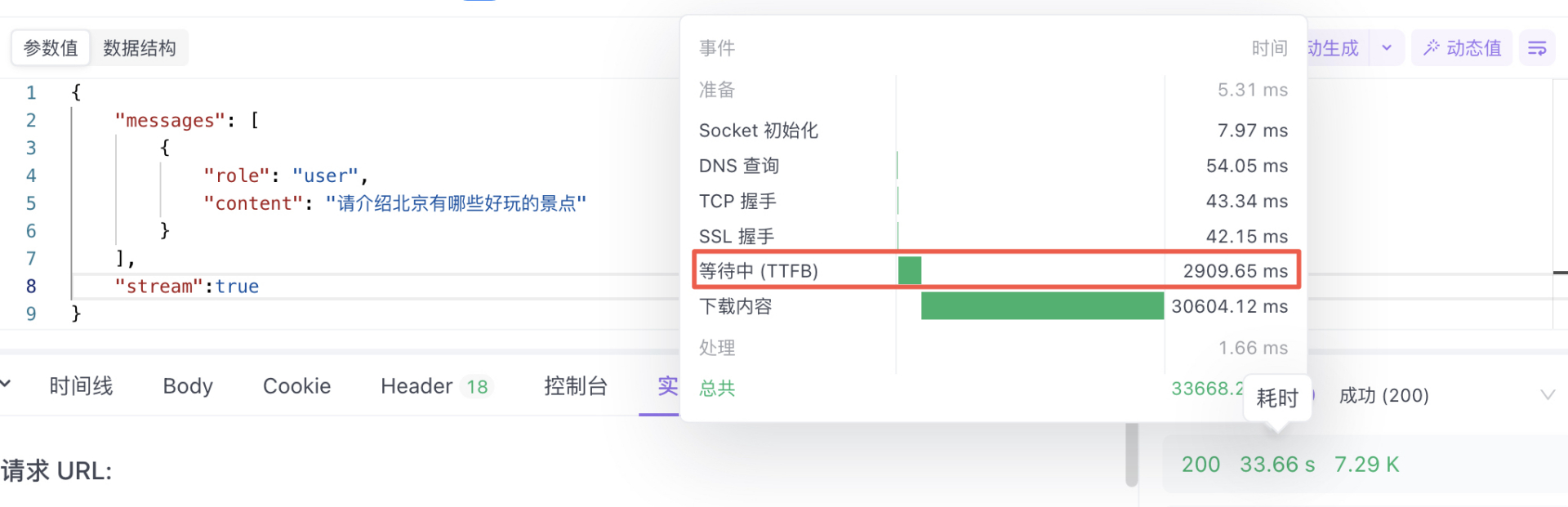

从上述两个测试对比可以看出,使用流式请求能够更快地获取到推理结果,随后每隔几秒就会返回更多推理文本段落。有效的缓解了用户侧等待焦虑。
切换模型
如何选择模型?
选择模型要从不同的角度入手,如tokens单价、生成速度、结果质量等;可以根据业务场景和需求按需选择使用。
费用&场景推荐
下面是简单列举了几个模型的费用情况,更多最新的模型资费您可以参考:https://cloud.baidu.com/doc/WENXINWORKSHOP/s/hlrk4akp7
|
模型名称
|
输入单价
|
输出单价
|
适用场景
|
|
ERNIE-4.0-8K
|
0.12元/千tokens
|
0.12元/千tokens
|
处理十分复杂场景、任务,需要严格按照Prompt执行的场景(复杂标签生成、参数提取、任务判断和直接搜索等)。
|
|
ERNIE-3.5-8K
|
0.012元/千tokens
|
0.012元/千tokens
|
常规任务场景,如意图识别、脚本生成、直接搜索等
|
|
ERNIE-Lite-8K-0922
|
0.008元/千tokens
|
0.008元/千tokens
|
聊天、文章扩写等
|
|
ERNIE-Speed-8K
|
0.004元/千tokens
|
0.008元/千tokens
|
聊天、简单任务处理等
|
如果您的业务场景包含不同的子场景,可以根据不同子场景对模型效果、响应速度等各方面的要求择优选择合适的模型即可(各取所长,多模融合)。
tokens响应速度
不同模型对应的tokens生成速度也都不一样。我们可以通过下面对不同模型测试的对比结果,观察到它们之间的差异(这些结果仅代表本次测试过程):
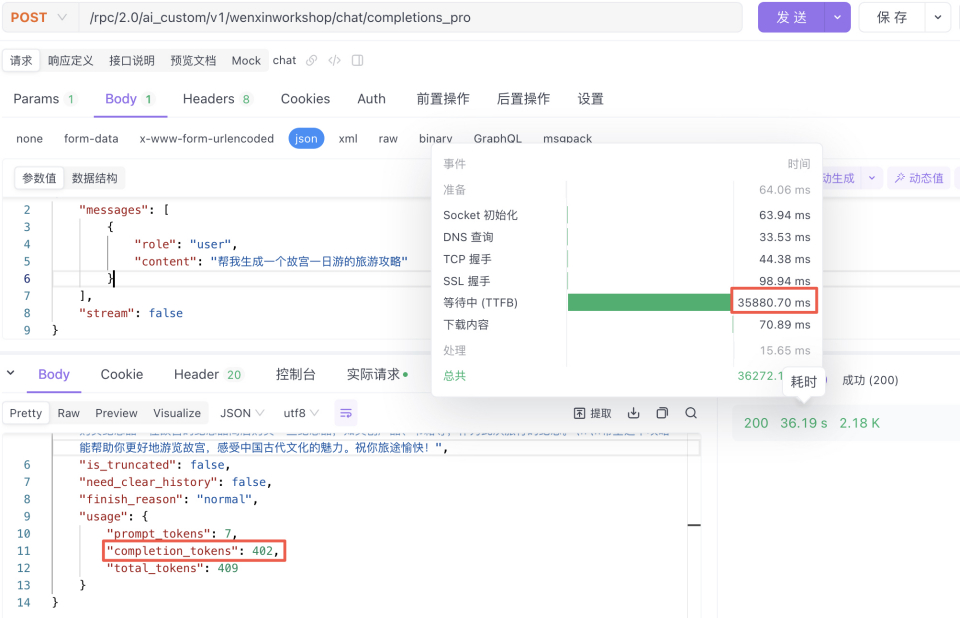
{"messages": [{"role": "user","content": "帮我生成一个故宫一日游的旅游攻略"}],"stream": false}
ERNIE-4.0-8K
测试1-模型推理时间:35.88s,推理结果402tokens:平均11.2 tokens/s (仅单次测试,供参考)
测试2-模型推理时间:50.02s,推理结果532tokens:平均10.63 tokens/s(仅单次测试,供参考)
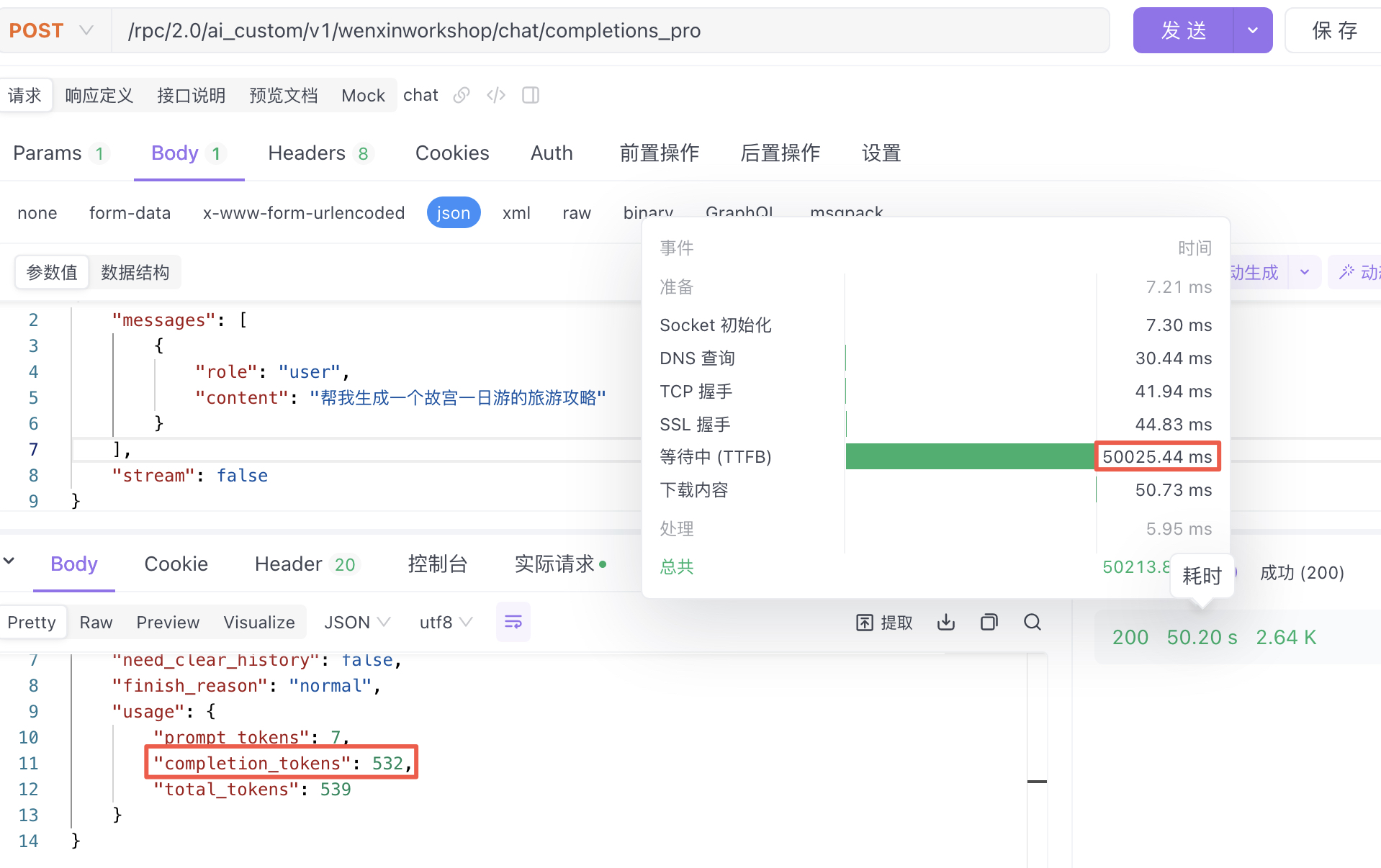
ERNIE-3.5-8k
测试1-模型推理时间:27.58s,推理结果453tokens:平均16.42 tokens/s(仅单次测试,供参考)
测试2-模型推理时间:26.60s,推理结果461tokens:平均17.33 tokens/s(仅单次测试,供参考)

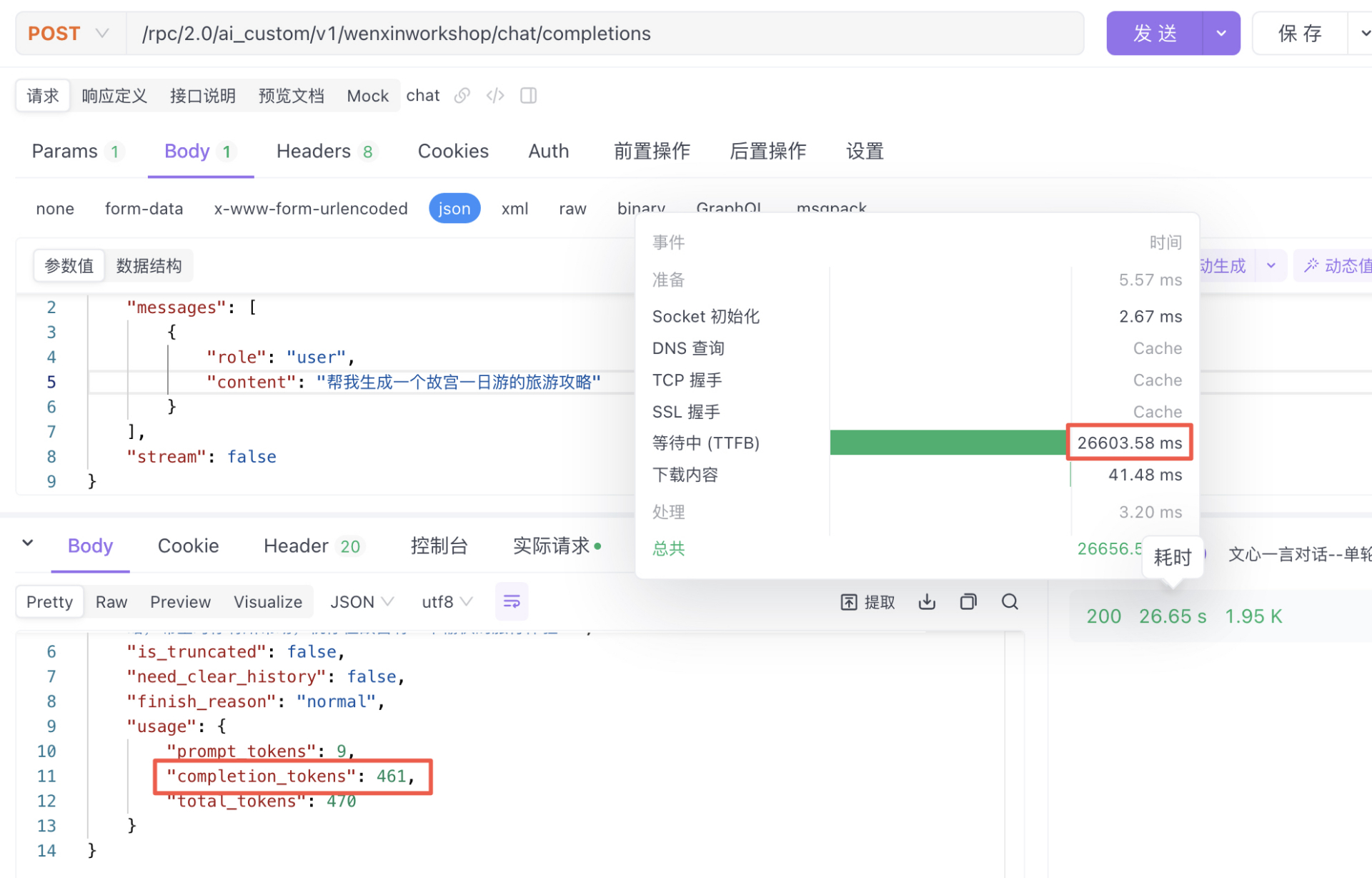
ERNIE-Speed-8K
测试1-模型推理时间:15.67s,推理结果606tokens:平均38.67 tokens/s(仅单次测试,供参考)
测试2-模型推理时间:15.51s,推理结果494tokens:平均31.85 tokens/s(仅单次测试,供参考)
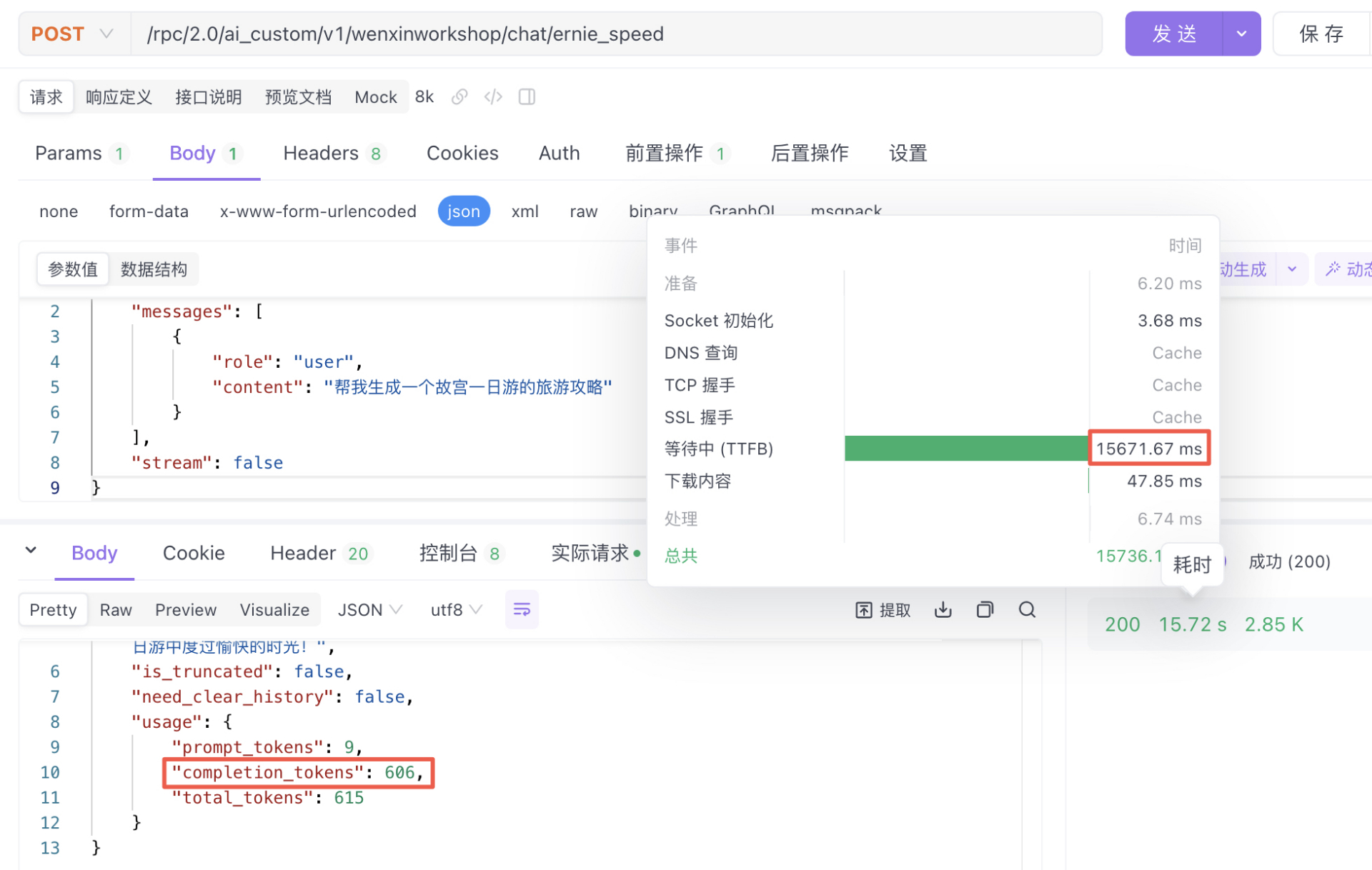
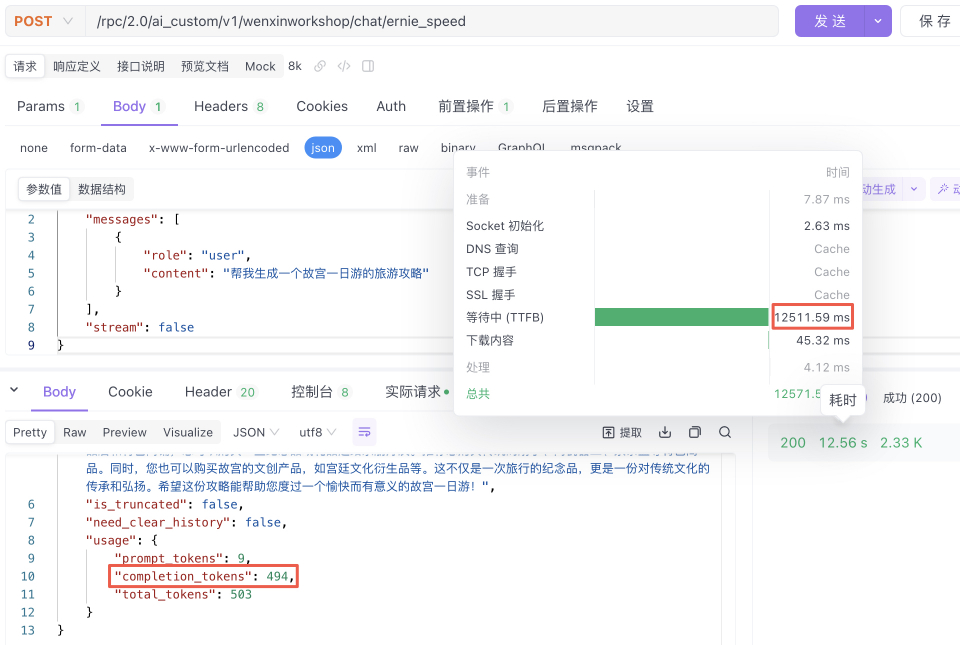
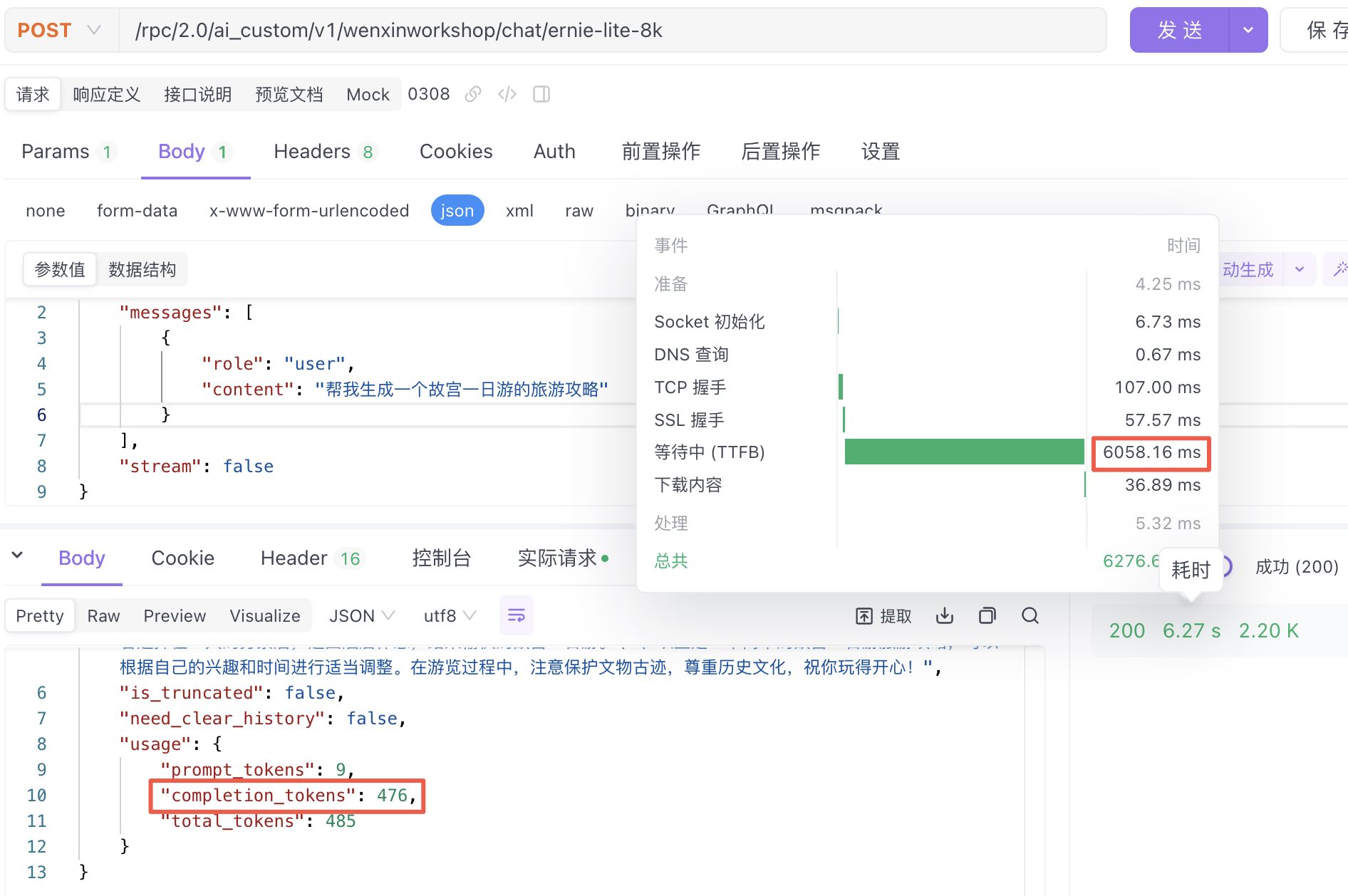
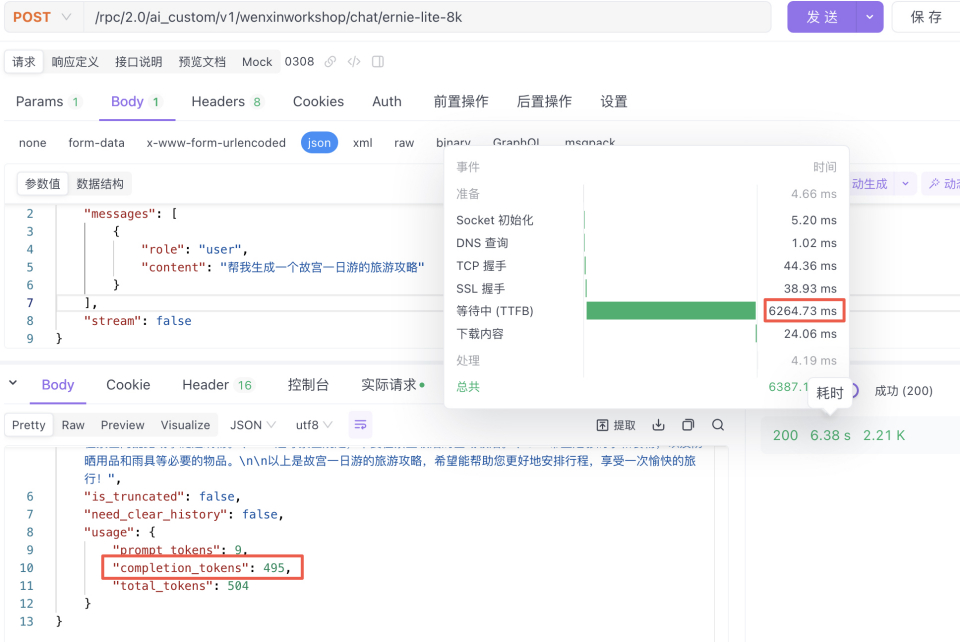
ERNIE-Lite-8K-0308
测试1-模型推理时间:6.05s,推理结果476tokens:平均78.67 tokens/s(仅单次测试,供参考)
测试2-模型推理时间:6.26s,推理结果495tokens:平均79.07 tokens/s(仅单次测试,供参考)
任务指令遵循效果对比
输入相同的Prompt,测试下列4个模型的指令遵循效果
本周完成了一些研发工作,我会给你一个列表,列表结构为第一列表示工作的类型,通常有Story、Feature、Bug等;第二列表示这项工作的状态,通常有新建,开发中,测试中,已完成;第三列代表工作是否有超期风险,如:已超期,未超期;第四列表示这列工作的内容,具体描述了我做了什么。请一步一步的思考,按照要求帮我写一份周报,我希望通过这些工作内容,生成一份周报。周报的结构由3部分组成:1. 工作摘要:请把第四列的内容进行合并总结改写成一句通顺的话,其中类似的话请合并;2. 主观分析:请根据第四列中已经超期的工作进行总结,表明需要重点关注;3.详细卡片:根据我输入的列表内容生成一个表格,给表格命名为“原始卡片”。我期望的返回格式是:## 本周进展 。 Begin:Task 新建 已超期【后端】自动化规则动作执行数据统计 ;Story 新建 自动化规则动作执行数据统计 ;TechTask 新建 未超期 快速编辑接口关联卡片支持传卡片 id, 目前需要空间前缀+编号 ;Story 新建 未超期 iTest 接入 iCafe 新建/编辑弹窗 ;Task 开发中 已超期【后端】order脏数据处理:如果order不为null,isDesc为null,那么给个默认值 ;Story 新建 未超期 迭代计划需要将viewId 同步到URL上,这样就能根据一个url唯一确定视图 ;Bug(线上) 已完成 未超期 请求storymapping dubbo 接口超时导致卡片创建失败 ;TechTask 完成 未超期 map-bugs 空间的「问题分类」字段有超过 1000个选项,卡顿明显。

从上面结果可以看出:
-
ERNIE-4.0-8K 工作摘要、主观分析内容比较简短精炼,效果最好;ERNIE-3.5-8K效果次之;ERNIE-Speed-8K和ERNIE-Lite-8K模型内容较多,稍显啰嗦。
-
最终都按照指令要求生成了周报,结构基本符合预期,都生成了表格内容。
综上所述,ERNIE-Speed-8K和ERNIE-Lite-8K模型也能按需求输出较为完整的关键信息和表格,在保证输出速度的前提下也能得到较好的输出结果。
约束输出内容长度
下面我们一起来看下如何约束输出内容长度达到缩短耗时的效果。以ERNIE-4.0-8K模型为例。
|
输入
|
输出结果
|
|
|
{
"messages": [
{
"role": "user",
"content": "生成一段描述故宫的内容"
}
],
"stream": false
}
|

|
输出260tokens,耗时20.46秒。
|
|
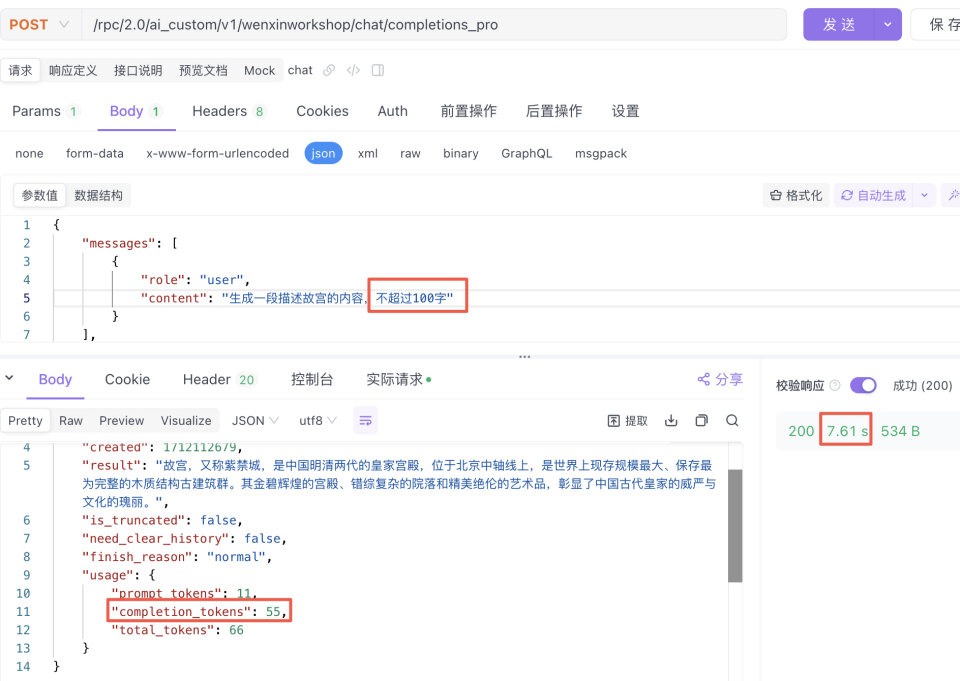
{
"messages": [
{
"role": "user",
"content": "生成一段描述故宫的内容,不超过100字"
}
],
"stream": false
}
|
|
输出55tokens,耗时7.61秒。
|
从上面对比结果可以看到,通过“不超过100字”类似的Prompt约束后,模型返回的结果长度大大缩短,耗时也从20秒减少到了7秒。在这种开放性问题回答场景效果显著。
但值得注意的点是:大语言模型对Prompt中字符约束的效果和提示词内容相关(例如:写一篇符合高考要求的议论文,字数不超过10个字。提示词前后矛盾,大模型便不会遵循字数约束的要求),是一个锦上添花的方案。
三、总结
在现有模型服务基础上,通过流式请求、切换模型和约束输出长度等三种方案,可以快速解决“大模型推理慢”的问题,成为常见的解决方案,可以根据业务场景按需使用。
当然千帆各模型推理速度、效果都在高速优化迭代中,相信我们会不断提升体验给您带来不一样惊喜,敬请期待
☞ 如果您在大模型落地过程中遇到任何问题,可以提交工单咨询:https://console.bce.baidu.com/ticket/#/ticket/create?productId=279
☞ 同时,大模型技术专家可为您提供效果调优、应用定制和技术培训等付费专属服务:https://cloud.baidu.com/product/llmservice.html
评论
